机器学习:感知机算法(PLA)
感知机(Perceptron)是一种最简单的人工神经网络模型,由弗兰克·罗森布拉特(Frank Rosenblatt)在1958年提出。它是一种线性分类器,用于二分类任务,即把输入数据分为两个类别。
1,概述
1.1,定义
感知机(Perceptron):
- 二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1;
- 感知机对应于输入空间中将实例划分为正负两类的分离超平面,属于判别模型;
- 感知机学习旨在求出将训练数据进行现行划分的分离超平面,为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。
- 感知机学习算法具有简单而易于实现的优点,分为原始形式和对偶形式;
感知机的缺点:我们在不知道数据的情况下(是否线性可分)PLA就不会停下来,这个时候我们会使用Pocket演算法来找到一根不错的直线。Pocket演算法的基本思想就是找到一根犯错误更小的直线。实务上我们一般会执行到一定的时间或者一定的步数就会停下来。结果是它是一条不错的线,但是可能不是一个最优解。
1.2,感知机模型
假设输入空间(特征空间)是
,输出空间是
。输入
表示实例的特征向量,对应输入空间(特征空间)的点,输出
表示实例的类别。由输入空间到输出空间的函数:
感知机:
为模型参数,
叫做权值或权值向量,
叫作偏执。
符号函数:
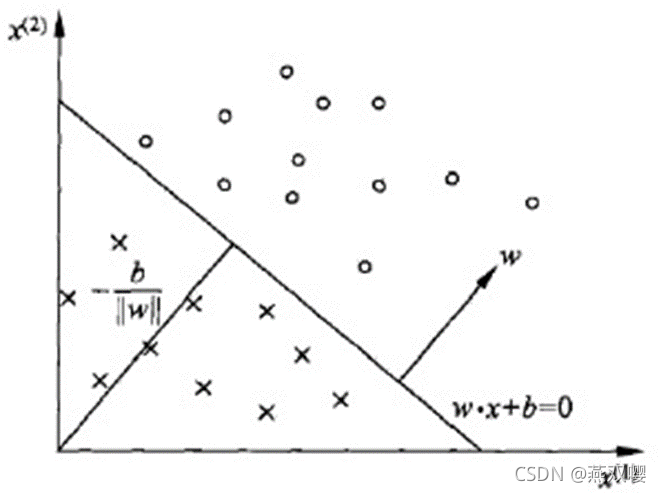
1.3,几何解释
感知机可以理解为几何中的线性方程:
对应于特征空间
中的一个超平面
,其中
是超平面法向量,
是超平面的截距。这个超平面将特征空间划分为两个部分。位于两部分的点(特征向量)分别被分为正、负两类。
2,学习策略
2.1,损失函数
假设训练集是线性可分的,感知机学习的目标是求得一个能够将训练集正实例点和负实例点完全正确分开的分离超平面。为了找出这样的超平面,即确定感知机模型参数
损失函数的一个自然选择是误分类点的总数。但是,这样的损失函数不是参数
到超平面
其次,对于误分类的数据
来说:
因为:
因此,误分类点到平面
这样,假设超平面
,那么所有误分类点到超平面
不考虑
,就得到感知机学习的损失函数:
原因:
正负的判断,即不影响学习算法的中间过程。因为感知机学习算法是误分类驱动的,这里需要注意的是所谓的“误分类驱动”指的是我们只需要判断
,即分子为0。则可以看出
- 总结:PLA的任务是进行二分类工作,它最终并不关心得到的超平面离各点的距离有多少,关心误分类点的数量,而SVM则关心距离。
由于
所以
是非负的。如果没有误分类点,损失函数值为0。而且由于误分类点越少,误分类点里超平面越近,损失函数值就越小(求和数目减少)。一个特定的样本点的损失函数:在误分类时是参数
,损失函数
因此感知学习的策略是在假设空间中选取使损失函数
2.2,优化函数
首先,任意选取一个超平面
,然后用梯度下降法不断极小化目标函数
。极小化的过程不是一次使
假设误分类点集合
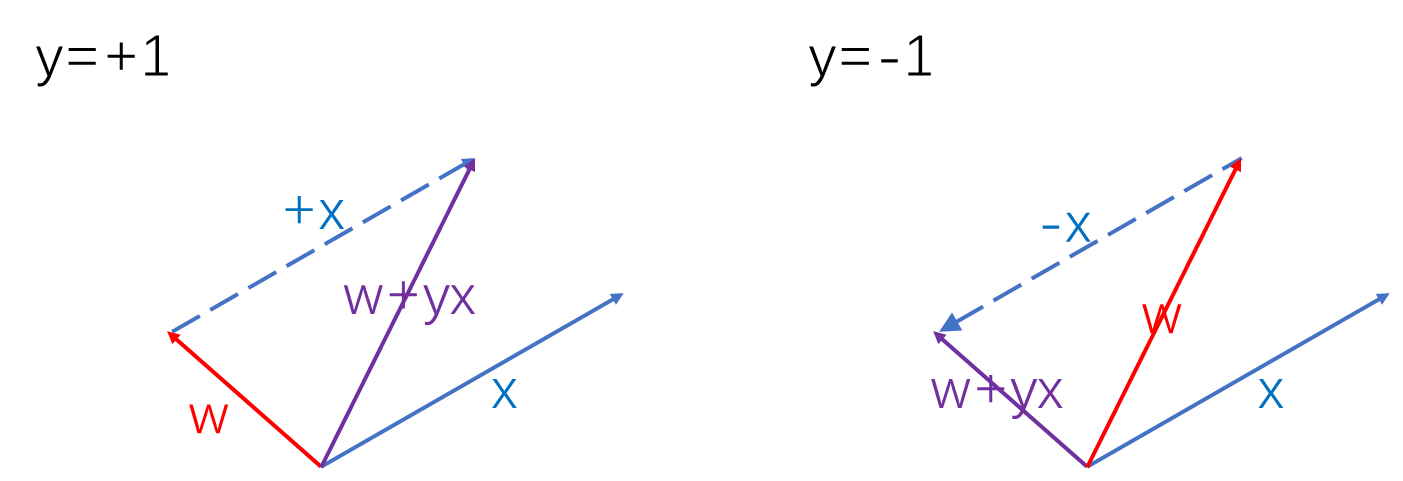
因此,需要沿着梯度的反方向更新
随机采取一个误分类点
,对
采用这种方法的原因:简单。但不限于这一种方法。
修正:
整体修正过程:
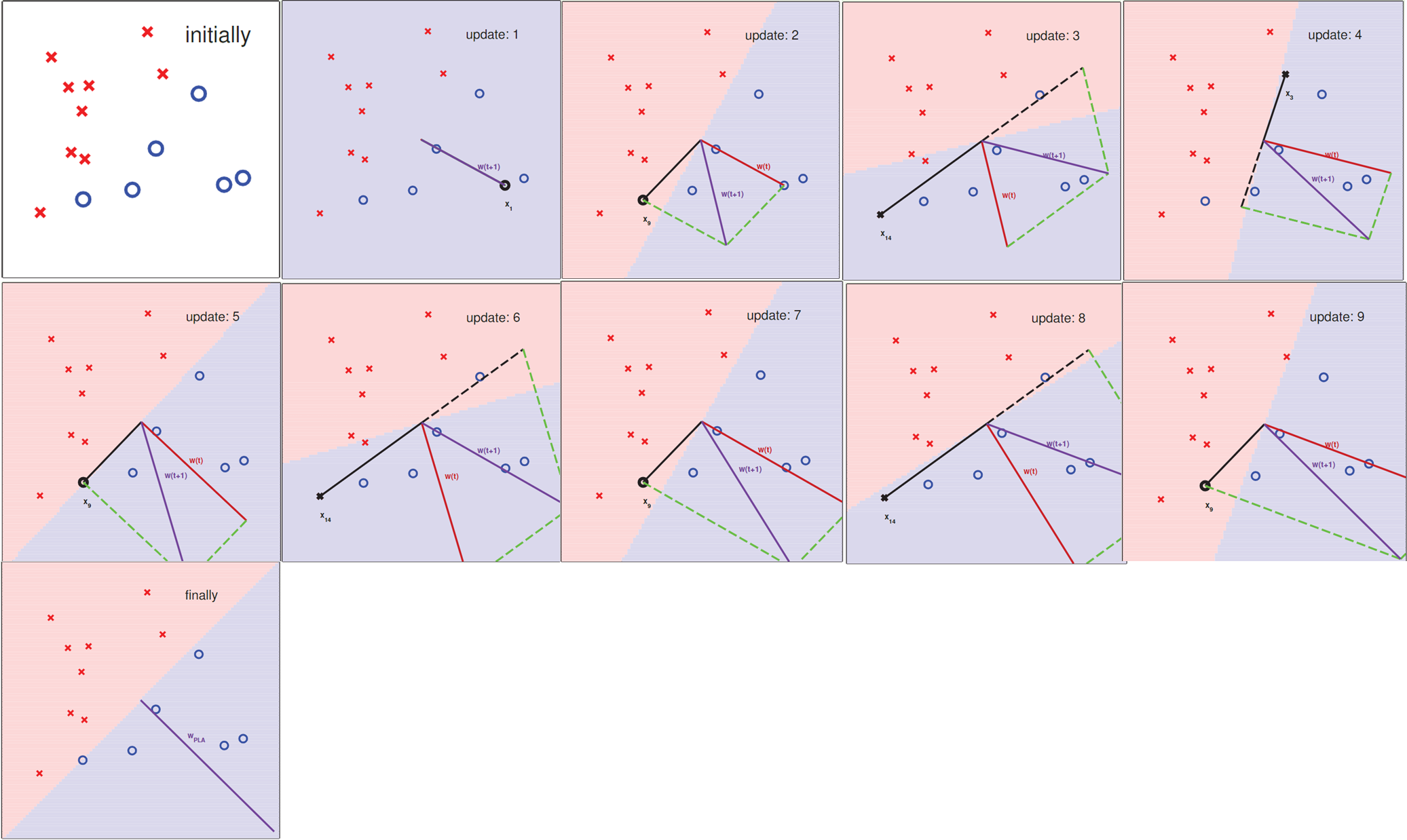
3,收敛性
3.1,向量持续修正
每次修改后的
(向量的乘积不断变大):
更新:
缩放:
线性可分:存在
在标准感知机中通常会省略
中,即:


完美的
。
确实发现它们的内积在不断地增大,内积的增大原因有向量的模长在增大或者是夹角在变小。但是证明两个向量的相关性增大需要证明的是两个向量的夹角在变小,所以需要排除向量模长的不确定性。
3.2,修正幅度上限
在这个推导中,更加关心的是
即:
修正之后权向量的长度,相较于修正之前的增加有一个上限,或者说它的长度增长是较慢的。这个上限由
和
差别不会太大,所以现在还不能证明夹角在变小。
3.3,优化证明
用
即:
的值的变化
过程如下:
由前面可知,
即:
-----------------------------------------------------------------------------------
即:
-----------------------------------------------------------------------------------
即:随着
不断增大,
的下限不断增加,在
区间(向量夹角不可能大于180),
角度上限不断减小,总体来看角度变小(机器学习不确定因素大,没法保证每一步都比上一步角度小,参考上面2.2节图)。

3.4,修正次数上限
即:
因为
,可得:
即:
3.4,线性不可分(Pocket PLA)
如果数据集是线性不可分的,那么对PLA进行改进,类似贪心算法:在pocket中保留一条当前最好的线,如果改进后的线更好(错分的样本数少),则更新最好的线,这样的缺点是需要遍历完空间内所有点的才能得到最好的结果。
对
个样本进行遍历,遇到错误就更新

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)