基于机器学习的信贷违约预测
本文旨在利用机器学习中的LightGBM模型构建信用风险评估模型,预测贷款申请人的违约概率,并区分中高低风险客户,从而优化贷款审批决策。研究基于Prosper公开贷款数据集,包含81个特征,涵盖贷款基本信息、借款人信息、信用历史与评分等类别。通过数据预处理、探索性分析和模型构建,研究发现借款人信用评分、信用卡使用频率、收入水平、信用评级及客户身份等因素与违约率显著相关。模型评估结果显示,该模型在准
本文的目的使用机器学习中的LightGBM模型构建一个一个信用风险评估模型,来进行风险评估,预测贷款申请人是否会违约,有效区分中高低风险客户,从而判断各个贷款是否应该批准,此模型的建立不仅降低银行因批准了不具备偿还贷款能力的申请人的申请而亏损的概率,还降低了因未批准具备偿还贷款能力的申请人的申请而收益损失的概率。
本文将基于Prosper公开贷款数据集中的train.csv文件来进行数据模型的构建,预测每个申请人的违约概率,将贷款申请人分为中高低三类风险申请人,并将其分类至“违约”和“非违约”类别,从而帮助判断是否应该批准此申请人的贷款申请。
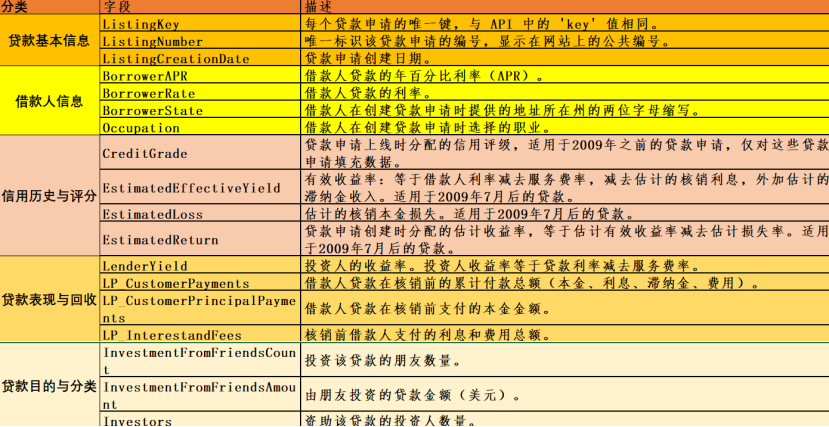
Prosper公开贷款数据集中有81个特征。数据集中的81个特征可以分为五类,分别为贷款基本信息、借款人信息、信用历史与评分、贷款表现与回收、贷款目的与分类。数据特征的分类整理方便了后续的数据查找。数据集的部分特征分类如下图所示,详细的特征分类请看附件-数据字典。
一、数据预处理
#加载库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
import lightgbm as lgb
from sklearn.metrics import average_precision_score
plt.rcParams['font.family'] = ['SimHei'] #用来显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号#导入数据
loanData=pd.read_csv(r'C:\Users\Lenovo\Desktop\案例集\基于机器学习的信贷违约预测\train.csv')
Data=pd.read_csv(r'C:\Users\Lenovo\Desktop\案例集\基于机器学习的信贷违约预测\test.csv')
loanData.head(5)1、按照贷款当前状态分类
#按照贷款当前状态分类
loanData.groupby(['LoanStatus'])['LoanStatus'].count()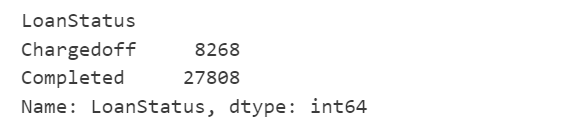
获取贷款状态(LoanStatus)列中每种状态的计数,帮助我们了解不同状态的贷款数量。其中Chargedoff(已核销)视为违约,Completed(已完成)视为非违约。
2、计算借款人信用评分范围的上限值和下限值的平均值
#借款人消费信用分:借款人信用评分范围的上限值和下限值的平均值(CreditScore)
loanData['CreditScore']=((loanData['CreditScoreRangeLower']+loanData['CreditScoreRangeUpper'])/2).round(0)
Data['CreditScore']=((Data['CreditScoreRangeLower']+Data['CreditScoreRangeUpper'])/2).round(0)
creditscore=loanData.groupby(['LoanStatus','CreditScore'])['CreditScore'].count().unstack(0)
creditscore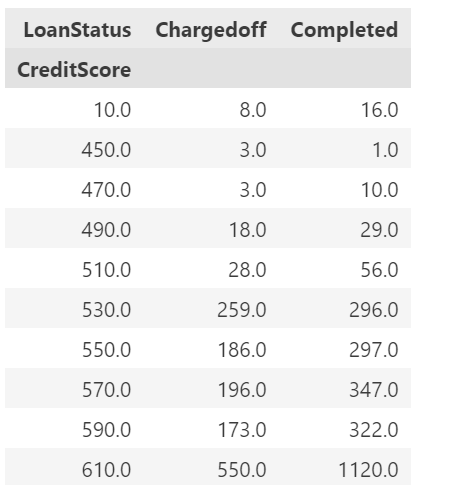
3、计算借款人信用评分范围的上限值和下限值的平均值
根据银行信用卡利用率(BankcardUtilization)的值,将其分类为不同的使用等级,主要有轻微使用(Mild Use)、中等使用(Medium Use)、大量使用(Heavy Use)、过度使用(Super Use)和没有使用(No Use)五类。
#对银行信用卡的使用情况进行分类
#数据处理
onefourth=loanData['BankcardUtilization'].quantile(0.25)
twofourth=loanData['BankcardUtilization'].quantile(0.5)
def Bankcard_Utilization(s,onefourth=0.21,twofourth=0.54):
if (s>0)&(s<=onefourth):
d='Mild Use'
elif (s>onefourth) & (s<=twofourth):
d='Medium Use'
elif (s>twofourth) & (s<=1):
d='Heavy Use'
elif s>1:
d='Super Use'
else:
d='No Use'
return d
loanData['BankCardUse']=loanData['BankcardUtilization'].apply(Bankcard_Utilization)
Data['BankCardUse']=Data['BankcardUtilization'].apply(Bankcard_Utilization)4、将2009.07.01前后的信用评级合并
#将2009.07.01之前的信用评级CreditGrade与 2009.07.01之后的信用评级ProsperRating (Alpha)合并(CombinedRating)
loanData['CombinedRating'] = loanData.apply(lambda row: row['CreditGrade']
if not pd.isna(row['CreditGrade']) else row['ProsperRating (Alpha)'], axis=1)
print(loanData['CombinedRating'])
Data['CombinedRating'] = Data.apply(lambda row: row['CreditGrade']
if not pd.isna(row['CreditGrade']) else row['ProsperRating (Alpha)'], axis=1)
5、按照贷款总数划分贷款人身份
根据贷款总额区分贷款人是否贷款过, Previous Borrower表示贷款人曾经贷款过,New Borrower表示贷款人没有过去的贷款记录。
def TotalProsper_Loans(s):
if s>0:
d='Previous Borrower'
else:
d='New Borrower'
return d
loanData['customerclarify']=loanData['TotalProsperLoans'].apply(TotalProsper_Loans)
Data['customerclarify']=Data['TotalProsperLoans'].apply(TotalProsper_Loans)6、违约率
loanData['违约率']=loanData['LP_GrossPrincipalLoss']/Data['LoanOriginalAmount']
Data['违约率']=Data['LP_GrossPrincipalLoss']/Data['LoanOriginalAmount']二、探索性分析
1. 借款人信用评分(CreditScore)越低,违约概率越大
#借款人信用评分(CreditScore)越低,违约概率越大
plt.figure(figsize=(12,8))
ax = plt.gca() # 获取当前轴
creditscore.plot(kind='line', ax=ax, grid=True, marker='o', linestyle='-') # 添加标记和线型
ax.set_ylabel('数量')
ax.set_xlabel('Creditscore')
ax.set_title('信用评分与违约率的关系') # 添加标题
plt.show()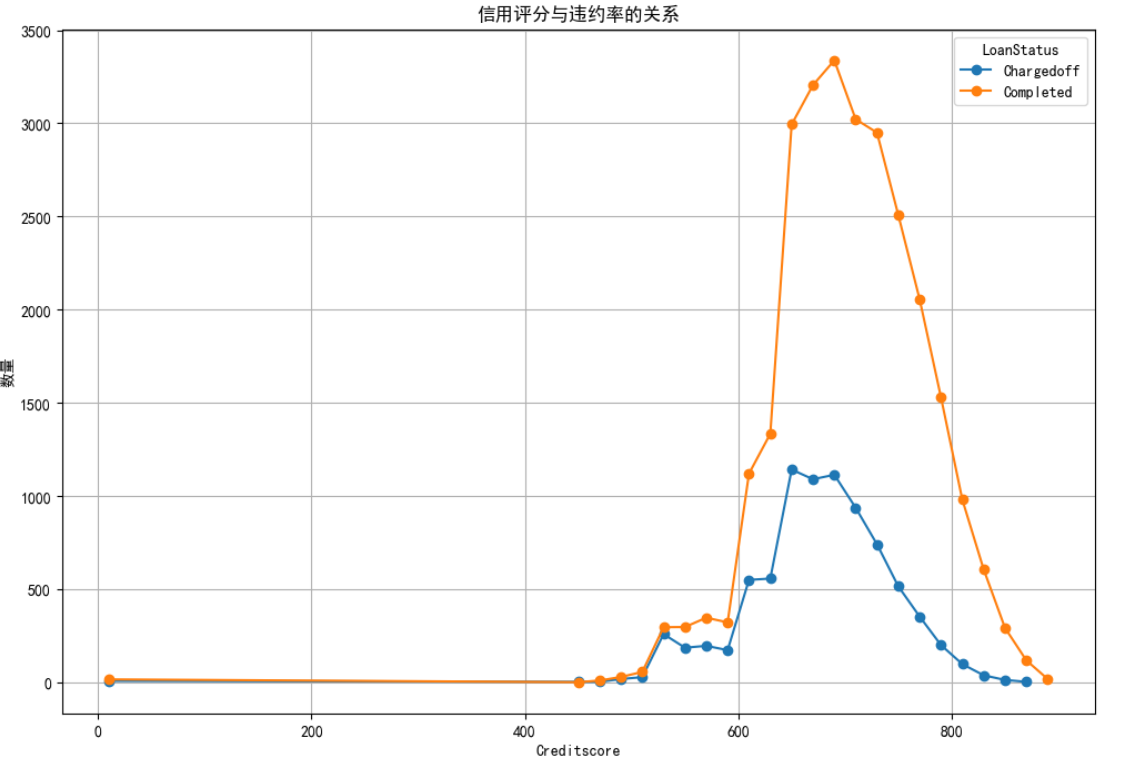
如图所示:在较低的信用评分区间(0-400),无论是“Chargedoff”还是“Completed”的数量都非常少,随着信用评分的增加,在500左右开始出现一些“Charged off”和“Completed”的数据点;在600-700之间,“Completed”的数量显著上升,并达到峰值, “Chargedoff”的数量也在这一区间内有所增长,但远低于“Completed”的数量;在800以上的信用评分区间,“Completed”的数量逐渐减少,而“Chargedoff”的数量也相应减少。总之,借款人信用评分越高,贷款被成功完成的概率越大,借款人信用评分越低,违约概率越大。
2. 信用卡使用频率(BankCardUse)越高,违约概率越大。
#2. 信用卡使用频率(BankCardUse)越高,违约概率越大。
bankcarduse=loanData.groupby(['LoanStatus','BankCardUse'])['BankCardUse'].count().unstack(0)
index=['Mild Use','Medium Use', 'Heavy Use', 'Super Use', 'No Use',]
bankcarduse=bankcarduse.reindex(index)
print(bankcarduse)
fig=plt.figure()
fig.set_size_inches(12,8)
ax=fig.add_subplot(111)
bankcarduse.plot(kind='bar',ax=ax)
ax.set_xticklabels(index,rotation=0)
ax.set_ylabel('数量')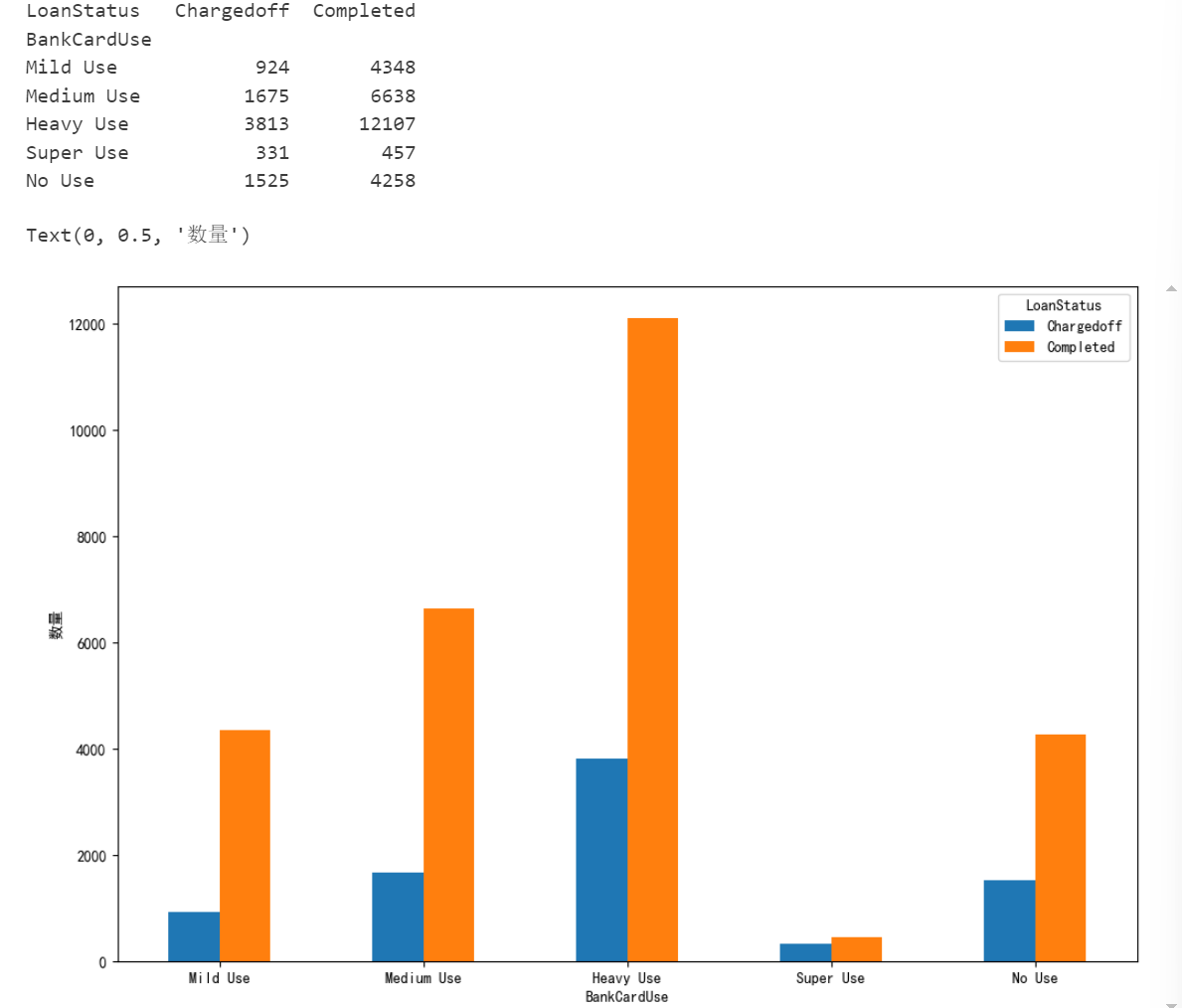
Chargedoffdrate=bankcarduse['Chargedoff']/(bankcarduse['Chargedoff']+bankcarduse['Completed'])
print(Chargedoffdrate)
plt.figure(figsize=(12,8))
ax = plt.gca()
ax.bar(Chargedoffdrate.index, Chargedoffdrate)
ax.set_xticklabels(Chargedoffdrate.index, rotation=0)
ax.set_ylabel('违约率')
ax.set_title('银行卡使用情况与违约率的关系')
plt.show()
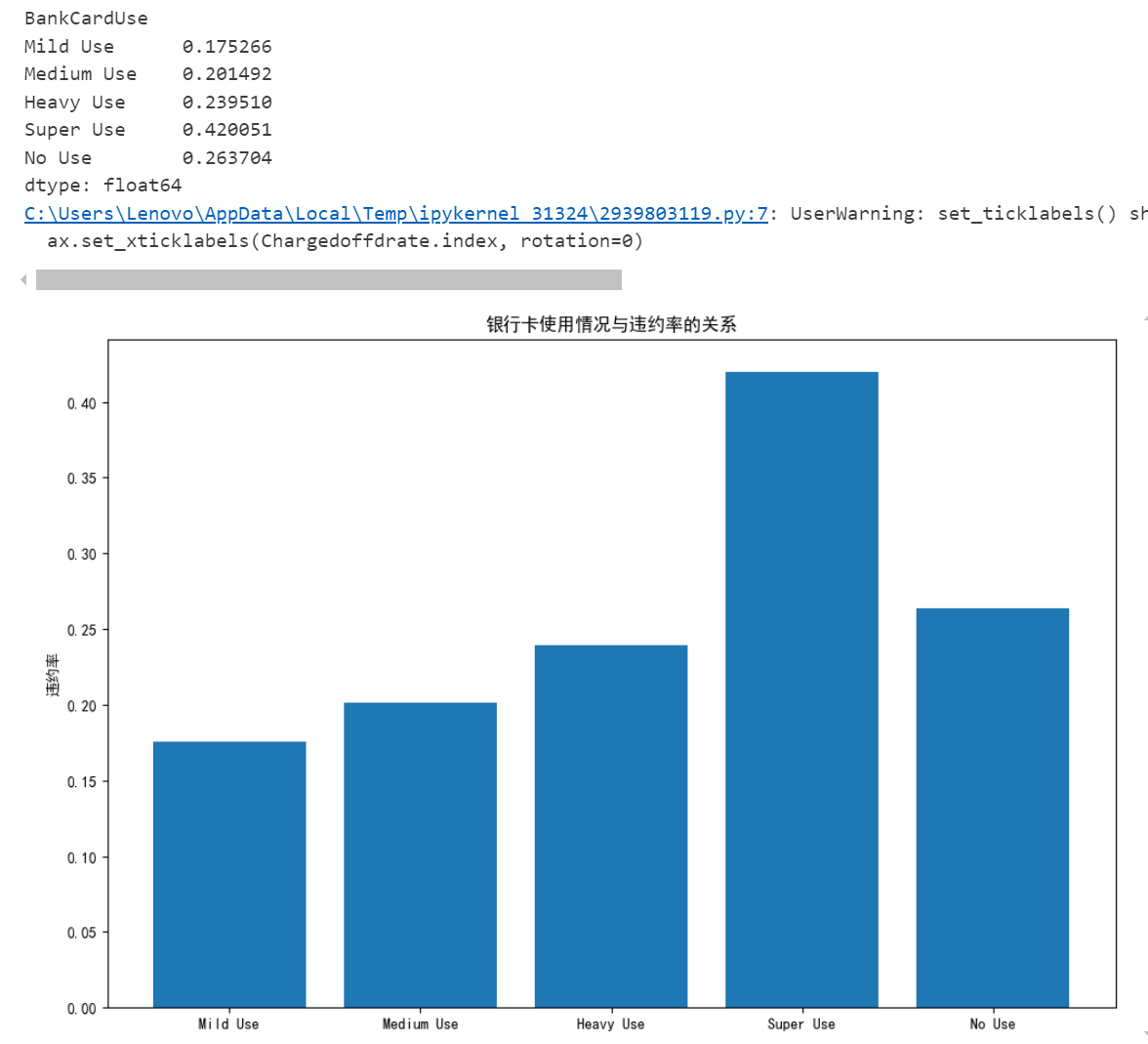
如图所示:在所有信用卡使用程度中,“Heavy Use ”组的总人数最多,同时“Chargedoff ”比例相对较高,约为30%左右,“Super Use”组的人数最少,但“Chargedoff ”的比例也相对较低。同时也可以看出银行卡的使用程度与违约率之间存在正相关关系。也就是说,随着银行卡使用程度的增加,违约率也随之上升。特别是当使用程度达到“超级使用”时,违约率出现了显著的增长。然而,即便是在“不使用”状态下,违约率也没有降到很低的程度,这可能意味着除了银行卡使用外,还存在其他因素影响违约率。总之,信用卡使用的频率越高,完成还款的比例也越高,但同时违约的风险也越大。
3. 消费者收入(Income Range)越低,违约概率越大。
incomerange=loanData.groupby(['LoanStatus','IncomeRange'])['IncomeRange'].count().unstack(0)
index=['Not displayed','Not employed','$0', '$1-24,999', '$25,000-49,999', '$50,000-74,999', '$75,000-99,999', '$100,000+']
incomerange=incomerange.reindex(index)
print(incomerange)
fig=plt.figure()
fig.set_size_inches(12,8)
ax=fig.add_subplot(111)
incomerange.plot(kind='bar',ax=ax)
ax.set_xticklabels(index,rotation=0)
ax.set_ylabel('数量')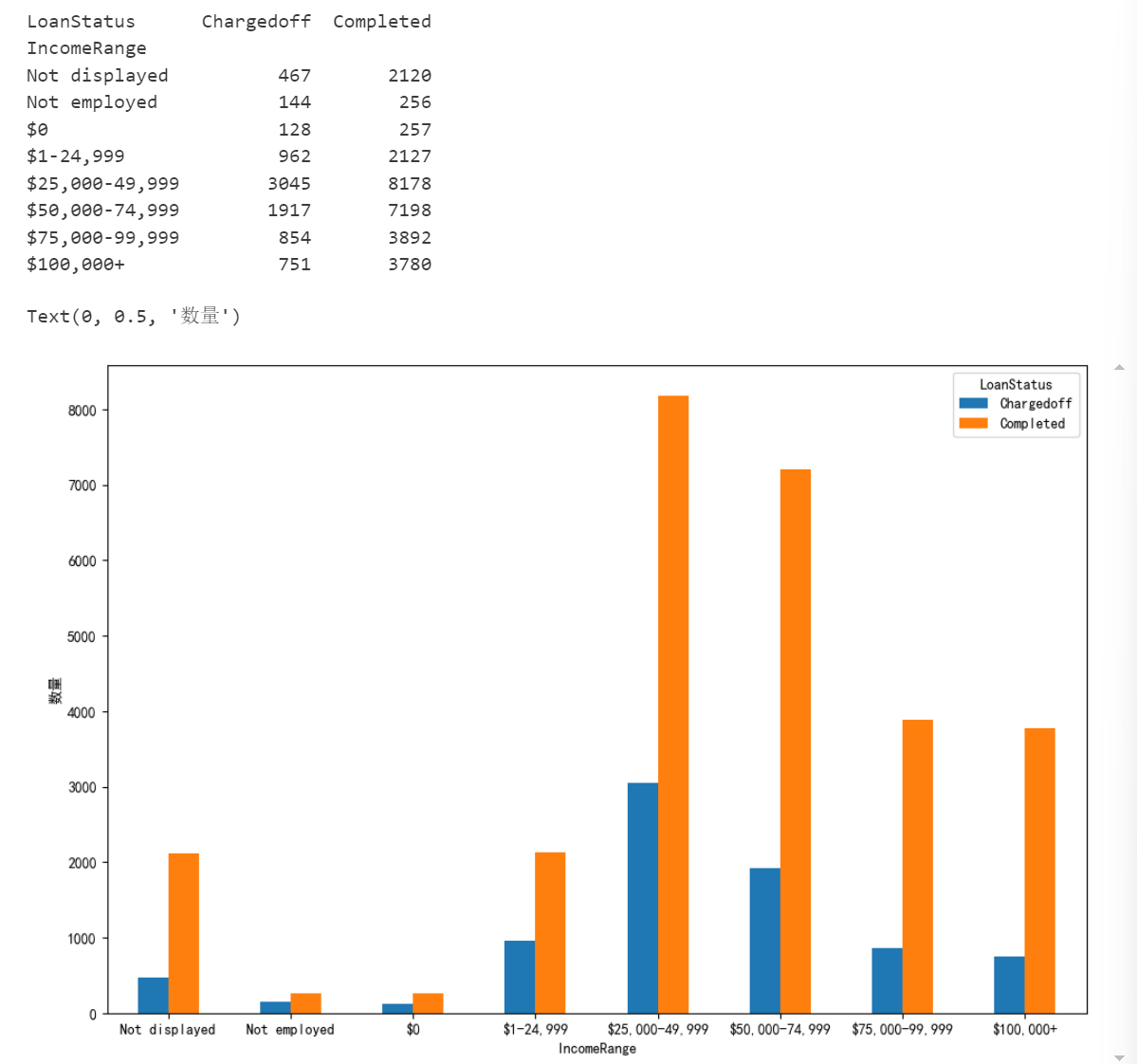
Chargedoffdrate=incomerange['Chargedoff']/(incomerange['Chargedoff']+incomerange['Completed'])
print(Chargedoffdrate)
plt.figure(figsize=(12,8))
ax = plt.gca()
ax.bar(Chargedoffdrate.index, Chargedoffdrate)
ax.set_xticklabels(Chargedoffdrate.index, rotation=0)
ax.set_ylabel('违约率')
ax.set_title('收入范围与违约率的关系')
plt.show()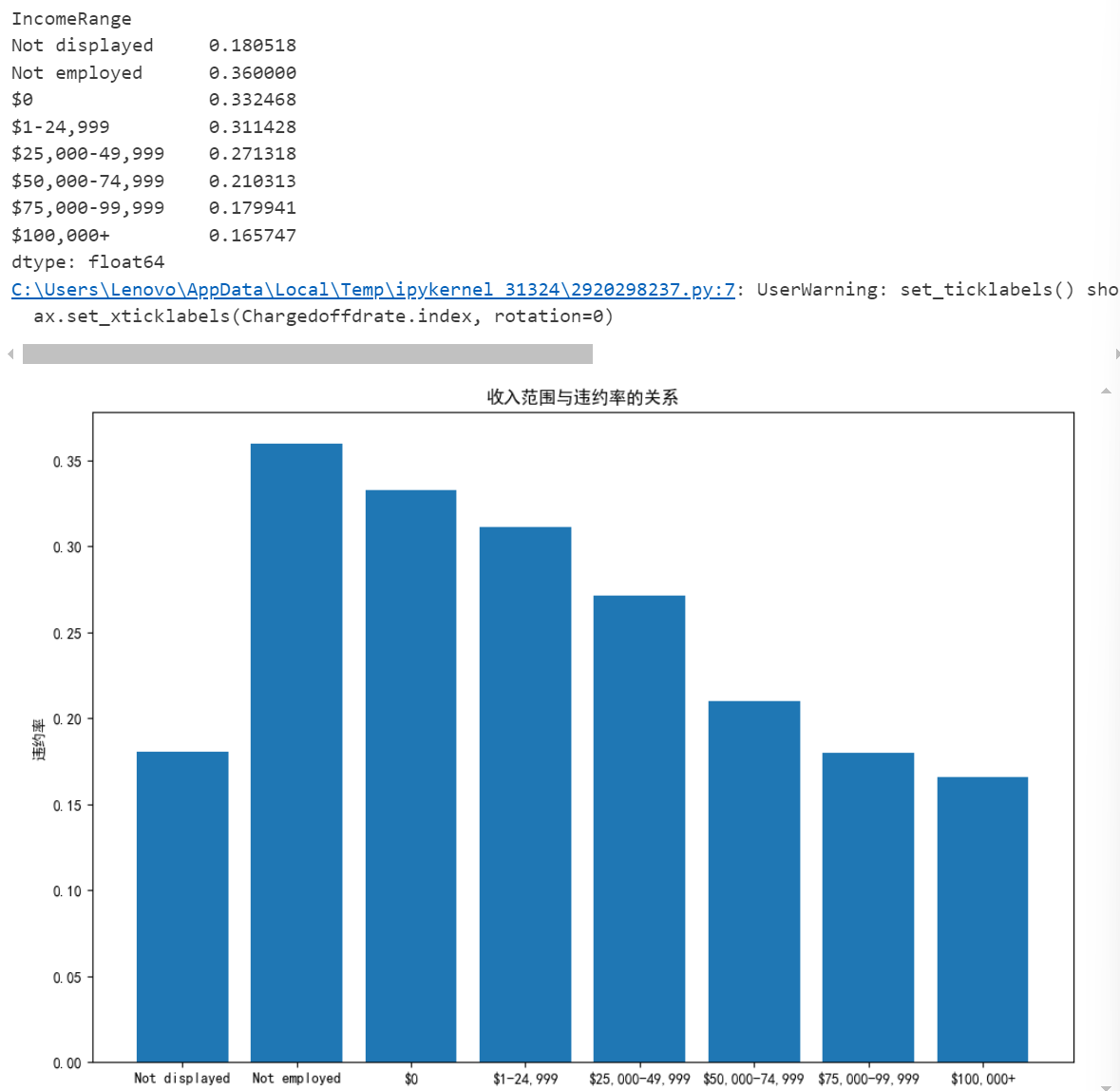
由图可知:收入水平与贷款状态之间存在着明显的关联性。随着收入的增加,贷款完成的比例先升后降,而在所有收入范围内,“Chargedoff”的比例始终低于“Completed”。这表明即使在高收入人群中,也可能面临较高的违约风险。收入水平与违约率之间存在负相关关系,即收入越高,违约率越低,收入越低,违约率越高。即使在高收入群体中,违约率也不是零,这意味着无论收入多少,都有可能发生违约事件。
4. 信用评级(CombinedRating)越低,违约概率越大。
CombinedRating=loanData.groupby(['LoanStatus','CombinedRating'])['LoanStatus'].count().unstack(0)
index=[ 'HR','E','D','C','B', 'A', 'AA']
CombinedRating=CombinedRating.reindex(index)
fig=plt.figure()
fig.set_size_inches(8,8)
ax=fig.add_subplot(111)
CombinedRating.plot(kind='bar',ax=ax)
ax.set_xticklabels(index,rotation=0)
ax.set_ylabel('数量') 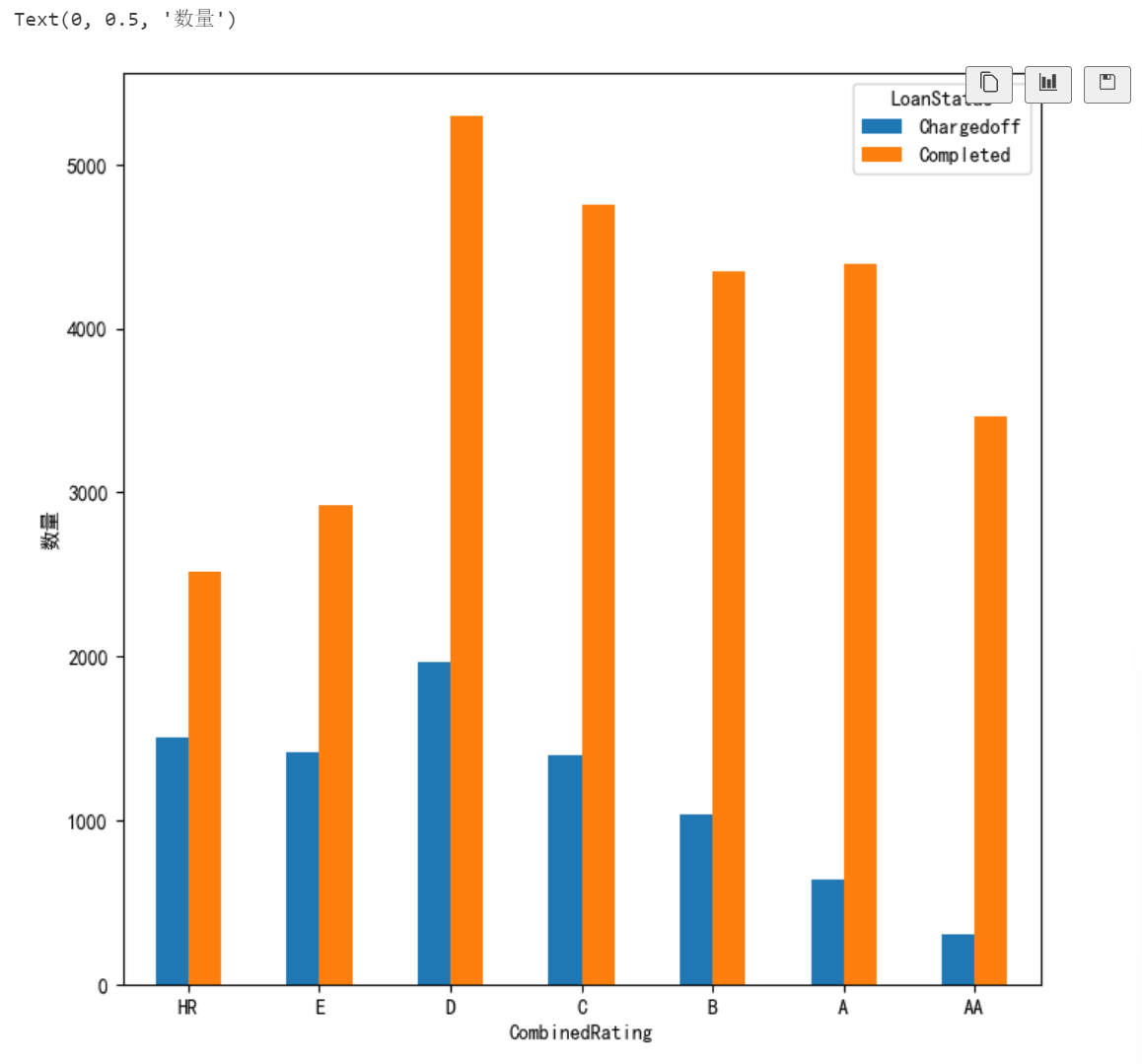
Chargedoffdrate=CombinedRating['Chargedoff']/(CombinedRating['Chargedoff']+CombinedRating['Completed'])
plt.figure(figsize=(12,8))
ax = plt.gca()
bars = ax.bar(Chargedoffdrate.index, Chargedoffdrate)
ax.bar(Chargedoffdrate.index, Chargedoffdrate)
ax.set_xticklabels(Chargedoffdrate.index, rotation=0)
ax.set_ylabel('违约率')
ax.set_title('信用评级与违约率的关系')
bar_centers = np.arange(len(Chargedoffdrate))
bar_width = bars[0].get_width()
bar_centers = bar_centers + bar_width / 2
# 在每个条形上方添加文本标签
for center, rate in zip(bar_centers, Chargedoffdrate):
plt.text(center, rate + 0.001, '%.2f%%' % (rate * 100), ha='center', va='bottom')
plt.show()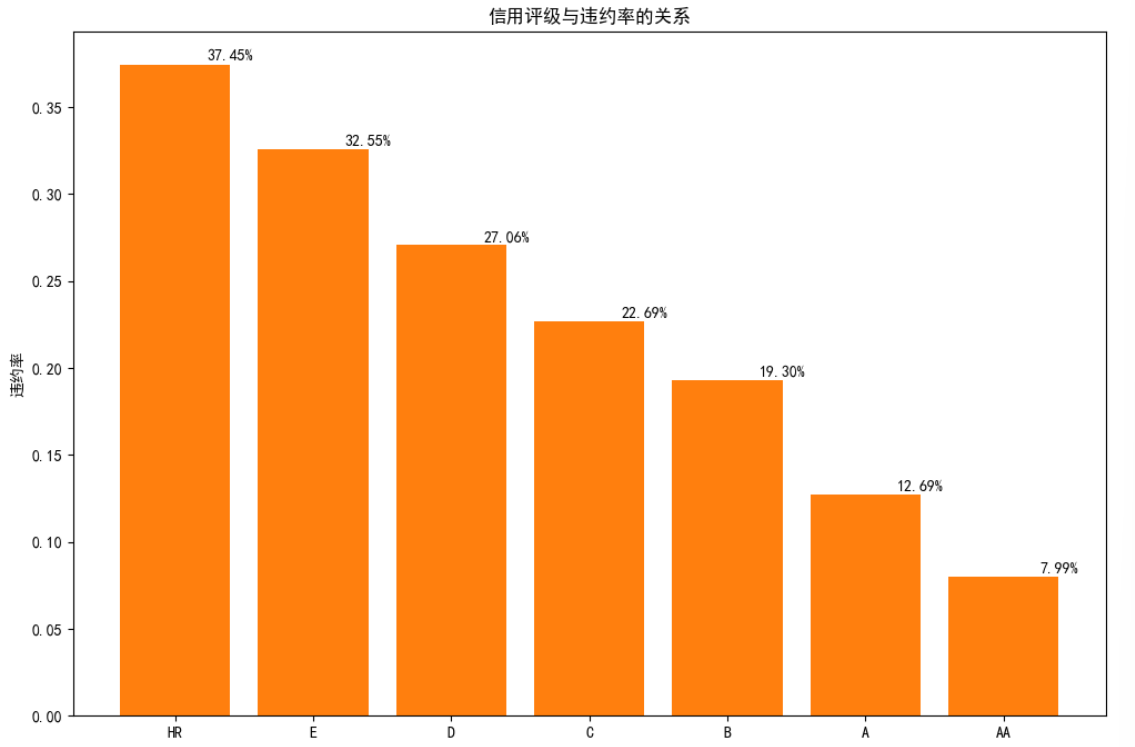
由图可知:随着信用评级的提高,贷款的完成率显著提升,而违约率则逐步下降。这表明评级系统有效地反映了借款人的信用状况,有助于预测未来的还款行为。总之,信用评级与违约率之间存在明显的负相关关系,信用评级越高的客户,其违约的可能性越小,反之,信用评级越低的客户,其违约率越高。
5. 新客户的表现优于老客户,违约率更低。
#按照贷款总数划分
def TotalProsper_Loans(s):
if s>0:
d='Previous Borrower'
else:
d='New Borrower'
return d
loanData['CustomerClarify']=loanData['TotalProsperLoans'].apply(TotalProsper_Loans)
Data['CustomerClarify']=Data['TotalProsperLoans'].apply(TotalProsper_Loans)
CustomerClarify=loanData.groupby(['LoanStatus','CustomerClarify'])['CustomerClarify'].count().unstack(0)
index=['Previous Borrower','New Borrower']
CustomerClarify=CustomerClarify.reindex(index)
print(CustomerClarify)
fig=plt.figure()
fig.set_size_inches(12,8)
ax=fig.add_subplot(111)
CustomerClarify.plot(kind='bar',ax=ax)
ax.set_xticklabels(index,rotation=0)
ax.set_ylabel('数量')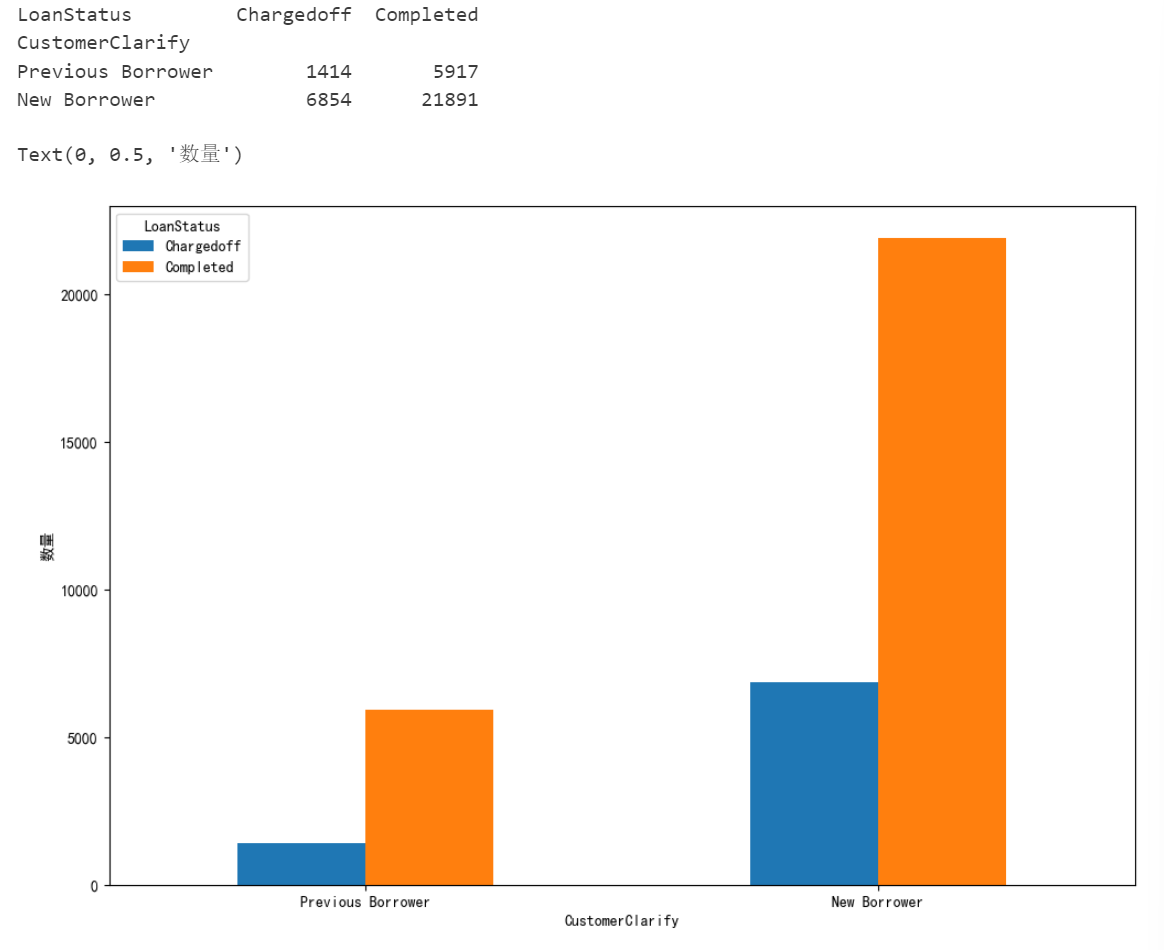
Chargedoffrate=CustomerClarify['Chargedoff']/(CustomerClarify['Chargedoff']+CustomerClarify['Completed'])
print(Chargedoffrate)
plt.figure(figsize=(12,8))
ax = plt.gca()
ax.bar(Chargedoffdrate.index, Chargedoffdrate)
ax.set_xticklabels(Chargedoffdrate.index, rotation=0)
ax.set_ylabel('违约率')
ax.set_title('贷款者身份与违约率的关系')
plt.show()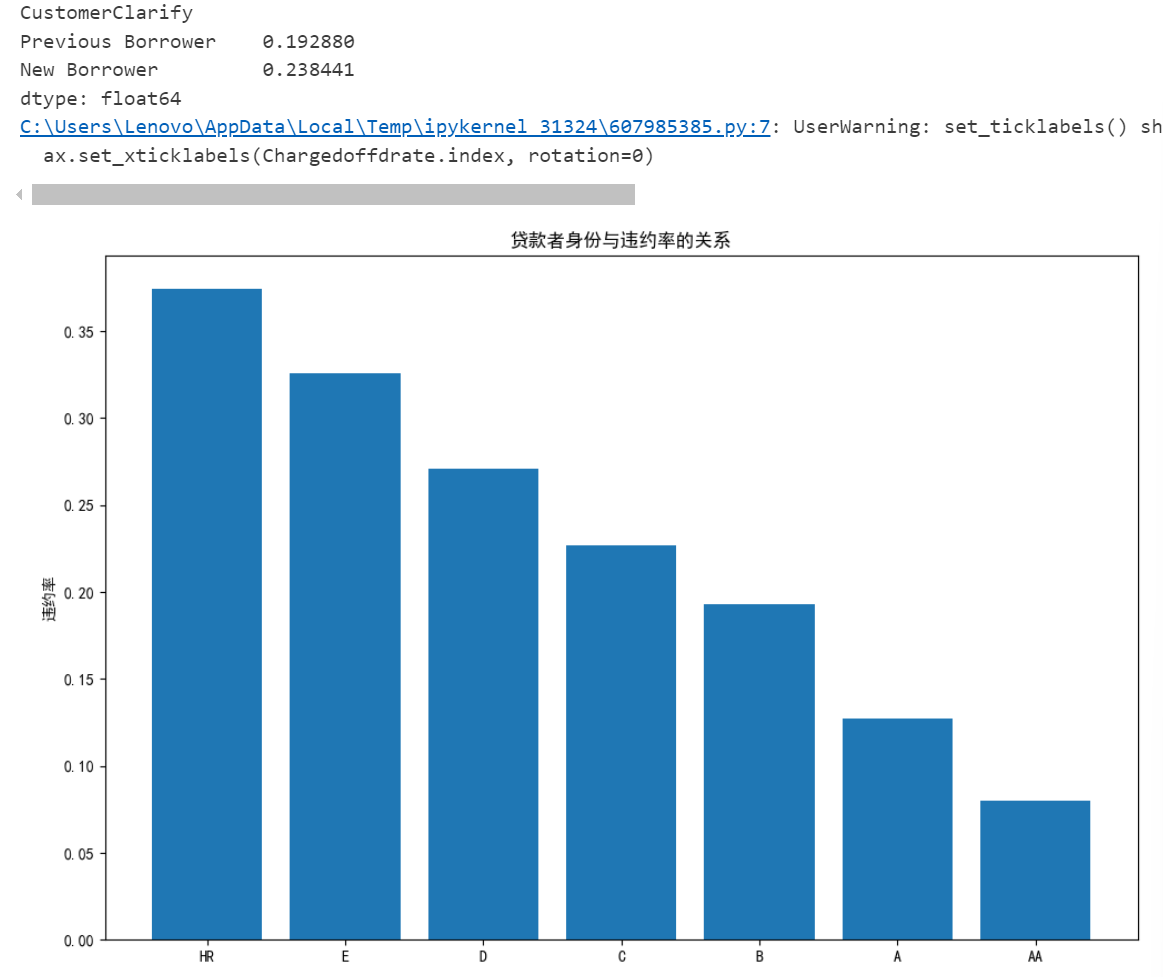
由图可知:新客户的“Completed”数量远大于“Chargedoff”,表明新客户中完成贷款的比例很高,而违约(即被核销)的比例相对较低;相比之下,老客户的“Completed”数量较少,而“Charged off”的数量也相对较少,但两者的差距不如新客户那么大。而且随着借款者身份等级的提高,违约率呈下降趋势。他们之间存在着明显的负相关关系,身份等级越高的借款人,其违约的可能性越小。反之身份等级越低其违约的可能性越大。
三、模型构建
# 检查并打印每列的缺失值数量
columns_to_check = ['CreditScore','CombinedRating','BankCardUse','CustomerClarify', 'IncomeRange']
print('train数据:')
for column in columns_to_check:
missing_values = loanData[column].isnull().sum()
missing_rate = loanData[column].isnull().mean() # 缺失率
display(f"{column}: {missing_values} missing values, missing rate: {missing_rate:.2%}")
print('---------------------------------------')
print('test数据:')
for column in columns_to_check:
missing_values = Data[column].isnull().sum()
display(f"{column}: {missing_values} missing values")
loanData['CreditScore']=loanData['CreditScore'].fillna(loanData['CreditScore'].median()) #中位数
Data['CreditScore']=Data['CreditScore'].fillna(Data['CreditScore'].median())
missindex=loanData[(loanData['CombinedRating'].isnull())]
loanData=loanData.drop(missindex.index,axis=0)
missindex=Data[(Data['CombinedRating'].isnull())]
Data=Data.drop(missindex.index,axis=0)
print("修改后")
# 检查并打印每列的缺失值数量
print('train数据:')
for column in columns_to_check:
missing_values = loanData[column].isnull().sum()
display(f"{column}: {missing_values} missing values")
print('---------------------------------------')
print('test数据:')
for column in columns_to_check:
missing_values = Data[column].isnull().sum()
missing_rate = Data[column].isnull().mean() # 缺失率
display(f"{column}: {missing_values} missing values, missing rate: {missing_rate:.2%}")
le = LabelEncoder()
for column in ['CombinedRating', 'IncomeRange', 'BankCardUse', 'CustomerClarify']:
loanData[column] = le.fit_transform(loanData[column])
Data[column] = le.fit_transform(Data[column])
# 编码目标变量
loanData['LoanStatus'] = le.fit_transform(loanData['LoanStatus'])
Data['LoanStatus'] = le.fit_transform(Data['LoanStatus'])
# 定义特征列和目标列
feature_columns = ['CreditScore','CombinedRating','BankCardUse','CustomerClarify', 'IncomeRange','违约率']
target_column = 'LoanStatus' # 假设这是违约状态的标签,且为字符串类型(如'违约'和'非违约')
# 预处理数据
X_train = loanData[feature_columns]
y_train = loanData[target_column]
X_test = Data[feature_columns]
y_test = Data[target_column]
#lag
lgb_train=lgb.Dataset(X_train,y_train)
lgb_test=lgb.Dataset(X_test,y_test,reference=lgb_train)
params={"num_leaves":100,"objective":"binary","boosting":"gbdt","metric":{"binary_logloss","auc"}}
clf=lgb.train(params,lgb_train,num_boost_round=200,valid_sets=lgb_test,feature_name=feature_columns)
print(clf)
probs=clf.predict(X_test,num_iteration=clf.best_iteration)
print(probs)preds=[0 if each <0.5 else 1 for each in probs]
print(preds)![]()
四、模型评估
count=0
for i in range(len(preds)):
if preds[i]==y_test.iloc[i]:
count+=1
print('准确率是{}'.format(count/len(preds)))![]()
# 计算PRAUC
prauc = average_precision_score(y_test, probs)
print(f'PRAUC: {prauc:.4f}')
#计算RMSCE
actual_default_rates = Data['违约率']
rmsce = np.sqrt(np.mean((1-probs - actual_default_rates) ** 2))
print(f"RMSCE: {rmsce:.4f}") 
#计算PRAUC-RMSCE
prauc_rmsce=prauc-rmsce
print(prauc_rmsce)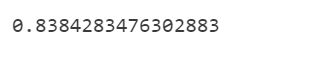

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)