2025热门技术剖析!材料研究的“第四范式”:机器学习革新材料设计!
近年来,机器学习技术的迅猛发展为材料科学领域注入了革命性动力,推动研究范式从传统“试错法”向数据驱动模式转型。通过高效挖掘材料“成分-结构-性能”间的复杂关联规律,机器学习显著加速了新材料的定向设计与性能优化进程,成为材料基因工程与高通量计算的核心技术支柱。在原子与微观尺度建模方面,核心进展聚焦分子与晶体结构的智能化表征技术,系统解析SMILES字符串、库伦矩阵等分子描述符的构建方法,并结合Materials Project、COD等数据库,利用Pymatgen工具包实现晶体能带结构、弹性张量等跨尺度性质的自动化提取。跨尺度性能预测则依托集成学习与核函数映射技术,例如通过随机森林的特征重要性分析揭示双金属ORR催化活性的关键电子描述符,利用支持向量机(SVM)的高斯核变换解决高熵合金相态分类中的非线性可分问题,以及基于决策树的可解释性框架优化储氢合金成分设计。在工程应用层面,机器学习与增材制造的深度协同,通过动态调整加工参数和智能缺陷识别技术,大幅提升了复杂结构材料的制备精度。与此同时,超轻超硬材料的突破性设计(如承重能力达自重百万倍的新材料)得益于算法驱动的元素组合筛选与原子排列优化策略。材料研究的“第四范式”正加速形成:大语言模型(如DeepSeek)通过文献挖掘与实验方案生成赋能材料发现,量子计算与自主实验系统的深度融合将进一步突破复杂材料体系的探索极限。
机器学习材料专题目标:内容涵盖了从基础Python编程到常见的机器学习算法,并通过实际案例分析与项目实践,帮助学者理解并掌握如何将机器学习技术应用于材料与化学领域。课程设计注重理论与实践的结合,逐步深入,让学员在学习过程中不仅能够掌握相关算法,还能亲自动手解决材料科学中的实际问题。
1、掌握Python编程基础及其在科学计算中的应用:学会利用Python进行数据处理、模型构建与可视化,熟悉NumPy、Pandas等工具。
2、理解材料与化学中的机器学习方法:掌握线性回归、逻辑回归、决策树、支持向量机等常见算法的基本原理与应用。
3、应用机器学习解决材料科学问题:通过项目实践,深入理解数据采集、特征选择、模型训练与评估等步骤,学会使用sklearn等工具库完成任务。
4、了解材料数据的特征工程与数据库应用:学习如何表示分子结构与晶体结构,并了解常见材料数据库的使用方法。
5、提升实战能力并引导深入学习:通过多样化的项目实践案例,巩固课程内容,为后续深度学习等更复杂算法的学习打下基础。
机器学习材料专题主讲老师陈老师来自国内“985工程”顶尖高校材料物理与化学专业,长期从事材料科学、机器学习,未来互联网与命名数据网络,量子力学等领域。在多个国际高水平期刊上发表 SCI检索论文15余篇。国家发明专利一项,他的授课方式深入浅出,能够将复杂的理论知识和计算方法讲解得清晰易懂,受到学员们的一致认可和高度评价!
大纲内容:
第一天:材料机器学习基础与Python环境配置
第一天将系统讲解机器学习在材料科学中的应用背景与Python编程基础。分为如下几个部分:首先概述机器学习在材料与化学领域的核心价值,涵盖材料发现、性能预测等应用场景;其次将指导学员完成Vscode、Anaconda开发环境搭建,通过变量定义、控制流语句等基础语法教学,掌握函数封装、类与对象构建及模块化编程的进阶技巧;最后聚焦科学数据处理工具链,系统学习NumPy矩阵运算、Pandas数据分析、Matplotlib/Seaborn可视化技术及文件系统操作,为材料数据建模奠定工程基础。
【理论内容】
1. 机器学习概述
2. 材料与化学中的常见机器学习方法
3. 应用前沿
【实操内容】
1)Python基础
1)开发环境搭建
2)变量和数据类型
3)控制流
2)Python基础(续)
1)函数
2)类和对象
3)模块
3. Python科学数据处理
1)NumPy
2)Pandas
3)绘图可视化
4)文件系统
第二天:材料机器学习基础算法与催化活性预测实战
第二天将深入解析初级机器学习算法的数学原理及其在材料科学中的典型应用场景。分为如下几个部分:首先系统讲解线性模型家族的理论体系,从线性回归的解析解推导、逻辑回归的交叉熵损失函数,拓展到Softmax回归在多分类任务中的概率建模机制,着重分析激活函数在非线性映射中的关键作用;接着引入感知机模型作为神经网络的基础原型,通过回归与分类任务的对比,揭示机器学习算法中最核心的两类任务的区别。最后以CO2催化活性预测为切入点,在解析催化活性与电子结构特征的关联规律中,完整演练材料机器学习项目的标准流程:使用金属氧化物催化剂数据集,结合Scikit-learn库实现数据标准化处理、特征工程构建、模型选择、超参数网格搜索与ROC曲线评估。
【理论内容】
1. 线性回归
1)线性回归的原理
2)线性回归的应用
2. 逻辑回归
1)逻辑回归的原理
2)逻辑回归的应用
3. Softmax回归
1)Softmax回归的原理
2)Softmax回归的应用
4. 感知机(浅层神经网络)
1)感知机的原理
2)使用感知机进行回归
3)使用感知机进行分类
【项目实操内容】
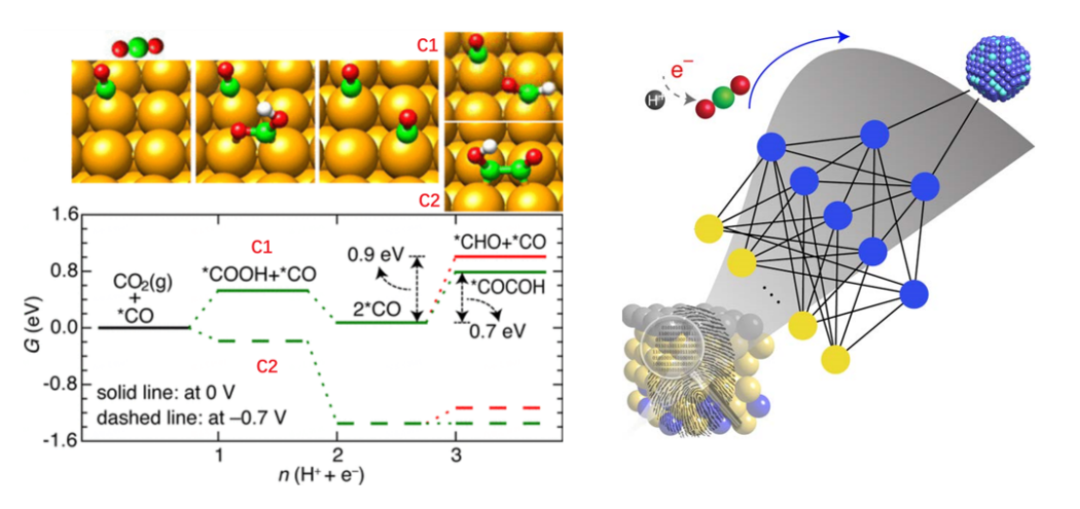
1. 机器学习对CO2催化活性的预测|机器学习入门简单案例 【文章】
1)机器学习材料与化学应用的典型步骤
a)数据采集和清洗
b)特征选择和模型选择
c)模型训练和测试
d)模型性能评估和优化
2)sklearn库介绍
a)sklearn库的基本用法
b)sklearn库的算法API
c)sklearn库的模型性能评估
第三天:材料机器学习进阶算法与项目实战
第三天将系统剖析机器学习中的进阶算法的数学框架及其在材料复杂体系中的建模策略。分为如下几个部分:首先从决策树的信息增益分裂准则切入,对比ID3/C4.5/CART算法的特征选择差异,并引申至集成学习框架中Bagging(随机森林)与Boosting(XGBoost)对模型偏差-方差权衡的优化机制;接着解析朴素贝叶斯基于特征条件独立假设的概率建模方法,及其在材料高通量筛选中的计算效率优势;最后深入探讨支持向量机的核函数映射技巧,通过可视化手段对比线性核、多项式核与高斯核在材料相态分类任务中的决策边界差异。
实战环节聚焦材料多尺度特性预测:在双金属ORR催化活性预测项目中,通过构建合金组分-电子结构特征矩阵,运用随机森林的变量重要性分析筛选关键描述符,结合Adaboost算法提升预测精度;在高熵合金相态分类任务中,基于原子半径、电负性等特征,演示支持向量机如何通过核函数变换处理非线性可分数据,并可视化决策超平面;同时拓展至生物炭材料回归预测,利用支持向量回归(SVR)分析孔隙率-吸附性能的定量关系。课程将结合Scikit-learn工具链,贯穿特征标准化、交叉验证、混淆矩阵评估等工业级实践流程。
【理论内容】
1. 决策树
1)决策树的原理
2)决策树的应用
2. 集成学习
1)集成学习的原理
2)集成学习的方法和应用
3. 朴素贝叶斯
1)朴素贝叶斯的原理
2)朴素贝叶斯的应用
4. 支持向量机
1)支持向量机的原理
2)支持向量机的应用
【项目实操内容】
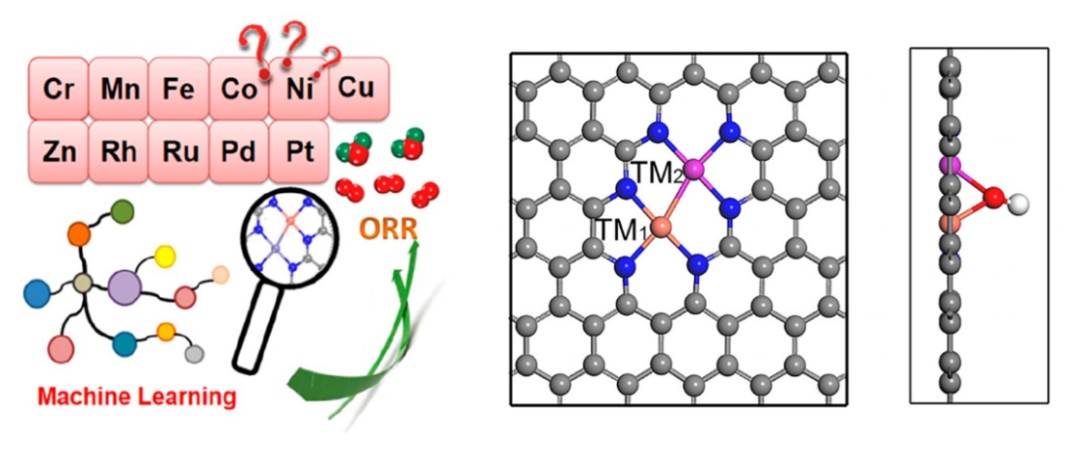
1. 利用集成学习预测双金属ORR催化剂活性【文章】
1)Sklearn中的集成学习算法
2)双金属ORR催化活性预测实战
a)数据集准备
b)特征筛选
c)模型训练
d)模型参数优化
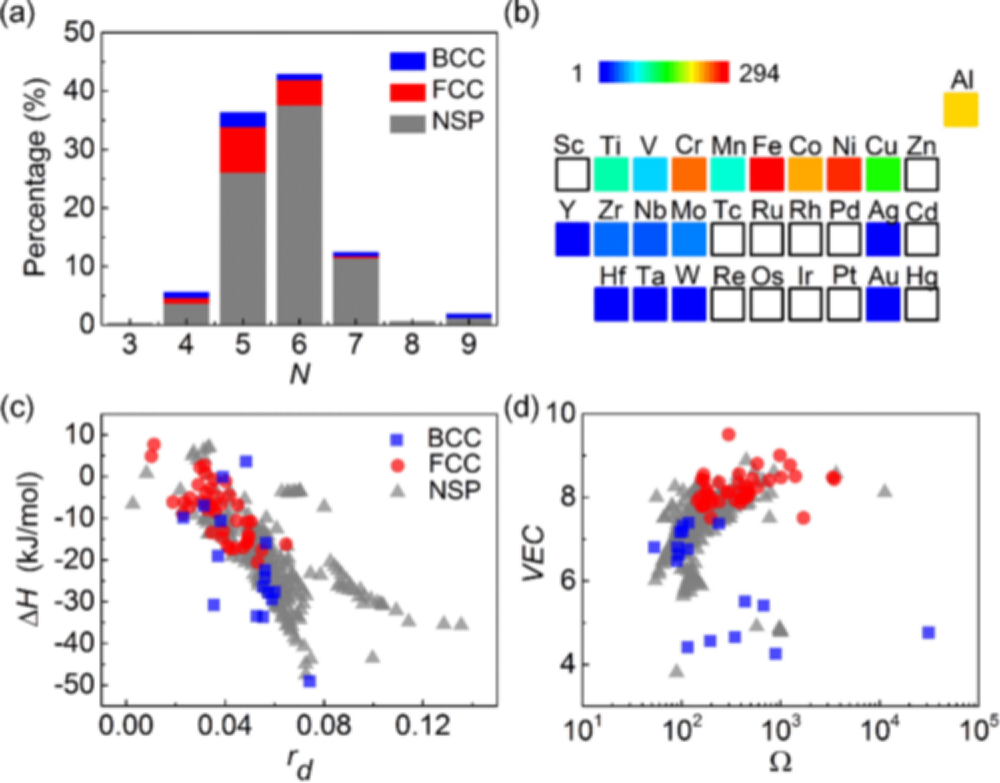
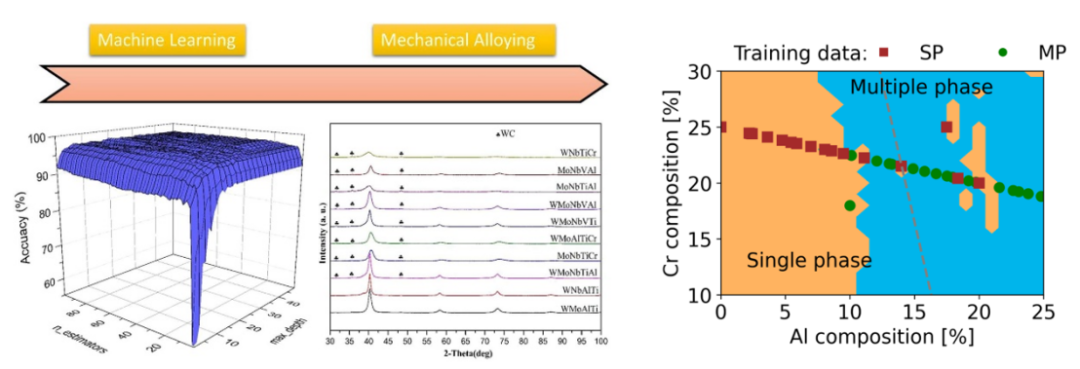
2. 使用支持向量机预测高熵合金相态【文章】
1)支持向量机的可视化演示
a)绘制决策边界
b)查看不同核函数的区别
2)支持向量机预测高熵合金相态(分类)
a)数据集准备
b)数据预处理
c)特征工程
d)模型训练及预测
3)支持向量机预测生物炭材料废水处理性能(回归)
a)数据集准备
b)数据预处理
c)模型训练及预测
第四天:材料无监督学习与分子特征工程实践
第四天将系统构建材料数据表征体系与无监督分析技术栈。分为如下几个部分:首先解析无监督学习的核心范式,对比K-Means聚类与DBSCAN密度聚类在材料相组成识别中的差异,详解常用的无监督学习技术在材料高通量筛选中的可视化应用;接着深入探讨材料特征工程的数学表达方法;最后结合Materials Project、COD等材料数据库,演示通过Pymatgen工具包自动化获取晶体能带结构、弹性张量等关键性质数据。
实战环节聚焦材料多模态数据处理:在石墨烯样品表征任务中,通过处理二维电镜图像,运用无监督聚类算法实现样品质量分级;针对高能材料分子性质预测,构建从SMILES字符串到3D分子坐标的全流程特征工程:使用RDKit生成初始构型,通过ASE优化分子结构,计算库伦矩阵与原子极化张量作为量子化学特征,对比Morgan指纹与MACCS键合描述符对机器学习模型性能的影响。
【理论内容】
1. 无监督学习
1)什么是无监督学习
2)无监督学习算法-聚类
3)无监督学习算法-降维
2. 材料与化学数据的特征工程
1)分子结构表示
2)晶体结构表示
3. 数据库
1)材料数据库介绍
2)Pymatgen介绍
【项目实操内容】
1. 无监督学习在材料表征中应用【文章】
1)K-Means聚类算法
2)石墨烯样品数据集准备
3)二维电镜图像处理
4)聚类及统计
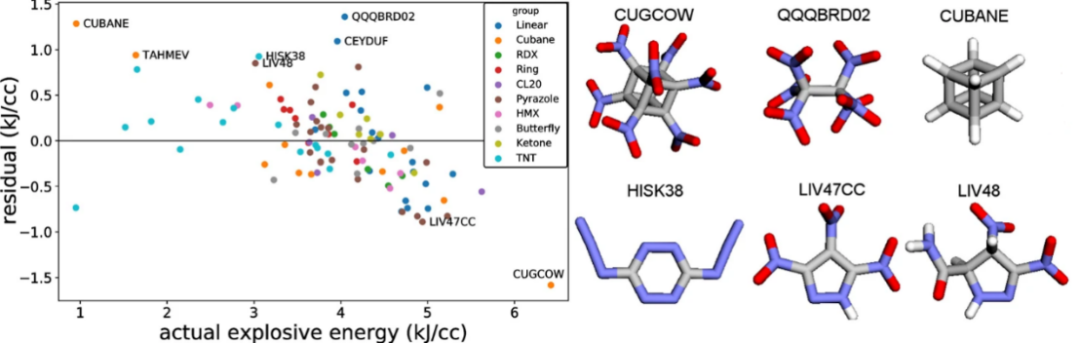
2. 利用机器学习预测高能材料分子性质【文章】
1)高能分子数据集准备
2)从SMILES生成分子坐标
3)从分子坐标计算库伦矩阵
4)测试不同分子指纹方法
5)比较不同特征化方法
6)模型性能评估
第五天:材料机器学习项目实践专题
第五天将深度融合前沿模型技术与材料多尺度特性预测场景。分为如下几个部分:首先系统解析大语言模型在材料研究中的创新应用范式,重点讲解DeepSeek的transformer架构原理及其在材料文献挖掘、实验方案生成等场景的提示词工程技巧;接着深入探讨更多的材料机器学习的常见技术路径,比如通过决策树的特征分裂可视化与SHAP值分析,揭示材料性能与微观结构的内在关联规律;最后为构建深度学习技术栈打基础,对比PyTorch动态计算图与Scikit-learn静态架构在复杂材料建模中的工程差异。
【项目实操内容】
1. DeepSeek提示词工程和落地场景
1)DeepSeek简介
2)大语言模型和DeepSeek原理
3)DeepSeek提示词工程和落
2.利用机器学习加速发现耐高温氧化的合金材料【文章】
1)合金材料数据集准备
2)数据预处理
3)特征构建和特征分析
4)多种模型训练
5)使用训练好的模型进行推理
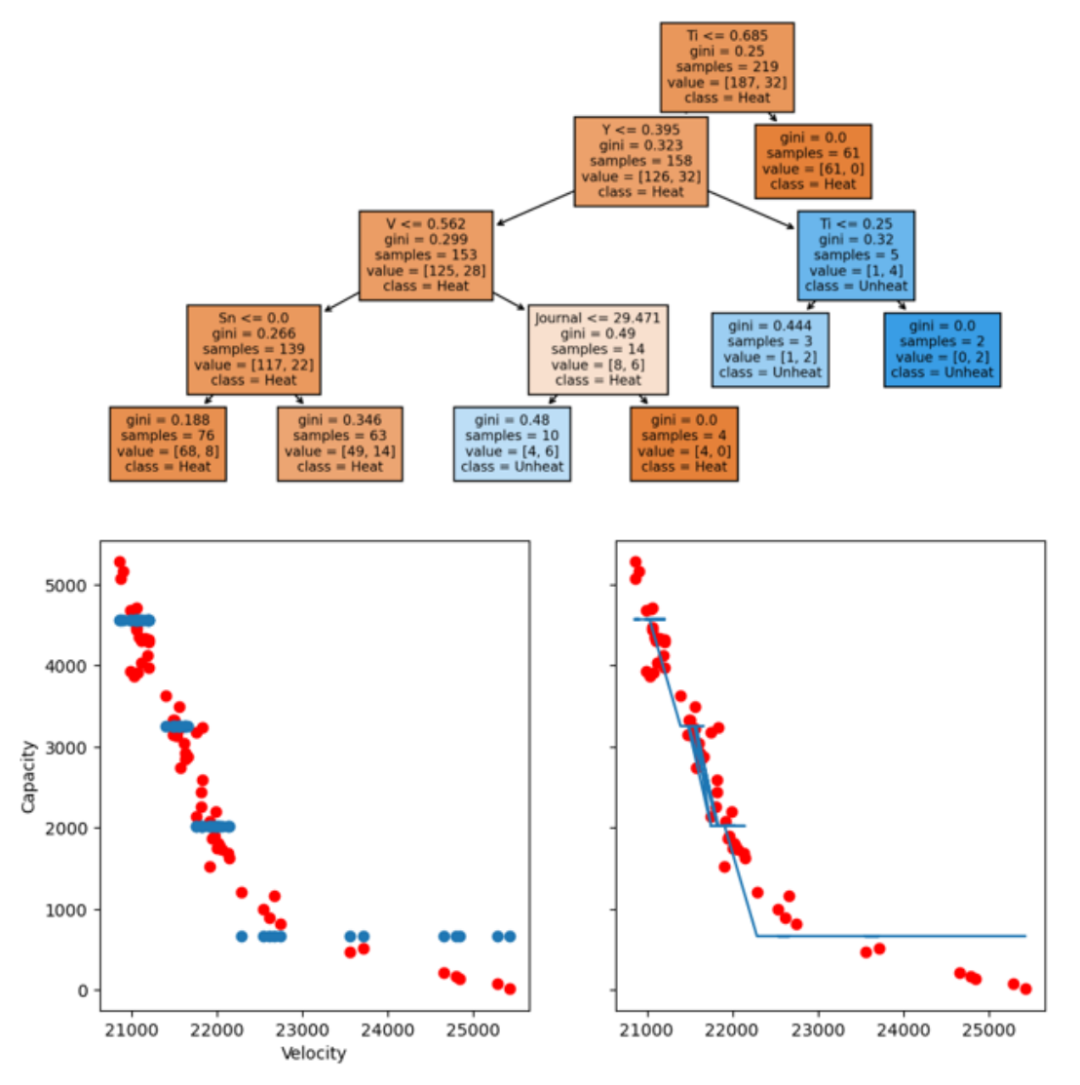
3.决策树(可解释性机器学习)预测AB2合金的储氢性能【文章】
1)储氢合金材料数据集准备
2)决策树基本流程
3)动手建立一棵树
4)决策树剪枝
5)决策过程可视化和特征重要性分析
6)分类决策树和回归决策树的区别
4.分子渗透性分类预测
1)使用定量的1D分子描述符和不同的机器学习模型进行QSAR模型的训练和预测
2)使用定性的2D分子描述符和不同的机器学习模型进行QSAR模型的训练和预测
3)比较不同分子描述方法对QSAR模型性能的影响
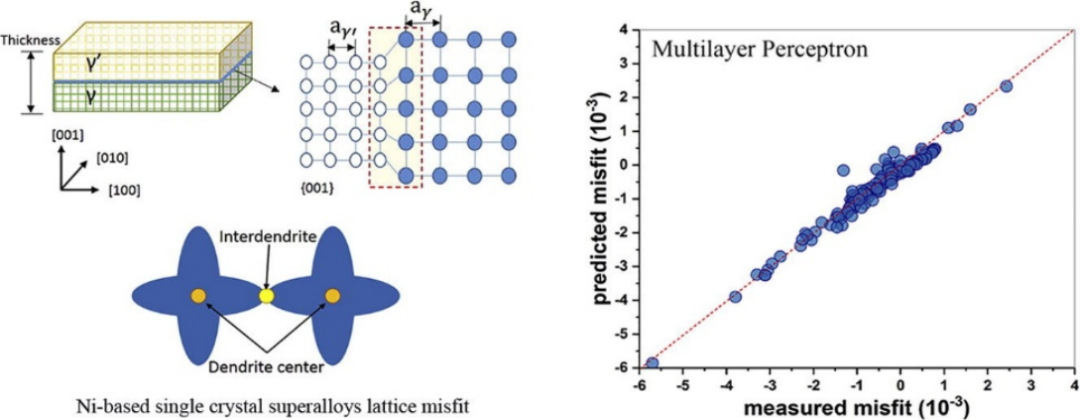
5.多层感知机预测单晶合金晶格错配度【文章】
1)PyTorch与Scikit-learn中多层感知机的区别
2)使用PyTorch构建多层感知机
3)训练PyTorch多层感知机模型预测单晶合金晶格错配度
4)PyTorch多层感知机模型参数优化
https://mp.weixin.qq.com/s/GUvb80w0vz6DF7FLDQ67Dw
上方链接查看完整信息

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)