机器学习:交叉验证和网络搜索
指定希望调整的参数及其可能取值的范围。例如,对于随机森林模型,可以设置 `n_estimators`(树的数量)和 `max_depth`(树的深度)。交叉验证是评估模型性能的有效方法,可以减少过拟合风险。网格搜索则是优化模型超参数的有效手段,能够提高模型的整体表现。
交叉验证(Cross Validation)和网格搜索(Grid Search)是机器学习中的重要技术,通常用于评估模型性能和优化超参数。以下是对这两种技术的详细介绍。
一、交叉验证(Cross Validation)
交叉验证是一种模型评估技术,旨在确保模型的泛化能力。它通过反复训练和测试模型来给出一个更可靠的性能评估。
(一)主要步骤
1. 数据分割
将数据集分成多个子集(折叠,通常称为“folds”),常见的划分方式包括 K-fold 交叉验证和留一交叉验证(Leave-One-Out Cross Validation)。
K-fold 交叉验证:将数据集分为 K 等份,模型将在 K-1 份数据上训练,然后在剩下的 1 份上测试。这个过程重复 K 次,每次选择不同的 1 份作为测试集,最后取 K 次的平均性能作为模型的评估指标。
留一交叉验证:在每次迭代中使用整个数据集中的一个样本作为测试集,其余样本作为训练集。对于 N 个样本,留一交叉验证将进行 N 次训练和测试。
2. 模型评估
每次训练结束后,记录模型在测试集上的性能指标(如准确率、F1分数等)。
3. 性能汇总
最终,通过将所有折叠的性能指标取平均值来得到模型的整体性能评估。
(二)优点
更可靠的评估:通过在不同数据集上进行训练和测试,可以减少偶然性,提高评估的可靠性。
充分利用数据:避免数据浪费,尤其是在数据少的情况下,交叉验证可以充分利用每一条数据。
(三)示例代码
使用 `scikit-learn` 中的 K-fold 交叉验证示例:
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# 加载数据
data = load_iris()
X, y = data.data, data.target
# 定义模型
model = RandomForestClassifier()
# 进行 5-fold 交叉验证
scores = cross_val_score(model, X, y, cv=5)
print(f'交叉验证得分: {scores}')
print(f'均值: {scores.mean()}')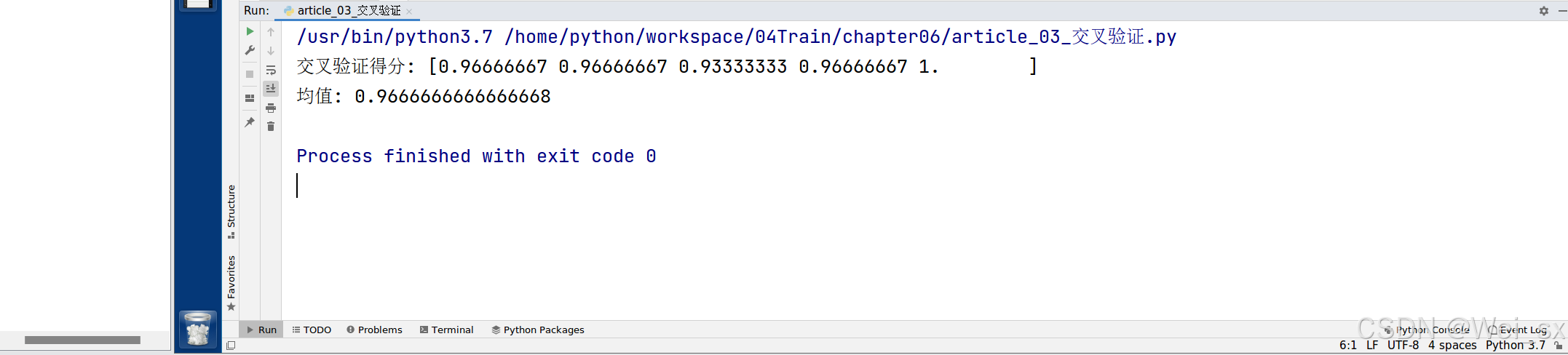
二、网格搜索(Grid Search)
网格搜索是一种超参数优化技术,用于系统地遍历多个超参数组合,以找到最优的超参数配置,从而提升模型性能。
(一)主要步骤
1. 定义参数网格
指定希望调整的参数及其可能取值的范围。例如,对于随机森林模型,可以设置 `n_estimators`(树的数量)和 `max_depth`(树的深度)。
2. 遍历组合
网格搜索会生成所有可能的超参数组合。
3. 模型评估
对于每一组超参数组合,使用交叉验证评估模型性能,以选择最佳的超参数。
4. 选出最佳组合
基于交叉验证的评估结果,选择使得模型性能最优的超参数组合。
(二)优点
系统性:可以全面探索超参数空间,找到最佳配置。
简单易用:易于实现,适用于很多不同模型。
(三)示例代码
使用 `scikit-learn` 中的网格搜索示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 加载数据
data = load_iris()
X, y = data.data, data.target
# 定义模型
model = RandomForestClassifier()
# 定义超参数网格
param_grid = {
'n_estimators': [1, 3, 5, 7],
'max_depth': [None, 10, 20]
}
# 初始化网格搜索
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy')
# 拟合模型
grid_search.fit(X, y)
# 输出最佳参数和对应得分
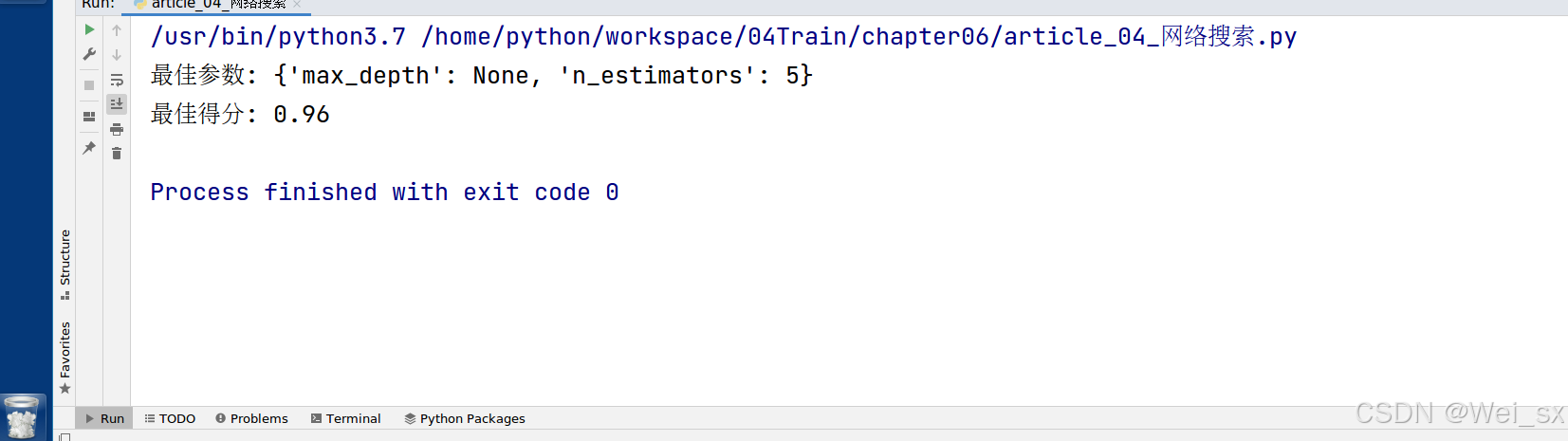
print(f'最佳参数: {grid_search.best_params_}')
print(f'最佳得分: {grid_search.best_score_}')
三、交叉验证与网格搜索的结合
交叉验证和网格搜索通常结合使用,通过网格搜索的每一组超参数配置,通过交叉验证来评估其性能。这种组合能够提供更全面的模型评估和优化,确保模型在未见数据上的泛化能力。
示例代码:
使用 `scikit-learn` 中交叉验证参数调优:
"""
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
对估计器的指定参数值进行详尽搜索
estimator:估计器对象
param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
fit:输入训练数据
score:准确率
结果分析:
bestscore__:在交叉验证中验证的最好结果
bestestimator:最好的参数模型
cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
"""
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1.获取数据
iris = load_iris()
# 2.数据基础处理
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2) #random_state=22
# 3.特征工程-数据预处理
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# x_test = transfer.fit_transform(x_test)
x_test = transfer.transform(x_test)
# 4.机器学习
# 4.1 实例化估计器
estimator = KNeighborsClassifier(n_neighbors=5)
# 4.2 模型寻找与调优-网格搜索和交叉验证
# 准备调超参数
param_dict = {'n_neighbors':[1,3,5]}
# 交叉验证参数调优:# cv=3:3折交叉验证,param_dict:超参数调优
estimator = GridSearchCV(estimator,param_grid=param_dict,cv=3)
# 4.2 模型训练
estimator.fit(x_train, y_train)
print('在交叉验证中验证的最好结果:\n',estimator.best_score_)
print('每次交叉验证后的准确率结果:\n',estimator.cv_results_)
print('最好的参数模型:\n',estimator.best_params_) # 调优
# 5.模型评估
# 5.1 预测,获得y_pre预测结果
y_pre = estimator.predict(x_test)
print("预测值:\n", y_pre)
# 结果比较
print('预测值和真实值对比:\n', y_pre == y_test)
# 5.2 准确率计算
socre = estimator.score(x_test, y_test)
print("准确率:\n", socre)
'''
结果:
在交叉验证中验证的最好结果:
0.9583333333333334
每次交叉验证后的准确率结果:
{'mean_fit_time': array([0.00051832, 0.00028976, 0.00025487]), 'std_fit_time': array([1.49858547e-04, 3.14985343e-05, 2.16353093e-05]), 'mean_score_time': array([0.00087778, 0.00091426, 0.00077049]), 'std_score_time': array([1.88614698e-04, 1.40531568e-04, 7.90822443e-05]), 'param_n_neighbors': masked_array(data=[1, 3, 5],
mask=[False, False, False],
fill_value='?',
dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}], 'split0_test_score': array([0.95 , 0.975, 0.975]), 'split1_test_score': array([0.925, 0.95 , 0.95 ]), 'split2_test_score': array([0.95 , 0.875, 0.95 ]), 'mean_test_score': array([0.94166667, 0.93333333, 0.95833333]), 'std_test_score': array([0.01178511, 0.04249183, 0.01178511]), 'rank_test_score': array([2, 3, 1], dtype=int32)}
最好的参数模型:
{'n_neighbors': 5}
预测值:
[2 1 1 2 2 0 0 1 2 2 0 1 0 1 0 2 2 2 1 0 1 0 1 2 1 0 1 2 1 2]
预测值和真实值对比:
[ True True True True True True True True True True True True
True True True True True True True True True True True True
True True True False True True]
准确率:
0.9666666666666667
'''
四、总结
交叉验证是评估模型性能的有效方法,可以减少过拟合风险。
网格搜索则是优化模型超参数的有效手段,能够提高模型的整体表现。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)