建筑兔零基础人工智能自学记录109|LangChain简单翻译应用-19
用LangChain和智谱AI开发一个简单的翻译API应用
·
LangChain中文网 - 跟着LangChain学AI开发
这次来看看LangChain,先找到了官网中英文文档。跟着pip配置了相关文件。
然后在智谱大模型智谱AI开放平台获取了免费的API
这里可以获取2种模型,一种是能思考的推理模型GLM-Z1-Flash,一种是完成文字接龙任务的语言模型GLM-4-Flash-250414(翻译、文档处理等)
 根据官方文档中构建一个简单的 LLM 应用,将代码让豆包改为智谱大模型能用的版本。并替换API
根据官方文档中构建一个简单的 LLM 应用,将代码让豆包改为智谱大模型能用的版本。并替换API

代码如下:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
import json
import requests
import re # 引入正则表达式用于结果清洗
# 替换为你的智谱API密钥
ZHIPUAI_API_KEY = "替换为你的智谱API密钥"
class TranslationRequest(BaseModel):
language: str = Field(..., description="目标语言(如:英语、日语、法语)")
text: str = Field(..., description="需要翻译的文本内容")
app = FastAPI(
title="GLM-4翻译API(纯结果版)",
version="1.0",
description="基于GLM-4-Flash-250414模型,仅返回纯翻译结果"
)
@app.post("/translate", response_description="仅包含纯翻译结果")
async def translate_text(request: TranslationRequest):
try:
# 1. 强化提示词(明确禁止任何额外内容)
prompt = f"""严格执行以下指令,不添加任何额外信息:
1. 将文本翻译成{request.language}
2. 只返回翻译后的文本,不包含:
- 解释、说明、分析
- 翻译过程、思考逻辑
- 任何标记(如引号、符号)
- 问候语或结束语
3. 文本:{request.text}"""
# 2. 模型请求参数(强化确定性)
api_url = "https://open.bigmodel.cn/api/paas/v4/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {ZHIPUAI_API_KEY}"
}
payload = {
"model": "GLM-4-Flash-250414",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.0, # 0表示完全确定性输出,无随机内容
"max_tokens": 1000,
"response_format": {"type": "text"} # 强制返回纯文本格式
}
# 3. 发送请求
response = requests.post(
url=api_url,
headers=headers,
data=json.dumps(payload)
)
response.raise_for_status()
response_data = response.json()
raw_translation = response_data["choices"][0]["message"]["content"]
# 4. 终极清洗:移除所有可能的冗余内容
cleaned_translation = raw_translation.strip()
# 移除可能的思维链标记(包括中文/英文标记)
cleaned_translation = re.sub(r"^.*?翻译结果:", "", cleaned_translation) # 移除"翻译结果:"前缀
cleaned_translation = re.sub(r"^[\"'](.*?)[\"']$", r"\1", cleaned_translation) # 移除首尾引号
cleaned_translation = re.sub(r"^.*?:", "", cleaned_translation) # 移除任何"XX:"前缀
cleaned_translation = cleaned_translation.strip()
return {
"original_text": request.text,
"target_language": request.language,
"translation": cleaned_translation # 仅保留清洗后的纯翻译结果
}
except requests.exceptions.HTTPError as e:
raise HTTPException(
status_code=response.status_code,
detail=f"API请求失败: {str(e)},响应:{response.text}"
)
except KeyError as e:
raise HTTPException(
status_code=500,
detail=f"响应格式错误,缺少字段: {str(e)},响应:{response.text}"
)
except Exception as e:
raise HTTPException(
status_code=500,
detail=f"翻译出错: {str(e)}"
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000, reload=True)
运行之后得到一个网址http://localhost:8000/docs

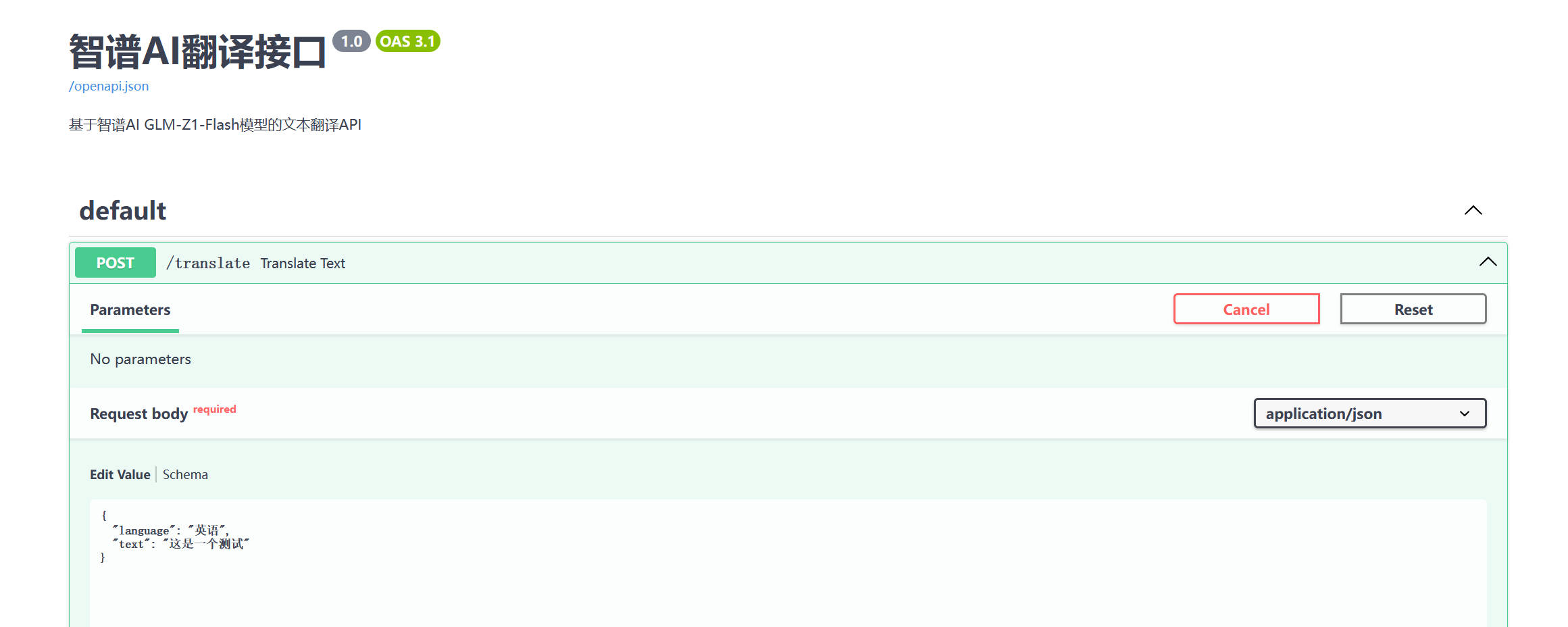
进入网页后,根据豆包的提示进行操作,主要是在edit value中输入语言和翻译句子,在code detail查看结果。经过反复报错修改

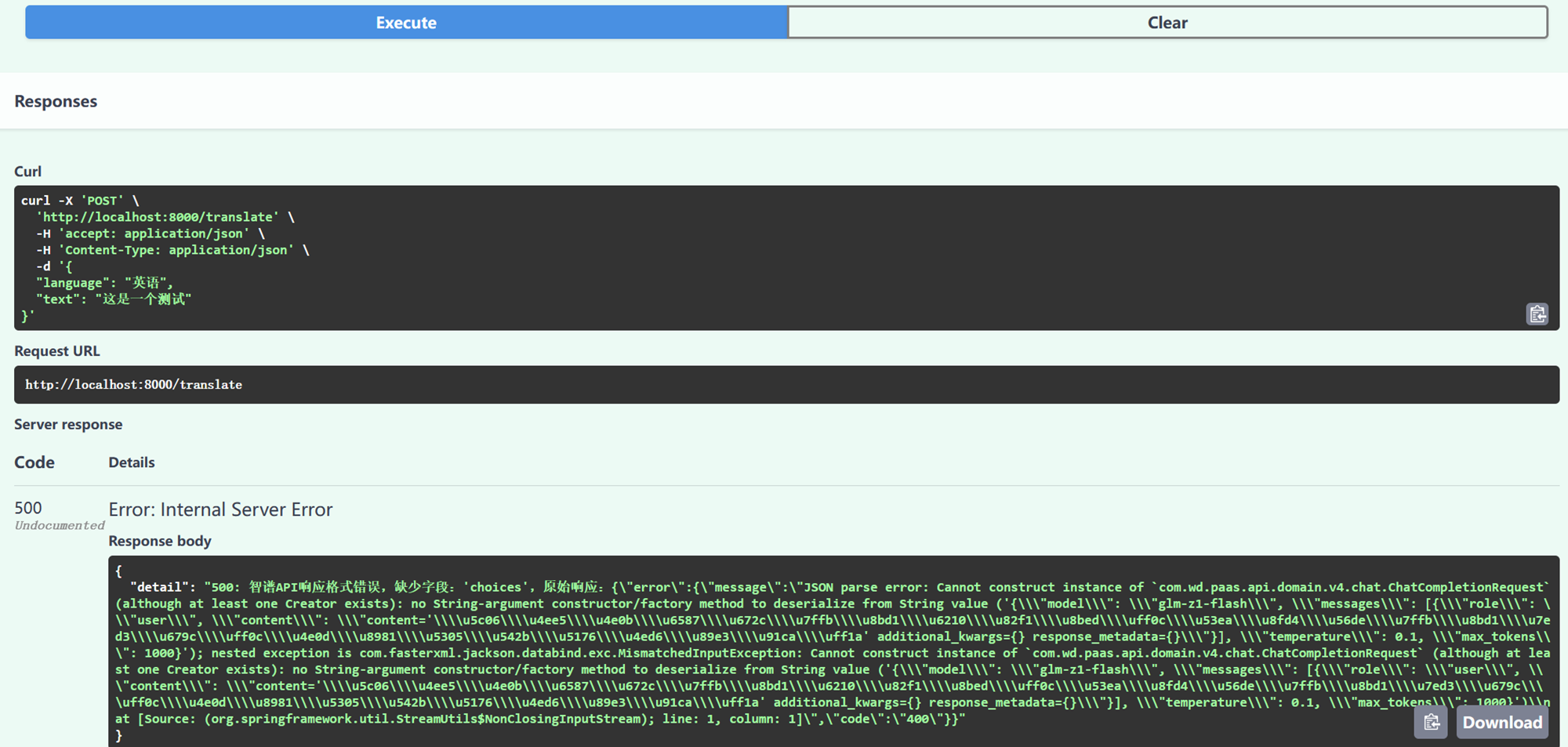 目前我得到的结果是一个推理模型的答案,也就是会有思考过程。要求用英文翻译 "这是一个测试",得到了这样一段文字。
目前我得到的结果是一个推理模型的答案,也就是会有思考过程。要求用英文翻译 "这是一个测试",得到了这样一段文字。
好的,用户让我把“这是一个测试”翻译成英语,而且只要结果,不要解释。首先,我需要确认原文的意思,确保准确翻译。测试在英语中通常是“test”,所以直译的话就是“This is a test.”。\n\n接下来,检查有没有需要注意的地方,比如语法是否正确,有没有拼写错误。确认无误后,按照用户的要求,只返回翻译后的句子,不加任何其他内容。用户可能是在测试翻译功能,或者需要快速得到结果,所以必须简洁。同时,用户可能希望确保翻译的准确性,特别是如果用于正式场合的话。不过这里看起来是简单的测试,所以直接给出正确翻译即可。最后,确保没有多余的空格或符号,符合用户的要求。\n</think>\nThis is a test."
}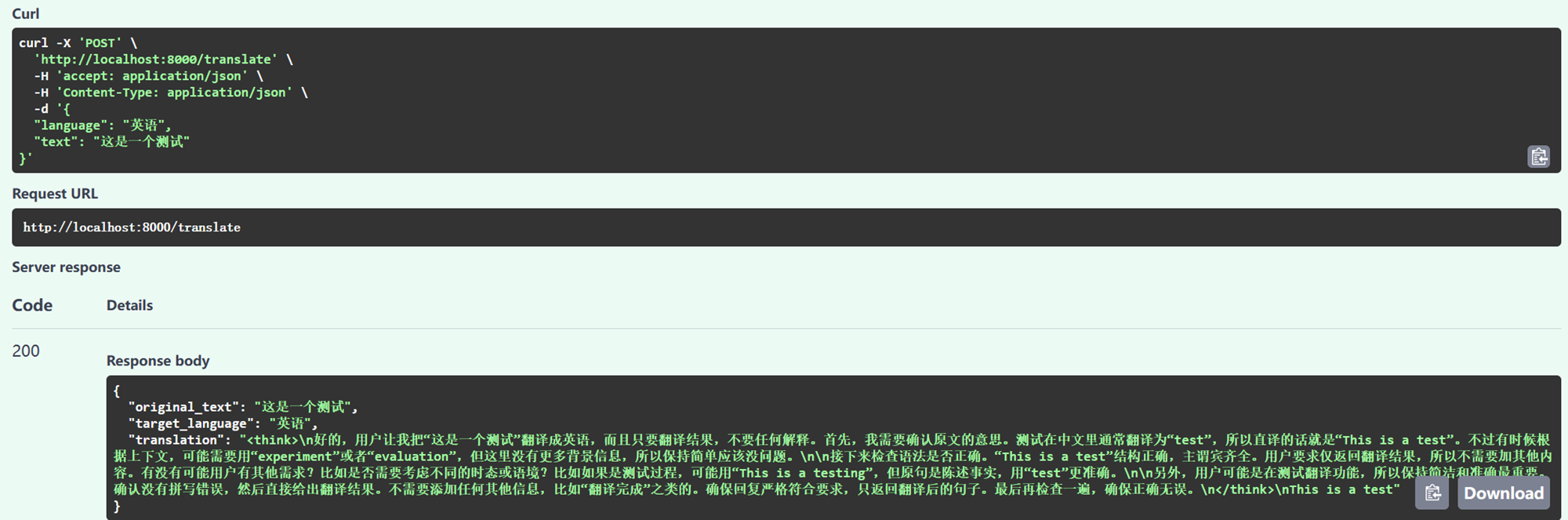 在我替换了不同模型的Api后结果仍然如此,有待继续解决。
在我替换了不同模型的Api后结果仍然如此,有待继续解决。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)