python打卡 DAY 10 机器学习建模与评估
·
目录
知识点:
1. 数据集的划分
2. 机器学习模型建模的三行代码
3. 机器学习模型分类问题的评估
1 数据划分
import pandas as pd
data = pd.read_csv(r'heart.csv')
# 划分训练集和测试机
from sklearn.model_selection import train_test_split
X = data.drop(['sex'], axis=1) # 特征,axis=1表示按列删除
y = data['sex'] # 标签
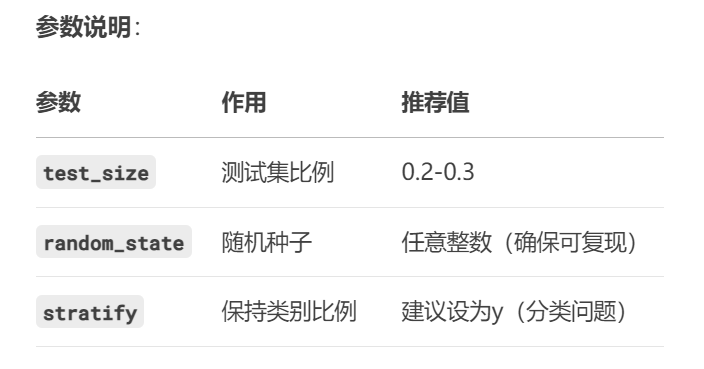
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 划分数据集,20%作为测试集,随机种子为42
# 训练集和测试集的形状
print(f"训练集形状: {X_train.shape}, 测试集形状: {X_test.shape}") # 打印训练集和测试集的形状
笔记:
1 数据集划分是机器学习中的重要步骤,通常将大部分数据用于训练模型,小部分数据用于评估模型性能。
2 test_size=0.2 表示测试集占20%,可以根据需要调整比例。
3 random_state=42 确保每次运行代码时划分结果一致,便于调试和复现。
2.模型训练与评估
步骤1:导入必要的库
from sklearn.svm import SVC #支持向量机分类器
from sklearn.neighbors import KNeighborsClassifier #K近邻分类器
from sklearn.linear_model import LogisticRegression #逻辑回归分类器
import xgboost as xgb #XGBoost分类器
import lightgbm as lgb #LightGBM分类器
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from catboost import CatBoostClassifier #CatBoost分类器
from sklearn.tree import DecisionTreeClassifier #决策树分类器
from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯分类器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息步骤2: 不同类型分类器训练与评估
2.1 SVM输入:
# SVM
svm_model = SVC(random_state=42)
svm_model.fit(X_train, y_train)
svm_pred = svm_model.predict(X_test)
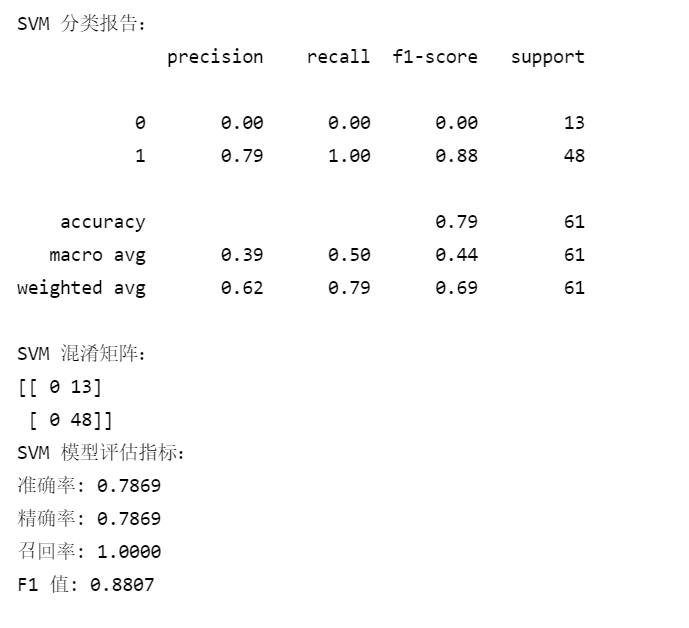
print("\nSVM 分类报告:")
print(classification_report(y_test, svm_pred)) # 打印分类报告
print("SVM 混淆矩阵:")
print(confusion_matrix(y_test, svm_pred)) # 打印混淆矩阵
# 计算 SVM 评估指标,这些指标默认计算正类的性能
svm_accuracy = accuracy_score(y_test, svm_pred)
svm_precision = precision_score(y_test, svm_pred)
svm_recall = recall_score(y_test, svm_pred)
svm_f1 = f1_score(y_test, svm_pred)
print("SVM 模型评估指标:")
print(f"准确率: {svm_accuracy:.4f}")
print(f"精确率: {svm_precision:.4f}")
print(f"召回率: {svm_recall:.4f}")
print(f"F1 值: {svm_f1:.4f}")输出:
2.2 KNN输入:
# KNN
knn_model = KNeighborsClassifier()
knn_model.fit(X_train, y_train)
knn_pred = knn_model.predict(X_test)
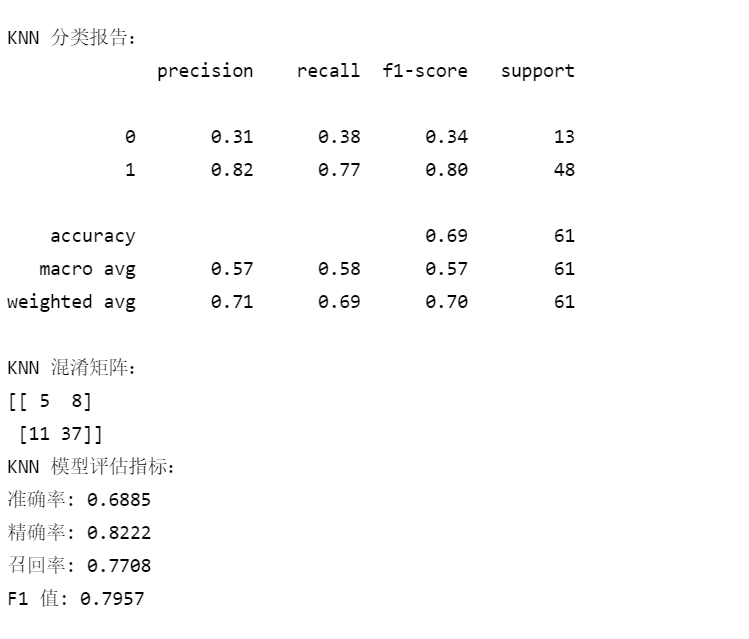
print("\nKNN 分类报告:")
print(classification_report(y_test, knn_pred))
print("KNN 混淆矩阵:")
print(confusion_matrix(y_test, knn_pred))
knn_accuracy = accuracy_score(y_test, knn_pred)
knn_precision = precision_score(y_test, knn_pred)
knn_recall = recall_score(y_test, knn_pred)
knn_f1 = f1_score(y_test, knn_pred)
print("KNN 模型评估指标:")
print(f"准确率: {knn_accuracy:.4f}")
print(f"精确率: {knn_precision:.4f}")
print(f"召回率: {knn_recall:.4f}")
print(f"F1 值: {knn_f1:.4f}")输出:
2.3 逻辑回归输入:
# 逻辑回归
logreg_model = LogisticRegression(random_state=42)
logreg_model.fit(X_train, y_train)
logreg_pred = logreg_model.predict(X_test)
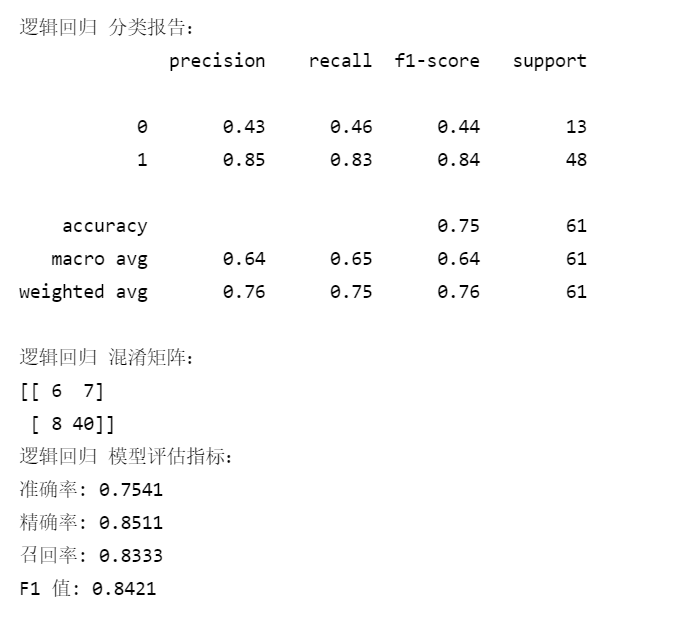
print("\n逻辑回归 分类报告:")
print(classification_report(y_test, logreg_pred))
print("逻辑回归 混淆矩阵:")
print(confusion_matrix(y_test, logreg_pred))
logreg_accuracy = accuracy_score(y_test, logreg_pred)
logreg_precision = precision_score(y_test, logreg_pred)
logreg_recall = recall_score(y_test, logreg_pred)
logreg_f1 = f1_score(y_test, logreg_pred)
print("逻辑回归 模型评估指标:")
print(f"准确率: {logreg_accuracy:.4f}")
print(f"精确率: {logreg_precision:.4f}")
print(f"召回率: {logreg_recall:.4f}")
print(f"F1 值: {logreg_f1:.4f}")输出:
2.4 朴素贝叶斯输入:
# 朴素贝叶斯
nb_model = GaussianNB()
nb_model.fit(X_train, y_train)
nb_pred = nb_model.predict(X_test)
print("\n朴素贝叶斯 分类报告:")
print(classification_report(y_test, nb_pred))
print("朴素贝叶斯 混淆矩阵:")
print(confusion_matrix(y_test, nb_pred))
nb_accuracy = accuracy_score(y_test, nb_pred)
nb_precision = precision_score(y_test, nb_pred)
nb_recall = recall_score(y_test, nb_pred)
nb_f1 = f1_score(y_test, nb_pred)
print("朴素贝叶斯 模型评估指标:")
print(f"准确率: {nb_accuracy:.4f}")
print(f"精确率: {nb_precision:.4f}")
print(f"召回率: {nb_recall:.4f}")
print(f"F1 值: {nb_f1:.4f}")输出:

2.5 决策树输入:
# 决策树
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)
print("\n决策树 分类报告:")
print(classification_report(y_test, dt_pred))
print("决策树 混淆矩阵:")
print(confusion_matrix(y_test, dt_pred))
dt_accuracy = accuracy_score(y_test, dt_pred)
dt_precision = precision_score(y_test, dt_pred)
dt_recall = recall_score(y_test, dt_pred)
dt_f1 = f1_score(y_test, dt_pred)
print("决策树 模型评估指标:")
print(f"准确率: {dt_accuracy:.4f}")
print(f"精确率: {dt_precision:.4f}")
print(f"召回率: {dt_recall:.4f}")
print(f"F1 值: {dt_f1:.4f}")输出:
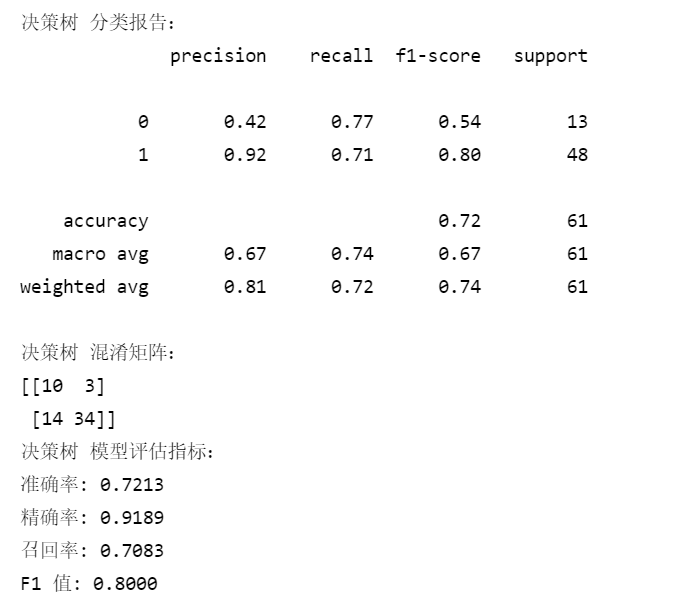
2.6 随机森林输入:
# 随机森林
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
print("\n随机森林 分类报告:")
print(classification_report(y_test, rf_pred))
print("随机森林 混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))
rf_accuracy = accuracy_score(y_test, rf_pred)
rf_precision = precision_score(y_test, rf_pred)
rf_recall = recall_score(y_test, rf_pred)
rf_f1 = f1_score(y_test, rf_pred)
print("随机森林 模型评估指标:")
print(f"准确率: {rf_accuracy:.4f}")
print(f"精确率: {rf_precision:.4f}")
print(f"召回率: {rf_recall:.4f}")
print(f"F1 值: {rf_f1:.4f}")输出:
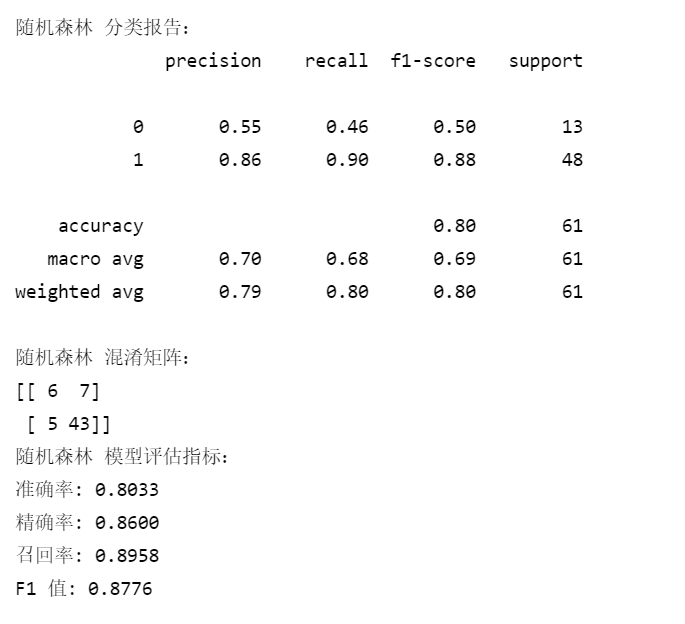
2.7 XGBoost输入:
# XGBoost
xgb_model = xgb.XGBClassifier(random_state=42)
xgb_model.fit(X_train, y_train)
xgb_pred = xgb_model.predict(X_test)
print("\nXGBoost 分类报告:")
print(classification_report(y_test, xgb_pred))
print("XGBoost 混淆矩阵:")
print(confusion_matrix(y_test, xgb_pred))
xgb_accuracy = accuracy_score(y_test, xgb_pred)
xgb_precision = precision_score(y_test, xgb_pred)
xgb_recall = recall_score(y_test, xgb_pred)
xgb_f1 = f1_score(y_test, xgb_pred)
print("XGBoost 模型评估指标:")
print(f"准确率: {xgb_accuracy:.4f}")
print(f"精确率: {xgb_precision:.4f}")
print(f"召回率: {xgb_recall:.4f}")
print(f"F1 值: {xgb_f1:.4f}")输出:

2.8 LightGBM输入:
# LightGBM
lgb_model = lgb.LGBMClassifier(random_state=42)
lgb_model.fit(X_train, y_train)
lgb_pred = lgb_model.predict(X_test)
print("\nLightGBM 分类报告:")
print(classification_report(y_test, lgb_pred))
print("LightGBM 混淆矩阵:")
print(confusion_matrix(y_test, lgb_pred))
lgb_accuracy = accuracy_score(y_test, lgb_pred)
lgb_precision = precision_score(y_test, lgb_pred)
lgb_recall = recall_score(y_test, lgb_pred)
lgb_f1 = f1_score(y_test, lgb_pred)
print("LightGBM 模型评估指标:")
print(f"准确率: {lgb_accuracy:.4f}")
print(f"精确率: {lgb_precision:.4f}")
print(f"召回率: {lgb_recall:.4f}")
print(f"F1 值: {lgb_f1:.4f}")输出:
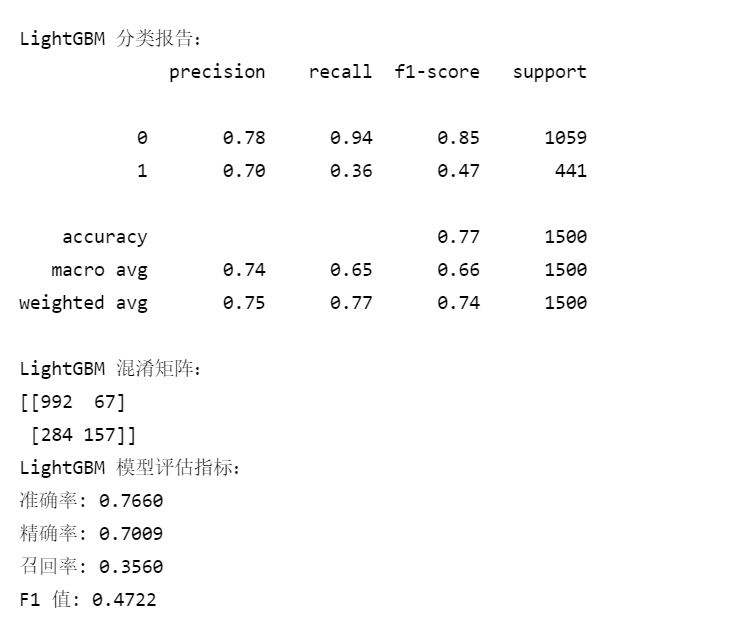
2.10 笔记:
2.10.1 三行经典代码
1. 模型实例化
2. 模型训练(代入训练集)
3. 模型预测 (代入测试集)
测试集的预测值和测试集的真实值进行对比,得到混淆矩阵接着基于混淆矩阵,计算准确率、召回率、F1值,这些都是固定阈值的评估指标
AUC是基于不同阈值得到不同的混淆矩阵,然后计算每个阈值对应FPR和TPR,讲这些点连成线,最后求曲线下的面积,得到AUC值
2.10.2 指标介绍
1 、classification_report 它会生成所有类别的指标
2 、准确率(Accuracy)是一个全局指标,衡量所有类别预测正确的比例 (TP + TN) / (TP + TN + FP + FN)。它不区分正负类,所以它只有一个值,不区分类别
3 、单独调用的 precision_score, recall_score, f1_score 在二分类中默认只计算正类(标签 1)的性能。由于模型从未成功预测出类别 1(TP=0),所以这些指标对类别 1 来说都是 0。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)