实现简单数据库 嵌入式_将参考数据嵌入到IBM ODM决策服务实现中
运行使用IBM ODM实施的复杂决策服务通常需要访问某些企业参考数据以评估和应用业务规则。 此数据通常定义为查找表或代表两个或多个业务概念之间关系的键值对集合。 使这些表可用于规则引擎有时会给应用程序体系结构,更改管理过程或这两者带来挑战。试用业务规则服务业务策略更改时,花费更少的时间进行编码和测试。 Bluemix的业务规则服务通过将业务逻辑与应用程序逻辑分开来最大程度地减少了...
实现简单数据库 嵌入式
运行使用IBM ODM实施的复杂决策服务通常需要访问某些企业参考数据以评估和应用业务规则。 此数据通常定义为查找表或代表两个或多个业务概念之间关系的键值对集合。 使这些表可用于规则引擎有时会给应用程序体系结构,更改管理过程或这两者带来挑战。
本教程的目的是提供指导和建议,以使参考数据在运行时可用于业务规则,这取决于大小,更改频率和数据特征的其他考虑。 本教程重点介绍两种简单的方法,即将参考数据与部署到Rule Execution Server的工件一起嵌入:规则集和托管执行对象模型(XOM)。 尽管其他方法可能更有效或更具扩展性,但是这两种方法对于IBM ODM on Cloud至关重要,因为这些规则可用的所有数据都来自决策服务调用期间提供的输入有效负载或来自Rule Execution Server资源。 。
上下文数据和参考数据
大多数基于业务规则的决策服务实现都是基于简单的无状态模型,该模型使用一系列if-then规则处理输入数据元素的集合,以生成表示预期业务决策的输出数据。 所需的输入数据分为以下两类:
- 特定于决策服务调用实例的数据。 示例包括贷款申请人的特征,您为其承销贷款的财产,需要裁定的医疗索赔的详细信息或要验证的采购订单。 在本教程中,该数据称为事务数据或决策的上下文数据 。
- 代表参考点的数据,这些参考点用于定义和应用业务策略。 该数据通常代表外部法规或合规性规则或有关公司如何开展业务的内部特征。 例如,它可能代表每个州法律允许的最高利率,或者代表有效的医疗程序代码列表,或者无法运送到邮政编码的物品类型。 在本教程的其余部分中,此类数据称为决策参考数据 。
从高级的角度来看,业务规则的关键功能是将从上下文数据发布的值(直接或通过业务规则计算得出)与从参考数据中选择的值进行匹配,以最终生成想要的决定。
考虑来自采购订单确认决策服务的规则示例,该规则的作用是排除买方居住国限制运输的任何物品。 可以在IBM ODM中表达这样的规则,如清单1所示:
清单1.使用参考数据的排除受限项目操作规则示例
definitions
set item to an item in the line items of 'the PO';
if
item is restricted in the state of residence of 'the buyer'
then
add item to the exclusions of 'the PO'
with reason "cannot ship item to the buyer's state";支持运行此规则所需的参考数据表可以定义在特定状态下受限制的项目列表。 例如,该表可能如图1所示:
图1.限制项目参考数据表
清单1中显示的业务规则同时使用了上下文和参考数据元素。 它通过将上下文数据与参考数据进行匹配来实现部分业务策略。 在此示例中,请考虑以下详细信息:
- 所订购的物品和采购订单的排除内容是上下文数据的一部分。
- 买方的居住状态也是上下文数据的一部分。
- 受状态限制的项目列表是参考数据的一部分。
图2说明了示例中涉及的不同类型的元素。
图2.支持规则集执行的上下文和参考数据
数据特征
上下文和参考数据通常具有不同的特征。 上下文数据表示业务领域中实体的详细信息。 因此,通常将其建模为包含多个级别和多值属性的大型复杂对象层次结构。 决策越复杂,对象层次结构就越大,就越详细,以反映与业务决策相关的上下文的尽可能多的方面。
相比之下,参考数据通常是一个简单的映射表(可能具有多个列)。 它没有上下文数据的结构复杂性。 但是,表通常很大,有成百上千个条目。 对于参考数据,更复杂的决策将转换为更细粒度的表(例如,具有更多行,其标准位于城市或邮政编码级别,而不是州级别)。 或者,更复杂的决策包括更多表以支持规则中更精细和更多样化的决策标准。
请考虑以下其他显着差异:
- 上下文数据范围是整个决策,而参考数据范围通常限于该决策中的少量特定规则或规则任务。
- 在大多数情况下,上下文数据中的所有数据点都用于计算决策,而参考数据集中的少数数据点可能适用。
- 上下文数据从一个决策服务调用到下一个决策服务调用是不同的,并且参考数据更改很少(通常不如规则本身更改那样频繁)。
作为映射表,参考数据描述了与上下文数据的某种关系。 但是,它没有提供有关如何使用该关系的任何规定。 在大多数情况下,数据自然适合规则集中规则的左侧(条件部分)。
面临的挑战是找到将参考数据合并到规则集中的最佳方法,以使其在运行时可用于手头的决策,甚至可能属于同一应用程序的其他决策。 下一节将介绍一些应考虑的因素,以帮助您选择正确的方法。
本教程中的代码示例是使用IBM ODM V 8.7.1开发的。
选择一种方法
最终选择的使参考数据可用于决策服务的方法取决于从解决方案的功能需求和非功能需求中得出的多个因素。 仔细评估这些因素,因为没有一种适合所有情况的方法。
本地或远程调用
通常,使用决策服务的本地调用(例如,使用从IlrJ2SESessionFactory或IlrPOJOSessionFactory获得的规则会话)是默认的解决方案,它提供了访问参考数据的最大灵活性。 在调用的应用程序和决策服务之间交换大量数据时,无需考虑网络延迟。 可以简化访问数据库或其他数据服务的安全注意事项。
相比之下,当您使用远程调用时(例如,自定义Web服务托管的透明决策服务(HTDS)或受监视的透明决策服务(MTDS)),请仔细评估通过网络交换的数据量。 您可能会发现很难为可能部署在云中的远程Rule Execution Server提供对数据源的必要访问权限。 例如,对于IBM ODM on Cloud,出于安全原因,不允许访问外部服务或数据源。
附带说明一下,如果请求有效载荷对于远程调用而言很大,请牢记以下提示。 如果使用从IlrEJB3SessionFactory获得的规则会话,则企业JavaBean(EJB)可能比Web服务更有效。 如果使用异构语言或环境,请考虑在解决方案中使用消息驱动的规则bean。
分享
相同的参考数据可以由不同的应用程序以不同的方式使用,并且可以具有多种类型的不同使用者。 数据是否是规则专用的,通常会决定如何将其合并到规则集中。 在多个使用者的情况下,数据必须始终对所有使用者可用,并且必须对所有使用者保持同步。
管治
预期的更改频率,所有权,软件开发生命周期和其他治理注意事项会强烈影响您应该维护参考数据的位置。 决策治理流程需要包括必要的步骤,以确保部署的每个新规则集都使用参考数据的正确版本。 当未通过IBM ODM管理参考数据的源时,此要求尤其重要。 无论其性质如何,都必须托管,管理,版本控制和保护每个存储库。
卷
需要管理的参考数据量可能会影响规则集的大小,性能以及在决策中心中编写规则的业务用户体验。 通常,大量参考数据会阻止将数据嵌入规则中。
测试中
参考数据必须可供测试。 容易理解,如果您使用决策中心业务控制台进行测试,则必须可以从决策中心访问参考数据存储。 同样,对于在Rule Designer中进行测试的规则开发人员,必须可以访问参考数据。 脱机测试要求数据源在本地环境中可用。
丰富请求有效负载
在讨论将参考数据嵌入可部署的Rule Execution Server工件中的解决方案的详细信息之前,请考虑一种通用策略,使参考数据可用于规则,然后再在Rule Execution Server上调用它们。 您可以通过增加请求有效负载来使数据可用。 过滤和丰富上下文数据,或者提供一组可在规则中使用的参考数据表的句柄。
通常,参考数据来自数据库表,并且由框架(例如来自Apache Commons的Java Caching System( commons.apache.org/proper/commons-jcs )和基于标准的开源Ehcache)进行缓存。缓存( www.ehcache.org )。
如图3所示,决策服务客户端线程负责收集规则集运行之后可用的数据。 图3中的客户机线程通常是定制Web服务的一部分,该定制Web服务以面向服务的体系结构向客户公开决策服务,并在扩展步骤之后封装IBM ODM服务的调用。
图3.通过请求丰富的参考数据
因为扩充直接影响有效负载的大小,所以此策略对决策服务调用是本地还是远程敏感。 另外,由于在调用决策服务之前已收集了所需的整个参考数据集,因此可能会检索到比实际需要更多的数据,从而影响性能。 最后,在过滤数据以进行充实时,避免包括业务知识。 有关此方法的更多详细信息,请参阅访问规则应用程序中的外部数据 。
在XOM中捕获参考数据
在许多情况下,最好在规则集执行期间收集参考数据。 与上一节中描述的请求有效负载丰富情况类似,数据本身在规则外部维护,并在规则运行时引入。 但是,规则执行线程会检索数据。 组件的组织如图4所示:
图4.在XOM中捕获参考数据
您可以将参考数据存储在外部数据源(例如数据库)中,也可以存储为XOM中的文件。 有关数据库方法的详细信息,请参见访问规则应用程序中的外部数据 。
替代方案包括在XOM中捕获参考数据,基本上依赖于将文件资源与托管XOM捆绑在一起。 在执行时读取文件并进行评估。 用于评估内容的方法取决于数据的性质。 可以在XOM层中对数据进行评估(对业务用户完全透明),也可以将其转换为业务对象模型(BOM)中的对象,然后将其用于规则创作任务中。 以下实现示例演示了如何读取文件以及如何在下游规则中使用结果。
实施实例
在XOM中捕获参考数据实质上依赖于将文件作为资源捆绑在XOM归档文件中,该文件由IBM ODM Rule Execution Server发布和管理。 资源文件在运行时由数据提供程序Java类加载和处理。 该类已成为BOM表的一部分,因此可以用来编写规则。
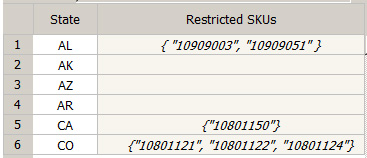
下面的示例演示数据提供程序类的示例实现,以及如何在下游规则中使用它。 来自图1的参考数据可以存储在平面文件中,其中每一行代表一种状态的限制。 该行的第一个标记指示状态,其余行是用逗号分隔的库存单位(SKU)列表。 内容类似于清单2中的示例。
清单2.平面文件中的示例参考数据
AL 10909003,10909051
AZ
AR 10801150
CA 10801121,10801122,10801124
CO
…清单3中的ReferenceDataProvider类读取文件并将内容转换为适当的限制对象。 它遵循单例模式设计,该设计将类的实例化限制为一个对象,并且它包括一个调用私有构造函数的公共同步getInstance方法。
在第一次调用中,构造函数解析数据集,并将解析后的数据集存储在ShippingStateRestriction对象的哈希图中,并按相应状态建立索引。
清单3. ReferenceDataProvider类定义
public class ReferenceDataProvider {
private static ReferenceDataProvider instance = null;
private Map<StateType, ShippingStateRestriction> restrictions = null;
private static final String LINE_SPLIT_BY = " ";
private static final String SKUS_SPLIT_BY = ",";
private ReferenceDataProvider() throws IOException {
if (restrictions == null) {
parseDataSet();
}
}
public static synchronized ReferenceDataProvider getInstance()
throws FileNotFoundException, IOException {
if (instance == null) {
instance = new ReferenceDataProvider();
}
returninstance;
}
public ShippingStateRestriction getRestriction(StateType state)
{
return restrictions.get(state);
}
private void parseDataSet() throws IOException {
String dataFilename = "SKURestrictionsByState.csv";
InputStream inputStream =
getClass().getClassLoader().getResourceAsStream(dataFilename);
BufferedReader br =
new BufferedReader(new InputStreamReader(inputStream));
restrictions = new HashMap<StateType, ShippingStateRestriction>();
String line;
while ((line = br.readLine()) != null) {
String[] entry = line.split(LINE_SPLIT_BY);
StateType state = StateType.valueOf(entry[0]);
List<String> skus = Arrays.asList(entry[1].split(SKUS_SPLIT_BY));
ShippingStateRestriction stateRestriction =
new ShippingStateRestriction();
stateRestriction.setState(state);
stateRestriction.setSkus(skus);
restrictions.put(state, stateRestriction);
}
br.close();
}
}在这个简单的示例中,文件的全部内容被加载到地图中,将数据过滤推到BOM或规则中。 如果内容很大,则可以对存储和保留的内容采取更区分的方法。
参考数据文件本身包含在XOM项目中,您可以在Java类路径中找到它。 图5显示了一个示例项目结构,其中包含SKURestrictionsByState.csv资源文件和ReferenceDataProvider类。
图5.示例XOM项目组织
在BOM表中,您可以使用各种模式将相关实体暴露给规则。 对于清单1中的示例规则,可以对Item类使用语言化的虚拟BOM方法来评估该项目是否受限制。 该方法的定义如图6所示。
图6.访问参考数据的示例BOM方法定义
清单4中的BOM到XOM的代码片段显示了使用ReferenceDataProvider类的方法主体。 它从映射中获取适当的状态限制,并根据需要返回true或false 。
清单4. BOM到XOM的代码以访问参考数据
ReferenceDataProvider provider = ReferenceDataProvider.getInstance();
ShippingStateRestriction restriction = provider.getRestriction(state);
return (restriction.getSkus().contains(this.getSku()));捕获参考数据的托管XOM应该独立于支持上下文数据的XOM类的核心集。 然后,可以独立于其他托管XOM资源部署参考数据XOM存档。 图7显示了采购订单验证决策服务的部署,该服务使用两个单独的资源: acme-shipping-xom.zip (包含XOM类的核心集)和reference-data-xom.zip (封装了必需的参考)数据)。
图7.规则执行服务器中的示例托管XOM
设计注意事项
复查以下注意事项,以确定是否采用文件资源解决方案作为参考数据的存储库:
- 变更的影响 :更改参考数据涉及更改为可部署的Java工件。 它不会影响服务实现,无需重新部署。 更新仍仅限于由Rule Execution Server组件管理的工件。
- 参考数据过滤逻辑 :当参考数据过滤规则可能发生更改或很复杂时,与在决策服务中对数据过滤进行硬编码相比,将数据加载到规则集中具有一些优势。 它允许规则在不重新部署服务实现的情况下得以发展,并且不会将业务逻辑放入服务层代码中。 但是,筛选规则中的大量复杂性可能是单独规则集的候选者。
- 更改频率 :对参考数据的更改频率应该较低,可能一年一次。 因为对参考数据的更改需要XOM的重新部署,通常需要一些批准和代码更改,所以不要对高度动态的数据集使用此方法。 同样,治理过程应提供有关如何对参考数据实施更改的特定指导。
- 参考数据大小 :参考数据的典型大小为几兆字节。 通常可以在运行时加载全部或部分内容,而不会占用Java虚拟机(JVM)堆内存。 Excel电子表格或纯文本文件通常支持轻松处理大量数据。
- 资源可用性 :有时,用于实施和管理参考数据数据库的硬件资源或人力资源稀缺,难以保护或不可用。 在这些类型的环境中,或者当额外的管理开销对业务用户而言是不适当的时,基于文件的方法为业务用户提供了一种快速的方法来维护与其相关的数据,并且更改保持在规则范围内。
- 数据可用性 :如果将数据部署在XOM中,则对远程数据源没有依赖性。 这种方法克服了规则集中远程数据访问的一些缺点(例如异常管理)。 如果参考数据大小无法在Decision Center中作为规则实施,则可以选择其他方法。
捕获规则中的参考数据
乍一看,IBM ODM中的决策表看起来像参考数据表。 因此,您可能想知道是否可以仅利用规则来捕获其参考数据,并通过规则集部署数据。 您可能出于以下原因选择此方法:
- 保存一个决策中心的单一存储库,以存储和管理与业务策略的实现相关的所有工件:业务用户必须仅学习一个用户界面来管理其业务决策,并且可以通过该界面执行所有更新。
- 涉及和管理单个运行时工件(RuleApp)以部署和运行业务策略:此方法简化了体系结构和变更管理。
- 避免规则和参考数据之间的任何同步问题:由于参考数据是与规则集一起部署的,因此就业务规则的定义而言,过早或过晚地更新都没有风险。
如果您在本教程中使用“排除受限项目”规则示例,则组件组织如图8所示。
图8.在规则集中捕获参考数据

实施实例
因为在规则集中的多个规则任务中可能需要参考数据(并且可能在多个规则集中),所以决策表的实现不应绑定到特定的BOM类。 而是将其与通用规则集变量关联以使其可重用。 在图9的示例中考虑以下可能的实现:
图9.支持参考数据决策表的变量
为了支持图1中决策表示例的定义,此实现示例使用两个规则集变量,一个称为state ,另一个称为restricted SKUs ,这是SKU字符串值的集合。
使用这些变量,您可以在图10中构建决策表以表示参考数据:
图10.决策表实现参考数据
然后,您可以将表封装在一个简单的子流中,如果需要可以重用。 为了使表正确启动,在运行子流之前,必须使用目标状态初始化state变量。 在此示例中,使用以下语句用购买者的国家住所值初始化状态变量:
set state to the state of residence of 'the buyer' ;运行参考数据表后,您可以利用结果来收集排除项。 清单1中最初呈现的规则然后类似于清单5中的示例:
清单5.在规则中捕获参考数据的实现示例
definitions
set item to an item in the line items of 'the PO';
if
the SKU of item is one of 'restricted SKUs'
then
add item to the exclusions of 'the PO';
with reason "cannot ship item to the buyer's state";设计注意事项
在考虑在规则中捕获参考数据时,请仔细权衡以下几点:
- 参考数据的更改频率应合理。 理想情况下,频率应与其他业务规则相当或更低。 尽管部署规则更改比应用程序代码更改要轻得多,但是与更新数据库内容相比,它涉及的更多。
- 参考数据的大小应合理。 尽管IBM ODM可以轻松容纳涉及成千上万条规则的规则集(使用IBM ODM V8.5.1中的Decision Engine更加有效),但是您不希望规则集的大小和执行时间由参考数据控制。
- 表示为参考数据的信息不应直接和唯一地与输入上下文数据中的元素相关联。 例如,收集怀疑被欺诈的帐号的黑名单并不是决策表的理想选择。 因为它直接依赖于上下文数据(客户帐号),所以该列表很可能与前面提到的两点相抵触:它比业务策略更频繁地更改,并且其大小最终变得非常大。
- 规则的所有者还应拥有参考数据。 否则,参考数据所有者必须包含在IBM ODM决策管理流程中,并学习如何编写和维护规则,否则规则所有者必须主动收集和更新参考数据表。
- 理想情况下,规则捕获的参考数据应仅在使用它们的规则集范围内相关。 特别是,不应从另一个存储库(例如外部数据库或文档)复制参考数据,这可能会导致数据不一致,除非从外部源自动生成规则。
- 相反,重要的是要意识到,规则捕获的参考数据不容易被其他系统或应用程序查询,就像从数据库中一样。 虽然Decision Center API允许检索和访问规则和决策表实体的定义,但它需要相对复杂的自定义代码,并且对于报告活动以外的任何内容,都将产生无法接受的性能。
除了通过决策中心直接管理参考数据规则外,以下两节还提出了一些替代方法,这些方法对于大型数据或从数据源自动提取的数据很有用。
办公室规则解决方案
IBM ODM的Office规则解决方案组件提供了Microsoft Office加载项,以允许在Microsoft Office文档中创建和编辑业务规则。 从决策中心,业务用户可以将规则项目中的规则发布到称为RuleDocs的Microsoft Office文档中,通过Microsoft Word和Microsoft Excel脱机处理文档,然后通过将RuleDocs导入回IBM ODM中来更新Decision Center项目。 对于已经使用Office的规则解决方案来管理规则的项目,您还可以使用它来管理参考数据决策表。
考虑Office规则解决方案的以下优点:
- 当参考数据由不直接参与决策服务维护的部门拥有时,RuleDocs提供了一种简单的方法,使外部部门可以对数据进行调整,而无需投资学习如何使用决策中心用户界面及其相关的治理流程。
- 与使用Decision Center相比,在Excel电子表格中管理大型决策表可以证明更有效的用户体验。 您和您的团队可能会发现,使用Excel而不是Decision Center导航大型表更容易,从而可以滚动和调整列和行的大小。 如果使用大型表,Rule Solutions for Office提供了一种更轻松的方式一次查看表中的所有数据,尽管不一定比在Decision Center中完成相同的操作更快。
请考虑Office规则解决方案的以下限制:
- 适用于IBM ODM V 8.7和更早版本的Office规则解决方案正式支持Microsoft Excel和Word版本2007和2010。不正式支持Microsoft Office 2013。
- IBM ODM on Cloud不支持Office Rule Rule Solutions。
自动化规则生成
代替手动创建和管理,可以在提取规则集之前从数据源自动生成代表参考数据的规则。 规则自动生成过程可以使用示例中心:决策表的数据源中演示的Decision Center API。 作为规则集提取脚本的第一步,可以按需或及时执行规则生成。
大多数时候,您会发现用于规则生成的数据来自数据库。 但是,当应用程序需求改为需要数据文件时,您可以将文件存储为资源,这是规则项目的一部分。 这种方法可确保参考数据文件始终与规则同步,并在决策中心存储库中正确版本化。
清单6显示了如何在给定文件名和扩展名的情况下,从Decision Center存储库中的规则项目中检索资源元素,并假定Decision Center会话参数已正确连接到所需的规则项目。
清单6.从规则项目获取资源元素
IlrResource getTableResource(IlrSession session,
String basename,
String extension)
throws IlrRoleRestrictedPermissionException,
IlrObjectNotFoundException
{
EClass eclass = session.getBrmPackage().getResource();
IlrSearchCriteria criteria = new IlrDefaultSearchCriteria(eclass);
for (IlrElementDetails element : session.findElementDetails(criteria)) {
IlrResource resource = (IlrResource) element;
if (resource.getName().equals(basename) &&
resource.getExtension().equals(extension)) {
return resource;
}
}
return null;
}清单6的示例中的方法返回的资源对象的getBody方法允许您检索文件的内容(请参见IlrResource类文档)。 通过参考数据文件的内容,您可以使用Decision Center API创建并填充决策表。
绩效影响
不出所料,将参考数据捕获为规则会影响规则管理和规则执行时间。
创作与维护
很大的决策表(例如,几千行)需要大量时间才能加载到规则设计器或决策中心中。 例如,在示例应用程序服务器上打开具有10,000行的决策表以在Decision Center中进行编辑可能需要5到10分钟,从而排除了对工件的交互式编辑。 在规则设计器,决策中心或Office的规则解决方案中,打开较大的表也可能导致内存不足异常。
决策表创作和管理的已发布好的做法是将它们限制在500行以下(请参阅“参考”部分中的决策表中的行数限制)。 对于具有建议的500行限制的几倍的表,您可以通过简单的解决方法将原始表分解为更小,更易于管理的卡盘。
执行
通常,如果使用决策引擎,则决策表的性能会随着表中行数的增加而扩展。 考虑使用决策表进行测试的结果,该决策表的结构类似于图11所示的结构(本质上是一个条件列和一个动作列),使用不同的行数,并在决策表中查找大量不同的值表。
本教程中用作参考的执行时间基于一个具有10行的示例表。 图11显示了其他表(分别具有100、1000和10000行)的执行时间,相对于10行的执行时间表示。
图11.不同大小的引用表的执行时间比较
该图表明,在具有10、100或1000行的表中查找值没有显着差异。 在10,000行表中查找值仅比在10行表中花费高1.5倍。
作为执行性能的最终参考点,请考虑使用Java哈希表实现参考数据表比使用决策表快约400倍。
混合方式
作为Rule Execution Server可部署工件,用于管理参考数据的另一种选择是上一部分中的两个选择的混合。 它包括使用规则存储库创作和管理作为决策表的参考数据,然后从表中生成参考数据XOM资源,以便在需要更新时重新部署它。 此方法基于以下步骤:
- 如在规则中捕获参考数据中所述,捕获参考数据并将其保存在决策表中。
- 规则集生成使用规则集提取器,该提取器从规则集存档中过滤出参考数据表。
- 参考数据XOM资源归档文件是根据决策表的内容生成的,并使用Decision Center API检索源表。 然后,使用决策表API解析和处理它们(请参见
IlrDTModel及其关联的类)。
考虑混合方法的好处:
- 捕获和管理参考数据,并在规则存储库中创建版本。 您无需外部管理系统即可获得参考数据,从而简化了整个决策管理流程。
- 在运行时,通过XOM访问参考数据,这比通过执行决策表更有效。 它允许更干净地集成到BOM中。
但是,混合方法需要投入大量资金,针对Decision Center API编写一些不平凡的自定义代码,该代码将决策表转换为XOM存档,并将XOM存档自动部署到Rule Execution Server。
Also, IBM ODM on Cloud does not allow deploying a customized Decision Center enterprise archive (EAR) file, and the IBM ODM on Cloud Decision Center does not allow you to open remote connections through the IlrSession API. Therefore, this option cannot be applied to IBM ODM on Cloud.
Harnessing the reference data in rules
After you choose a method to store the reference data for a decision, consider designs for how to incorporate the reference data into the ruleset.
The first option consists of filtering the reference data to some extent and enriching the context data with the resulting set. For example, the filtering and enrichment can be one or several attributes or flags that you add to the context data to represent more characteristics of the context data that are derived from the reference data. In the example in this tutorial, imagine that each item instance is enriched with the list of states in which it is restricted. Essentially, the context BOM object gets populated from the reference data through a transformation. With this approach, you must pay attention to avoid couching business logic in the transformation.
As a variant, another option is creating more business objects and adding them to the model to represent the reference data. These objects can be populated from the reference data and injected into the rule execution context.
Regardless of the chosen design, defer the access the reference data to when it is needed in the decision. It is common that a business decision has many paths in its logic, and not all the paths require access to all the reference data elements. Consider just-in-time access to the reference data and properly caching the data after it is retrieved.
结论
This tutorial presented two approaches to manage reference data with resource files when the Rule Execution Server cannot access an external data source. The first approach relies on rule project resources to generate reference data as decision tables in the ruleset. The second approach uses files that are deployed with the XOM resource to initialize a Java object singleton pattern.
You can apply the examples and approaches that you learned to your work with decision services.
致谢
The authors would like to thank Franck Delporte and Peter Holtzman for their review of this tutorial and their suggestions.
翻译自: https://www.ibm.com/developerworks/bpm/bpmjournal/1512_berlandier1-trs/1512_berlandier1.html
实现简单数据库 嵌入式

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)