C++ OpenCV图像分割之KMeans方法
前言kmeans算法主要用来实现自动聚类,是一种非监督的机器学习算法,使用非常广泛。在opencv3.0中提供了这样一个函数,直接调用就能实现自动聚类,非常方便。API介绍double ...
前言
kmeans算法主要用来实现自动聚类,是一种非监督的机器学习算法,使用非常广泛。在opencv3.0中提供了这样一个函数,直接调用就能实现自动聚类,非常方便。
API介绍
double kmeans(InputArray data, int K, InputOutputArray bestLabels, TermCriteria criteria, int attempts, int flags, OutputArray centers=noArray() )
参数说明:
data: 需要自动聚类的数据,一般是一个Mat。浮点型的矩阵,每行为一个样本。
k: 取成几类,比较关键的一个参数。
bestLabels: 返回的类别标记,整型数字。
criteria: 算法结束的标准,获取期望精度的迭代最大次数
attempts: 判断某个样本为某个类的最少聚类次数,比如值为3时,则某个样本聚类3次都为同一个类,则确定下来。
flags: 确定簇心的计算方式。有三个值可选:KMEANS_RANDOM_CENTERS 表示随机初始化簇心。KMEANS_PP_CENTERS 表示用kmeans++算法来初始化簇心(没用过),KMEANS_USE_INITIAL_LABELS 表示第一次聚类时用用户给定的值初始化聚类,后面几次的聚类,则自动确定簇心。
centers: 用来初始化簇心的。与前一个flags参数的选择有关。如果选择KMEANS_RANDOM_CENTERS随机初始化簇心,则这个参数可省略。
代码演示
我们再新建一个项目名为opencv--kmeans,按照配置属性(VS2017配置OpenCV通用属性),然后在源文件写入#include和main方法.
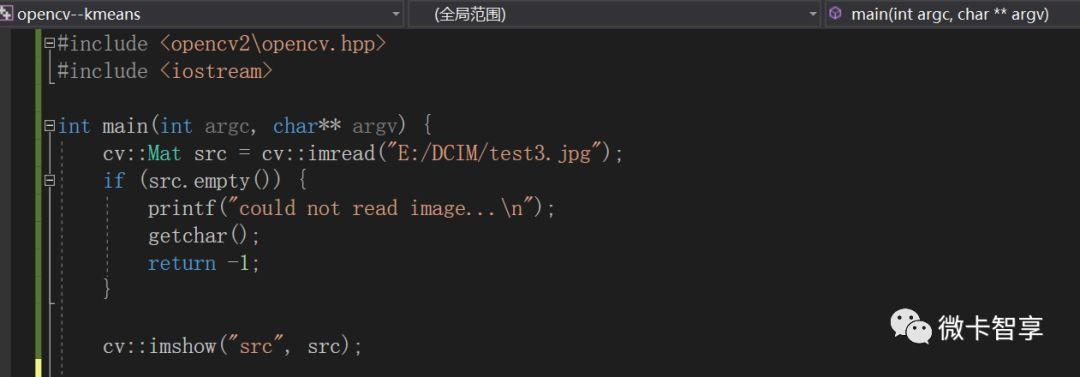
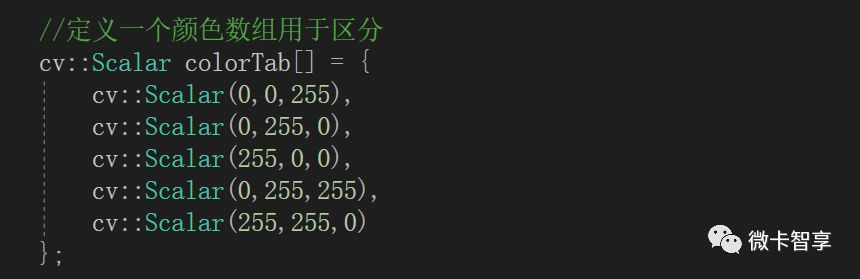
首先定义一个颜色数组用于后面分割图像用
获取源图像的宽度,高度以及颜色的通道数

定义KMeans方法用到的初始值

将源图上的RGB数据转换为样本数据

运行KMeans进行图像分割

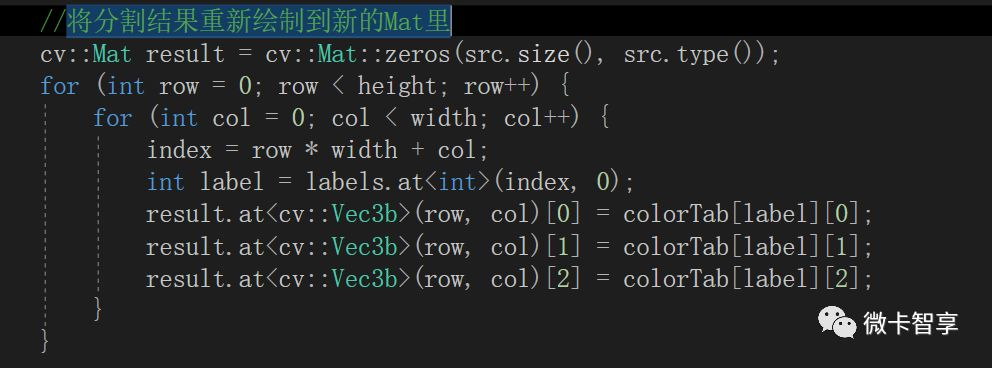
将分割结果重新绘制到新的Mat里
显示结果
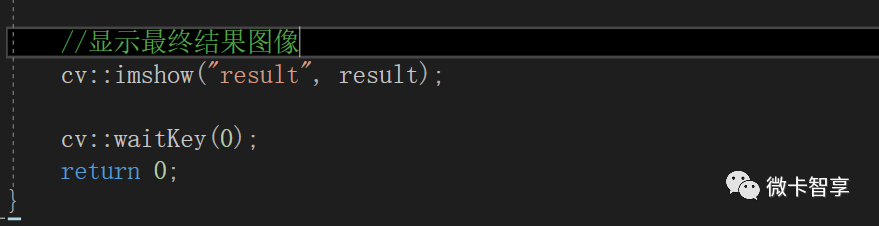
接下来我们看一下运行的效果
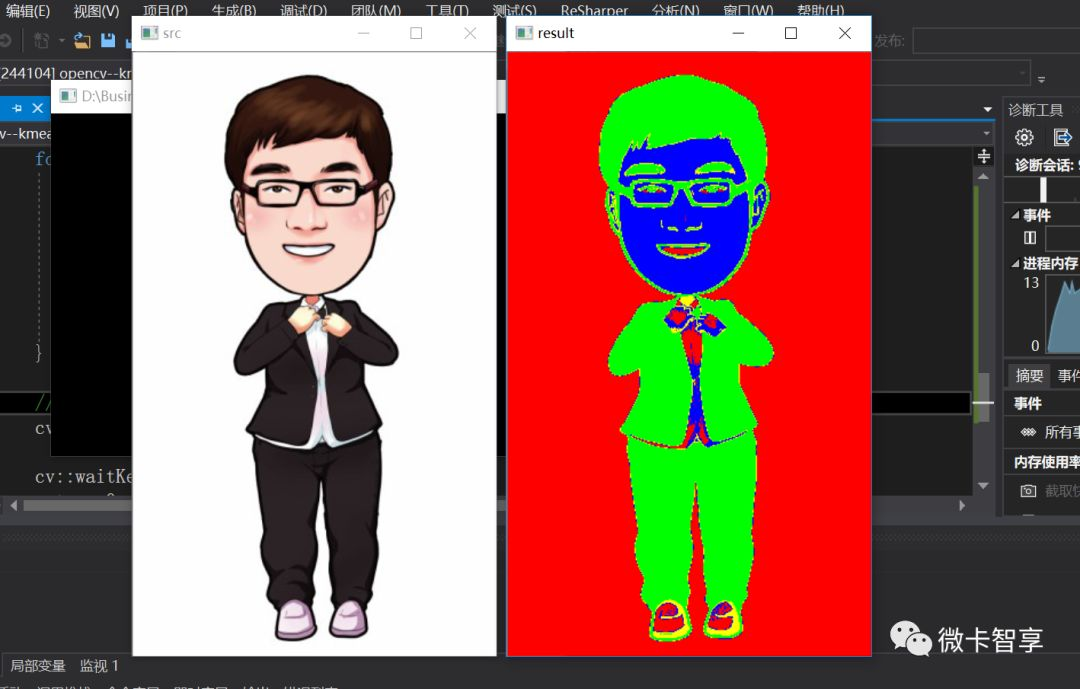
上面可以看到我们完美的把背景和我们的人物分割开了。
-END-
长按下方二维码关注微卡智享


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)