MLFlow︱机器学习工作流框架:MLFlow docker 实践(二)
文章目录1 mlflow Dockerfile2 训练模型3 对比模型4 打包模型5 模型部署6 模型inference调用mlflow的安装与使用,可以直接:pip install mlflow1 mlflow Dockerfile本来按照这个MLFlow教程(MLflow系列1:MLflow入门教程(Python)),找台机器跑起来没啥问题;不过,看到项目的github有Dockerfile那
mlflow的安装与使用,可以直接:
pip install mlflow
1 mlflow Dockerfile
本来按照这个MLFlow教程(MLflow系列1:MLflow入门教程(Python)),找台机器跑起来没啥问题;
不过,看到项目的github有Dockerfile那必须上啊!
然后就被各类报错虐了一下午。。
首先,来看一下全环境的官方mlflow/Dockerfile:
FROM continuumio/miniconda
WORKDIR /app
ADD . /app
RUN pip install -r dev-requirements.txt && \
pip install -r test-requirements.txt && \
pip install -e . && \
apt-get update && apt-get install -y gnupg && \
apt-get install -y openjdk-8-jre-headless && \
curl -sL https://deb.nodesource.com/setup_10.x | bash - && \
apt-get update && apt-get install -y nodejs && \
cd mlflow/server/js && \
npm install && \
npm run build
初始化是continuumio/miniconda,后续还是改成了continuumio/anaconda3,在安装两个requirements.txt会遇到各种time-out报错,没后续尝试。
然后,转而去看代码里面另外一份 : mlflow/examples/docker/Dockerfile
FROM continuumio/miniconda:4.5.4
RUN pip install mlflow==0.8.1 \
&& pip install azure-storage==0.36.0 \
&& pip install numpy==1.14.3 \
&& pip install pandas==0.22.0 \
&& pip install scikit-learn==0.19.1 \
&& pip install cloudpickle
又是各种报错,索性,笔者心一横,就直接简单版本开局:
FROM continuumio/anaconda3
RUN pip install --pre mlflow -i https://pypi.tuna.tsinghua.edu.cn/simple
docker build -t <名称>:<编号> -f <名称> .
一般为:
docker build -t mlflow-docker-example:v1 -f Dockerfile .
除此之外,还有是有几个开源了蛮好的docker:
- Ycallaer/mlflowdocker,
Docker container for mlflow 0.8 framework with azure backend.
2 训练模型
以这个案例为实验:mlflow/examples/sklearn_elasticnet_wine/
我们使用下边的train.py代码进行训练;
python train.py 0.5 0.5
通过MLflow tracking APIs来记录每次训练的信息,比如模型超参数和模型的评价指标。这个例子还将模型进行了序列化以便后续部署。
每次运行完训练脚本,MLflow都会将信息保存在目录mlruns中。
3 对比模型
mlflow ui [OPTIONS]
在mlruns目录的上级目录中运行下边的命令:mlflow ui
但是由于是docker 之中,就需要考虑mlflow的IP + 端口的用法了,需要使用:
mlflow ui -p 5000 -h 0.0.0.0
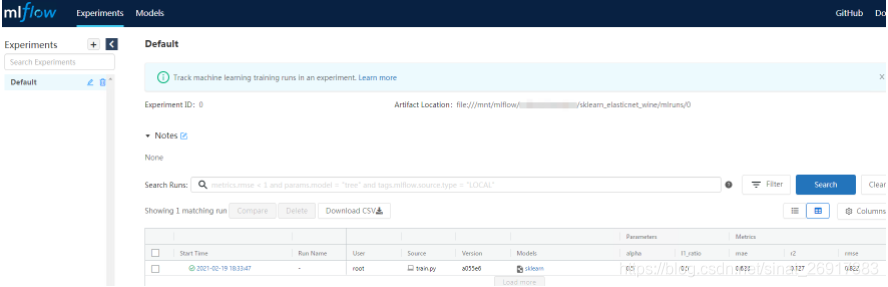
4 打包模型
打包模型,需要
- MLproject - 主配置文件
- conda.yaml - 辅配置文件,可以不要
- mlruns
MLproject
conda_env,代表部署环境
main代表一些参数点,和训练执行文件
这个文件,可以较快的设定训练参数
# sklearn_elasticnet_wine/MLproject
name: tutorial
conda_env: conda.yaml
entry_points:
main:
parameters:
alpha: float
l1_ratio: {type: float, default: 0.1}
command: "python train.py {alpha} {l1_ratio}"
conda.yaml
系统环境所需的一些依赖,以及对应的版本。
# sklearn_elasticnet_wine/conda.yaml
name: tutorial
channels:
- defaults
dependencies:
- numpy=1.14.3
- pandas=0.22.0
- scikit-learn=0.19.1
- pip:
- mlflow
通过执行mlflow run examples/sklearn_elasticnet_wine -P alpha=0.42可以运行这个项目,
MLflow会根据conda.yaml的配置在指定的conda环境中训练模型。
(PS,执行这个命名,需cd 在 MLproject的文件之中 )
当然,这里conda.yaml有个问题就是如果不指定channels会新建一个环境,新建的环境有可能啥依赖也没有,会报错:

譬如:
>>> mlflow.run(project_uri, parameters=params)2021/02/19 18:38:27 INFO mlflow.projects.utils: === Created directory /tmp/tmp67_irfg1 for downloading remote URIs passed to arguments of type 'path' ===
2021/02/19 18:38:27 INFO mlflow.projects.backend.local: === Running command 'source /opt/conda/bin/../etc/profile.d/conda.sh && conda activate mlflow-da39a3ee5e6b4b0d3255bfef95601890afd80709 1>&2 && python train.py 0.5 0.01' in run with ID 'fc28f62058144c778a8ca2ae49d0c7ab' ===
Traceback (most recent call last):
File "/mnt/mlflow/mlflow/examples/sklearn_elasticnet_wine/train.py", line 9, in <module>
import pandas as pd
ModuleNotFoundError: No module named 'pandas'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/conda/lib/python3.8/site-packages/mlflow/projects/__init__.py", line 310, in run
_wait_for(submitted_run_obj)
File "/opt/conda/lib/python3.8/site-packages/mlflow/projects/__init__.py", line 327, in _wait_for
raise ExecutionException("Run (ID '%s') failed" % run_id)
mlflow.exceptions.ExecutionException: Run (ID 'fc28f62058144c778a8ca2ae49d0c7ab') failed
一种方式就是conda activate mlflow-xxxxxx,然后把该安装的都安装了
5 模型部署
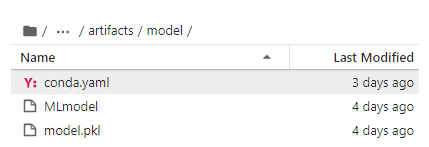
训练完之后,就会出现在mlruns文件夹之中:
/Users/mlflow/mlflow-prototype/mlruns/0/7c1a0d5c42844dcdb8f5191146925174/artifacts/model
其中,
- MLmodel元数据文件是告诉MLflow如何加载模型。
- model.pkl文件是训练好的序列化的线性回归模型。
那么模型部署和tensorflow-server蛮相似,
需要替换成你自己的目录
mlflow models serve -m /Users/mlflow/mlflow-prototype/mlruns/0/7c1a0d5c42844dcdb8f5191146925174/artifacts/model -p 1234 -h 0.0.0.0
这里 docker之中,-p 和 -h的端口和IP的设置还是需要的,默认为1234
6 模型inference调用
模型部署完之后,调用方式:
curl调用:
curl -X POST -H "Content-Type:application/json; format=pandas-split" \
--data '{"columns":["alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free sulfur dioxide", "pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"],"data":[[12.8, 0.029, 0.48, 0.98, 6.2, 29, 3.33, 1.2, 0.39, 75, 0.66]]}' \
http://10.0.0.0:5000/invocations
python调用:
import pandas as pd
from requests import post
api_url = "http://10.0.0.0:5000/invocations"
data = '{"columns":["alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free sulfur dioxide", "pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"],"data":[[12.8, 0.029, 0.48, 0.98, 6.2, 29, 3.33, 1.2, 0.39, 75, 0.66]]}'
headers = {'Content-Type': 'application/json; format=pandas-split'}
r = post(api_url, data, headers=headers)
r.encoding = 'utf-8'
r.json()
模型返回的样例:
[6.379428821398614]

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)