机器学习-特征缩放
从数值来看, 年份和工资相比数值太小, 对整个模型的影响基本上可以忽略。(方差计算的是数据平方, 个体数据相差值会放大,所以开方求平方根可以缩小换算回来。机器学习中, 特征值通常相差比较巨大,不同维度的特征值相差巨大,导致部分特征影响微乎其微,用来做训练效果不好。Xnew =x - mean(x)/ std(x)[均值标准差】举个例子, 工作年数和 工资收入作为特征值,来构建预测模型。因此,我们需
机器学习中, 特征值通常相差比较巨大, 不同维度的特征值相差巨大,导致部分特征影响微乎其微, 用来做训练效果不好。
举个例子, 工作年数和 工资收入作为特征值,来构建预测模型。
工作年数 一般比较小 1-10 , 工资收入 都是3000-100 0000 不等。 从数值来看, 年份和工资相比数值太小, 对整个模型的影响基本上可以忽略。
因此,我们需要对特征值进行缩放, 已规避数值差异带来的影响。
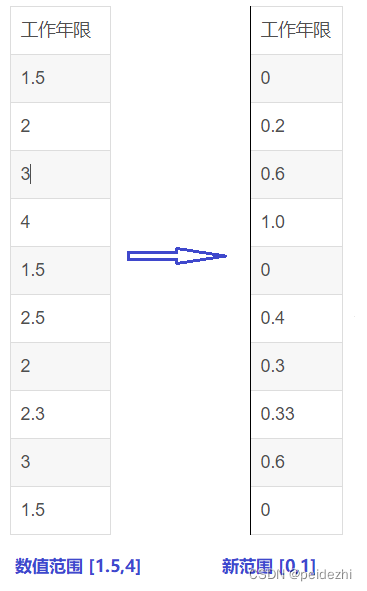
1 特征缩放:线性归一化 (min-max normalization)
Xnew = x - min(x)/ max(x)-min(x)
也称最大最小值归一化 。 计算公式如下。
2 标准差归一化 ( Z-score normalization)
Xnew = x - mean(x) / std(x) [均值 标准差】
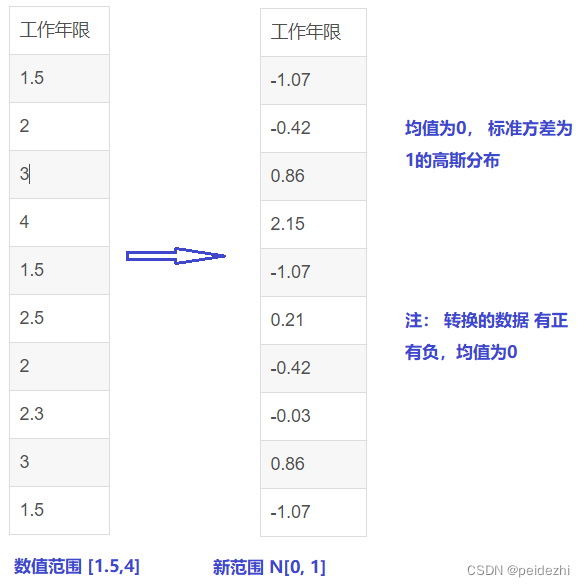

标准差std(x) = 方差的算术平方根 。(方差计算的是数据平方, 个体数据相差值会放大,所以开方求平方根可以缩小换算回来。 即标准差)
3 特征标准化方法选择。
具体哪一种 标准化方法比较好,依据实际效果来。
5 特征值离散化
一般在搭建机器学习分类模型时,需要对连续型的特征进行离散化,也就是分箱。
5.1 无监督分箱
1) 等距分箱
特征的取值范围等间隔分割,从最小值到最大值之间,均分N等份,如果最小值和最大值分 别为A、B,则每个区间的长度为W=(B-A)/N,则区间的边界为A+W,A+2W,A+3W,..., A+(N-1)W
该方法对异常值比较敏感,比如远大于正常范围的数值会影响区间的划分。
2)等频分箱
每个区间包含大致相等的实例数量。比如说 N=10 ,每个区间应该包含大约10%的实例。
5.2 有监督分箱
卡方分箱 、最优分箱等。
TODO
举例: 年龄特征 (21 22 23 21 24 25 22 23 25 24 21 26 28 30)
X<=22 ==> X = 1
22 < X <=24 ==> X =2
X > 24 ==> X =3
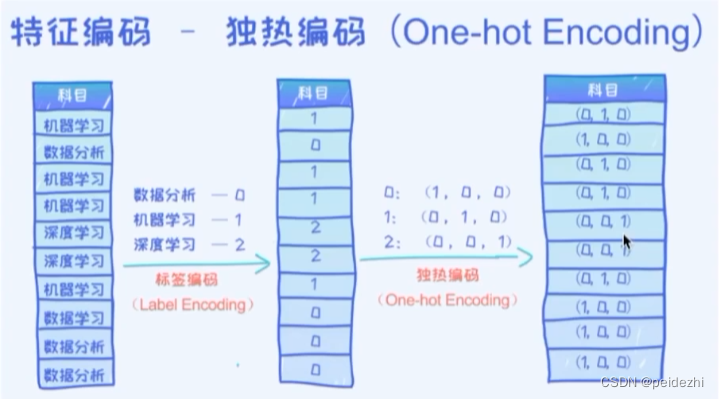
6 类别特征分类编码 one-hot编码
在机器学习中,我们常用到分类。比如 经典的 手写 1-9 数值分类识别。 如果分类特征 按, 1 ,2, 3 ...9来分类的话, 会把这些数值明显差异大小有别带入到模型中。 实际上 只是一个分类,没有大小。
针对类别特征的编码,常用的是 one-hot编码。
7 交叉验证与参数调优
一份数据集,我们一般取 80%作为训练集, 20%作为测试集。
但是,仅一次选择, 可能效果泛化不好,特别是20%跟训练集比较接近的时候。
因此, 为达到更好效果,我们经常使用交叉验证。
1)S-fold交叉验证。 即S折交叉验证
将数据集分成S份 (常用的是10折)。 以10折为例
取1份作为验证数据。 另外9份作为训练集。
取第2份作为验证数据。另外9份作为训练集。
......
取第10份作为验证数据。另外9份作为训练集。
将上述验证效果最好的参数模型,作为开发侧的输出,提交給测试团队进行下一步操作。
8 模型度量、评价
0) 混淆矩阵
TP: 预测为 Positive, 实际为Positive
FP: 预测为 Positive, 实际为Negative
TN: 预测为 Negative, 实际为Negative
FN: 预测为 Negive, 实际为Positive
|
准确率 ACC |
Accuray = TN + TF / TP+TN+ FP+ FN | 分类模型所有判断正确的样本,占所有观测值的比重 |
|
精确率 PPV |
Precision = TP / TP + FP | 模型预测的所有positive样本中,模型预测对的比例 |
|
灵敏度 TPR(召回率) |
Sensitive = Recall = TP/ TP + FN | 真实是positive的样本中,模型预测对的比例 |
F1 = 2 * (Precision * Recall ) / (Precision+ Recall)
如之前的场景。 我们要识别出所有的 次品 (提高recall)
但是呢同时要兼顾 准确率,不要本来1个次品,结果识别出了20个次品,虽然提高了recall。打但是准确率太低。
F1就是为兼顾两者,而设计的一个计算公式。
1) 准确率: 就是所有预测正确的(包括正类和负类)占总的的比例。
准确率,不能作为一个模型好坏的唯一评价标准。
eg: 某工厂产品加工。合格率本身就已经达到了99%
如果我写个模型,直接全部输出全部是正品(实际99个正品,1个次品)。 那么准确率已经达到了99%。 达到客户要求(98%以上准确率)了。
但是呢, 客户实际上要求1个次品都不能流入市场。所以光靠准确率无法达到客户目标。
实际生产中,我们主要关注正向样本。因此一般以下2个指标构成F1来度量模型。
2) 精确率(即positive准确率)
positive样本中,模型预测对的比例
3) 召回率(灵敏度)
接问题1, 如果客户关注的是次品, 那么次品就是我们的positive正向指标。
次品流向市场对客户严重影响,因此必须严控。提高召回率。
召回率(也叫灵敏度) = TP/ (TP +FN)
假如为了满足我的 召回率, 我们的模型 增强了校验标准,把8分合格的产品也检测为 次品。 如 :100个样品, 5个识别为正向数据(次品, 实际只有一个次品,4个识别错误) 95个识别为负向数据(正品)
recall= 1 /1 + 0 =100%
可见,召回率 虽然 100%, 但是呢, 导致客户的成本加大,合格品也被当作次品处理了。因此准确率也是很重要,需要兼顾。
2) 多分类计算准确率和召回率:
上述的度量用于2分类计算。如果需要计算多分类的度量,一般以观测分类作为正向值,分别计算,最后求所有分类的平均值。
可以参看:机器学习笔记-多分类下的召回率和F值_多分类召回率_柒夏码农之路的博客-CSDN博客
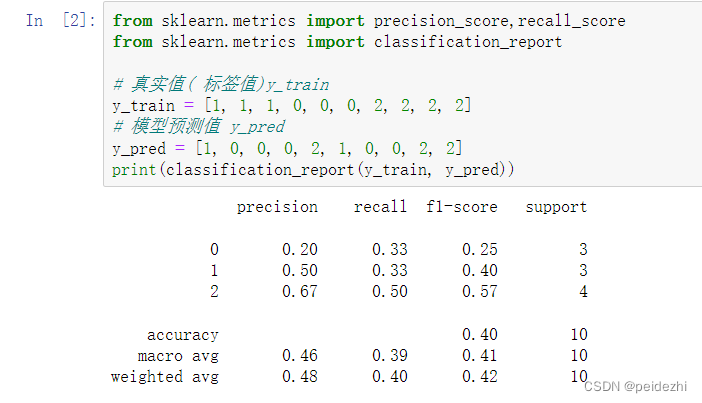
3)SKlearn 计算方法:
i) classification_report 对象可以直接计算 标签值和预测值的算术平均值
和 加权平均值结果(样本数量占比)。
from sklearn.metrics import classification_report
y_train= [1, 1, 1, 0, 0, 0, 2, 2, 2, 2] // 样本标签值
y_pred = [1, 0, 0, 0, 2, 1, 0, 0, 2, 2] // 预测值
print(classification_report(y_true, y_pred))
ii) cross_val_score 、cross_val_predict
cross_val_score:得到K折验证中每一折的得分,K个得分取平均值就是模型的平均性能
cross_val_predict:得到经过K折交叉验证计算得到的每个训练验证的输出预测
示例代码(cross_val_score):
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
clf = SGDClassifier()
scores = cross_val_score(clf, X_tfidf, target, cv=10)
//classification_instance 任意分类器
// cv: 训练数据打10折, 其中一折用于预测,下述返回结果即为预测打分。 其它9折用于训练模
// 型。 交叉10次
y_scores = cross_val_predict(classification_instance, X_train, y_train, cv=10)
有了这个得分,我们可以画出 阈值和召回率的曲线,(阈值越高,召回率月底,精度越高)
from sklearn.metrics import precision_recall_curve
precesion,recall, threshhod = precision_recall_curve(y_train,y_scores)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)