【数据结构】--- 并查集
编号为4和9的同学属于1号小分队,该小分队有3人(包含队长1),编号为3和5的同学属于2号小分队,该小分队有3个人(包含队长1)。,现给这些学生进行编号:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};操作后对路径进行压缩(即直接将查询路径上的每个节点的父节点指向根节点),那么每次查询操作会更快,因为树的高度变小了,从而加速未来的查询。: 公司今年校招全国总共招生10人,西安招4人,
Welcome to 9ilk's Code World

(๑•́ ₃ •̀๑) 个人主页: 9ilk
(๑•́ ₃ •̀๑) 文章专栏: 数据结构
本篇博客我们简单介绍一下并查集这个数据结构,讲解它的原理,简单实现以及应用。
🏠 并查集原理
在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。在此过程中要反复用到查询某一个元素归属于那个集合的运算。适合于描述这类问题的抽象数据类型称为并查集(union-find set)。
例子 : 公司今年校招全国总共招生10人,西安招4人,成都招3人,武汉招3人,10个人来自不同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; 给以下数组用来存储该小集体,数组中的数字代表:该小集体中具有成员的个数。(都初始化为-1表示每个元素初始条件都是独立个体,每个集合都是只有自己一个元素)
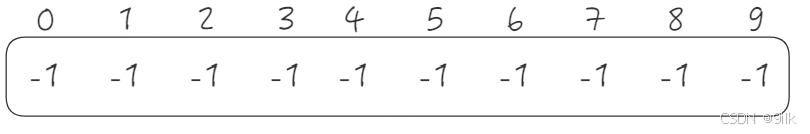
- Q : 怎么描述几个人之间的关系??形成多个集合该如何表示?
1. 建立成多棵树即可,并查集就是森林,一个集合对应一棵树,集合中的一个节点做根,集合的其他节点作为孩子。
2. 可以利用类似堆的方式,利用下标表示关系(双亲表示法)。
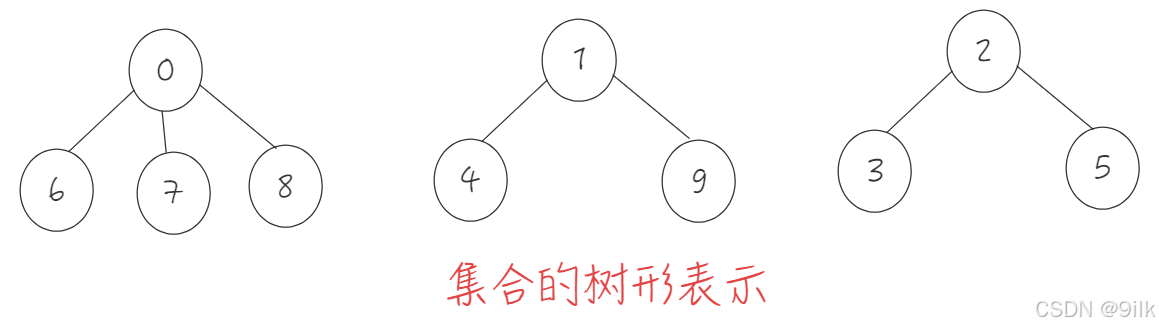
例子:毕业后,学生们要去公司上班,每个地方的学生自发组织成小分队一起上路,于是:西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识了,10个人形成了三个小团体。假设右三个群主0,1,2担任队长,负责大家的出行。
-
从上图可以看出:编号6,7,8同学属于0号小分队,该小分队中有4人(包含队长0);编号为4和9的同学属于1号小分队,该小分队有3人(包含队长1),编号为3和5的同学属于2号小分队,该小分队有3个人(包含队长1)。
一趟火车之旅后,每个小分队成员就互相熟悉,称为了一个朋友圈。
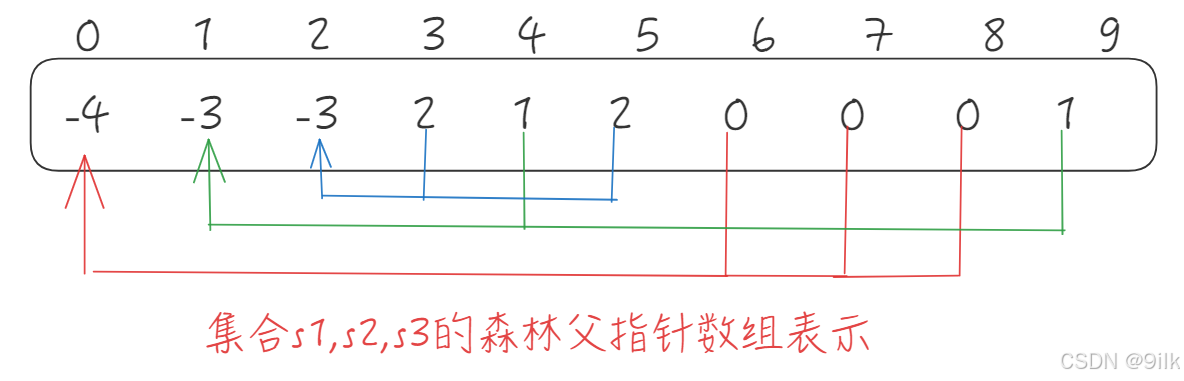
仔细观察数组,可以得出以下结论:
1. 数组的下标对应集合中元素的编号。
2. 数组中如果为负数,负号代表根,数字绝对值代表该集合中元素个数。
3. 数组中如果为非负数,代表该元素双亲在数组中的下标。
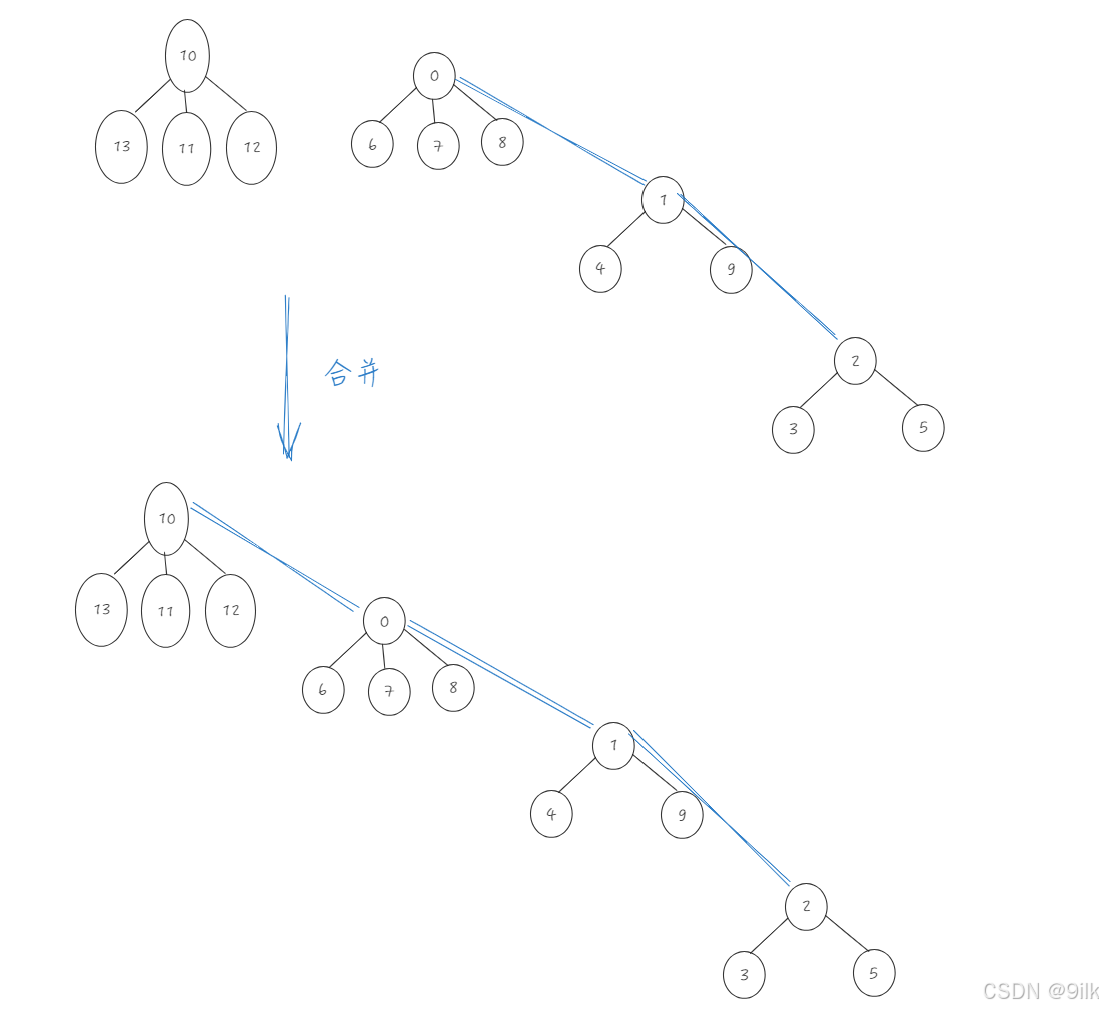
在公司工作一段时间后,西安小分队中8号同学与成都小分队1号同学奇迹般的走到了一起,两个小圈子的学生相互介绍,最后成为了一个小圈子(即已有的集合再合并如何做):
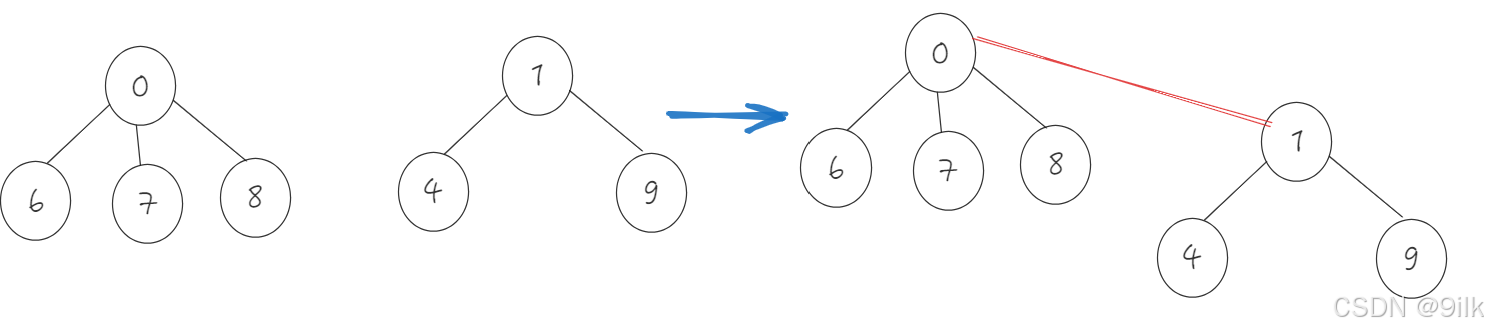
- 合并两个集合:我们需要先找出两节点对应的根,把它们的根合并(如果两根不相等的话),然后将被合并的根的值+=到新根,再让被合并的根的值储存新根的编号。
🏠 并查集实现
🎸 基本结构
实现并查集,我们需要一个数组来表示元素的编号以及通过下标的值表示元素之间的关系。
class UnionFindSet
{
public:
UnionFindSet(size_t n)
:_ufs(n,-1) //初始状态都为一个独立个体集合
{}
private:
vector<int> _ufs;
};- 一开始每个元素都是独立个体,自成一个集合,都设置为-1,表示该集合(树)有一个元素。
🎸 FindRoot
int FindRoot(int x) //找根结点
{
int root = x;
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
return root;
}- FindRoot : 查找某个节点的根节点,我们可以通过判断对应数组下标中的值来查找。如果值为负数,说明该下标就是根节点的下标;否则顺着数组下标对应的值继续找根节点下标,直到找到数组下标中的值为负数为止。
🎸 Union
void Union(int x1,int x2) //合并两个结点
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2) return;//两者本来就是一个集合没必要合并
if (root1 > root2)
swap(root1, root2);
//让小的root1作为根结点 先将root2的值都给root1,然后root2的值存root1下标
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
}- Union : 合并两节点。合并即合并两者的根节点,因此我们需要先找出两者的根节点,如果两者根节点相同就不需要合并,否则进行合并,更新数组下标中的值。
注意:根节点值为负数,负数的绝对值代表该集合中元素个数!
void Union(int x1,int x2) //合并两个结点
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2) return;//两者本来就是一个集合没必要合并
if (abs(root1) < abs(root2)) //数量小的向数量大的集合合并
swap(root1, root2);
//让小的root1作为根结点 先将root2的值都给root1,然后root2的值存root1下标
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
}- 优化:在合并节点时,如果节点数量大的集合往节点数量小的集合合并,可能导致路径过长,此时我们可以进行一个优化使数量小的往大的合并。
🎸 InSet
bool InSet(int x1,int x2) //两个结点是否在一个集合:其实就是比较两者根节点是否相同
{
return FindRoot(x1) == FindRoot(x2);
}- InSet : 判断两个节点是否属于一个集合,其实就是判断两节点根节点是否相同。
🎸 SetSize
size_t SetSize()//集合个数: 找有多少根结点->找多少下标的值为-1
{
int count = 0;
for (auto& v : _ufs)
if (v < 0) count++;
return count;
}- SetSize : 树(集合)的数量。只需遍历数组查看对应数组下标中的值为负数即是根节点。
完整参考代码:
class UnionFindSet
{
public:
UnionFindSet(size_t n)
:_ufs(n,-1) //初始状态都为一个独立个体集合
{}
int FindRoot(int x) //找根结点
{
int root = x;
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
return root;
}
void Union(int x1,int x2) //合并两个结点
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2) return;//两者本来就是一个集合没必要合并
if (root1 > root2)
swap(root1, root2);
//让小的root1作为根结点 先将root2的值都给root1,然后root2的值存root1下标
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
}
bool InSet(int x1,int x2) //两个结点是否在一个集合:其实就是比较两者根节点是否相同
{
return FindRoot(x1) == FindRoot(x2);
}
size_t SetSize()//集合个数: 找有多少根结点->找多少下标的值为-1
{
int count = 0;
for (auto& v : _ufs)
if (v < 0) count++;
return count;
}
private:
vector<int> _ufs;
};🏠 并查集应用
通过以上学习,并查集一般可以解决一下问题:
1. 查找元素属于哪个集合:沿着数组表示树形关系以上一直找到根(即:树中中元素为负数的位置)。
2. 查看两个元素是否属于同一个集合:沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在。
3. 将两个集合归并成一个集合:
- 将两个集合中的元素合并
- 将一个集合名称改成另一个集合的名称
4. 集合的个数:遍历数组,数组中元素为负数的个数即为集合的个数。
(1)省份数量

- 思路 : 知道并查集及其性质,本题就容易许多。我们可以将城市下标存进并查集里,如果城市之间直接相连则进行合并集合,最后统计有多少个集合就是有多少省份。
class UnionFindSet
{
public:
UnionFindSet(size_t n)
:_ufs(n,-1) //初始状态都为一个独立个体集合
{}
int FindRoot(int x) //找根结点
{
int root = x;
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
return root;
}
void Union(int x1,int x2) //合并两个结点
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2) return;//两者本来就是一个集合没必要合并
if (root1 > root2)
swap(root1, root2);
//让小的root1作为根结点 先将root2的值都给root1,然后root2的值存root1下标
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
}
bool InSet(int x1,int x2) //两个结点是否在一个集合:其实就是比较两者根节点是否相同
{
return FindRoot(x1) == FindRoot(x2);
}
size_t SetSize()//集合个数: 找有多少根结点->找多少下标的值为-1
{
int count = 0;
for (auto& v : _ufs)
if (v < 0) count++;
return count;
}
private:
vector<int> _ufs;
};
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected)
{
int n = isConnected.size();//城市的数量
UnionFindSet ufs(n);
for(int i = 0 ; i < isConnected.size() ; i++)
{
for(int j = 0 ; j < isConnected[0].size() ; j++)
{
if(isConnected[i][j] == 1)
ufs.Union(i,j);
}
}
return ufs.SetSize();
}
};
由于C++库中并未实现并查集,因此直接手搓一个未免有点麻烦,我们其实可以直接使用vector来实现并查集相关操作的接口即可。
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected)
{
int n = isConnected.size();//城市的数量
vector<int> ufs(n,-1);
auto FindRoot = [&ufs](int x){
while(ufs[x] >= 0)
x = ufs[x];
return x;
}; //寻找根节点
for(int i = 0 ; i < isConnected.size() ; i++)
{
for(int j = 0 ; j < isConnected[0].size() ; j++)
{
if(isConnected[i][j] == 1) //合并集合
{
int root1 = FindRoot(i);
int root2 = FindRoot(j);
if(root1 != root2)
{
ufs[root1] += ufs[root2];
ufs[root2] = root1;
}
}
}
}
//找集合个数
int ret = 0 ;
for(int i = 0 ; i < n ; i++) //SetSize
if(ufs[i] < 0) ret++;
return ret;
}
};(2) 等式方程的可满足性

- 思路:同样我们可以利用并查集性质,开一个26大小的数组,先处理等式方程将 == 左右两边的元素放进一个集合;接着再处理不等式方程,查看!=左右两边的元素是否在一个集合,在则返回false。
参考代码:
class Solution {
public:
bool equationsPossible(vector<string>& equations) {
vector<int> ufs(26,-1);
auto FindRoot = [&ufs](int x){
while(ufs[x] >= 0)
x = ufs[x];
return x;
};
//第一次将符号为相等的放进一个集合
for(int i = 0 ; i < equations.size();i++)
{
if(equations[i][1] == '=')
{
int root1 = FindRoot(equations[i][0] - 'a');
int root2 = FindRoot(equations[i][3] - 'a');
if(root1 != root2)
{
ufs[root1] += ufs[root2];
ufs[root2] = root1;
}
}
}
//第二次遍历找!=
for(int i = 0 ; i < equations.size() ; i++)
{
if(equations[i][1] == '!')
{
int root1 = FindRoot(equations[i][0] - 'a');
int root2 = FindRoot(equations[i][3] - 'a');
if(root1 == root2) return false;
}
}
return true;
}
};🏠 压缩路径
Q : 什么时候需要压缩路径?
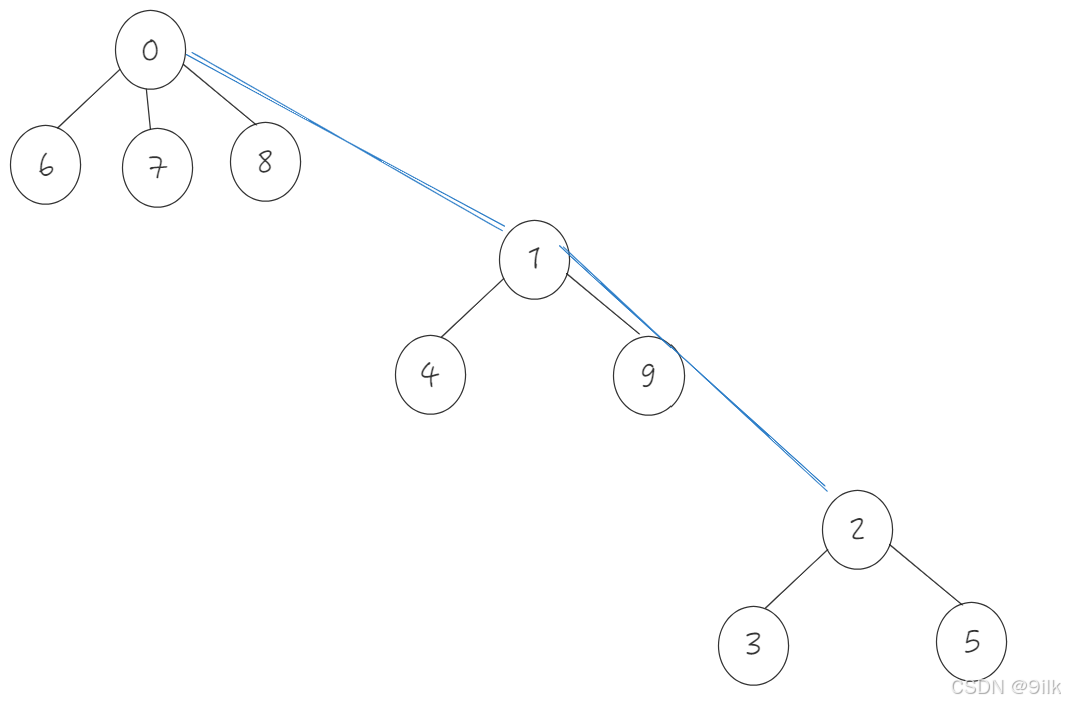
在并查集的基本实现中,每个元素都有一个指向其父节点的指针。当我们调用 FindRoot(x) 操作时,我们沿着父节点链一直查找,直到找到一个根节点。这个过程的时间复杂度为树的高度。每次调用 FindRoot(x) 操作时,如果树的高度较高(如上图,下面两个集合先合并再和最上面合并就会导致),为了减少树的高度,路径压缩应该立即进行。
如果我们在每次 FindRoot(x) 操作后对路径进行压缩(即直接将查询路径上的每个节点的父节点指向根节点),那么每次查询操作会更快,因为树的高度变小了,从而加速未来的查询。
Q:怎么实现路径压缩?
路径压缩的核心思想是在每次 FindRoot操作过程中,将沿途经过的节点直接连接到根节点,减少树的高度。
int FindRoot(int x)
{
if (_ufs[x] < 0) return x; // 这是根节点
// 路径压缩:递归查找并将每个节点直接连接到根节点
_ufs[x] = FindRoot(_ufs[x]);
return _ufs[x];
}- 每次调用
FindRoot时,经过的路径上的所有节点都会直接指向根节点,后续查询的时间复杂度大大降低。
当然我们也可以采取循环的方式来压缩路径:
int FindRoot(int x) //找根结点
{
int root = x;
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
//找到根节点之后 从下往上压缩
while(_ufs[x]>=0)
{
int parent = _ufs[x];
_ufs[x] = root;
x = parent;
}
return root;
}文章如有不正欢迎指出~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 52
52 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)