论文笔记(一)一种基于GPU的高效并行安全机器学习框架An Efficient Parallel Secure Machine Learning Framework on GPUs
IEEE Trans. Parallel Distributed Syst.上GPU加速的安全机器学习文献学习
@article{DBLP:journals/tpds/ZhangCZZZD21,
author = {Feng Zhang and
Zheng Chen and
Chenyang Zhang and
Amelie Chi Zhou and
Jidong Zhai and
Xiaoyong Du},
title = {An Efficient Parallel Secure Machine Learning Framework on GPUs},
journal = {{IEEE} Trans. Parallel Distributed Syst.},
volume = {32},
number = {9},
pages = {2262--2276},
year = {2021},
url = {An Efficient Parallel Secure Machine Learning Framework on GPUs | IEEE Journals & Magazine | IEEE Xplore},
doi = {10.1109/TPDS.2021.3059108},
timestamp = {Thu, 14 Oct 2021 09:20:51 +0200},
biburl = {https://dblp.org/rec/journals/tpds/ZhangCZZZD21.bib},
bibsource = {dblp computer science bibliography, dblp: computer science bibliography}
}
I、论文梗概
背景:隐私保护重要性--MPC用于很多应用中,尤其在机器学习中,MPC有特殊的优势(相对DP)
we find that the low performance problem exists even with two-party computation, which is mainly due to the following reasons.
SecureML [10], proposed by Mohassel and others, is the state-of-the-art machine learning framework based on two-party computation.
GPUs have been widely used as a powerful accelerator to machine learning algorithms [15], [16]. However, none of existing studies has focused on the acceleration of secure machine learning algorithms using GPUs.
针对的问题:性能
Previous work on secure machine learning mostly focused on novel protocols or improving accuracy, while the performance metric has been ignored.
本文的解决策略:提出基于GPU的框架 GPU-based framework ParSecureML
遇到的挑战:
- complex computation patterns, 复杂计算模式
- frequent intra-node data transmission between CPU and GPU, 节点内CPU和GPU间数据传输
- complicated inter-node data dependence 复杂的节点间数据依赖
提出的结构思路:
- profiling-guided adaptive GPU utilization,
- fine-grained double pipeline for intra-node CPU-GPU cooperation,
- compressed transmission for inter-node communication,
- integrate architecture specifific optimizations, such as Tensor Cores, into ParSecureML
成果:
- the first GPU-based secure machine learning framework.
- Compared to the state-of-the-art framework, ParSecureML achieves an average of 33.8X speedup.
- ParSecureML can also be applied to inferences, which achieves 31.7X speedup on average.
ParSecureML 创新点
针对三大挑战: Building a GPU-based secure machine learning framework requires handling three challenges.
- the complex triplet multiplication based computation patterns
- how to handle the PCIe transmission overhead caused by frequent intra-node data transmission between CPU and GPU.
- the complicated inter-node data dependence
三项新技术
- a profiling guided adaptive GPU engine分析过程找到计算最密集的部分
- a double pipeline design, which can overlap not only the GPU computation and PCIe data transmission, but also potential steps among different NN layers
- a novel compression-based transmission method
对CPU和GPU进行了深度优化:
- 对随机数设计了线程安全的随机生成设计(a thread-safe random number generation design);
- 计算密集复杂部分置于GPU(使用cache优化来并行这些操作)
- 引入架构的特殊优化,将TensorCores 加入GPUs
对比ML算法(6种):
convolutional neural network (CNN) [19], multilayer perceptron (MLP) [20], linear regression [21], logistic regression [22], recurrent neural network (RNN) [23], and Support Vector Machine (SVM) [24],
5个数据集:
MNIST [25], VGGFace2 [26], NIST [27], CIFAR-10 [28], and a synthetic dataset.
II、ParSecureML协议
- Overview:
三个组件:
1)profiling-guided adaptive GPU utilization针对挑战一
- Double pipeline execution for overlapping intra-node data transmission and computation (compute1和communicate作为CPU执行的reconstruct phase,compute2作为GPU部分,形成一条pipeline;另外ML中单层中多个步骤,在这条pipeline中层间操作可以重叠)
- Compressed transmission for inter-node communication 针对挑战三
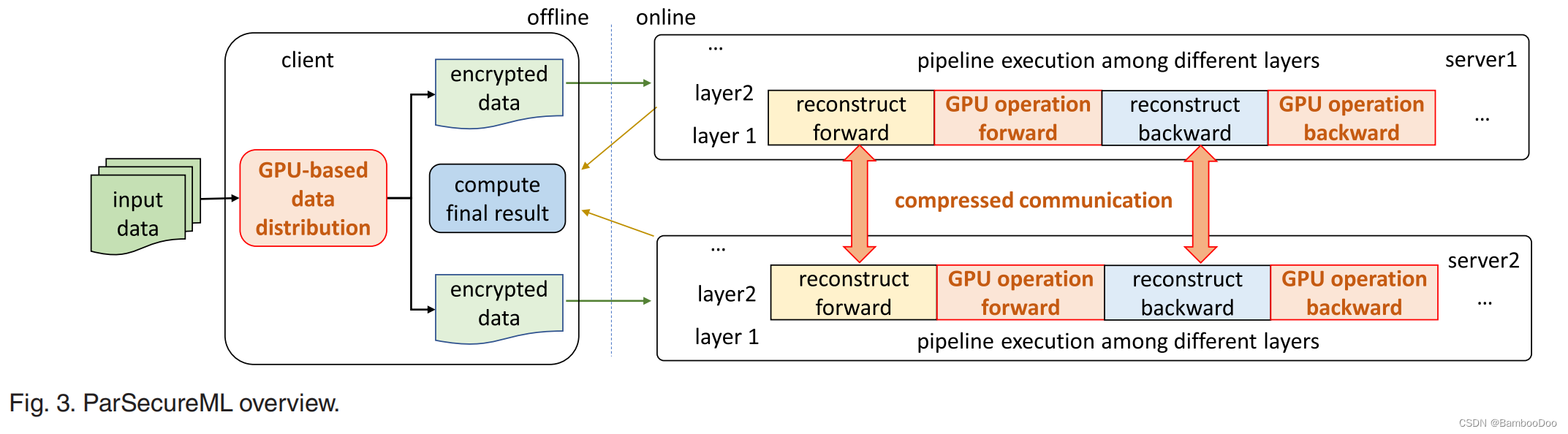
多技术集成的困难:GPU任务需要与pipeline执行和压缩传输合作;
双pipeline设计更复杂(CPU-GPU传输、计算、压缩传输)
压缩传输的数据能在GPU中存储
workflow:ML tasks各层中有forward propagation and backward propagation,both with reconstruct and GPU operation phases
- profiling-guided adaptive GPU utilization
- offline:三元组中矩阵乘法可GPU加速
- online:
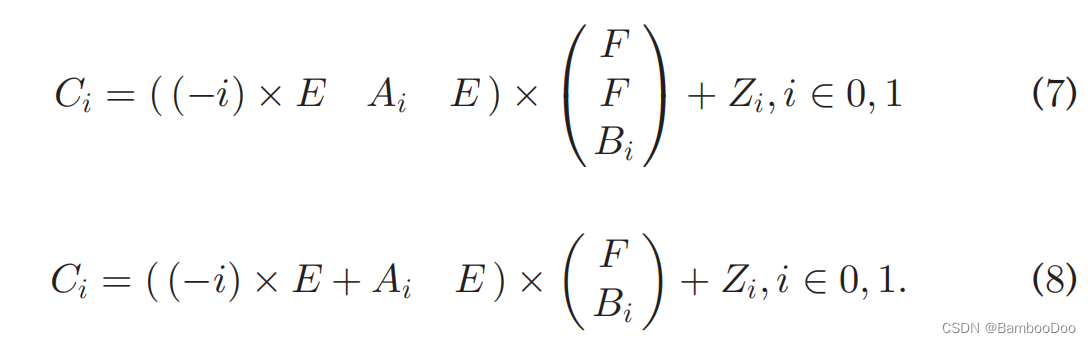
- Activation function design:
Equation (9) to simulate the original nonlinear functions in GPUs
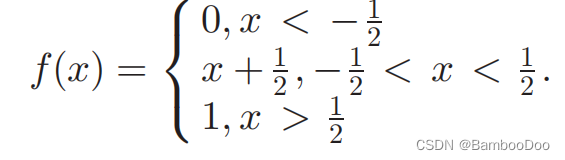
- Double pipeline execution for overlapping intra-node data transmission and computation
思路:
每层 forward:数据处理 backward:参数更新;每层都需要数据传输
————————需要fine-grained pipeline设计,不使用coarse-grained pipeline[43]\[44]
许多步骤贯穿多层
————————需要a second pipeline来overlap the possible steps in different layers
Pipeline Design:
- First Pipeline: overlap GPU computation and PCIe data transmission in equation (8)
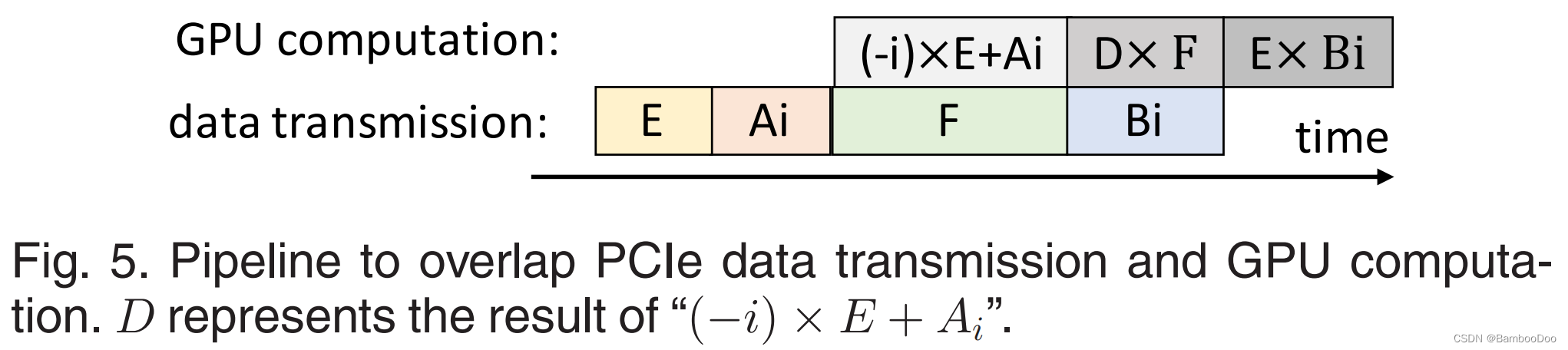
- Second Pipeline:
各层Forward and backward都需要reconstruct步骤和GPU操作,
后续层处理基于当前层的forward propagation,因此前后层forward 中reconstruct无法重叠。而backward中reconstruct不需要等待下一层,可与下一层propagation重叠——————可以节省一个reconstruct时间
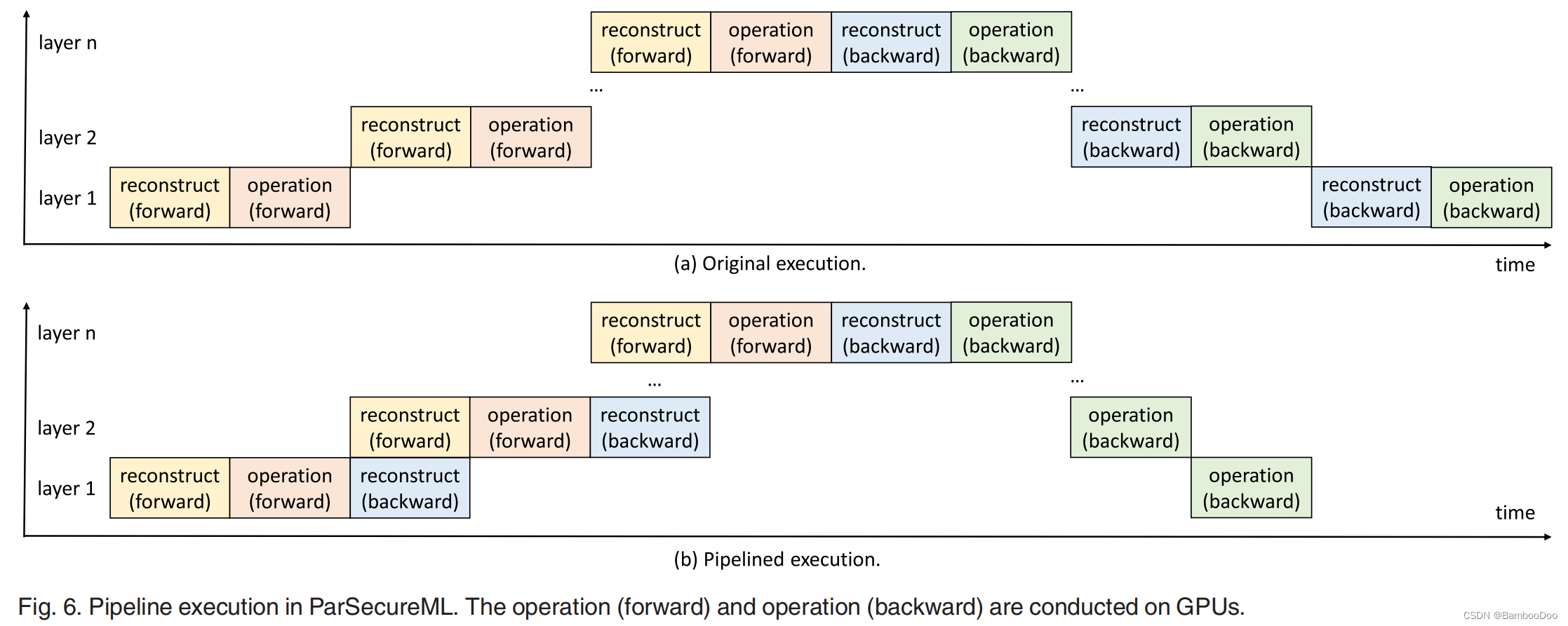
- Compressed Transmission for Inter-Node Communication
分析:迭代后的矩阵通常为稀疏矩阵。激活函数后会有多个零;当层数上涨,初始几层损失函数的梯度很小。
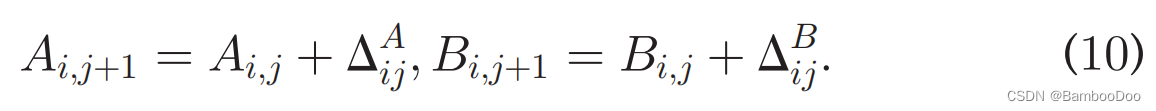
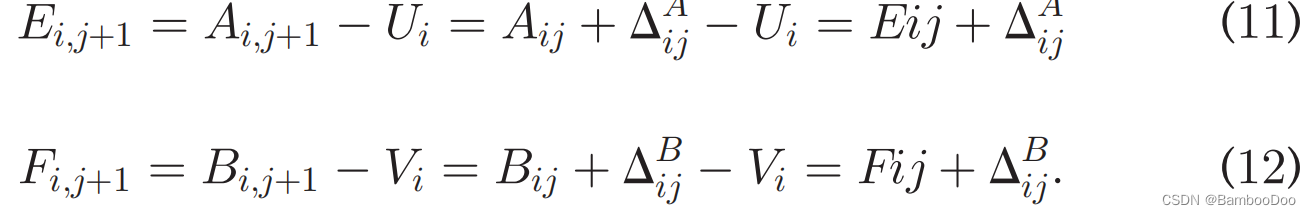

- 优化
1)CPU 加速
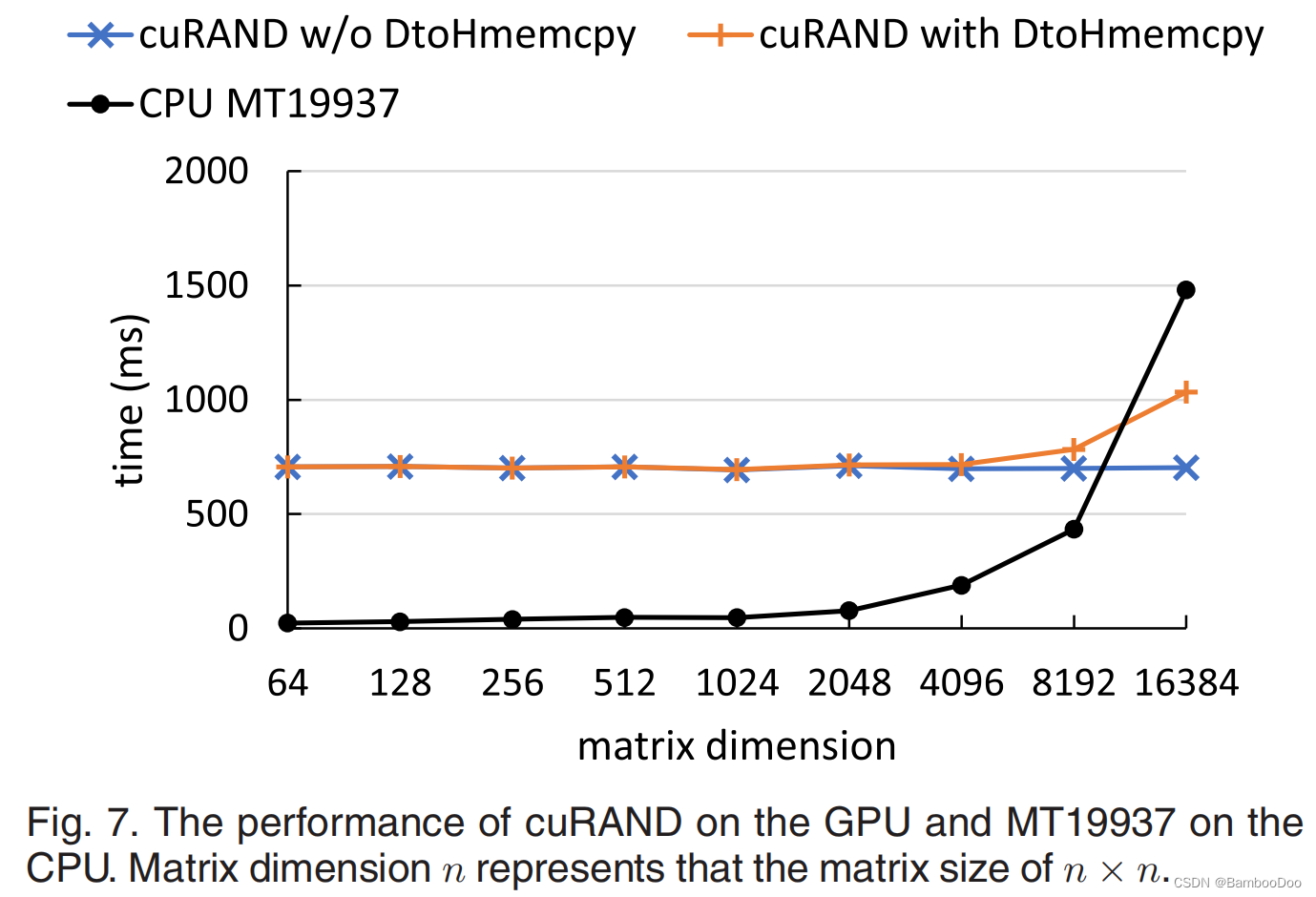
- 随机数产生的加速:使用 a thread-safe random number generator, Mersenne Twister 19937 generator (MT19937) [48], from C++ 11 random library(1.06 X rand()运行时间)另种可能的提高方式:cuRAND on GPUs,不过只在大矩阵下有好的加速效果
- 矩阵加减法优化 (5)(6)中加减法多,可以通过multi-threaded for-loop in parallel
2) GPU加速
- nvprof分析GPU运行,发现有三部分:host-to-device内存复制,通用矩阵乘法操作(针对),device-to-device内存复制
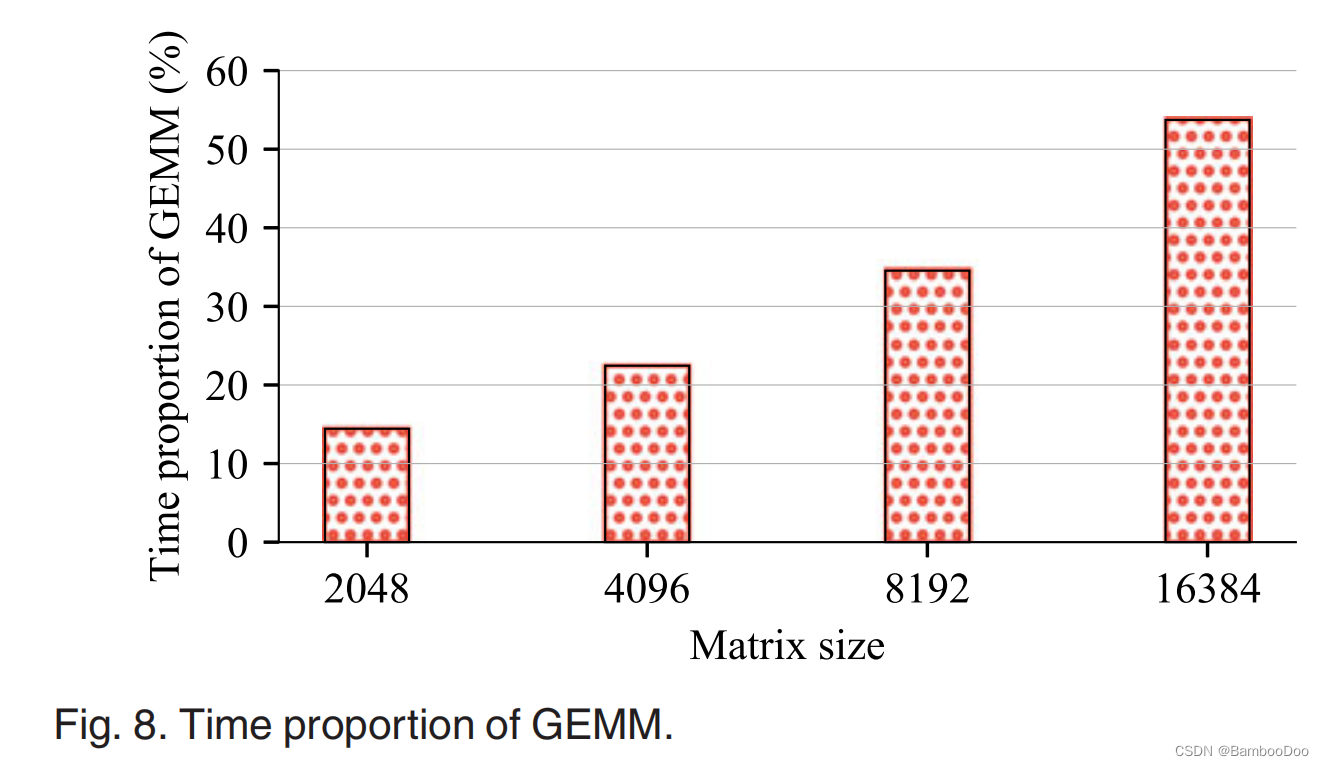
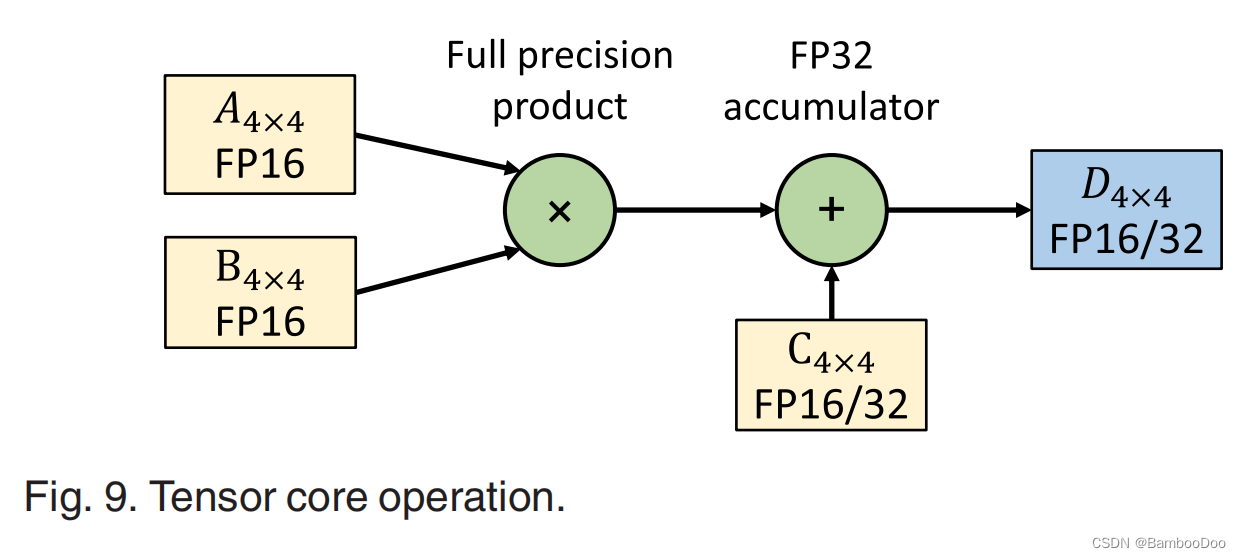
- Tensor Core Utilization.
Popular GPU machine learning frameworks, including TensorFlow [35], PyTorch [36], MXNet [51], and Caffe2 [52], all utilize Tensor Cores.

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)