当企业数据遇上 AI,豆包可以本地离线运行了,数据安全的福音
一、数据隐私和安全问题
在数字化浪潮席卷的当下,企业积累的核心商业数据、机密研究成果等重要信息,构成了其在市场竞争中披荆斩棘的 “铠甲”。这些数据承载着无数心血与智慧,是不容有失的企业命脉。然而,随着 AI 技术的迅猛发展,当我们渴望借助 AI 强大的阅读与分析能力,从海量数据中挖掘价值、洞察趋势时,却陷入了两难的困境。
将这些关键数据上传至互联网使用在线 AI 服务,就如同将自家的钥匙随意交给陌生人。尽管互联网 AI 能够快速处理数据、给出分析结果,但数据一旦离开安全可控的内部环境,就暴露在了复杂多变的网络风险之中。数据泄露、被恶意篡改、非法窃取等隐患如影随形,任何一个安全漏洞都可能让企业遭受难以估量的损失。
在这样的困局下,本地离线大模型犹如黑暗中的灯塔,为我们指明了方向。它无需将数据上传至云端,所有的数据处理与分析都在企业内部安全可控的环境中完成。就像将一位智能助手请到企业内部,它扎根于本地,不与外界进行数据交互,仅专注于企业赋予的任务。本地离线大模型凭借强大的计算能力和先进算法,能够高效读取、分析企业内部数据,精准提取关键信息,助力企业发现数据背后的隐藏价值。
同时,本地离线大模型还具备高度的定制化优势。企业可以根据自身业务需求和数据特点,对模型进行个性化训练和优化,使其更加贴合实际应用场景,实现 “私人订制” 般的智能服务。在保障数据安全的基础上,充分发挥 AI 的价值,让数据真正成为驱动企业创新与发展的核心动力,帮助企业在数字时代既享受 AI 带来的便利,又无需为数据安全提心吊胆。
二、操作步骤
(一)下载豆包客户端
进入下载页面:https://www.doubao.com/download/desktop
(二)进入设置页面
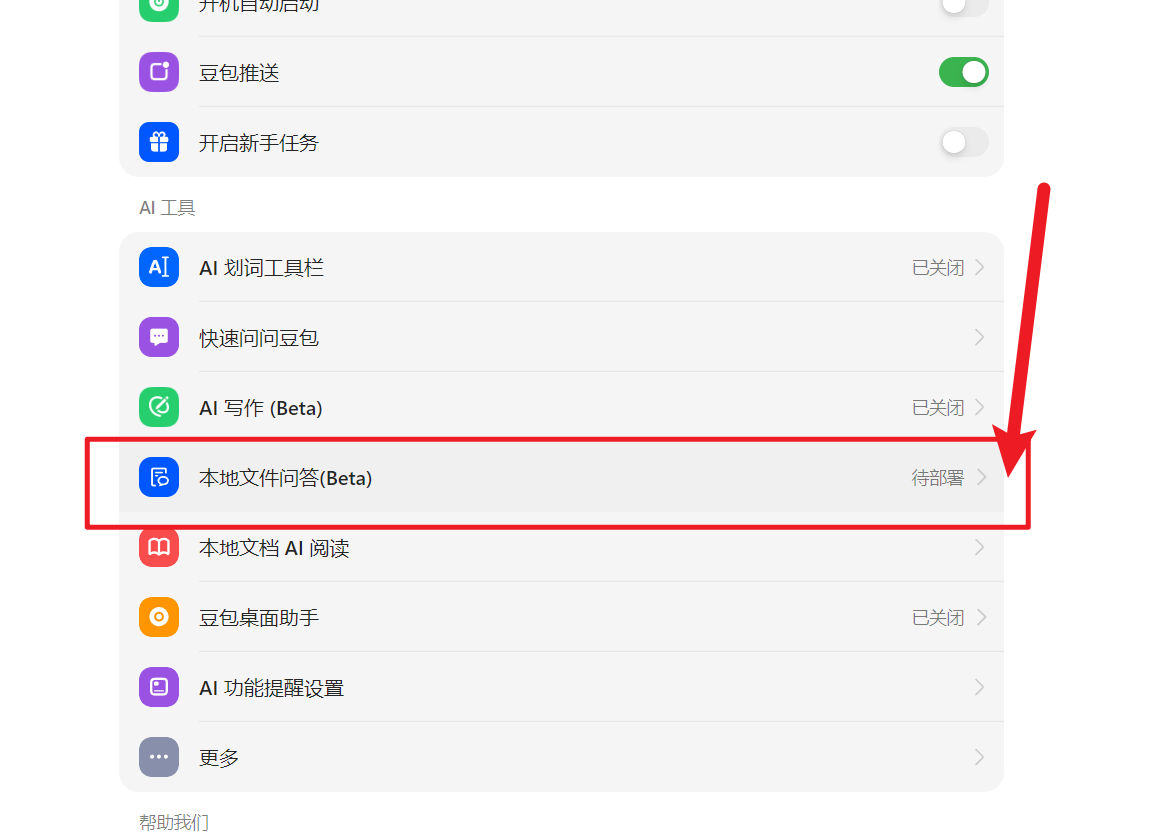
在【AI工具】区域找到 【本地文件问答】,点击右侧的箭头
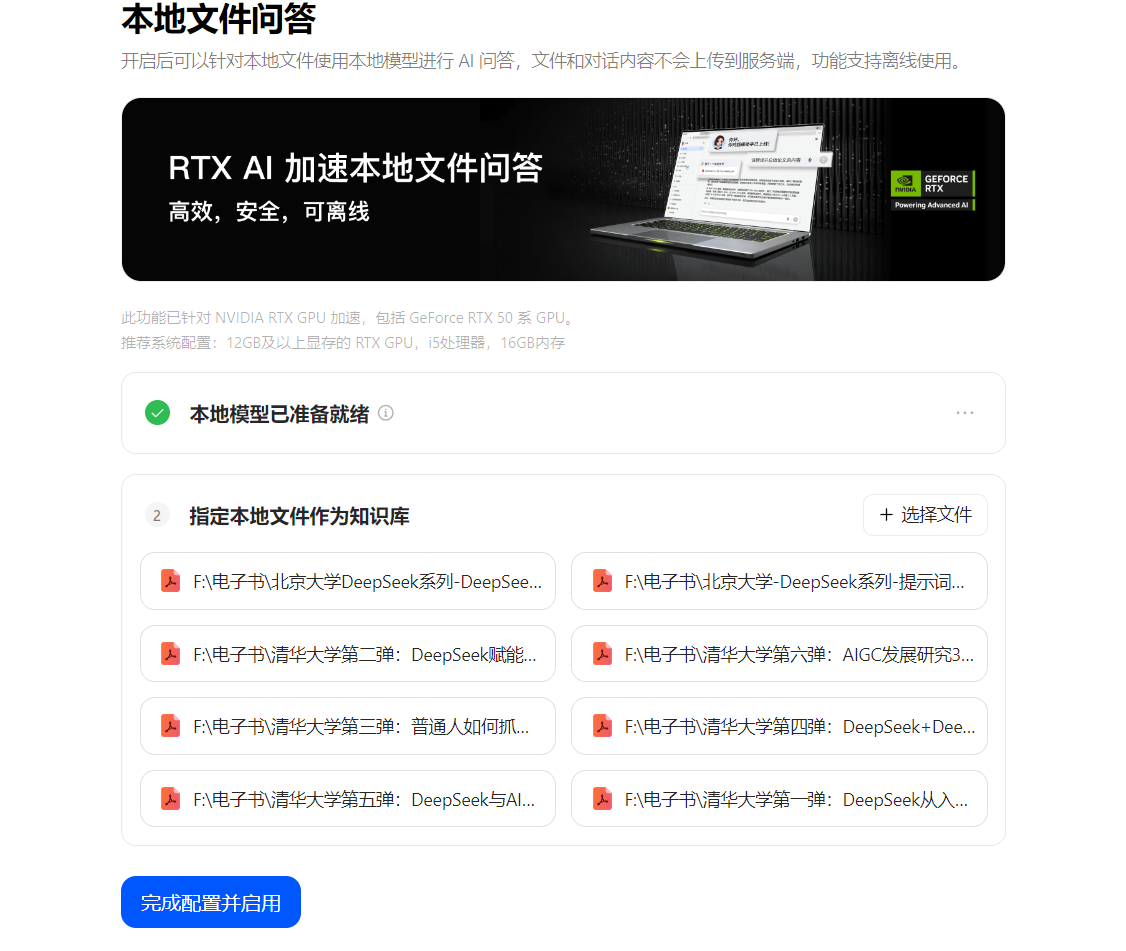
(三)指定本地文件
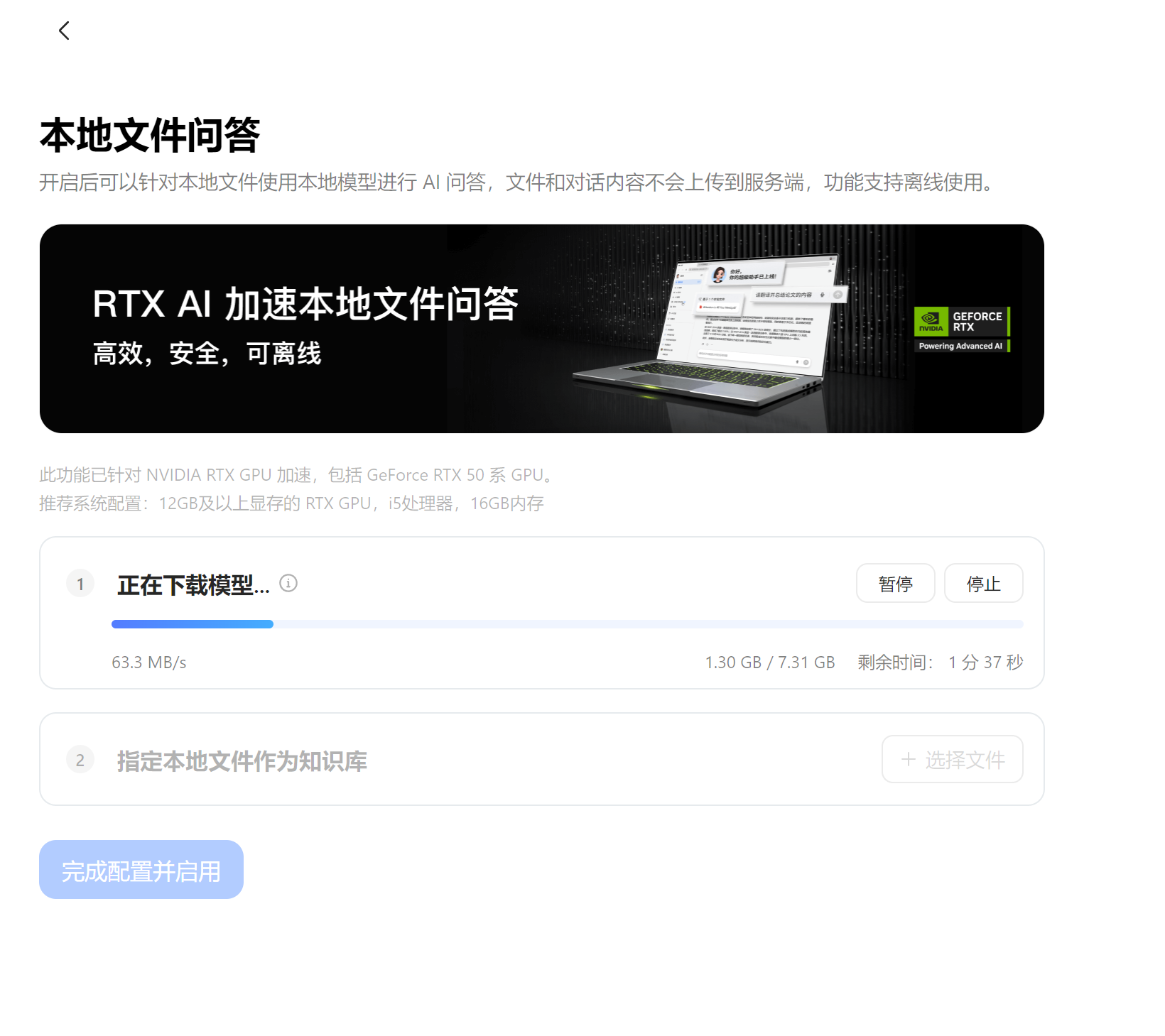
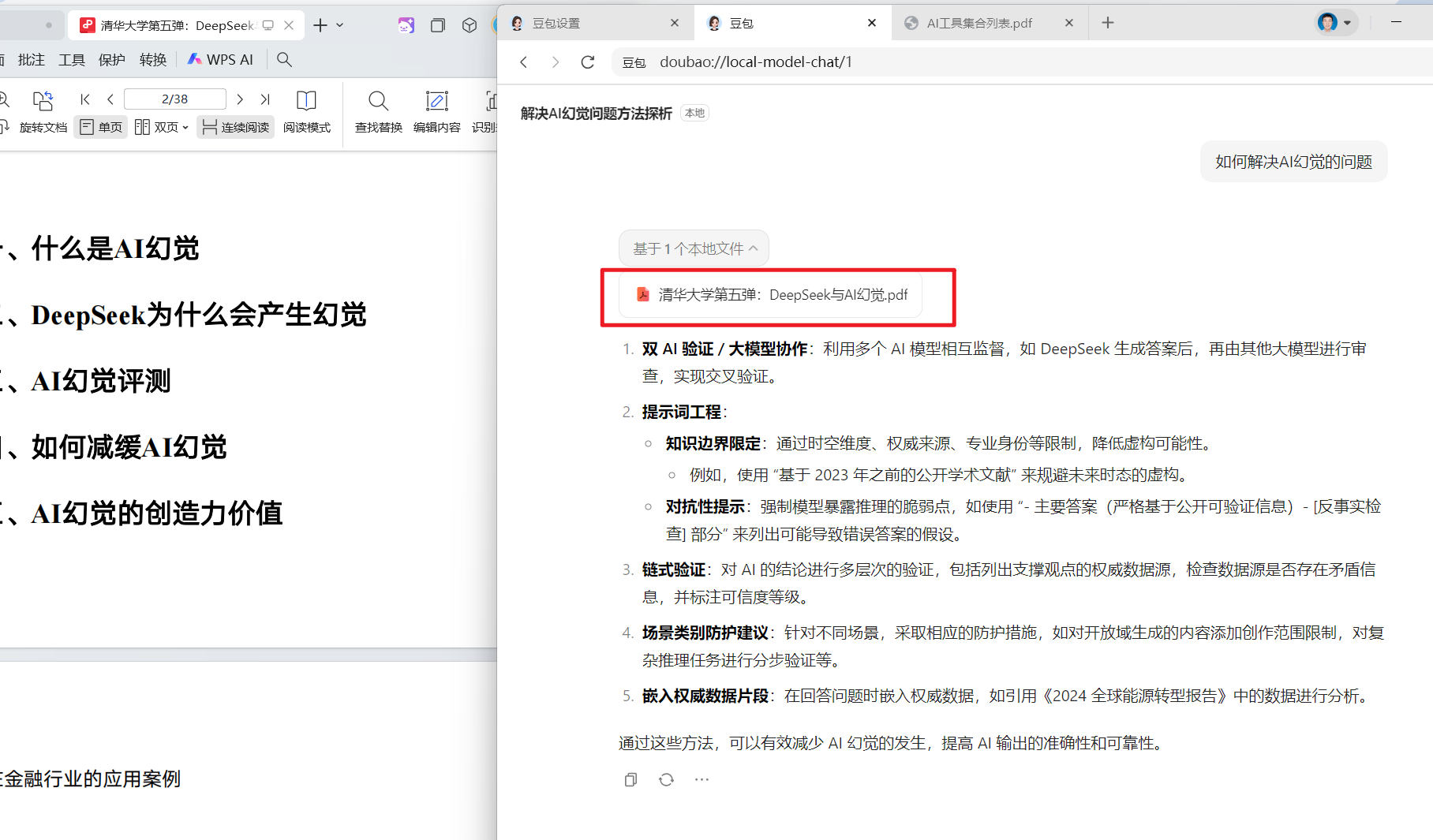
开启后可以针对本地文件使用本地模型进行 AI 问答,文件和对话内容不会上传到服务端,这个功能简直太贴心了,既能使用了大模型,又保护了数据隐私。
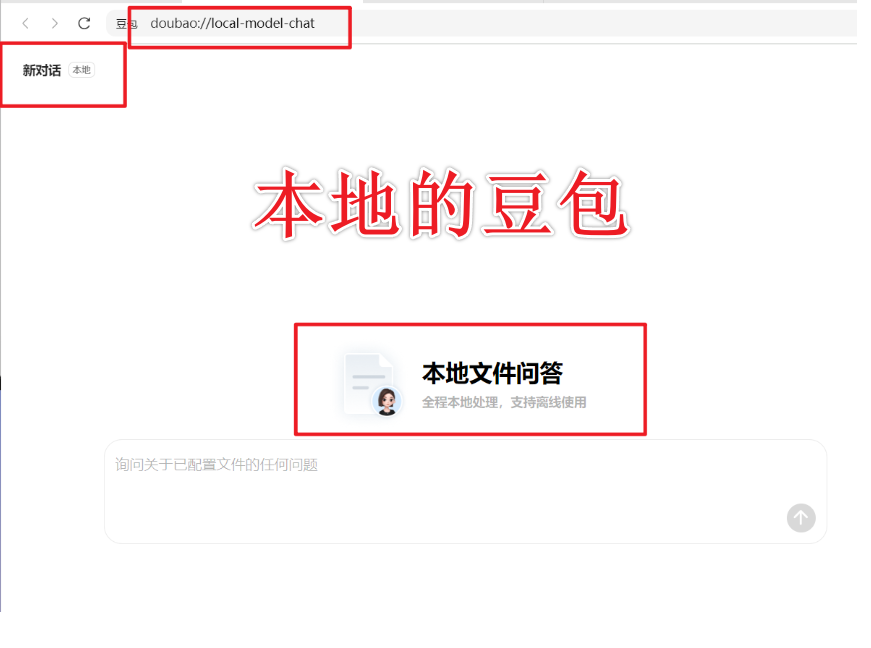
(四)发起对话
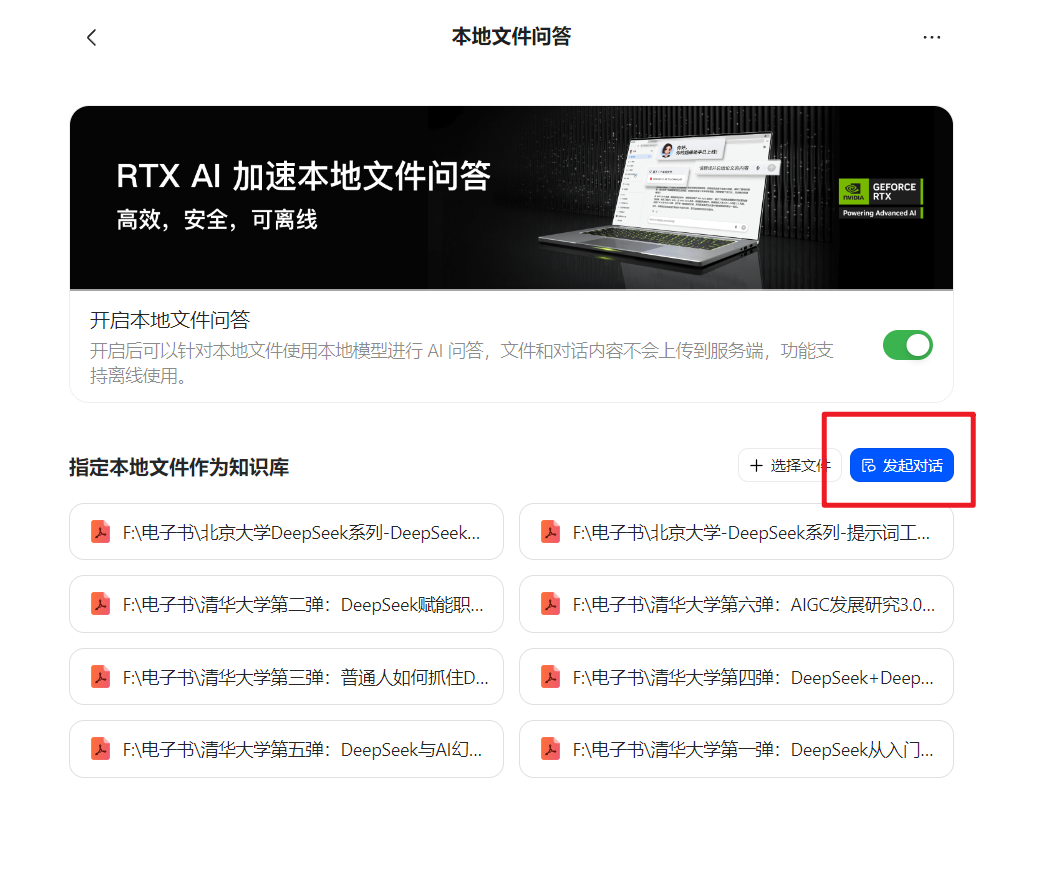
(五)本地对话
本地文件问答全程本地处理,支持离线使用
最大的福音
三、其他本地模型:
当然能本地运行的大模型还有很多开源的,但安装成本较高。
以下是一些开源大模型:
- 通义千问Qwen3:阿里开源模型,获国际权威测评榜开源模型冠军。
- Llama 3:Meta发布的开源模型,同体量下性能出色。
- Phi-3:微软开发的小型开源语言模型,所需资源少。
- Falcon 180B:计算能力强,在多种NLP任务中表现出色。
- BLOOM:1760亿参数的开放获取语言模型,支持多种语言。
- XGen-7B:Salesforce推出的LLM,支持长上下文窗口,效率高。
- GPT - NeoX:EleutherAI开发的GPT开源替代品,可用于多任务。
- Vicuna - 13B:基于LLaMa 13B微调的开源对话模型,应用广泛。
- Mixtral 8x7B:Mistral AI推出的模型,采用稀疏专家混合架构。
- Yi - 34B:零一万物的开源模型,在中英文任务中表现出色。
- CodeGeeX:清华大学等机构开发,130亿参数的多语言代码生成模型。
- OPT:一系列仅包含解码器的预训练transformers模型,零样本和少样本学习能力强。
- CPM:中文预训练语言模型,由26亿参数和100GB中文训练数据组成。
- GLM - 130B:1300亿参数的双语(英文和中文)预训练语言模型。
- mT5:T5的多语言变体,在101种语言的数据集上预训练。
可以看我以前的文章,大模型的本地部署

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)