Redis Module 模块组件(搜索、json、时序数据、图数据、布隆过滤器、限流、推荐、机器学习等)
Redis 本身有比较丰富的数据类型,例如 String、Hash、Set、ListJSON 是我们常用的数据类型,当我们需要在 Redis 中保存 json 数据时是怎么存放的呢?虽然 Redis 有大量的核心数据结构,但是没有一个符合 JSON 的要求。当然可以通过使用其他数据类型来解决问题:比如在实际项目中,我们经常会使用 Strings 来存储原始的序列化 JSON 串;或者使用 Hash
介绍
首先介绍下RedisMod这个东西,它是一系列Redis的增强模块。有了RedisMod的支持,Redis的功能将变得非常强大。目前RedisMod中大体包含了如下增强模块:
- RediSearch:一个功能齐全的搜索引擎;
- RedisJSON:对JSON类型的原生支持;
- RedisTimeSeries:时序数据库支持;
- RedisGraph:图数据库支持;
- RedisBloom:概率性数据的原生支持;
- RedisGears:可编程的数据处理;
- RedisAI:机器学习的实时模型管理和部署。
- RedisML:推荐系统
- Redis-cell:限流
更多模块可以看redis官方网站:https://redis.io/docs/modules/
注意事项
不同版本表现不同,不仅仅拓展有版本,语言的API也有版本。由于不是redis官方的实现,需要小心注意具体的结果。
安装
docker安装所有mod
我们需要安装带所有RedisMod的Redis,使用Docker来安装非常方便的!
先sudo su
使用如下命令下载RedisMod的镜像;
docker pull redislabs/redismod:preview
在容器中运行RedisMod服务。
docker run -p 6379:6379 --name redismod \
-v /mydata/redismod/data:/data \
-d redislabs/redismod:preview
此时可以使用常规手段连接了,如果想要直接用cli命令行工具的话:
#进入redis
$ docker exec -it redismod bash
#启用redis-cli
$ redis-cli
#然后就可以输入redis命令了 如
$ set test 1
ok
get test
1
docker单独安装
# 以redis json为例
# https://hub.docker.com/r/redislabs/rejson
docker run -p 6379:6379 --name redis-redisjson redislabs/rejson:latest
如果你之前已经安装了redis 会提示端口已被占用,而且这里的redis可能和官方最新版有差距
所以不是很推荐这种方法单独安装。
有没有除了下面那种方法,docker单独安装拓展的呢?
源码单独安装-以redis search为例
可以先安装官方的redis镜像,再在docker里单独安装
如果不想使用 Docker,我们也可以使用源码的方式进行安装,安装命令如下:
- 首先安装 redis 4.0以上版本(略)
- 安装相关系统依赖
- 安装 redis 模块
- redis 加载 redis 模块
安装依赖
yum groupinstall "Development Tools"
#(这是 centos 中的安装方法,ubuntu 可以使用这个命令
# apt-get install build-essential )
安装模块
git clone https://github.com/RedisLabsModules/RediSearch.git
cd RediSearch # 进入模块目录
make all
安装完成之后,可以使用如下命令启动 Redis 并加载 RediSearch 模块,命令如下:
src/redis-server redis.conf --loadmodule ../RediSearch/src/redisearch.so
在启动信息中会看到模块 的相关信息(rejson为例)
<ReJSON> JSON data type for Redis
Redis Search
redis search 基本语法
使用RediSearch来搜索数据之前,我们得先创建下索引,建立索引的语法有点复杂,我们先来看下;
FT.CREATE {index}
[ON {data_type}]
[PREFIX {count} {prefix} [{prefix} ..]
[LANGUAGE {default_lang}]
SCHEMA {identifier} [AS {attribute}]
[TEXT | NUMERIC | GEO | TAG ] [CASESENSITIVE]
[SORTABLE] [NOINDEX]] ...
使用FT.CREATE命令可以建立索引,语法中的参数意义如下;
index:索引名称;
data_type:建立索引的数据类型,目前支持JSON或者HASH两种;
PREFIX:通过它可以选择需要建立索引的数据前缀,比如PREFIX 1 "product:"表示为键中以product:为前缀的数据建立索引;
LANGUAGE:指定TEXT类型属性的默认语言,使用chinese可以设置为中文;
identifier:指定属性名称;
attribute:指定属性别名;
TEXT | NUMERIC | GEO | TAG:这些都是属性可选的类型;
SORTABLE:指定属性可以进行排序。
注意:这里必须要设置语言编码为中文,也就是“language “chinese””,默认是英文编码,如果不设置则无法支持中文查询(无法查出结果)。
示例
创建索引:
FT.CREATE myIdx ON HASH PREFIX 1 doc:
SCHEMA
title TEXT WEIGHT 5.0
body TEXT
url TEXT
添加数据:
hset doc:1 title "hello world" body "Love Redis" url "http://redis.io"
查找:
> FT.SEARCH myIdx "hello world" LIMIT 0 10
1) (integer) 1 //多少个结果
2) "doc:1" //key名
3) 1) "title" //属性1
2) "hello world"//结果
3) "body"//属性2
4) "Love Redis"
5) "url"////属性3
6) "http://redis.io"
注意:当前查询只支持ASCII和UTF-8
(下面的不用放ppt上了)
删除
> FT.DROPINDEX myIdx
OK
自动补全建议
> FT.SUGADD autocomplete "hello world" 100
OK
> FT.SUGGET autocomplete "he"
1) "hello world"
语法
RediSearch的搜索语法比较复杂,不过我们可以对比SQL来使用它,具体可以参考下表。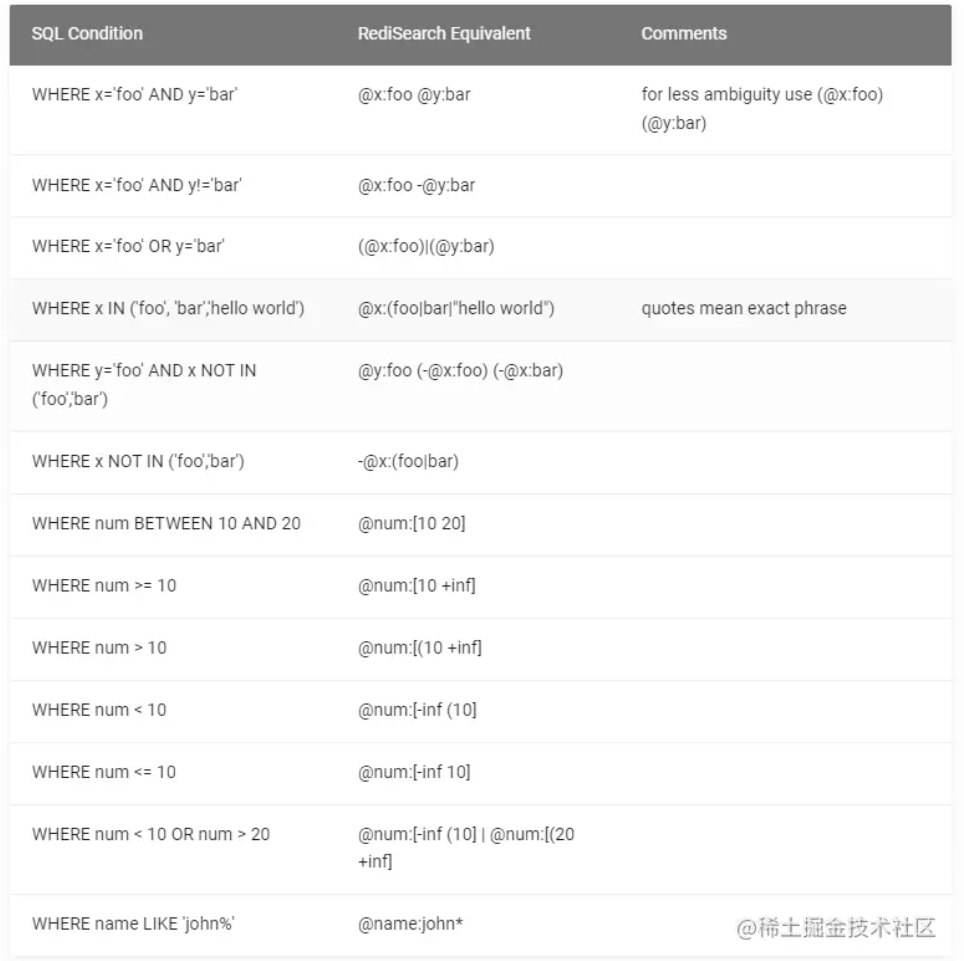
性能对比查看:https://www.proyy.com/7073276818425380872.html
Redis JSON
介绍
Redis 本身有比较丰富的数据类型,例如 String、Hash、Set、List
JSON 是我们常用的数据类型,当我们需要在 Redis 中保存 json 数据时是怎么存放的呢?
虽然 Redis 有大量的核心数据结构,但是没有一个符合 JSON 的要求。当然可以通过使用其他数据类型来解决问题:比如在实际项目中,我们经常会使用 Strings 来存储原始的序列化 JSON 串;或者使用 Hashes 来展示 JSON 对象。但是这并不是原生的 JSON,并且只是在少数地方去用。这种体验会留下一种非 Redis 的感觉,并且它们的笨拙与通常使用 Redis 的简单和优雅产生了很大的冲突。
但是借助于 Redis 提供的模块化,Itamar Haber 以及 Dvir Volk 一伙人就开始了 RedisJSON 模块的开发工作。RedisJSON 模块提供了一种新的数据类型,用于快速高效的处理 JSON 。像其他 Redis 数据类型一样,RedisJSON 的值存储在对应的 keys 中,并且可以通过一个专门的命令子集访问。通过这些命令或模块暴露的 API,就可以在 Redis 上对 JSON 进行相应的操作。
rejson 是一个为 redis 提供了 json 存储能力的模块,有了它Redis就可以存储原生JSON类型数据了,通过它你可以很方便地访问JSON中的各个属性,类似在MongoDB中那样
Docker 镜像地址: https://hub.docker.com/r/redislabs/rejson
Github 地址:https://github.com/RedisJSON/RedisJSON
官方文档:https://oss.redis.com/redisjson/
使用
简单示例
# .或者$是json文档的root,后面的一串是具体的 json 数据值[注意.或者$前后有空格]
# 命令大小写均可 如json.set
> JSON.SET testkey . '{"foo": "bar", "ans": 42}'
> # OR > JSON.SET testkey $ '{"foo": "bar", "ans": 42}'
OK
> JSON.GET testkey
"{\"foo\":\"bar",\"ans\":42}"
获取某字段的值
# 命令中的 .ans 是目标路径,表示 root 下面的 ans
> JSON.GET object .ans
"42"
# 还支持这种多查询
JSON.GET product:1 .foo .ans
# 如果是数组,那么可以
JSON.GET example $[1]
设置某字段值
# 这个命令是在 root 下新增了一个字段 name,值为 bill
> json.set object .name '"bill"'
# 也可以修改已有字段的值,用法相同
删除字段
> json.del object .name
(integer) 1
数字操作
# ans 字段是数字类型,值为 42,下面对其执行 +3 操作
> json.numincrby object .ans 3
"45"
> json.nummultby object .ans 2
"90"
> json.get object
"{\"foo\":\"bar\",\"ans\":90,\"hi\":\"hello\"}"
还有很多其他操作命令,具体可以查看项目文档
# 字符串长度
JSON.STRLEN animal $
#字符串append
JSON.STRAPPEND animal $ '" (Canis familiaris)"'
127.0.0.1:6379> JSON.SET obj $ '{"name":"Leonard Cohen","lastSeen":1478476800,"loggedOut": true}'
OK
127.0.0.1:6379> JSON.OBJLEN obj $
1) (integer) 3
127.0.0.1:6379> JSON.OBJKEYS obj $
1) 1) "name"
2) "lastSeen"
3) "loggedOut"
To return a JSON response in a more human-readable format, run redis-cli in raw output mode and include formatting keywords such as INDENT, NEWLINE, and SPACE with the JSON.GET command:
$ redis-cli --raw
127.0.0.1:6379> JSON.GET obj INDENT "\t" NEWLINE "\n" SPACE " " $
[
{
"name": "Leonard Cohen",
"lastSeen": 1478476800,
"loggedOut": true
}
]
性能
每当调用 JSON.SET 时,模块都会通过流词法分析器( streaming lexer)来解析输入的 JSON 并对其构建树形数据结构,如下图所示: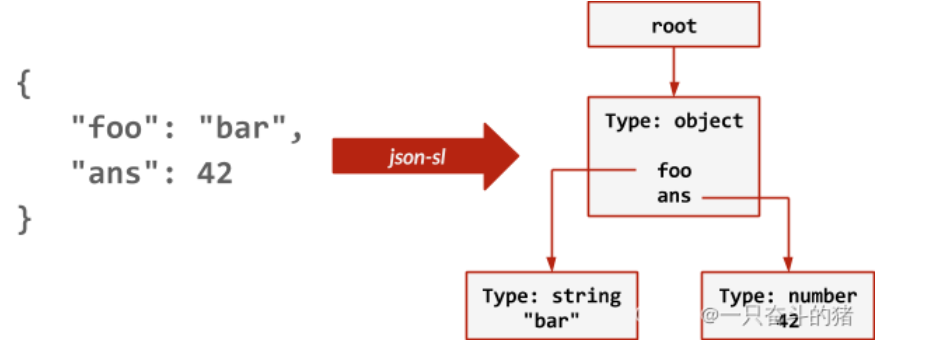
RedisJSON 将数据以二进制格式存储在树的节点上,并支持 JSONPath 的子集,以便于子元素的引用。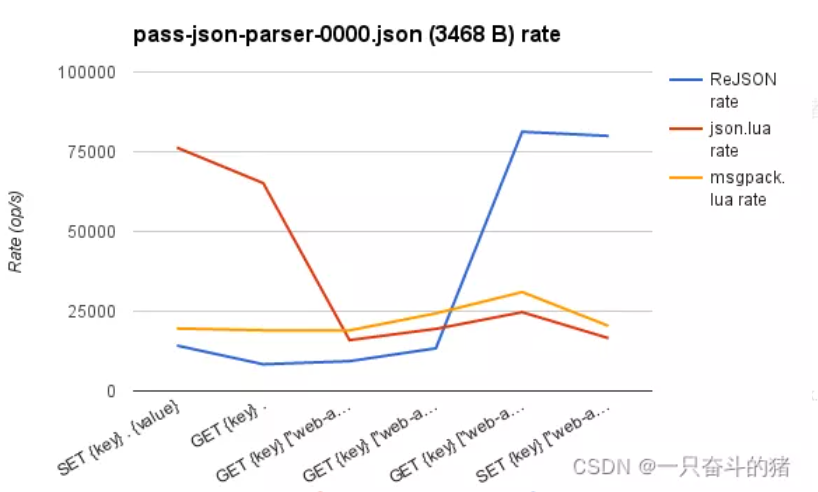
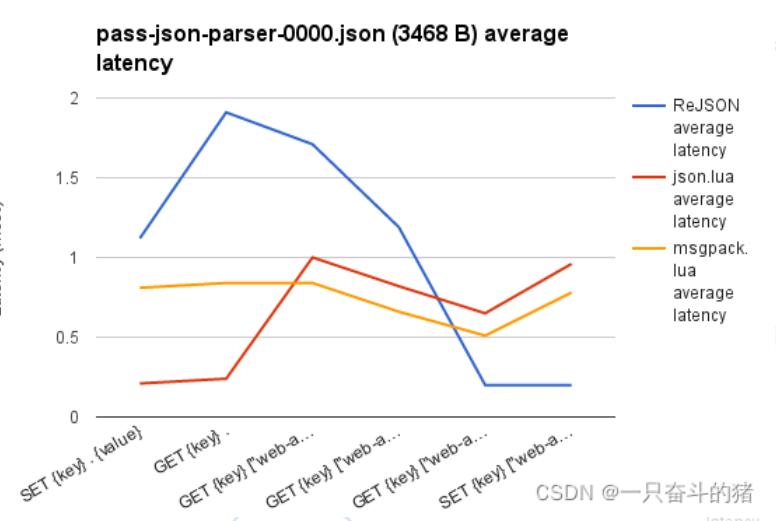
上面两个图比较了在具有三个嵌套级别的 3.4KB JSON 负载上执行的读写操作的速率( operations/sec,操作数/秒)和平均延迟(ms,毫秒)。 RedisJSON 与两种将数据存储在字符串中的变体进行比较。 两种变体都作为 Redis 服务器端 Lua 脚本实现,其中 json.lua 变体存储原始序列化 JSON,而 msgpack.lua 使用的是 MessagePack 编码。
【注】从图中可以看出 RedisJSON 在处理 JSON 嵌套时性能确实高于其他两种,但是处理普通的性能就比较低了,估计是做了取舍吧。
更多性能测试看:https://redis.io/docs/stack/json/performance/
redis search 与 json结合
首先 我们新建一些json数据
JSON.SET product:1 $ '{"id":1,"productSn":"7437788","name":"小米8","subTitle":"全面屏游戏智能手机 6GB+64GB 黑色 全网通4G 双卡双待","brandName":"小米","price":2699,"count":1}'
JSON.SET product:2 $ '{"id":2,"productSn":"7437789","name":"红米5A","subTitle":"全网通版 3GB+32GB 香槟金 移动联通电信4G手机 双卡双待","brandName":"小米","price":649,"count":5}'
JSON.SET product:3 $ '{"id":3,"productSn":"7437799","name":"Apple iPhone 8 Plus","subTitle":"64GB 红色特别版 移动联通电信4G手机","brandName":"苹果","price":5499,"count":10}'
对之前的商品数据建立索引
FT.CREATE productIdx ON JSON PREFIX 1 "product:" LANGUAGE chinese SCHEMA $.id AS id NUMERIC $.name AS name TEXT $.subTitle AS subTitle TEXT $.price AS price NUMERIC SORTABLE $.brandName AS brandName TAG
FT.CREATE productIdx ON JSON PREFIX 1 "product:"
LANGUAGE chinese
SCHEMA $.id AS id NUMERIC
$.name AS name TEXT
$.subTitle AS subTitle TEXT
$.price AS price NUMERIC SORTABLE
$.brandName AS brandName TAG
开始查询
- 由于我们设置了price字段为SORTABLE,我们可以以price降序返回商品信息;
> FT.SEARCH productIdx * SORTBY price DESC
1) (integer) 3
2) "product:3"
3) 1) "price"
2) "5499"
3) "$"
4) "{\"id\":3,\"productSn\":\"7437799\",\"name\":\"Apple iPhone 8 Plus\",\"subTitle\":\"64GB \xe7\xba\xa2\xe8\x89\xb2\xe7\x89\xb9\xe5\x88\xab\xe7\x89\x88 \xe7\xa7\xbb\xe5\x8a\xa8\xe8\x81\x94\xe9\x80\x9a\xe7\x94\xb5\xe4\xbf\xa14G\xe6\x89\x8b\xe6\x9c\xba\",\"brandName\":\"\xe8\x8b\xb9\xe6\x9e\x9c\",\"price\":5499,\"count\":10}"
4) "product:1"
5) 1) "price"
2) "2699"
3) "$"
4) "{\"id\":1,\"productSn\":\"7437788\",\"name\":\"\xe5\xb0\x8f\xe7\xb1\xb38\",\"subTitle\":\"\xe5\x85\xa8\xe9\x9d\xa2\xe5\xb1\x8f\xe6\xb8\xb8\xe6\x88\x8f\xe6\x99\xba\xe8\x83\xbd\xe6\x89\x8b\xe6\x9c\xba 6GB+64GB \xe9\xbb\x91\xe8\x89\xb2 \xe5\x85\xa8\xe7\xbd\x91\xe9\x80\x9a4G \xe5\x8f\x8c\xe5\x8d\xa1\xe5\x8f\x8c\xe5\xbe\x85\",\"brandName\":\"\xe5\xb0\x8f\xe7\xb1\xb3\",\"price\":2699,\"count\":1}"
6) "product:2"
7) 1) "price"
2) "649"
3) "$"
4) "{\"id\":2,\"productSn\":\"7437789\",\"name\":\"\xe7\xba\xa2\xe7\xb1\xb35A\",\"subTitle\":\"\xe5\x85\xa8\xe7\xbd\x91\xe9\x80\x9a\xe7\x89\x88 3GB+32GB \xe9\xa6\x99\xe6\xa7\x9f\xe9\x87\x91 \xe7\xa7\xbb\xe5\x8a\xa8\xe8\x81\x94\xe9\x80\x9a\xe7\x94\xb5\xe4\xbf\xa14G\xe6\x89\x8b\xe6\x9c\xba \xe5\x8f\x8c\xe5\x8d\xa1\xe5\x8f\x8c\xe5\xbe\x85\",\"brandName\":\"\xe5\xb0\x8f\xe7\xb1\xb3\",\"price\":649,\"count\":5}"
- 指定返回的字段
>FT.SEARCH productIdx * RETURN 3 name subTitle price
1) (integer) 3
2) "product:3"
3) 1) "name"
2) "Apple iPhone 8 Plus"
3) "subTitle"
4) "64GB \xe7\xba\xa2\xe8\x89\xb2\xe7\x89\xb9\xe5\x88\xab\xe7\x89\x88 \xe7\xa7\xbb\xe5\x8a\xa8\xe8\x81\x94\xe9\x80\x9a\xe7\x94\xb5\xe4\xbf\xa14G\xe6\x89\x8b\xe6\x9c\xba"
5) "price"
6) "5499"
4) "product:1"
5) 1) "name"
2) "\xe5\xb0\x8f\xe7\xb1\xb38"
3) "subTitle"
4) "\xe5\x85\xa8\xe9\x9d\xa2\xe5\xb1\x8f\xe6\xb8\xb8\xe6\x88\x8f\xe6\x99\xba\xe8\x83\xbd\xe6\x89\x8b\xe6\x9c\xba 6GB+64GB \xe9\xbb\x91\xe8\x89\xb2 \xe5\x85\xa8\xe7\xbd\x91\xe9\x80\x9a4G \xe5\x8f\x8c\xe5\x8d\xa1\xe5\x8f\x8c\xe5\xbe\x85"
5) "price"
6) "2699"
6) "product:2"
7) 1) "name"
2) "\xe7\xba\xa2\xe7\xb1\xb35A"
3) "subTitle"
4) "\xe5\x85\xa8\xe7\xbd\x91\xe9\x80\x9a\xe7\x89\x88 3GB+32GB \xe9\xa6\x99\xe6\xa7\x9f\xe9\x87\x91 \xe7\xa7\xbb\xe5\x8a\xa8\xe8\x81\x94\xe9\x80\x9a\xe7\x94\xb5\xe4\xbf\xa14G\xe6\x89\x8b\xe6\x9c\xba \xe5\x8f\x8c\xe5\x8d\xa1\xe5\x8f\x8c\xe5\xbe\x85"
5) "price"
6) "649"
我们把brandName设置为了TAG类型,我们可以使用如下语句查询品牌为小米或苹果的商品;
> FT.SEARCH productIdx '@brandName:{小米 | 苹果}'
1) (integer) 3
2) "product:3"
3) 1) "$"
2) "{\"id\":3,\"productSn\":\"7437799\",\"name\":\"Apple iPhone 8 Plus\",\"subTitle\":\"64GB \xe7\xba\xa2\xe8\x89\xb2\xe7\x89\xb9\xe5\x88\xab\xe7\x89\x88 \xe7\xa7\xbb\xe5\x8a\xa8\xe8\x81\x94\xe9\x80\x9a\xe7\x94\xb5\xe4\xbf\xa14G\xe6\x89\x8b\xe6\x9c\xba\",\"brandName\":\"\xe8\x8b\xb9\xe6\x9e\x9c\",\"price\":5499,\"count\":10}"
4) "product:1"
5) 1) "$"
2) "{\"id\":1,\"productSn\":\"7437788\",\"name\":\"\xe5\xb0\x8f\xe7\xb1\xb38\",\"subTitle\":\"\xe5\x85\xa8\xe9\x9d\xa2\xe5\xb1\x8f\xe6\xb8\xb8\xe6\x88\x8f\xe6\x99\xba\xe8\x83\xbd\xe6\x89\x8b\xe6\x9c\xba 6GB+64GB \xe9\xbb\x91\xe8\x89\xb2 \xe5\x85\xa8\xe7\xbd\x91\xe9\x80\x9a4G \xe5\x8f\x8c\xe5\x8d\xa1\xe5\x8f\x8c\xe5\xbe\x85\",\"brandName\":\"\xe5\xb0\x8f\xe7\xb1\xb3\",\"price\":2699,\"count\":1}"
6) "product:2"
7) 1) "$"
2) "{\"id\":2,\"productSn\":\"7437789\",\"name\":\"\xe7\xba\xa2\xe7\xb1\xb35A\",\"subTitle\":\"\xe5\x85\xa8\xe7\xbd\x91\xe9\x80\x9a\xe7\x89\x88 3GB+32GB \xe9\xa6\x99\xe6\xa7\x9f\xe9\x87\x91 \xe7\xa7\xbb\xe5\x8a\xa8\xe8\x81\x94\xe9\x80\x9a\xe7\x94\xb5\xe4\xbf\xa14G\xe6\x89\x8b\xe6\x9c\xba \xe5\x8f\x8c\xe5\x8d\xa1\xe5\x8f\x8c\xe5\xbe\x85\",\"brandName\":\"\xe5\xb0\x8f\xe7\xb1\xb3\",\"price\":649,\"count\":5}"
由于price是NUMERIC类型,我们可以使用如下语句查询价格在500~1000的商品;
> FT.SEARCH productIdx '@price:[500 1000]'
1) (integer) 1
2) "product:2"
3) 1) "$"
2) "{\"id\":2,\"productSn\":\"7437789\",\"name\":\"\xe7\xba\xa2\xe7\xb1\xb35A\",\"subTitle\":\"\xe5\x85\xa8\xe7\xbd\x91\xe9\x80\x9a\xe7\x89\x88 3GB+32GB \xe9\xa6\x99\xe6\xa7\x9f\xe9\x87\x91 \xe7\xa7\xbb\xe5\x8a\xa8\xe8\x81\x94\xe9\x80\x9a\xe7\x94\xb5\xe4\xbf\xa14G\xe6\x89\x8b\xe6\x9c\xba \xe5\x8f\x8c\xe5\x8d\xa1\xe5\x8f\x8c\xe5\xbe\x85\",\"brandName\":\"\xe5\xb0\x8f\xe7\xb1\xb3\",\"price\":649,\"count\":5}"
还可以通过前缀进行模糊查询,类似于SQL中的LIKE,使用*表示;
FT.SEARCH productIdx '@name:小米*'
在FT.SEARCH中直接指定搜索关键词,可以对所有TEXT类型的属性进行全局搜索,支持中文搜索,比如我们搜索下包含黑色字段的商品;
当然我们也可以指定搜索的字段,比如搜索副标题中带有红色字段的商品;
FT.SEARCH productIdx '@subTitle:红色'
通过FT.DROPINDEX命令可以删除索引,如果加入DD选项的话,会连数据一起删除;
FT.DROPINDEX productIdx
Redis RoaringBitmap
原理部分
看另一篇博客:https://blog.csdn.net/S_ZaiJiangHu/article/details/125656217
安装 介绍
一些语言,如java内置了这种数据类型,但是使用起来还是不如redis这种中间件方便。
https://github.com/aviggiano/redis-roaring
docker run -p 6379:6379 aviggiano/redis-roaring:latest
使用
官方提供的API
最新的还是去看github
基础命令
- R.SETBIT (same as SETBIT)
- R.GETBIT (same as GETBIT)
- R.BITOP (same as BITOP)
- R.BITCOUNT (same as BITCOUNT without start and end parameters)
- R.BITPOS (same as BITPOS without start and end parameters)
自己的命令
-
R.SETINTARRAY (create a roaring bitmap from an integer array)
-
R.GETINTARRAY (get an integer array from a roaring bitmap)
-
R.SETBITARRAY (create a roaring bitmap from a bit array string)
-
R.GETBITARRAY (get a bit array string from a roaring bitmap)
-
R.APPENDINTARRAY (append integers to a roaring bitmap)
-
R.RANGEINTARRAY (get an integer array from a roaring bitmap with start and end, so can implements paging)
-
R.SETRANGE (set or append integer range to a roaring bitmap)
-
R.SETFULL (fill up a roaring bitmap in integer)
-
R.STAT (get statistical information of a roaring bitmap)
-
R.OPTIMIZE (optimize a roaring bitmap)
-
R.MIN (get minimal integer from a roaring bitmap, if key is not exists or bitmap is empty, return -1)
-
R.MAX (get maximal integer from a roaring bitmap, if key is not exists or bitmap is empty, return -1)
-
R.DIFF (get difference between two bitmaps)
Missing commands:
- R.BITFIELD (same as BITFIELD)
示例
$ redis-cli
# create a roaring bitmap with numbers from 1 to 99
127.0.0.1:6379> R.SETRANGE test 1 100
# get all the numbers as an integer array
127.0.0.1:6379> R.GETINTARRAY test
# fill up the roaring bitmap
# because you need 2^32*4 bytes memory and a very long time
127.0.0.1:6379> R.SETFULL full
# use `R.RANGEINTARRAY` to get numbers from 100 to 1000
127.0.0.1:6379> R.RANGEINTARRAY full 100 1000
# append numbers to an existing roaring bitmap
127.0.0.1:6379> R.APPENDINTARRAY test 111 222 3333 456 999999999 9999990
性能表现
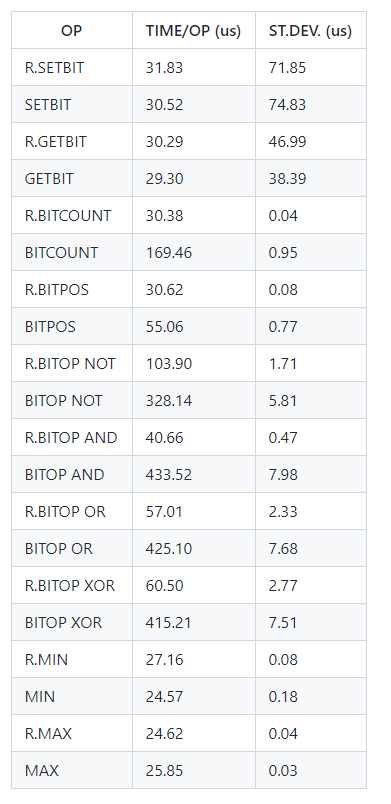
Redis TimeSeries 时间序列
转自:https://zhuanlan.zhihu.com/p/309279751 《蒋德钧 Redis核心技术与实战实践篇》 第14节
时间序列介绍
我们现在做互联网产品的时候,都有这么一个需求:记录用户在网站或者 App 上的点击行为数据,来分析用户行为。这里的数据一般包括用户 ID、行为类型(例如浏览、登录、下单等)、行为发生的时间戳。
比如一个物联网项目的数据存取需求,和这个很相似。我们需要周期性地统计近万台设备的实时状态,包括设备 ID、压力、温度、湿度,以及对应的时间戳:
DeviceID, Pressure, Temperature, Humidity, TimeStamp
这些与发生时间相关的一组数据,就是时间序列数据。
这些数据的特点是没有严格的关系模型,记录的信息可以表示成键和值的关系(例如,一个设备 ID 对应一条记录)。
所以,并不需要专门用关系型数据库(例如 MySQL)来保存。而 Redis 的键值数据模型,正好可以满足这里的数据存取需求。Redis 基于自身数据结构以及扩展模块,提供了两种解决方案。
还有比如,手机亮屏时间,CPU温度监控上报等可以用
时间序列数据的特点
在实际应用中,时间序列数据通常是持续高并发写入的,例如,需要连续记录数万个设备的实时状态值。同时,时间序列数据的写入主要就是插入新数据,而不是更新一个已存在的数据,也就是说,一个时间序列数据被记录后通常就不会变了,因为它就代表了一个设备在某个时刻的状态值(例如,一个设备在某个时刻的温度测量值,一旦记录下来,这个值本身就不会再变了)。
所以,这种数据的写入特点很简单,就是插入数据快,这就要求我们选择的数据类型,在进行数据插入时,复杂度要低,尽量不要阻塞。看到这儿,你可能第一时间会想到用 Redis 的 String、Hash 类型来保存,因为它们的插入复杂度都是 O(1),是个不错的选择。但是,String 类型在记录小数据时(例如刚才例子中的设备温度值),元数据的内存开销比较大,不太适合保存大量数据。
那我们再看看,时间序列数据的读操作有什么特点。我们在查询时间序列数据时,既有对单条记录的查询(例如查询某个设备在某一个时刻的运行状态信息,对应的就是这个设备的一条记录),也有对某个时间范围内数据的查询(例如每天早上 8 点到 10 点的所有设备的状态信息)。除此之外,还有一些更复杂的查询,比如对某个时间范围内的数据做聚合计算。
这里的聚合计算,就是对符合查询条件的所有数据做计算,包括计算均值、最大 / 最小值、求和等。例如,我们要计算某个时间段内的设备压力的最大值,来判断是否有故障发生。
那用一个词概括时间序列数据的“读”,就是查询模式多。
弄清楚了时间序列数据的读写特点,接下来我们就看看如何在 Redis 中保存这些数据。我们来分析下:针对时间序列数据的“写要快”,Redis 的高性能写特性直接就可以满足了;而针对“查询模式多”,也就是要支持单点查询、范围查询和聚合计算,Redis 提供了保存时间序列数据的两种方案,分别可以基于 Hash 和 Sorted Set 实现,以及基于 RedisTimeSeries 模块实现。
基于 Hash 和 Sorted Set 保存时间序列数据
Hash 和 Sorted Set 组合的方式有一个明显的好处:它们是 Redis 内在的数据类型,代码成熟和性能稳定。所以,基于这两个数据类型保存时间序列数据,系统稳定性是可以预期的。
问题1 那么,为什么保存时间序列数据,要同时使用这两种类型?
这是我们要回答的第一个问题。关于 Hash 类型,我们都知道,它有一个特点是,可以实现对单键的快速查询。这就满足了时间序列数据的单键查询需求。我们可以把时间戳作为 Hash 集合的 key,把记录的设备状态值作为 Hash 集合的 value。可以看下用 Hash 集合记录设备的温度值的示意图: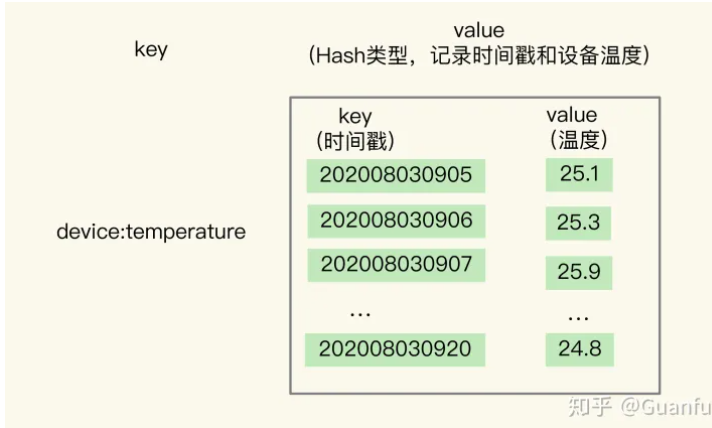
当我们想要查询某个时间点或者是多个时间点上的温度数据时,直接使用 HGET 命令或者 HMGET 命令,就可以分别获得 Hash 集合中的一个 key 和多个 key 的 value 值了。
举个例子。我们用 HGET 命令查询 202008030905 这个时刻的温度值,使用 HMGET 查询 202008030905、202008030907、202008030908 这三个时刻的温度值,如下所示:
HGET device:temperature 202008030905
"25.1"
HMGET device:temperature 202008030905 202008030907 202008030908
1) "25.1"
2) "25.9"
3) "24.9"
你看,用 Hash 类型来实现单键的查询很简单。但是,Hash 类型有个短板:它并不支持对数据进行范围查询。
虽然时间序列数据是按时间递增顺序插入 Hash 集合中的,但 Hash 类型的底层结构是哈希表,并没有对数据进行有序索引。所以,如果要对 Hash 类型进行范围查询的话,就需要扫描 Hash 集合中的所有数据,再把这些数据取回到客户端进行排序,然后,才能在客户端得到所查询范围内的数据。显然,查询效率很低。
为了能同时支持按时间戳范围的查询,可以用 Sorted Set 来保存时间序列数据,因为它能够根据元素的权重分数来排序。我们可以把时间戳作为 Sorted Set 集合的元素分数,把时间点上记录的数据作为元素本身。
我还是以保存设备温度的时间序列数据为例,进行解释。下图显示了用 Sorted Set 集合保存的结果。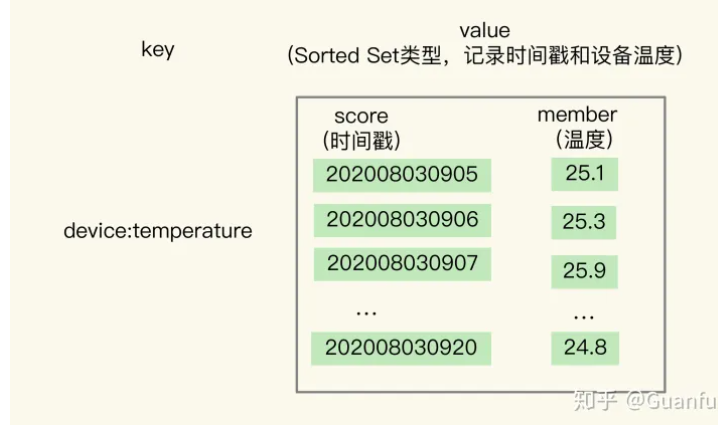
使用 Sorted Set 保存数据后,我们就可以使用 ZRANGEBYSCORE 命令,按照输入的最大时间戳和最小时间戳来查询这个时间范围内的温度值了。如下所示,我们来查询一下在 2020 年 8 月 3 日 9 点 7 分到 9 点 10 分间的所有温度值:
ZRANGEBYSCORE device:temperature 202008030907 202008030910
1) "25.9"
2) "24.9"
3) "25.3"
4) "25.2"
现在我们知道了,同时使用 Hash 和 Sorted Set,可以满足单个时间点和一个时间范围内的数据查询需求了.
但是我们又会面临一个新的问题,也就是我们要解答的第二个问题:
问题2 如何保证写入 Hash 和 Sorted Set 是一个原子性的操作呢?
所谓“原子性的操作”,就是指我们执行多个写命令操作时(例如用 HSET 命令和 ZADD 命令分别把数据写入 Hash 和 Sorted Set),这些命令操作要么全部完成,要么都不完成。
只有保证了写操作的原子性,才能保证同一个时间序列数据,在 Hash 和 Sorted Set 中,要么都保存了,要么都没保存。否则,就可能出现 Hash 集合中有时间序列数据,而 Sorted Set 中没有,那么,在进行范围查询时,就没有办法满足查询需求了。
那 Redis 是怎么保证原子性操作的呢?这里就涉及到了 Redis 用来实现简单的事务的 MULTI 和 EXEC 命令。当多个命令及其参数本身无误时,MULTI 和 EXEC 命令可以保证执行这些命令时的原子性。关于 Redis 的事务支持和原子性保证的异常情况,我们只要了解一下 MULTI 和 EXEC 这两个命令的使用方法就行了。
MULTI 命令:表示一系列原子性操作的开始。收到这个命令后,Redis 就知道,接下来再收到的命令需要放到一个内部队列中,后续一起执行,保证原子性。
EXEC 命令:表示一系列原子性操作的结束。一旦 Redis 收到了这个命令,就表示所有要保证原子性的命令操作都已经发送完成了。
此时,Redis 开始执行刚才放到内部队列中的所有命令操作。你可以看下下面这张示意图,命令 1 到命令 N 是在 MULTI 命令后、EXEC 命令前发送的,它们会被一起执行,保证原子性。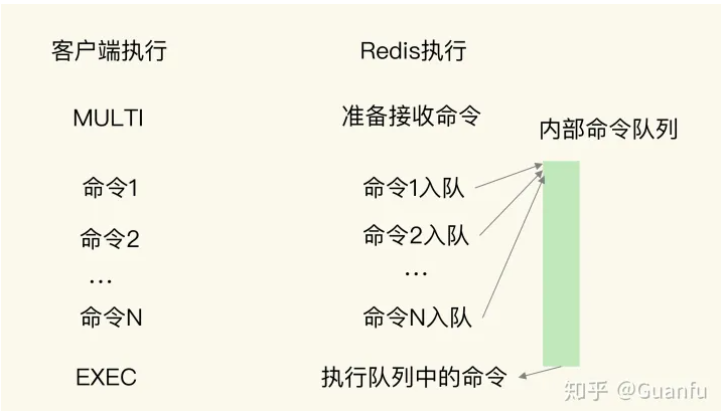
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> HSET device:temperature 202008030911 26.8
QUEUED
127.0.0.1:6379> ZADD device:temperature 202008030911 26.8
QUEUED
127.0.0.1:6379> EXEC
1) (integer) 1
2) (integer) 1
问题3 如何对时间序列数据进行聚合计算?
聚合计算一般被用来周期性地统计时间窗口内的数据汇总状态,在实时监控与预警等场景下会频繁执行。因为 Sorted Set 只支持范围查询,无法直接进行聚合计算,所以,我们只能先把时间范围内的数据取回到客户端,然后在客户端自行完成聚合计算。这个方法虽然能完成聚合计算,但是会带来一定的潜在风险,也就是大量数据在 Redis 实例和客户端间频繁传输,这会和其他操作命令竞争网络资源,导致其他操作变慢。
在这个物联网项目中,就需要每 3 分钟统计一下各个设备的温度状态,一旦设备温度超出了设定的阈值,就要进行报警。这是一个典型的聚合计算场景,我们可以来看看这个过程中的数据体量。假设我们需要每 3 分钟计算一次的所有设备各指标的最大值,每个设备每 15 秒记录一个指标值,1 分钟就会记录 4 个值,3 分钟就会有 12 个值。我们要统计的设备指标数量有 33 个,所以,单个设备每 3 分钟记录的指标数据有将近 400 个(33 * 12 = 396),而设备总数量有 1 万台,这样一来,每 3 分钟就有将近 400 万条(396 * 1 万 = 396 万)数据需要在客户端和 Redis 实例间进行传输。
为了避免客户端和 Redis 实例间频繁的大量数据传输,我们可以使用 RedisTimeSeries 来保存时间序列数据。
Stream解决方案
Redis Stream 是 Redis 5.0 版本新增加的数据结构,使用 Rax(Radix树的单独实现)实现,与 Sorted Sets 相比,Redis Streams 增强了插入和读取的性能。但 Stream 主要用于消息队列,仍然缺少了特定于时间序列的聚合工具。
缺点:
内置缺少聚合工具。
RedisTimeSeries解决方案
RedisTimeSeries 支持直接在 Redis 实例上进行聚合计算。还是以刚才每 3 分钟算一次最大值为例。在 Redis 实例上直接聚合计算,那么,对于单个设备的一个指标值来说,每 3 分钟记录的 12 条数据可以聚合计算成一个值,单个设备每 3 分钟也就只有 33 个聚合值需要传输,1 万台设备也只有 33 万条数,数据量大约是在客户端做聚合计算的十分之一,很显然,可以减少大量数据传输对 Redis 实例网络的性能影响。
所以,如果我们只需要进行单个时间点查询或是对某个时间范围查询的话,适合使用 Hash 和 Sorted Set 的组合,它们都是 Redis 的内在数据结构,性能好,稳定性高。但是,如果我们需要进行大量的聚合计算,同时网络带宽条件不是太好时,Hash 和 Sorted Set 的组合就不太适合了。此时,使用 RedisTimeSeries 就更加合适一些。
好了,接下来,我们就来具体学习下 RedisTimeSeries
介绍
RedisTimeSeries 是 Redis 的一个扩展模块。它专门面向时间序列数据提供了数据类型和访问接口,并且支持在 Redis 实例上直接对数据进行按时间范围的聚合计算。
使用
当用于时间序列数据存取时,RedisTimeSeries 的操作主要有 5 个:
-
用 TS.CREATE 命令创建时间序列数据集合;
-
用 TS.ADD 命令插入数据;
-
用 TS.GET 命令读取最新数据;
-
用 TS.MGET 命令按标签过滤查询数据集合;
-
用 TS.RANGE 支持聚合计算的范围查询。
下面,我来介绍一下如何使用这 5 个操作。
- 用 TS.CREATE 命令创建一个时间序列数据集合
在 TS.CREATE 命令中,我们需要设置时间序列数据集合的 key 和数据的过期时间(以毫秒为单位)。此外,我们还可以为数据集合设置标签,来表示数据集合的属性。例如,我们执行下面的命令,创建一个 key 为 device:temperature、数据有效期为 600s 的时间序列数据集合。也就是说,这个集合中的数据创建了 600s 后,就会被自动删除。最后,我们给这个集合设置了一个标签属性{device_id:1},表明这个数据集合中记录的是属于设备 ID 号为 1 的数据。
这个是整个key的删除 不是数据的删除
>TS.CREATE device:temperature RETENTION 600000 LABELS device_id 1
更复杂的示例
#创建标签属性sensor_id为2, area_id为32时间序列集合(注意这里的key名)
$ TS.CREATE temperature:2:32 RETENTION 600000 DUPLICATE_POLICYLAST LABELS sensor_id 2 area_id 32
- 用 TS.ADD 命令插入数据,用 TS.GET 命令读取最新数据
我们可以用 TS.ADD 命令往时间序列集合中插入数据,包括时间戳和具体的数值,并使用 TS.GET 命令读取数据集合中的最新一条数据。
例如,我们执行下列 TS.ADD 命令时,就往 device:temperature 集合中插入了一条数据,记录的是设备在 2020 年 8 月 3 日 9 时 5 分的设备温度;再执行 TS.GET 命令时,就会把刚刚插入的最新数据读取出来。
>TS.ADD device:temperature 1596416700 25.1
#也可以使用 * 代替上面指定的时间戳让Redis将自动生成时间戳。
1596416700
>TS.GET device:temperature
25.1
- 用 TS.MGET 命令按标签过滤查询数据集合
在保存多个设备的时间序列数据时,我们通常会把不同设备的数据保存到不同集合中。此时,我们就可以使用 TS.MGET 命令,按照标签查询部分集合中的最新数据。在使用 TS.CREATE 创建数据集合时,我们可以给集合设置标签属性。当我们进行查询时,就可以在查询条件中对集合标签属性进行匹配,最后的查询结果里只返回匹配上的集合中的最新数据。
举个例子。假设我们一共用 4 个集合为 4 个设备保存时间序列数据,设备的 ID 号是 1、2、3、4,我们在创建数据集合时,把 device_id 设置为每个集合的标签。此时,我们就可以使用下列 TS.MGET 命令,以及 FILTER 设置(这个配置项用来设置集合标签的过滤条件),查询 device_id 不等于 2 的所有其他设备的数据集合,并返回各自集合中的最新的一条数据。
TS.MGET FILTER device_id!=2
1) 1) "device:temperature:1"
2) (empty list or set)
3) 1) (integer) 1596417000
2) "25.3"
2) 1) "device:temperature:3"
2) (empty list or set)
3) 1) (integer) 1596417000
2) "29.5"
3) 1) "device:temperature:4"
2) (empty list or set)
3) 1) (integer) 1596417000
2) "30.1"
- 用 TS.RANGE 支持需要聚合计算的范围查询
最后,在对时间序列数据进行聚合计算时,我们可以使用 TS.RANGE 命令指定要查询的数据的时间范围,同时用 AGGREGATION 参数指定要执行的聚合计算类型。
RedisTimeSeries 支持的聚合计算类型很丰富,包括求均值(avg)、求最大 / 最小值(max/min),求和(sum)等。例如,在执行下列命令时,我们就可以按照每 180s 的时间窗口,对 2020 年 8 月 3 日 9 时 5 分和 2020 年 8 月 3 日 9 时 12 分这段时间内的数据进行均值计算了。
TS.RANGE device:temperature 1596416700 1596417120 AGGREGATION avg 180000
1) 1) (integer) 1596416700
2) "25.6"
2) 1) (integer) 1596416880
2) "25.8"
3) 1) (integer) 1596417060
2) "26.1"
Redis Cell限流
https://github.com/brandur/redis-cell
使用
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并提供了原子的限流指令。有了这个模块,限流问题就非常简单了。
该模块只有 1 条指令 cl.throttle,它的参数和返回值都略显复杂,接下来让我们来看看这个指令具体该如何使用
无需加入ppt
A Redis module that provides rate limiting in Redis as a single command. Implements the fairly sophisticated generic cell rate algorithm (GCRA) which provides a rolling time window and doesn’t depend on a background drip process.
但是官网的介绍又说是GCRA算法?
CL.THROTTLE user123 15 30 60 1
▲ ▲ ▲ ▲ ▲
| | | | └───── apply 1 token (default if omitted)
| | └──┴─────── 30 tokens / 60 seconds
| └───────────── 15 max_burst
└─────────────────── key "user123"
15:官方叫 max_burst,没理解什么意思,首次执行时令牌桶会默认填满
30:与下一个参数一起,表示在指定时间窗口内允许访问的次数
60:指定的时间窗口,单位:秒
2:表示本次要申请的令牌数,不写则默认为1
以上命令表示从一个初始值为15的令牌桶中取2个令牌,该令牌桶的速率限制为30次/60秒。
# 返回值说明
127.0.0.1:6379> CL.THROTTLE user123 15 30 60
1) (integer) 0
2) (integer) 16
3) (integer) 15
4) (integer) -1
5) (integer) 2
1:是否成功,0:成功, 1:拒绝
2:令牌桶的容量,大小为初始值+1
3:当前令牌桶中可用的令牌
4:若请求被拒绝,这个值表示多久后才令牌桶中会重新添加令牌,单位:秒,可以作为重试时间
5:表示多久后令牌桶中的令牌会存满
下面是漏桶算法的解释 虽然不是使用露桶实现的 也有参考意义
上面这个指令的意思是允许「用户回复行为」的频率为每 60s 最多 30 次 (漏水速率),漏斗的初始容量为 15,也就是说一开始可以连续回复
15 个帖子, 然后才开始受漏水速率的影响。 我们看到这个指令中漏水速率变成了 2 个参数, 替代了之前的单个浮点数。
用两个参数相除的结果来表达漏水速率相对单个浮点 数要更加直观一些。 在执行限流指令时,如果被拒绝了,就需要丢弃或重试。cl.throttle
指令考虑的 非常周到, 连重试时间都帮你算好了,直接取返回结果数组的第四个值进行 sleep 即可,
如果不想阻塞线程,也可以异步定时任务来重试
思考
因为业务的原因(周末请求比平时多),最近公司的服务一到周末就嗝屁,消防群里忙的不可开交,有几次跟redis有关系导致服务雪崩,后来架构那边出建议各个业务组减少对其他服务的依赖。
一方面其他服务都不可靠,一方面一些核心业务不能做降级,并且公司日益壮大,服务太多,出错排查的成本太大,基于这些原因,能在自己服务内解决的就不要依赖其他服务。
个人觉得,项目不大的,维护成本不高的话,可以采用直接使用redsi-cll ,否则可以考虑细粒度的控制到每个服务节点去限流,配合相应的负载均衡策略去实现。以上为个人理解,仅供参考。
另一篇的lua类似实现
1)方案1 - Lua脚本
思路
把限制逻辑封装到一个Lua脚本中,调用时只需传入:key、限制数量、过期时间,调用结果就会指明是否运行访问
local notexists = redis.call(\"set\", KEYS[1], 1, \"NX\", \"EX\", tonumber(ARGV[2]))
if (notexists) then
return 1
end
local current = tonumber(redis.call(\"get\", KEYS[1]))
if (current == nil) then
local result = redis.call(\"incr\", KEYS[1])
redis.call(\"expire\", KEYS[1], tonumber(ARGV[2]))
return result
end
if (current >= tonumber(ARGV[1])) then
error(\"too many requests\")
end
local result = redis.call(\"incr\", KEYS[1])
return result
(2)方案2 - 扩展模块
Redis4 中开放了模块系统,大家可以开发自己的模块插入到 redis 中,redis 官方已经推荐了一个访问限制模块 redis-cell,只需要一条命令就可以实现需求
示例
CL.THROTTLE user123 15 30 60
user123 是 key
15 是最大配额数量
30 是可以访问次数
60 是时间周期,单位秒
综合起来的意思是,user123 的最大资源配额是15,60秒内最多可以访问30次
返回结果:
- (integer) 0 # 0 允许; 1 拒绝
- (integer) 16 # 总配额
- (integer) 15 # 剩余配额
- (integer) -1 # 几秒后可以重试,-1 表示不限制,第一条为0时,此处为-1
- (integer) 2 # 几秒后恢复最大值
复制
每次执行这个命令时,剩余配额都会减1,当配额不足,或者访问次数超限时,都会被拒绝
项目地址
https://github.com/antirez/neural-redis
Redis s2geo
Geohash 和 Google S2
这两个算法主要是对二维数据转换成一维数据,然后可以建立索引。 所谓滴滴附近的人等等功能的实现原理就是这样的。
应用场景:可以和限流结合,对某个城市区域限流推送,优化控制
详细可看:
https://www.jianshu.com/p/7332dcb978b2
https://blog.csdn.net/weixin_47747094/article/details/125536246
redis 这个模块实现了s2的算法.
和redis原始geo的对比
- Geohash 有12级,从5000km 到7cm。中间每一级的变化比较大。有时候可能选择上一级会大很多,选择下一级又会小一些。这种情况选择多长的 Geohash 字符串就比较难选。选择不好,每次判断可能就还需要取出周围的8个格子再次进行判断。S2 有30级,从 0.7cm² 到 85,000,000km² 。中间每一级的变化都比较平缓,接近于4次方的曲线。所以选择精度不会出现 Geohash 选择困难的问题。
- Geohash 需要 12 bytes 存储。S2 的存储只需要一个 uint64 即可存下。
- S2 库里面不仅仅有地理编码,还有其他很多几何计算相关的库。地理编码只是其中的一小部分。本文没有介绍到的 S2 的实现还有很多很多,各种向量计算,面积计算,多边形覆盖,距离问题,球面球体上的问题,它都有实现。
Redis ML 推荐
(ppt 不需要)
https://blog.csdn.net/qq_33449307/article/details/119985038
布谷鸟过滤器 CuckooFilter
Bloom Filter 可能存在误报并且无法删除元素,因此近些年来有一些学者提出了Cuckoo hash(布谷鸟哈希算法)。Cuckoo hash算法的哈希函数是成对的(具体的实现可以根据需求设计),每一个元素都有两个哈希函数用来分别映射到两个位置,其中一个是记录的位置,另一个是备用位置,这个备用位置是处理碰撞时用的。
布谷鸟过滤器源于布谷鸟Hash算法,布谷鸟Hash表有两张,分别对应两个Hash函数,当有新的数据插入的时候,它会计算出这个数据在两张表中对应的两个位置,这个数据一定会被存在这两个位置之一(表1或表2)。一旦发现其中一张表的位置被占,就将该位置原来的数据踢出,被踢出的数据就去另一张表找对应的位置。通过不断的踢出数据,最终所有数据都找到了自己的归宿。但仍会有数据不断的踢出,最终形成循环,总有一个数据一直没办法找到落脚的位置,这代表布谷Hash表走到了极限,需要将Hash算法优化或Hash表扩容。
H1(key) = hash1(key)
H2(key) = H1(key) xor H1(key’s fingerprint)
H3(key) = key’s fingerprint = (key)
与Cuckoo hash算法不太相同的地方时,布谷鸟过滤器只存储元素的指纹信息(几个bit,类似于布隆过滤器),由于不是存储了数据的全部信息,会有误判的可能。由于布谷鸟过滤器在踢出数据时,需要再次计算原数据在另一种表的Hash值,因此作者设计Hash算法时将两个Hash函数变成了一个Hash函数,第一张表的备选位置是Hash(x),第二张表的备选位置是Hash(x)⊕hash(fingerprint(x)),即第一张表的位置与存储的指纹的Hash值做异或运算。这样可以快速计算出其元素在另一张表的位置。
布谷鸟过滤器在做防缓存击穿时具有很好的表现,与布隆过滤器不同的是,它可以删除元素而不是在误判率到达一定程度时扩建;同时对于很久之前插入的数据,进行删除可以提高缓存的性能;而布隆过滤器只能遍历一遍键,进行重建,开销巨大。
布谷鸟不会自己筑巢,下蛋后会将自己的蛋放入别的鸟类巢穴中,由其他鸟代为抚育,而幼鸟则会将其他未出生的鸟蛋推出鸟巢,自己独享食物。
布谷鸟哈希的原理就来源于上面的故事,他的核心在于哈希替换——布谷鸟哈希中每一个元素中有两个桶,分别使用了两种哈希函数存储两个下标,其中一个是主位置,另一个则是备用的位置。当主位置发生哈希冲突时,就会将元素存储到备用位置中,而如果备用位置也产生了冲突,就会将原有冲突的元素剔除,让其重复执行之前的流程,直到次数达到阈值时,才认为哈希表已满,进行 rehash
为了提高空间利用率,降低碰撞概率,布谷鸟过滤器在布谷鸟哈希上做了改进,将其从一维的结构变成了二维的结构(每个桶存储的元素从一个变为 n 个),且每个位置中只存储几个 bit 的指纹,而非完整的元素。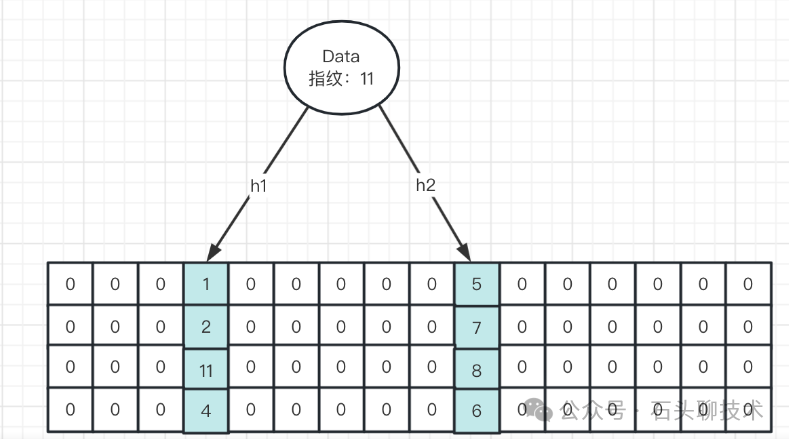

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)