python机器学习——boosting集成学习
boosting集成学习boosting :训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。对所有基模型预测的结果进行线性综合产生最终的预测结果。通俗来说,对于基模型1,我们使用训练集X0X_0X0,Y0Y_0Y0来训练,得到预测结果Y0^\hat{Y_0}Y0^,然后我们将Y0−Y0^Y_0-\hat{Y_0}Y0−Y0
boosting集成学习
boosting :训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。对所有基模型预测的结果进行线性综合产生最终的预测结果。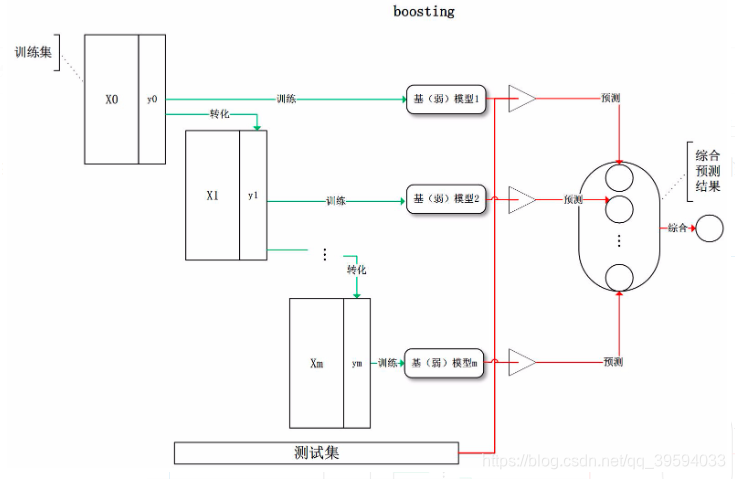
通俗来说,对于基模型1,我们使用训练集X0X_0X0,Y0Y_0Y0来训练,得到预测结果Y0^\hat{Y_0}Y0^,然后我们将Y0−Y0^Y_0-\hat{Y_0}Y0−Y0^得到残差Y1Y_1Y1,然后继续利用X1X_1X1(X1=X0X_1=X_0X1=X0)和Y1Y_1Y1训练基模型2,以此类推,最后在预测的时候只需要将所有基模型的预测结果相加就行了。这种训练框架的优点是每一个基模型都在修正前面模型的预测结果,这样训练误差就会比之前的模型进一步下降,一般认为boosting方法用于降低偏差(模型预测值与真实值的差距)。比较有代表性的算法就是adaboost。
参考文献
[1]周志华. 机器学习[M]. 清华大学出版社, 北京, 2016.

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)