向量数据库对比:Faiss vs Chroma vs Milvus
向量数据库是一种专门的存储系统,旨在有效地处理和查询高维向量数据,通常用于快速检索和相似性搜索。简而言之,我们使用它们来查找不一定是“精确”而是“相似”的数据,这使得它们对于处理大量文档、图像和音频文件的用户非常有用。如今,它们在 RAG(检索增强生成)等 AI 驱动的应用程序中越来越受欢迎。由于 AI 的速度仍然相对较慢,矢量数据库可以充当前线,检索相关数据以供 AI 稍后处理。那么,我们实际上
什么是矢量数据库?
向量数据库是一种专门的存储系统,旨在有效地处理和查询高维向量数据,通常用于快速检索和相似性搜索。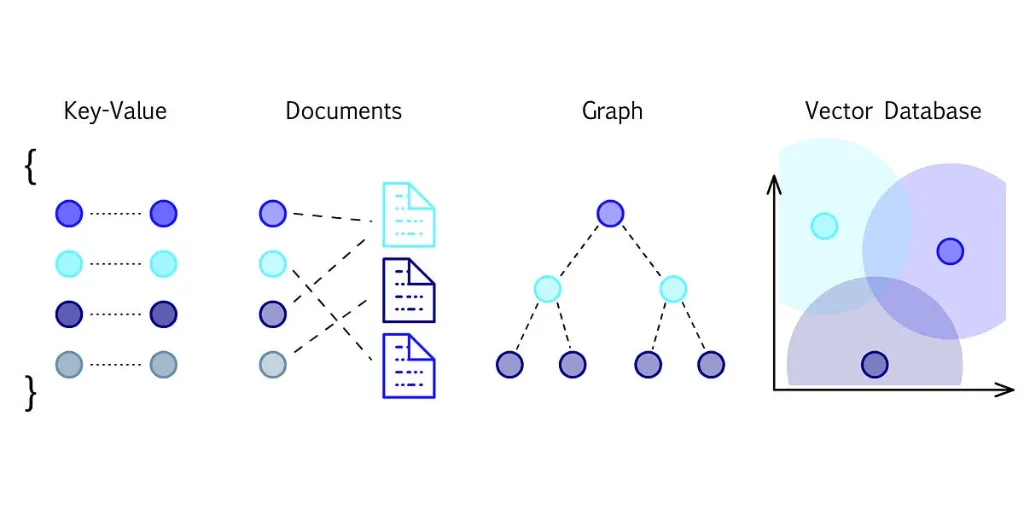
简而言之,我们使用它们来查找不一定是“精确”而是“相似”的数据,这使得它们对于处理大量文档、图像和音频文件的用户非常有用。如今,它们在 RAG(检索增强生成)等 AI 驱动的应用程序中越来越受欢迎。由于 AI 的速度仍然相对较慢,矢量数据库可以充当前线,检索相关数据以供 AI 稍后处理。
什么是向量嵌入?
那么,我们实际上在其中存储了什么呢?原始数据?不完全是。我们存储从原始数据中嵌入的向量。向量嵌入是一种将单词、句子和其他类型的数据转换为数字以捕获其含义和关系的方法。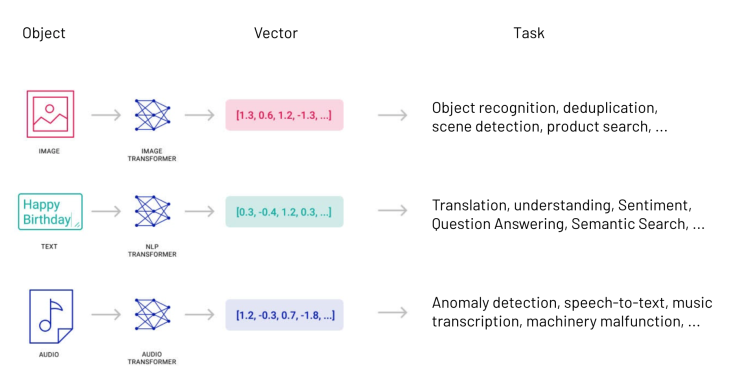
为此,我们需要一个机器学习 (ML) 过程,在该过程中训练模型将上述任何数据类型转换为数字向量。将向量插入数据库后,我们还需要使用 Vectors 查询它们,因此使用相同的 ML 模型进行插入和查询非常重要。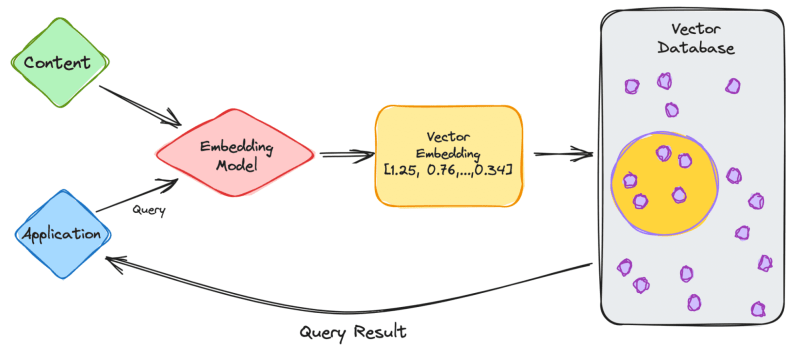
另一个重要因素是获取期间的索引,以最有效的方式存储和检索数据。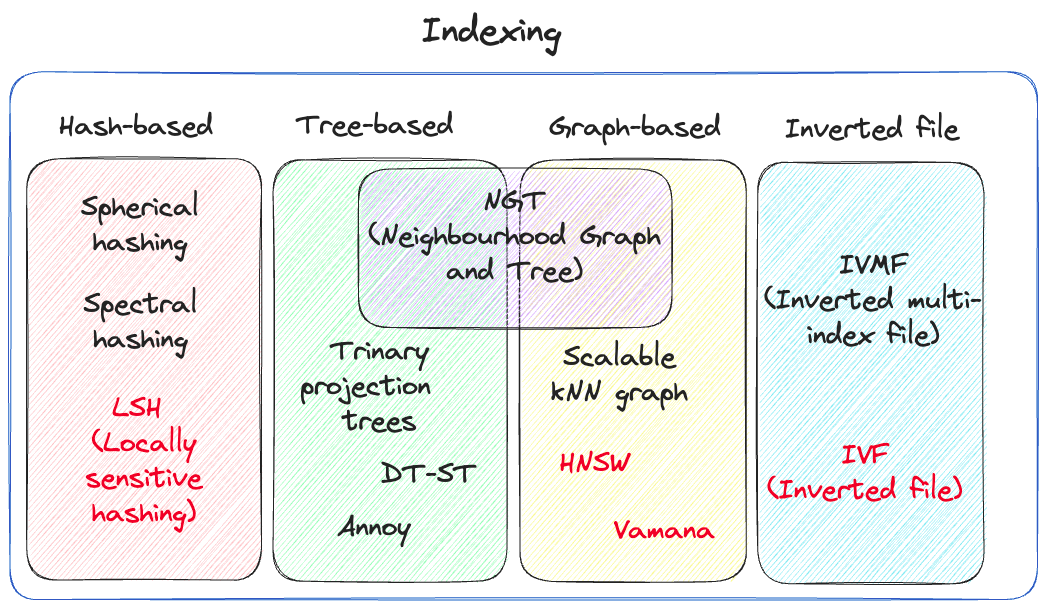
以下是最常见的:
**Flat Index:**将所有向量存储在单个列表中的简单索引。对于小型数据集,它的速度很快,但随着数据集大小的增加,由于搜索要进行详尽的搜索,它可能会变得效率低下。
**IVF(倒排文件):**一种两级索引结构,用于将向量空间划分为多个单元格,并将每个向量分配给一个或多个单元格。它使用倒排列表来存储属于每个单元格的向量,从而实现高效的近似最近邻搜索。
HNSW (Hierarchical Navigable Small World):一种基于图的索引,用于构建向量空间中数据点的分层图。它将数据点组织成不同的粒度级别,从而允许通过浏览图表来快速搜索近似最近邻。
LSH(位置敏感哈希):一系列哈希技术,可将相似的数据点以高概率映射到相同的哈希存储桶。它通过将向量空间划分为哈希桶并在同一桶中搜索相似的向量来实现近似最近邻搜索。
PQ(乘积量化):一种使用向量量化技术将高维向量压缩为紧凑代码的索引结构。它通过将向量量化为子向量并为每个子向量存储码本来减少内存使用并加速搜索操作。
Annoy (Approximate Nearest Neighbors Oh Yeah):一种基于树的索引方法,用于构建数据空间的随机投影。它构建了一个树结构,该结构可以通过遍历树并将查询向量与树节点进行比较来快速近似最近邻搜索。
Faiss vs Chroma vs Milvus
好了,现在我们已经对矢量数据库及其工作原理有所了解,让我们看看一些最流行的矢量数据库。
您可能已经注意到,Faiss 并不是一个真正的数据库,但如果您想构建自己的数据库,可以使用它。
一般比较
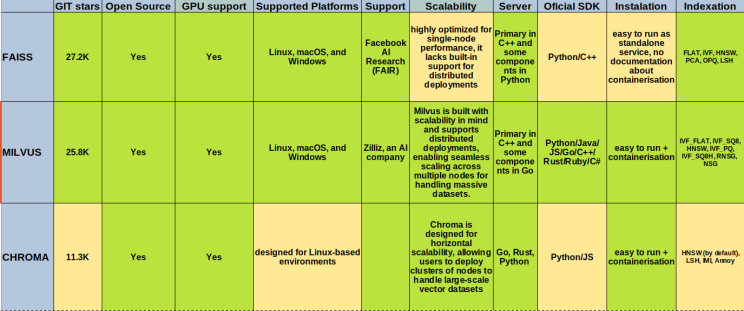
正如你在上面看到的,主要的一点是它们都是流行的开源解决方案,并且支持 GPU(这对性能非常重要)。由于 Faiss 是一个库,因此默认情况下它不可扩展,因此您需要自己扩展它。但是,让我们进行一些严肃的测试,比如性能和负载测试。
测试环境、数据和场景
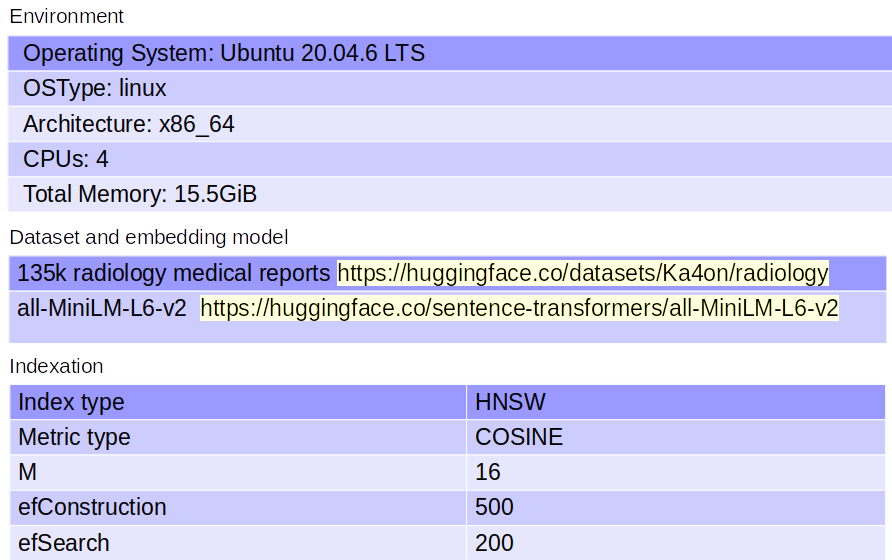
是的,我知道,那是一台旧计算机,但它可以完成工作。我应该提到没有使用 GPU。医学数据集取自此来源,我使用了此处的 ML 模型。关于索引,我对所有数据库使用了上面提到的相同指标。这些指标通常侧重于精度和性能。以下是有关每个选项的更多详细信息:
metric_type:此参数指定在计算向量之间的相似性时要使用的距离度量。在这种情况下,“COSINE” 表示将使用余弦相似度指标。余弦相似度是两个向量之间相似度的度量,用于度量它们之间夹角的余弦值。
index_type:此参数指定用于组织向量数据库中向量的索引结构的类型。在这种情况下,“HNSW”代表 Hierarchical Navigable Small World,这是一种近似最近邻搜索算法。
params:此子字典包含特定于所选索引类型的其他参数。对于 HNSW 索引,通常使用以下参数:
- M:此参数控制图形在 HNSW 指数中的程度。M 值越高,图形越密集,这可以产生更准确的搜索结果,但需要更多的内存和计算资源。
- efConstruction:该参数控制 HNSW 索引构建过程中动态列表的大小。它影响指标的质量和施工过程的效率。
- efSearch:此参数控制搜索过程中动态列表的大小。较大的 efSearch 值可能会带来更准确的搜索结果,但在搜索操作期间需要更多的计算资源。
负载测试是使用 k6 框架进行的。每个用户都使用 60 个不同的向量(取自“放射学”术语的单词,嵌入了与测试数据集相同的模型)查询 API,并要求每个请求返回 10 个最近的向量。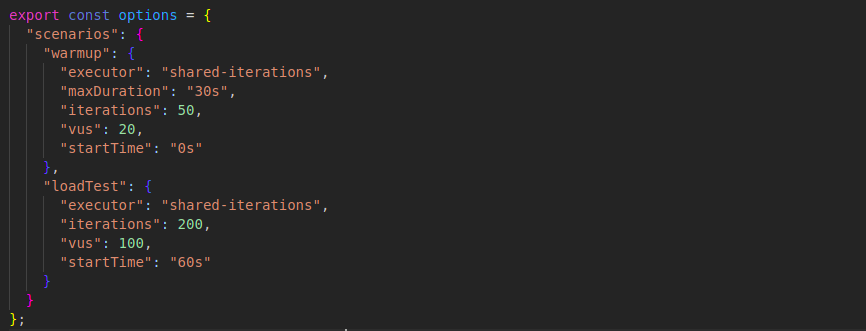
Results 结果

结论
根据结果,Faiss 似乎是查询时间性能的赢家,但扩展它可能具有挑战性。有一些现有项目使用 REST 包装 Faiss,提供监控和附加功能。
Milvus 似乎是一个不错的成熟选择。它可以扩展,有关于容器化和 Kubernetes 配置的良好文档,包括精确的 RAM 内存计算。
不幸的是,Chroma 似乎不够成熟,也缺乏足够的文档。但是,由于其嵌入式功能,例如流行的 ML 嵌入模型和内置数据摄取,它仍然可能是一个选项。
代码可在此处获得:https://github.com/pilotofbalance/vector_db_benchmarking。使用 README 文件构建和运行您自己的比较测试。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)