mysql分组查询选择数量最多的前十个_MySQL分组查询前几条数据
分组查询是一个比较常见也稍微复杂一点的查询,好比查询每一个班成绩最好的三名学生,每一个部门工资最高的三个员工等等,今天就分享一下分组查询这样一个用法。sql1、准备工做首先上两张表,部门表和员工表。spa部门表codeDROP TABLE IF EXISTS `department`;CREATE TABLE `department` (`id` int(10) NOT NULL AUTO_INC
分组查询是一个比较常见也稍微复杂一点的查询,好比查询每一个班成绩最好的三名学生,每一个部门工资最高的三个员工等等,今天就分享一下分组查询这样一个用法。sql
1、准备工做
首先上两张表,部门表和员工表。spa
部门表code
DROP TABLE IF EXISTS `department`;
CREATE TABLE `department` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;
INSERT INTO `department` VALUES ('1', '蜀');
INSERT INTO `department` VALUES ('2', '吴');
INSERT INTO `department` VALUES ('3', '魏');
员工表blog
DROP TABLE IF EXISTS `employee`;
CREATE TABLE `employee` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`salary` int(10) DEFAULT NULL,
`department_id` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4;
INSERT INTO `employee` VALUES ('1', '玄德', '20000', '1');
INSERT INTO `employee` VALUES ('2', '公瑾', '15000', '2');
INSERT INTO `employee` VALUES ('3', '云长', '22000', '1');
INSERT INTO `employee` VALUES ('4', '孟德', '15000', '3');
INSERT INTO `employee` VALUES ('5', '子龙', '17000', '1');
INSERT INTO `employee` VALUES ('6', '仲谋', '19000', '2');
INSERT INTO `employee` VALUES ('7', '奉孝', '17000', '3');
INSERT INTO `employee` VALUES ('8', '翼德', '18000', '1');
INSERT INTO `employee` VALUES ('9', '子敬', '12000', '2');
INSERT INTO `employee` VALUES ('10', '元让', '14000', '3');
如今咱们的目标是查询出每一个部门工资最高的三个员工(秉承着褒刘贬曹的态度,蜀国的工资固然是最高的),正确的查询结果以下:排序
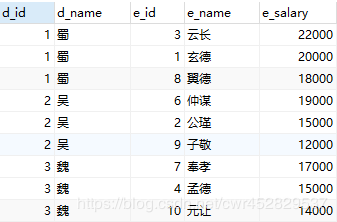
感兴趣的同窗能够先本身尝试一下,固然方法不止一种,这里博主提供其中一种方法:class
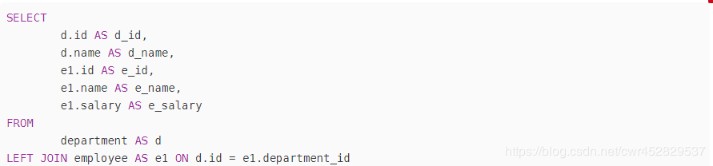
SELECT
d.id AS d_id,
d.name AS d_name,
e1.id AS e_id,
e1.name AS e_name,
e1.salary AS e_salary
FROM
department AS d
LEFT JOIN employee AS e1 ON d.id = e1.department_id
WHERE
(
SELECT
COUNT(*)
FROM
employee AS e2
WHERE
e1.department_id = e2.department_id
AND e1.salary < e2.salary
) < 3
ORDER BY
d_id,
e_salary DESC
若是不太理解这个SQL的同窗能够看一下下面的解析,理解的同窗能够忽略。遍历
解析:
咱们把这条SQL分红三部分来解读,第一部分就是外层WHERE以前的部分方法
第一步im
这一块应该很好理解,就是把部门表和员工表经过左外链接链接在一块儿,这一块代码的执行结果以下:d3
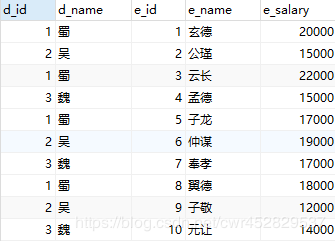
至关于就是把全部的部门和部门对应的员工信息查询出来,下一步咱们须要从中选出各个部门工资最高的三个员工,因此咱们须要加一些查询条件
第二步
第二步就是添加查询条件,这一步也是最重要的一步
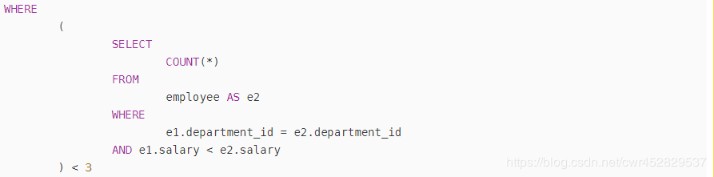
这里能够这样理解,e1是刚才外层咱们查询出来的表,e2就是单独的一张员工表,这里至关于把e1中的每一条数据与e2进行遍历比较(e1.department_id = e2.department_id AND e1.salary < e2.salary),说简单点,这个SELECT就是统计e2中工资比e1高的员工数量(相同部门),举个例子,好比COUNT(*)返回的是1,也就表示e2中只有一个员工比当前e1高,换句话说就是当前的e1是工资是当前部门第二高的,若是COUNT(*)返回的是2,就表示当前e1是工资第三高的,因此这里 < 3就表示选择选择工资前三的员工,可是这个时候尚未排序,因此下一步就是进行排序
第三步
第三步就是对查询出的数据进行排序

表达的不清楚的地方但愿你们多多斟酌一下。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)