开源版 DeepSeek R1:对 DeepSearch R3 的完全开放复现
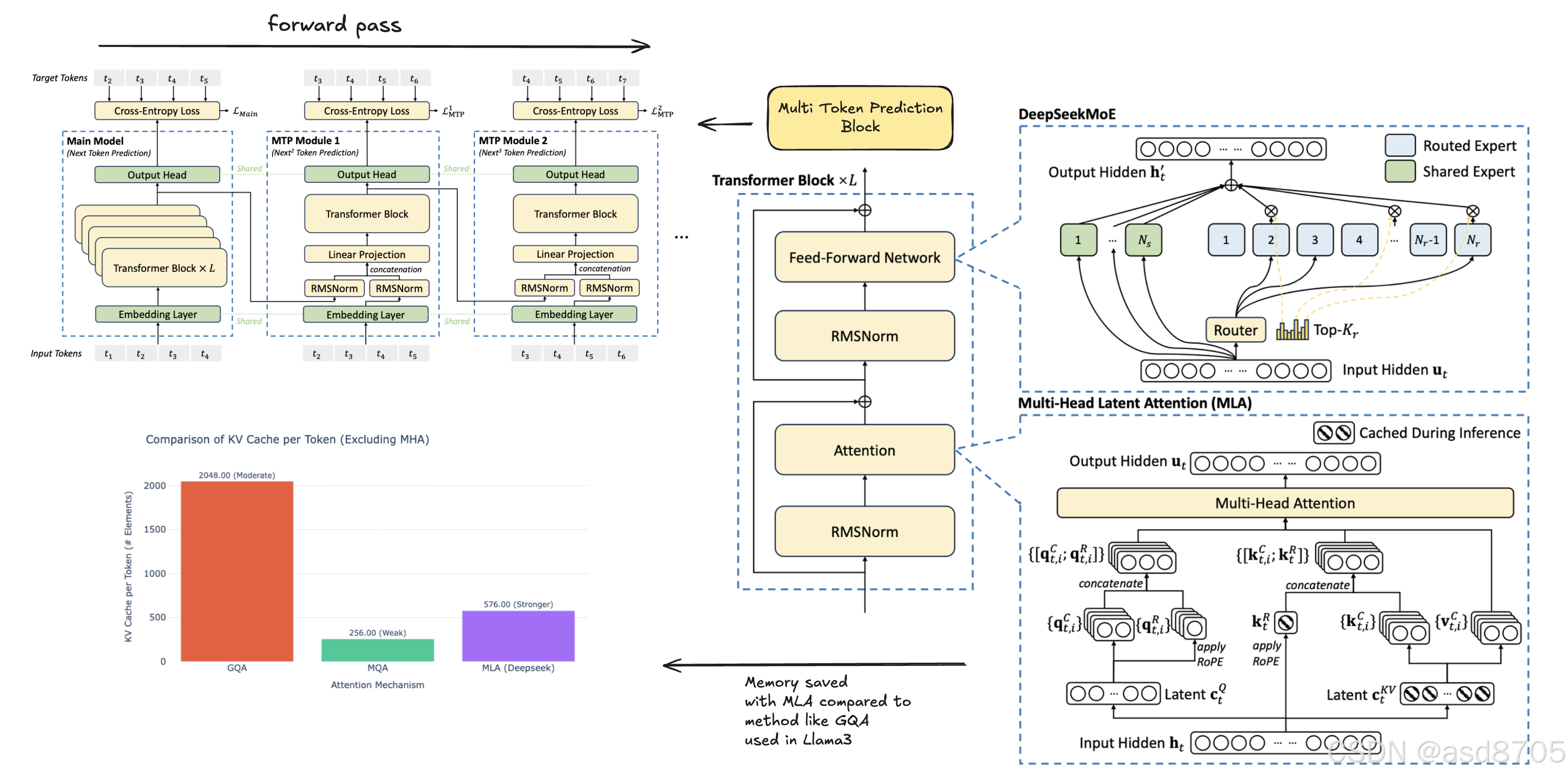
DeepSeek-R1 是一个基于深度求索 V3 的推理模型。这款拥有 671B 参数规模的大型混合专家(Mixture of Experts, MoE)式神经网络,与Sonnet 3.5以及GPT‑40等顶尖大师水平并驾齐驱,更令人惊叹的是,在实现这一成就时,其训练成本仅为580万美元,这一切都是通过多 token 预测(Multi Token Prediction, MTP)、多头潜在注意力机
深度求索-R1是什么?
如果你曾经遇到过棘手的数学问题,你就会明白多花点时间认真思考有多有用。就像OpenAI的o1模型所展示的那样,当大型语言模型(LLMs)在推理任务(如数学、编程和逻辑)中被训练得更彻底——即在预测阶段使用更多计算资源——它们就能显著提升解决这些任务的问题能力。
然而,OpenAI 推理模型背后的秘密一直被严格保密——直到上周,当深度求索公司发布了 DeepSeek-R1 模型后,它迅速引发了一场网络瘫痪(以及股市动荡!)。
除了性能表现至少与或优于o1相当外,DeepSeek-R1发布时还伴随着一份详细技术报告,该报告阐述了其训练配方中的关键步骤。此配方涉及多项创新,其中最值得注意的是,他们采用纯强化学习(reinforcement learning)来无需人工监督地教一个基础语言模型进行推理,如下图所示:如果你拥有能力强大的基础模型以及高质量数据混合,那么现在创建一个有力的推理模型变得非常简单。
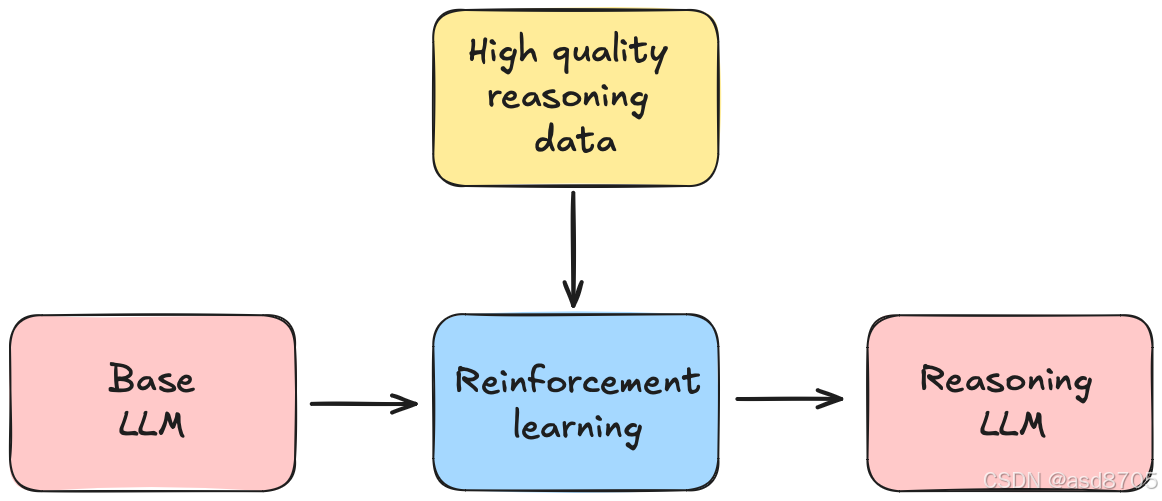
然而,DeepSeek-R1发布后仍存在以下几个问题:
数据收集:推理特定数据集如何被筛选或整理?
模型训练:未公开提供任何训练代码,因此尚不清楚哪些超参数效果最佳,以及它们与不同模型家族、尺度之间是否有所区别。
扩展规律:在训练推理型模型时,有关计算资源与数据之间权衡的情况是什么?
这些问题促使我们启动了Open-R1项目,以系统性地重构DeepSeek-R1的数据和训练管道、验证其声明并推动开放式推理模型的边界。在通过建设Open-R1,我们旨在提供关于如何强化学习能增进推理方面的透明度,与开源社区分享可复现见解,并为未来模型打下利用这些技术方法之基础。
在这篇博客文章中,我们将探讨DeepSeek-R1的关键成分,是哪些部分我们计划进行复制,以及如何贡献给Open-R1项目。让我们开始吧!🚀
他们怎么做到的?
DeepSeek-R1 是一个基于深度求索 V3 的推理模型。就像任何优秀的推理模型一样,它都建立在坚实基石之上,而深度求索 V3 刚好就是这个基石。这款拥有 671B 参数规模的大型混合专家(Mixture of Experts, MoE)式神经网络,与Sonnet 3.5以及GPT‑40等顶尖大师水平并驾齐驱,更令人惊叹的是,在实现这一成就时,其训练成本仅为580万美元,这一切都是通过多 token 预测(Multi Token Prediction, MTP)、多头潜在注意力机制(Multi-Head Latent Attention, MLA)等架构创新,以及大量硬件优化所实现。
深度求索(DeepSeek)还推出了两款模型:深度求索R1-Zero和深度求索R1,每款模型采用了不同的训练方法。其中,深度求索R1-Zero完全避免了监督微调,而是仅依靠强化学习(Reinforcement Learning, RL),并结合组群相对策略优化(Group Relative Policy Optimization, GRPO)使训练过程更加高效。一种简单的奖励系统被用于引导模型,其根据回答的准确性及结构提供反馈。这一方法帮助模型培养了一些有用的推理能力,如将问题拆解为步骤、以及验证自身输出。但该方法生成的回答往往缺乏清晰度且难以阅读。
这就是DeepSeek-R1发挥作用的地方。它首先经历了一个"冷启动"阶段,在一个精心设计的小示例集中进行微调,以提高清晰度和可读性。不久之后,它又接受了更多强化学习(RL)和优化步骤,其中包括利用基于人工偏好的评分标准以及可以验证的奖励机制来拒绝低质量输出,从而打造出一个既擅长推理又能生成整齐一致答案的模型。
这些听起来都很不错,但到底哪里有问题呢?让我们一起找出这些“空白”吧!
Open-R1: 缺失的模块
深度求索R1的发布为社区带来了巨大的利益,但他们并未全面开放——尽管模型权重已公开,但训练该模型所用的数据集与代码却未透露 😢.
而Open-R1项目正是为了填补这些空白,使整个研究与产业界能够基于这些材料搭建类似或更优质的模型。而通过开源开发,这也让所有人都能参与进来!
以下是我们的计划:
Step 1: 通过对DeepSeek-R1中的高质量推理数据集进行蒸馏,复制R1-Distill模型。
Step 2: 复制DeepSeek用于创建R1-Zero的纯RL管线。这将涉及整理大规模针对数学、推理和代码的心智数据集。
Step 3: 展示我们可以通过多阶段训练实现:基线模型→SFT→RL。
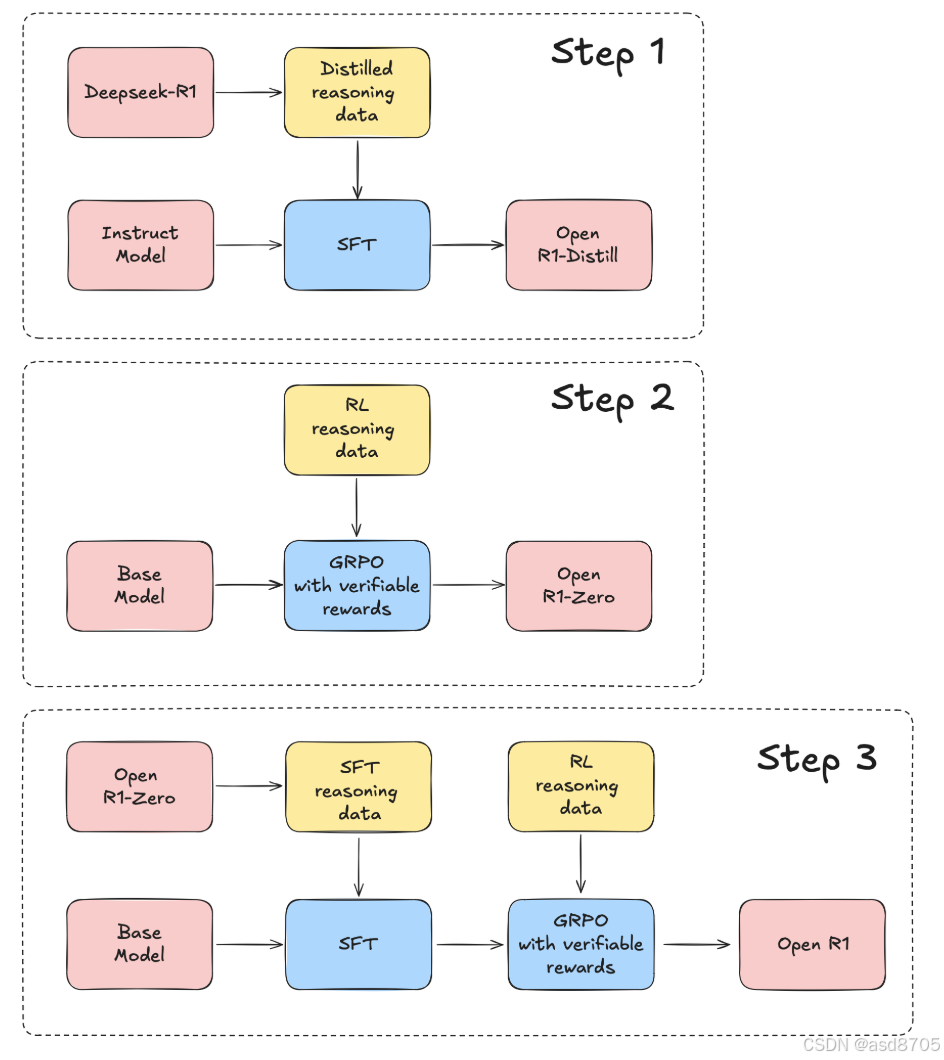
这些合成数据集将使每个人能够通过仅对它们进行微调,将现有或新的大型语言模型(LLM)转变为推理型模型。与此同时,与之相关联的一套基于强化学习(Reinforcement Learning, RL) 的训练方案,将为任何人提供构建类似类型模式的一个起点,并且还将使研究人员能够在此基础上打造出更加先进的手法。
请注意,我们不仅想要停留在数学数据集中。在探索其他领域方面有很多潜力,其中一个明显的例子就是代码,但也包括诸如医学这样的科学领域,在这些领域中,推理模型可能会产生巨大的影响。
这项举措不仅仅是复制成功的经验——更重要的是与社区分享所获得的见解。通过记录哪些方法奏效、哪些没有效果以及背后的原因,我们希望能帮助他人避免浪费时间并避开那些毫无收获之路。
如果你觉得有趣,我们非常期待你的帮助!无论是编写代码还是加入Hugging Face上的讨论,有许多方式可以参与进来。一起让我们建设它!🚀

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)