python金融分析小知识(31)——机器学习之KNN分类算法的使用
Hello 大家好,我是一名新来的金融领域打工人,日常分享一些python知识,都是自己在学习生活中遇到的一些问题,分享给大家,希望对大家有一定的帮助!哈喽大家好,今天是我第一次该大家介绍机器学习算法,以前我都是在讲一些数据分析的小知识等等,今天给大家带来我经常遇到的KNN机器学习算法的使用。KNN(K-Nearest Neighbor)是机器学习算法中一种较为简单的算法,其主要思想就是通过识别k
Hello 大家好,我是一名新来的金融领域打工人,日常分享一些python知识,都是自己在学习生活中遇到的一些问题,分享给大家,希望对大家有一定的帮助!
哈喽大家好,今天是我第一次该大家介绍机器学习算法,以前我都是在讲一些数据分析的小知识等等,今天给大家带来我经常遇到的KNN机器学习算法的使用。
1.KNN基础介绍
KNN(K-Nearest Neighbor)是机器学习算法中一种较为简单的算法,其主要思想就是通过识别k个最近距离的点(基于欧几里得距离)来进行预测,该算法既可以用于分类也可以用于回归。
2.KNN算法用于分类
下面我通过代码来向大家介绍KNN在分类任务中的应用:
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier #导入KNN分类模型关于iris数据集的内容大家可以参考我之前的文章:
python金融分析小知识(28)——使用seaborn绘制线性回归图
iris = load_iris() #导入iris数据集
iris#将数据的特征与标签分别赋值给X,y
X, y = iris.data, iris.target我们来看看特征与标签:


# 拆分数据集(训练集+测试集)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y) #拆分的比例用默认的# 创建KNN分类器 参数保持默认 默认为5个邻居
knn_clf = KNeighborsClassifier()
# 训练模型
knn_clf.fit(X_train, y_train) 查看准确率:
查看准确率:

在这里之前我们所使用的KNN参数都是默认的参数,默认的参数不一定可以带来最大的准确率,所以接下来我们需要进行网格搜索,寻找模型的最优参数:
# 下面使用网格搜索进行参数分析(邻居的数量参数的分析)
from sklearn.model_selection import GridSearchCV
n_neighbors = list(range(1,11,1)) #指定参数的值
cv = GridSearchCV(estimator=KNeighborsClassifier(), param_grid={'n_neighbors':n_neighbors}, cv=5) #进行五折交叉验证
cv.fit(X,y) #使用网格搜索拟合数据集
cv.best_params_ #查看最优的参数打印结果:

这说明当参数n_neughbors参数是6时模型可以取得最高的准确率,下面我们来试试参数取6:
# 创建KNN分类器 参数保持默认 采用最佳参数
knn_clf2 = KNeighborsClassifier(n_neighbors=6)
# 训练模型
knn_clf2.fit(X_train, y_train)
查看准确率,看准确率是不是提高了一些:

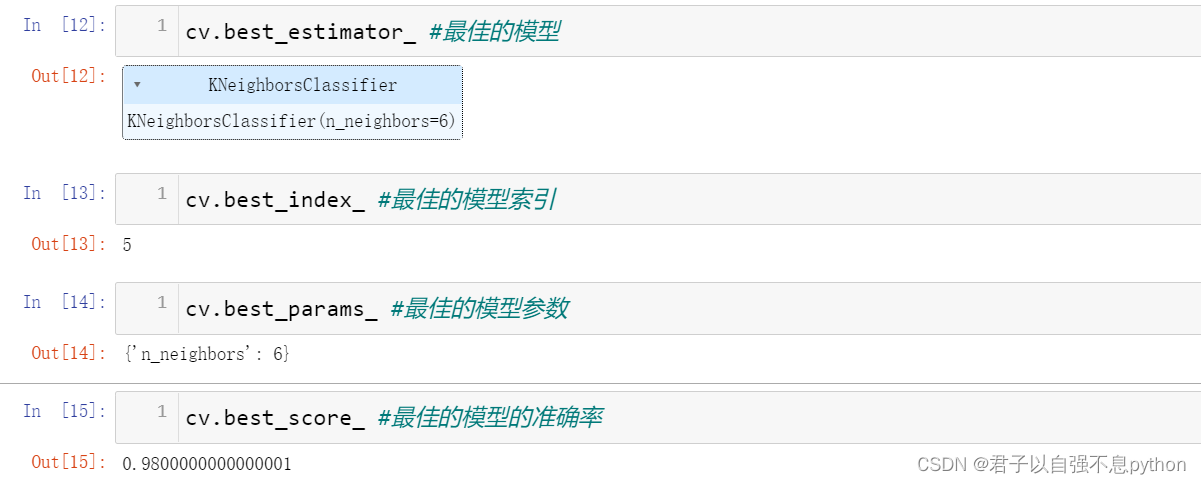
3.cv交叉验证的几个主要属性
我们可以查看交叉验证的几个主要属性:
好啦今天的文章就分享到这里啦!下一期讲讲KNN的回归算法。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)