【机器学习实战4】基于朴素贝叶斯分类器的西瓜数据集
目录
一、 朴素贝叶斯算法
1. 1 基本原理
朴素贝叶斯分类器的核心是贝叶斯定理,其公式为:
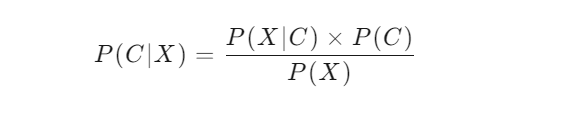
其中:
-
P(C∣X) 是在特征 X 出现的条件下,类别 C 出现的概率,称为后验概率。
-
P(X∣C) 是在类别 C 出现的条件下,特征 X 出现的概率,称为似然概率。
-
P(C) 是类别 C 出现的先验概率。
-
P(X) 是特征 X 出现的总概率。
朴素贝叶斯分类器通过计算每个类别的后验概率,选择后验概率最大的类别作为预测结果。
1.2 概率估计方法
-
先验概率 P(C):通常是通过训练数据中每个类别的样本数量来估计的,即:

-
似然概率 P(X∣C):根据特征的类型(离散或连续)有不同的估计方法:
-
离散特征:通常使用频率来估计。例如,对于文本分类中的词频,P(Xi∣C) 可以通过类别 C 中特征 Xi 出现的次数除以类别 C 中所有特征的总次数来计算。
-
连续特征:通常假设特征服从某种分布(如高斯分布),通过计算特征的均值和方差来估计概率密度函数。
-
二、西瓜数据集
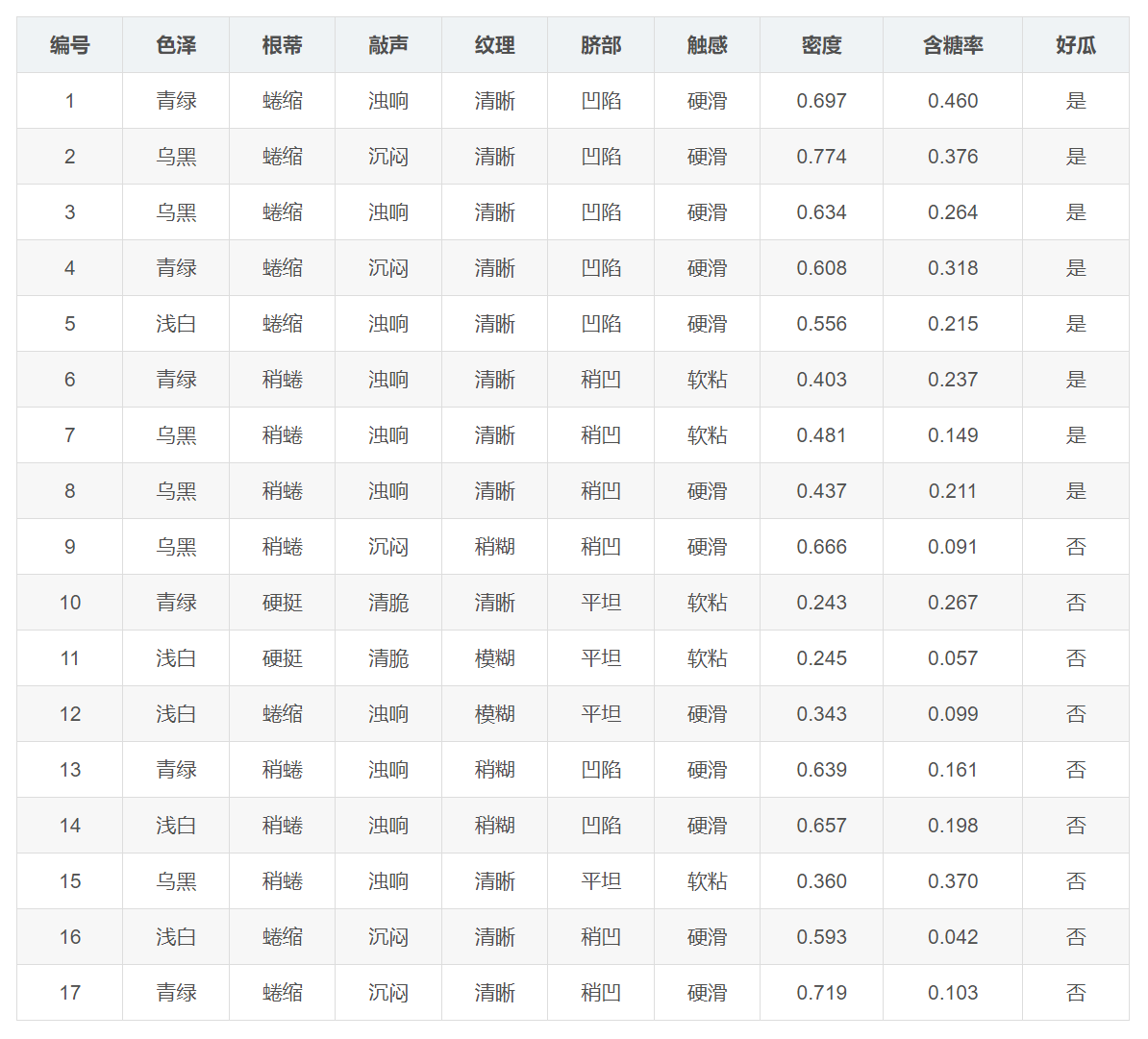
数据集中共 17 个样本,每个样本包含如下特征:
离散特征:
色泽(如:青绿、乌黑、浅白)
根蒂(如:蜷缩、稍蜷、硬挺)
敲声(如:浊响、沉闷、清脆)
纹理(如:清晰、稍糊、模糊)
脐部(如:凹陷、稍凹、平坦)
触感(如:硬滑、软粘)
连续特征:
密度(浮点数,如:0.697)
含糖率(浮点数,如:0.460)
分类标签:
好瓜(类别标签,是 / 否)
测试集:

三、朴素贝叶斯分类器实现步骤
3.1分类过程
-
计算先验概率
计算每个类别(好瓜、坏瓜)在数据集中出现的概率 P(C)。 -
计算条件概率
-
离散属性:计算每个离散特征在每个类别下的条件概率 P(Xi∣C)。
-
连续属性:假设连续特征服从高斯分布,计算均值和方差,进而得到条件概率密度函数。
-
-
计算后验概率
P(C∣X)∝P(C)×i∏P(Xi∣C)
对于新样本,计算其属于每个类别的后验概率 P(C∣X): -
比较后验概率
比较不同类别的后验概率,选择后验概率最大的类别作为分类结果。
3.2代码实现
代码如下:
import numpy as np
import math
import pandas as pd
# 加载数据集函数
# dataSet:训练集 testSet:待测集 labels:样本所具有的特征的名称
def loadDataSet():
dataSet = [['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '坏瓜']]
testSet = ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460] # 待测集
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率'] # 特征
return dataSet, testSet, labels
# 计算先验概率P(c)
def prior():
dataSet = loadDataSet()[0] # 载入数据集
countG = 0 # 初始化好瓜=0
countB = 0 # 初始化坏瓜=0
countAll = len(dataSet)
for item in dataSet: # 好瓜个数
if item[-1] == "好瓜":
countG += 1
for item in dataSet: # 坏瓜个数
if item[-1] == "坏瓜":
countB += 1
# 计算先验概率P(c)
P_G = round(countG / countAll, 3)
P_B = round(countB / countAll, 3)
return P_G, P_B
# 计算(不同类别中指定连续特征的)均值、标准差
def mean_std(feature, cla): # feature:传入指定将要计算其均值的标准差的特征名称,cla:计算指定分类cla下该特征的条件概率 feature/cla
dataSet, testSet, labels = loadDataSet()
lst = [item[labels.index(feature)] for item in dataSet if item[-1] == cla] # 类别为cla中指定特征feature组成的列表
mean = round(np.mean(lst), 3) # 均值
std = round(np.std(lst), 3) # 标准差
return mean, std
# 计算离散属性的条件概率P(xi|c)
def P(index, cla):
dataSet, testSet, labels = loadDataSet() # 载入数据集
countG = 0 # 初始化好瓜数量
countB = 0 # 初始化坏瓜数量
for item in dataSet: # 统计好瓜个数
if item[-1] == "好瓜":
countG += 1
for item in dataSet: # 统计坏瓜个数
if item[-1] == "坏瓜":
countB += 1
lst = [item for item in dataSet if
(item[-1] == cla) & (item[index] == testSet[index])] # lst为cla类中第index个属性上取值为xi的样本组成的集合
P = round(len(lst) / (countG if cla == "好瓜" else countB), 3) # 计算条件概率
return P
# 计算连续属性的条件概率p(xi|c)
def p():
dataSet, testSet, labels = loadDataSet() # 载入数据集
denG_mean, denG_std = mean_std("密度", "好瓜") # 好瓜密度的均值、标准差
denB_mean, denB_std = mean_std("密度", "坏瓜") # 坏瓜密度的均值、标准差
sugG_mean, sugG_std = mean_std("含糖率", "好瓜") # 好瓜含糖率的均值、标准差
sugB_mean, sugB_std = mean_std("含糖率", "坏瓜") # 坏瓜含糖率的均值、标准差
# p(密度|好瓜)
p_density_G = (1 / (math.sqrt(2 * math.pi) * denG_std)) * np.exp(
-(((testSet[labels.index("密度")] - denG_mean) ** 2) / (2 * (denG_std ** 2))))
p_density_G = round(p_density_G, 3)
# p(密度|坏瓜)
p_density_B = (1 / (math.sqrt(2 * math.pi) * denB_std)) * np.exp(
-(((testSet[labels.index("密度")] - denB_mean) ** 2) / (2 * (denB_std ** 2))))
p_density_B = round(p_density_B, 3)
# p(含糖率|好瓜)
p_sugar_G = (1 / (math.sqrt(2 * math.pi) * sugG_std)) * np.exp(
-(((testSet[labels.index("含糖率")] - sugG_mean) ** 2) / (2 * (sugG_std ** 2))))
p_sugar_G = round(p_sugar_G, 3)
# p(含糖率|坏瓜)
p_sugar_B = (1 / (math.sqrt(2 * math.pi) * sugB_std)) * np.exp(
-(((testSet[labels.index("含糖率")] - sugB_mean) ** 2) / (2 * (sugB_std ** 2))))
p_sugar_B = round(p_sugar_B, 3)
return p_density_G, p_density_B, p_sugar_G, p_sugar_B
# 预测后验概率P(c|xi)
def bayes():
# 计算类先验概率
P_G, P_B = prior()
# 计算离散属性的条件概率
P0_G = P(0, "好瓜") # P(青绿|好瓜)
P0_B = P(0, "坏瓜") # P(青绿|坏瓜)
P1_G = P(1, "好瓜") # P(蜷缩|好瓜)
P1_B = P(1, "坏瓜") # P(蜷缩|坏瓜)
P2_G = P(2, "好瓜") # P(浊响|好瓜)
P2_B = P(2, "坏瓜") # P(浊响|坏瓜)
P3_G = P(3, "好瓜") # P(清晰|好瓜)
P3_B = P(3, "坏瓜") # P(清晰|坏瓜)
P4_G = P(4, "好瓜") # P(凹陷|好瓜)
P4_B = P(4, "坏瓜") # P(凹陷|坏瓜)
P5_G = P(5, "好瓜") # P(硬滑|好瓜)
P5_B = P(5, "坏瓜") # P(硬滑|坏瓜)
# 计算连续属性的条件概率
p_density_G, p_density_B, p_sugar_G, p_sugar_B = p()
# 计算后验概率
isGood = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G * p_density_G * p_sugar_G # 计算是好瓜的后验概率
isBad = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B * p_density_B * p_sugar_B # 计算是坏瓜的后验概率
return isGood, isBad
if __name__ == '__main__':
dataSet, testSet, labels = loadDataSet()
testSet = [testSet]
df = pd.DataFrame(testSet, columns=labels, index=[1])
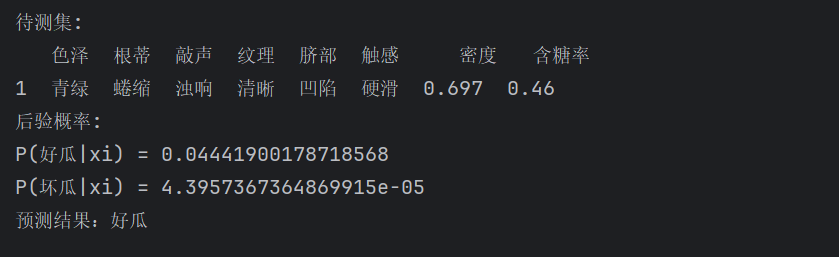
print(f"待测集:\n{df}")
isGood, isBad = bayes()
print("后验概率:")
print(f"P(好瓜|xi) = {isGood}")
print(f"P(坏瓜|xi) = {isBad}")
print("预测结果:好瓜" if (isGood > isBad) else "预测结果:坏瓜");测试结果如下:
四、实验总结
4.1 实验分析:
-
优点:朴素贝叶斯分类器简单易实现,对小规模数据集表现良好,且对缺失数据具有一定的鲁棒性。
-
局限性:朴素贝叶斯算法假设特征之间相互独立,这在实际应用中往往不成立,可能会影响分类效果。
-
改进方向:可以尝试其他算法(如决策树、支持向量机等)进行对比,或者对特征独立性的假设进行放松,使用半朴素贝叶斯等更复杂的模型。
4.2 结论:
朴素贝叶斯分类器是一个有效的分类工具,尤其适用于特征独立性假设成立的场景。尽管在某些情况下可能需要对算法进行改进或选择其他更适合的算法,但它仍然是机器学习初学者和专业人士的重要工具之一。通过本次实验,我不仅学会了如何使用朴素贝叶斯进行分类,还学会了如何评估和解释分类结果,为今后解决类似问题打下了坚实的基础。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)