YOLOv8+DeepSort+PyQt+UI(yolov8目标跟踪+GUI界面)目标跟踪+语义分割+姿态识别 三合一 计算机视觉
。,并将姿态识别与语义分割相结合。近年来,计算机视觉和目标检测技术发展迅猛,其中YOLOv8和DeepSort成为热门的目标跟踪算法。这两个算法的结合,加上PyQt的强大界面设计功能,可以为用户带来全新的图像处理和目标跟踪体验。本文将介绍如何使用YOLOv8+DeepSort+PyQt+UI实现目标跟踪与GUI界面的完美结合。首先,让我们了解一下YOLOv8和DeepSort算法的原理和特点。YO
YOLOv8+DeepSort+PyQt+UI: 实现目标跟踪与友好界面的完美结合
。
语义分割
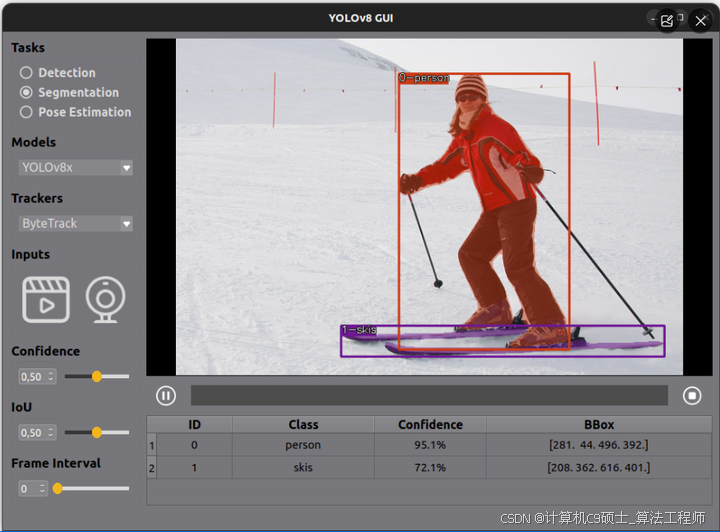
可对姿态识别检测
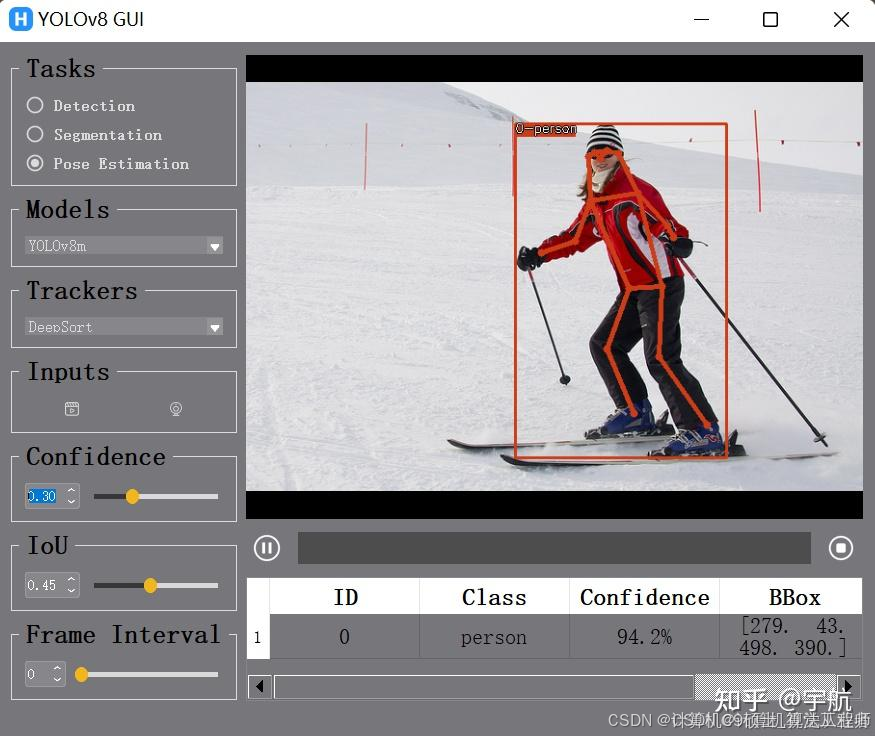
目标检测
,并将姿态识别与语义分割相结合。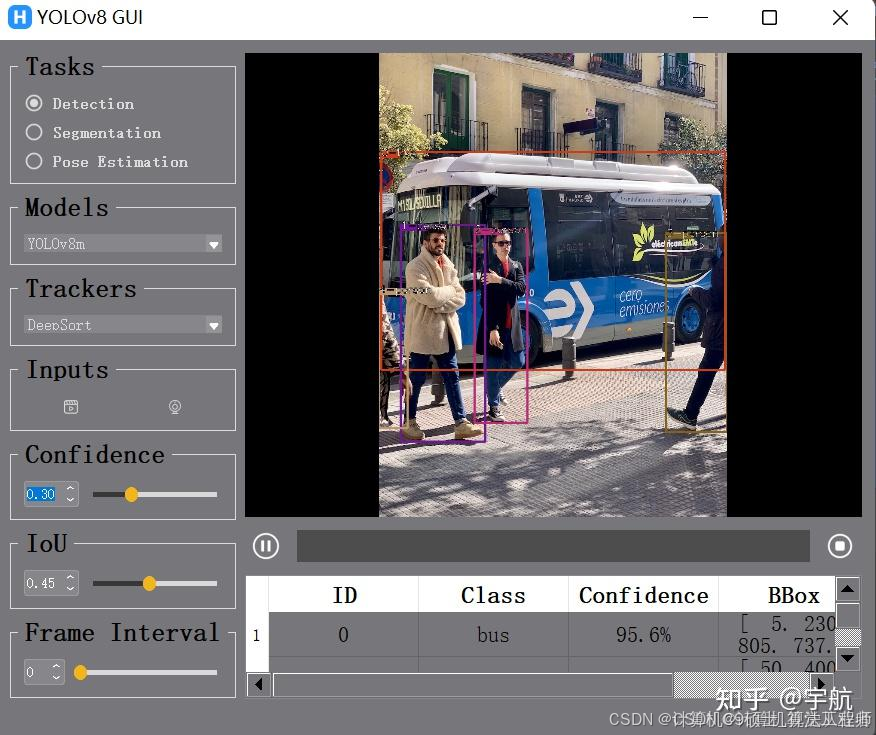
近年来,计算机视觉和目标检测技术发展迅猛,其中YOLOv8和DeepSort成为热门的目标跟踪算法。这两个算法的结合,加上PyQt的强大界面设计功能,可以为用户带来全新的图像处理和目标跟踪体验。本文将介绍如何使用YOLOv8+DeepSort+PyQt+UI实现目标跟踪与GUI界面的完美结合。

首先,让我们了解一下YOLOv8和DeepSort算法的原理和特点。YOLOv8是一种基于卷积神经网络的目标检测算法,其快速且准确地检测出图像中的多个目标。DeepSort则是一种基于深度学习的目标跟踪算法,通过对目标的特征进行编码和匹配,实现对目标在视频序列中的连续跟踪。将这两个算法结合在一起,可以实现对视频流中多个目标的实时跟踪与定位。
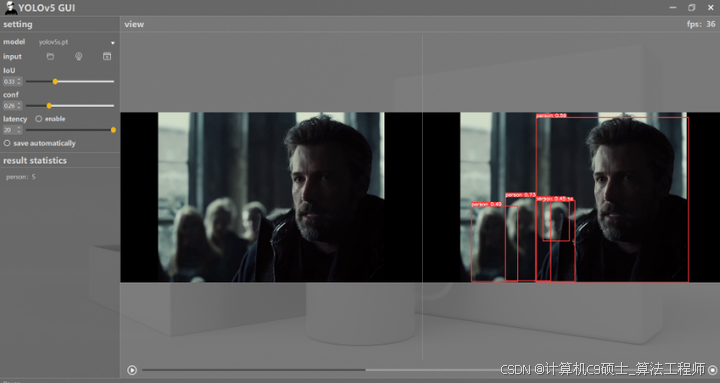
接下来,我们考虑如何将这些算法与PyQt的UI设计功能结合起来。PyQt是一个功能强大且易于使用的Python图形用户界面框架,可以帮助我们创建友好的用户界面。通过PyQt,我们可以设计出一个直观而丰富的界面,使用户能够轻松地选择视频流,调整算法参数,并实时查看目标跟踪结果。
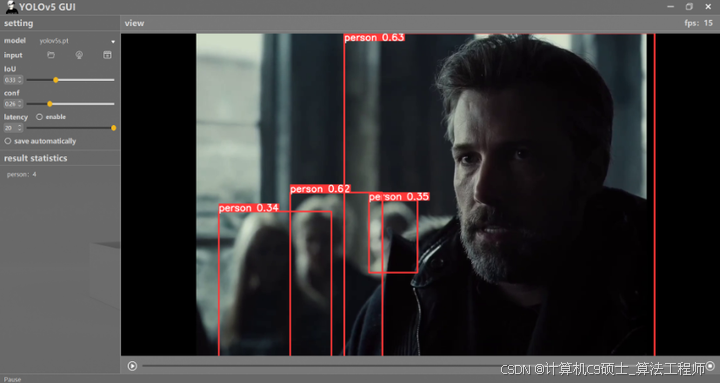
在界面设计中,我们可以添加一些常用的功能,比如视频流选择按钮、开始/停止按钮、目标跟踪结果显示框等。用户可以通过点击按钮选择要进行目标跟踪的视频流,点击开始按钮后,算法将实时对视频流中的目标进行跟踪,并将结果显示在界面上。此外,还可以提供一些额外的功能,比如目标识别结果的保存和导出等,以增强用户的使用体验。
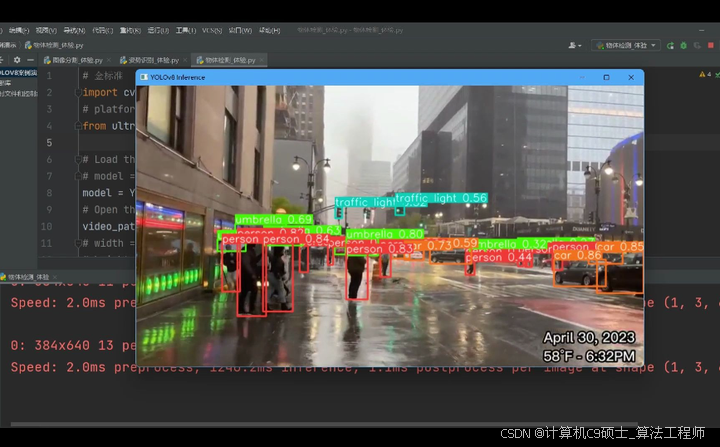
通过YOLOv8+DeepSort+PyQt+UI,用户不仅可以方便地进行目标跟踪,还能通过友好的界面设计进行更多的图像处理操作。他们可以选择不同的视频流进行实时跟踪,并在界面上观察到每个目标的位置、速度和轨迹等信息。用户也可以通过调整算法参数,优化目标跟踪结果并获得更准确的定位和匹配效果。
综上所述,YOLOv8+DeepSort+PyQt+UI的结合为用户提供了一个强大的目标跟踪和图像处理平台。它不仅实现了高效的目标检测和跟踪功能,还通过友好的用户界面设计提供了更多的控制和交互方式。希望这个文章能够帮助读者更好地理解和应用这个强大的技术组合,从而推动计算机视觉和目标跟踪领域的发展。一个 GUI 应用程序,它使用 YOLOv8 进行对象检测/跟踪、人体姿势估计/图像、视频或相机跟踪。
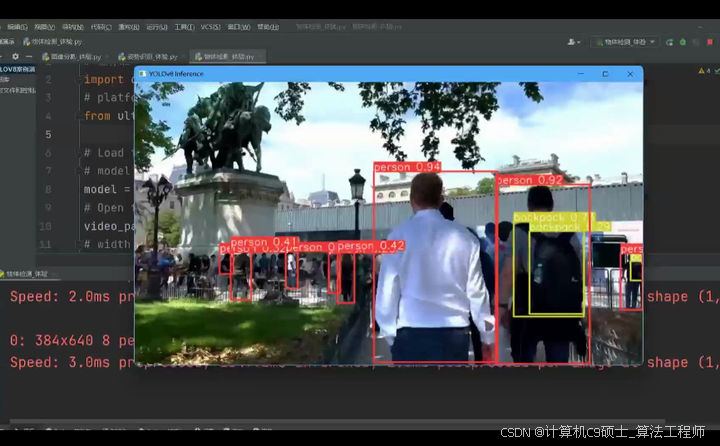
关键代码:
from src.qt.stream.video_capture import CameraCaptureThread
from src.qt.stream.visualize import VideoVisualizationThread
from src.qt.stream.ai_worker import AiWorkerThread
from src.ui.main_window import Ui_MainWindow
from src.qt.video.video_worker import FileProcessThread
from PyQt5 import QtGui, QtWidgets
from PyQt5.QtCore import Qt
import sys
import numpy as np
import cv2 as cv
class MainWindow(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.setupUi(self)
self.ai_thread = AiWorkerThread()
self.camera_thread = CameraCaptureThread()
self.display_thread = VideoVisualizationThread()
self.file_process_thread = FileProcessThread()
self.conf_thr = 0.3
self.iou_thr = 0.45
self.frame_interval = 0
self.model_name = "yolov8n"
self.ai_task = "object_detection"
self.tracker_name = "deepsort"
self.init_slots()
self.buttons_states("waiting_for_setting")
def init_slots(self):
self.radioButton_det.toggled.connect(lambda: self.get_ai_task(self.radioButton_det))
self.radioButton_pose.toggled.connect(lambda: self.get_ai_task(self.radioButton_pose))
self.radioButton_seg.toggled.connect(lambda: self.get_ai_task(self.radioButton_seg))
self.doubleSpinBox_conf.valueChanged.connect(lambda x: self.update_parameter(x, 'doubleSpinBox_conf'))
self.doubleSpinBox_interval.valueChanged.connect(lambda x: self.update_parameter(x, 'doubleSpinBox_interval'))
self.doubleSpinBox_iou.valueChanged.connect(lambda x: self.update_parameter(x, 'doubleSpinBox_iou'))
self.horizontalSlider_conf.valueChanged.connect(lambda x: self.update_parameter(x, 'horizontalSlider_conf'))
self.horizontalSlider_interval.valueChanged.connect(lambda x: self.update_parameter(x, 'horizontalSlider_interval'))
self.horizontalSlider_iou.valueChanged.connect(lambda x: self.update_parameter(x, 'horizontalSlider_iou'))
self.comboBox_model.currentTextChanged.connect(self.choose_model)
self.comboBox_tracker.currentTextChanged.connect(self.choose_tracker)
self.pushButton_cam.clicked.connect(self.process_camera)
self.pushButton_file.clicked.connect(self.process_file)
self.pushButton_stop.clicked.connect(self.stop_video)
self.pushButton_play.clicked.connect(self.file_process_thread.toggle_play_pause)
def resizeEvent(self, event:QtGui.QResizeEvent):
self.screen_size = (self.label_display.width(), self.label_display.height())
self.display_thread.get_screen_size(self.screen_size)
self.file_process_thread.get_screen_size(self.screen_size)
QtWidgets.QMainWindow.resizeEvent(self, event)
def update_parameter(self, x, flag):
if flag == 'doubleSpinBox_conf':
self.horizontalSlider_conf.setValue(int(x*100))
self.conf_thr = float(x)
elif flag == 'doubleSpinBox_interval':
self.horizontalSlider_interval.setValue(int(x))
self.frame_interval = int(x)
self.file_process_thread.set_frame_interval(self.frame_interval)
elif flag == 'doubleSpinBox_iou':
self.horizontalSlider_iou.setValue(int(x*100))
self.iou_thr = float(x)
elif flag == 'horizontalSlider_conf':
self.doubleSpinBox_conf.setValue(x/100)
self.conf_thr = float(x/100)
elif flag == 'horizontalSlider_interval':
self.doubleSpinBox_interval.setValue(x)
self.frame_interval = int(x)
self.file_process_thread.set_frame_interval(self.frame_interval)
elif flag == 'horizontalSlider_iou':
self.doubleSpinBox_iou.setValue(x/100)
self.iou_thr = float(x/100)
if self.ai_thread.isRunning:
self.ai_thread.set_confidence_threshold(self.conf_thr)
self.ai_thread.set_iou_threshold(self.iou_thr)
if self.file_process_thread.isRunning:
self.file_process_thread.set_confidence_threshold(self.conf_thr)
self.file_process_thread.set_iou_threshold(self.iou_thr)
def get_ai_task(self, btn):
if btn.text() == 'Detection':
if btn.isChecked() == True:
self.ai_task = "object_detection"
elif btn.text() == 'Pose Estimation':
if btn.isChecked() == True:
self.ai_task = "pose_detection"
elif btn.text() == 'Segmentation':
if btn.isChecked() == True:
self.ai_task = "segmentation"
def choose_model(self):
self.model_name = self.comboBox_model.currentText()
self.model_name = self.model_name.lower()
def choose_tracker(self):
self.tracker_name = self.comboBox_tracker.currentText()
self.tracker_name = self.tracker_name.lower()
def buttons_states(self, work_state):
if work_state == "waiting_for_setting":
self.radioButton_det.setDisabled(False)
self.radioButton_pose.setDisabled(False)
self.radioButton_seg.setDisabled(False)
self.comboBox_model.setDisabled(False)
self.comboBox_tracker.setDisabled(False)
self.pushButton_cam.setDisabled(False)
self.pushButton_file.setDisabled(False)
self.pushButton_play.setDisabled(True)
self.pushButton_stop.setDisabled(True)
self.doubleSpinBox_conf.setDisabled(False)
self.horizontalSlider_conf.setDisabled(False)
self.doubleSpinBox_interval.setDisabled(False)
self.horizontalSlider_interval.setDisabled(False)
self.doubleSpinBox_iou.setDisabled(False)
self.horizontalSlider_iou.setDisabled(False)
self.doubleSpinBox_interval.setDisabled(False)
self.horizontalSlider_interval.setDisabled(False)
elif work_state == "processing_on_camera":
self.pushButton_play.click
self.radioButton_det.setDisabled(True)
self.radioButton_pose.setDisabled(True)
self.radioButton_seg.setDisabled(True)
self.comboBox_model.setDisabled(True)
self.comboBox_tracker.setDisabled(True)
self.pushButton_cam.setDisabled(True)
self.pushButton_file.setDisabled(True)
self.pushButton_play.setDisabled(True)
self.pushButton_stop.setDisabled(False)
self.doubleSpinBox_conf.setDisabled(False)
self.horizontalSlider_conf.setDisabled(False)
self.doubleSpinBox_interval.setDisabled(True)
self.horizontalSlider_interval.setDisabled(False)
self.doubleSpinBox_iou.setDisabled(False)
self.horizontalSlider_iou.setDisabled(False)
self.doubleSpinBox_interval.setDisabled(True)
self.horizontalSlider_interval.setDisabled(True)
elif work_state == "processing_on_file":
self.radioButton_det.setDisabled(True)
self.radioButton_pose.setDisabled(True)
self.radioButton_seg.setDisabled(True)
self.comboBox_model.setDisabled(True)
self.comboBox_tracker.setDisabled(True)
self.pushButton_cam.setDisabled(True)
self.pushButton_file.setDisabled(True)
self.pushButton_play.setDisabled(False)
self.pushButton_stop.setDisabled(False)
self.doubleSpinBox_conf.setDisabled(False)
self.horizontalSlider_conf.setDisabled(False)
self.doubleSpinBox_interval.setDisabled(False)
self.horizontalSlider_interval.setDisabled(False)
self.doubleSpinBox_iou.setDisabled(False)
self.horizontalSlider_iou.setDisabled(False)
self.doubleSpinBox_interval.setDisabled(False)
self.horizontalSlider_interval.setDisabled(False)
def process_camera(self):
video_source = self.get_stream_source()
print("SOURCE", video_source)
if video_source is not None:
self.ai_thread.set_start_config(
ai_task=self.ai_task,
model_name=self.model_name,
tracker_name=self.tracker_name)
self.camera_thread.set_start_config(video_source=video_source)
self.display_thread.set_start_config([self.label_display.width(),self.label_display.height()])
self.camera_thread.send_frame.connect(self.display_thread.get_fresh_frame)
self.camera_thread.send_frame.connect(self.ai_thread.get_frame)
self.ai_thread.send_ai_output.connect(self.display_thread.get_ai_output)
self.display_thread.send_displayable_frame.connect(self.update_display_frame)
self.display_thread.send_ai_output.connect(self.update_statistic_table)
self.display_thread.send_thread_start_stop_flag.connect(self.buttons_states)
self.ai_thread.start()
self.display_thread.start()
self.camera_thread.start()
def process_file(self):
img_fm = (".tif", ".tiff", ".jpg", ".jpeg", ".gif", ".png", ".eps", ".raw", ".cr2", ".nef", ".orf", ".sr2", ".bmp", ".ppm", ".heif")
vid_fm = (".flv", ".avi", ".mp4", ".3gp", ".mov", ".webm", ".ogg", ".qt", ".avchd")
file_list = " *".join(img_fm+vid_fm)
file_name, _ = QtWidgets.QFileDialog.getOpenFileName(self, "choose an image or video file", "./data", f"Files({file_list})")
if file_name:
self.file_process_thread.set_start_config(
video_path=file_name,
ai_task=self.ai_task,
screen_size=[self.label_display.width(),self.label_display.height()],
model_name=self.model_name,
tracker_name=self.tracker_name,
confidence_threshold=self.conf_thr,
iou_threshold=self.iou_thr,
frame_interval=self.frame_interval)
self.file_process_thread.send_ai_output.connect(self.update_statistic_table)
self.file_process_thread.send_display_frame.connect(self.update_display_frame)
self.file_process_thread.send_play_progress.connect(self.progressBar_play.setValue)
self.file_process_thread.send_thread_start_finish_flag.connect(self.buttons_states)
self.file_process_thread.start()
def stop_video(self):
self.display_thread.stop_display()
self.ai_thread.stop_process()
self.camera_thread.stop_capture()
self.file_process_thread.stop_process()
def update_display_frame(self, showImage):
self.label_display.setPixmap(QtGui.QPixmap.fromImage(showImage))
def clean_table(self):
while (self.tableWidget_results.rowCount() > 0):
self.tableWidget_results.removeRow(0)
def update_statistic_table(self, ai_output):
self.clean_table()
self.tableWidget_results.setRowCount(0)
if ai_output == []:
return
for box in ai_output:
each_item = [str(box["id"]),str(box["class"]), "{:.1f}%".format(box["confidence"]*100), str(box["bbox"])]
row = self.tableWidget_results.rowCount()
self.tableWidget_results.insertRow(row)
for j in range(len(each_item)):
item = QtWidgets.QTableWidgetItem(str(each_item[j]))
item.setTextAlignment(Qt.AlignHCenter | Qt.AlignVCenter)
self.tableWidget_results.setItem(row, j, item)
def get_stream_source(self):
video_source, okPressed = QtWidgets.QInputDialog.getText(self, "Input Camera_ID or RTSP", "Camera ID or RTSP")
if okPressed:
if video_source.isdigit():
return int(video_source)
else:
return video_source
else:
return None
if __name__ == '__main__':
app = QtWidgets.QApplication(sys.argv)
mainWindow = MainWindow()
mainWindow.show()
sys.exit(app.exec_())
所有使用 ONNX 中的 YOLOv8 模型执行检测、姿势和分割的 python 脚本。
支持的 AI 任务:
检波
姿态估计
分割
支持的型号:
YOLOv8n的
YOLOv8s
YOLOv8分钟
YOLOv8l
YOLOv8x
支持的跟踪器:
深度排序
字节跟踪
支持的输入源:
本地文件:图像或视频
照相机
RTSP-流
安装
使用 pip 安装所需的软件包:
pip install -r requirements.txt
或使用 conda:
conda env create -f environment.yml
activate the conda environment
conda activate yolov8_gui
下载权重
下载模型权重:
python download_weights.py
模型文件保存在 weights/ 文件夹中。
python download_weights.py
跑
python main.py
使用 pip 安装所需的软件包:
集成YOLOv8用于目标检测与跟踪、DeepSort用于对象跟踪、以及PyQt用于构建用户界面的应用程序,并且同时支持语义分割和姿态估计,是一个相对复杂的任务。由于YOLOv8在撰写此回答时并不是一个已发布的模型 将基于YOLOv5或类似的结构来提供一个概念性的代码框架,然后你可以根据实际的YOLOv8 API进行调整。
以下是一个简化的示例代码,展示如何使用YOLOv5(作为YOLOv8的替代)、DeepSort、PyQt5以及OpenPose(用于姿态估计)和Segmentation模型(例如DeepLabV3+)结合来创建一个应用程序。请注意,你需要安装相关的依赖库:
pip install torch torchvision torchaudio opencv-python-headless PyQt5 deep_sort_pytorch openpose
首先,确保你有适用于YOLOv5的Python包,DeepSort,以及适合你的项目的其他模型如OpenPose和DeepLabV3+。
下面是一个简化版的概念验证代码:
import sys
from PyQt5.QtWidgets import QApplication, QLabel, QVBoxLayout, QWidget
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import QTimer
import cv2
import numpy as np
from deep_sort import DeepSort # 假设这是DeepSort的导入方式
# 导入YOLOv5, OpenPose 和 Segmentation 模型
# from yolov5 import YOLOv5 # 替换为YOLOv8的实际导入方式
# from segmentation_model import SegmentationModel
# from openpose import OpenPose
class App(QWidget):
def __init__(self):
super().__init__()
self.initUI()
self.cap = cv2.VideoCapture(0) # 打开摄像头
# 初始化YOLOv5, DeepSort, OpenPose, Segmentation模型
# self.detector = YOLOv5() # 替换为YOLOv8初始化方法
self.tracker = DeepSort()
# self.open_pose = OpenPose()
# self.segmentation_model = SegmentationModel()
self.timer = QTimer()
self.timer.timeout.connect(self.nextFrameSlot)
self.timer.start(30)
def initUI(self):
self.setWindowTitle('YOLOv8+DeepSort with PyQt')
self.setGeometry(100, 100, 640, 480)
self.label = QLabel('Webcam here')
layout = QVBoxLayout()
layout.addWidget(self.label)
self.setLayout(layout)
def nextFrameSlot(self):
ret, frame = self.cap.read()
if ret:
# 使用YOLOv5进行目标检测
# boxes, scores, class_ids = self.detector.detect(frame)
# 使用DeepSort对检测结果进行跟踪
# tracked_boxes = self.tracker.update(boxes, scores, class_ids, frame)
# 使用OpenPose进行姿态估计
# pose_keypoints = self.open_pose.predict(frame)
# 使用Segmentation模型进行语义分割
# segmented_image = self.segmentation_model.predict(frame)
# 此处省略了具体的处理逻辑
self.displayImage(frame)
def displayImage(self, img):
qformat = QImage.Format_Indexed8
if len(img.shape) == 3: # rows[0], cols[1], channels[2]
if img.shape[2] == 4:
qformat = QImage.Format_RGBA8888
else:
qformat = QImage.Format_RGB888
outImage = QImage(img, img.shape[1], img.shape[0], img.strides[0], qformat)
outImage = outImage.rgbSwapped()
self.label.setPixmap(QPixmap.fromImage(outImage))
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = App()
ex.show()
sys.exit(app.exec_())
注意:上述代码只是一个基本框架,具体的目标检测、跟踪、姿态估计和语义分割部分需要根据你使用的具体模型API进行实现。对于YOLOv8的具体实现,你需要替换from yolov5 import YOLOv5部分为YOLOv8的实际加载方式。同样地,DeepSort、OpenPose和Semantic Segmentation模型的调用也需要依据各自的文档进行适当的配置和调用。
此外,为了完整运行这个应用,你还需要准备相应的预训练模型,并确保它们能够正确加载和使用。每个模型的预测结果如何整合到一起显示在界面上也是需要考虑的问题之一。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)