(小白也能轻松搞定)使用YOLOv10训练自己的数据集
有些同学在配置环境时会懒省事,直接使用之前的虚拟环境,我在这里建议大家新建一个虚拟环境,因为不同的模型所需要的虚拟环境是不同的,如果使用之前的环境,出问题的时候进行修改(比如修改某个依赖包的版本),这样可能会使当前的模型代码正常运行,但往往会导致之前的模型代码运行报错,所以建议大家还是新建一个虚拟环境。然后会提示你是否真的要删除,输入y,接着安装另一个版本的numpy (经过我的实验,发现这个版本
一、初步认识YOLOv10
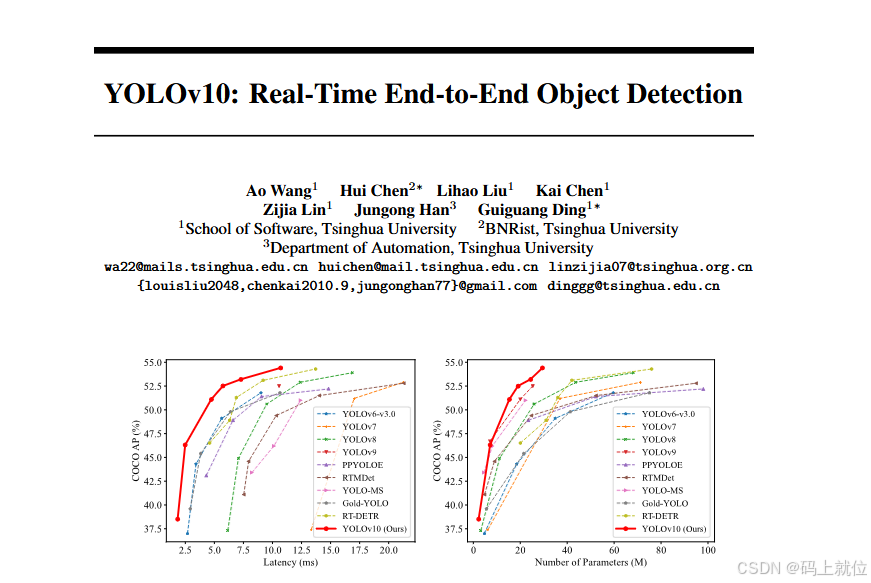
论文地址:
[2405.14458] YOLOv10: Real-Time End-to-End Object Detection
代码地址:GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection [NeurIPS 2024]
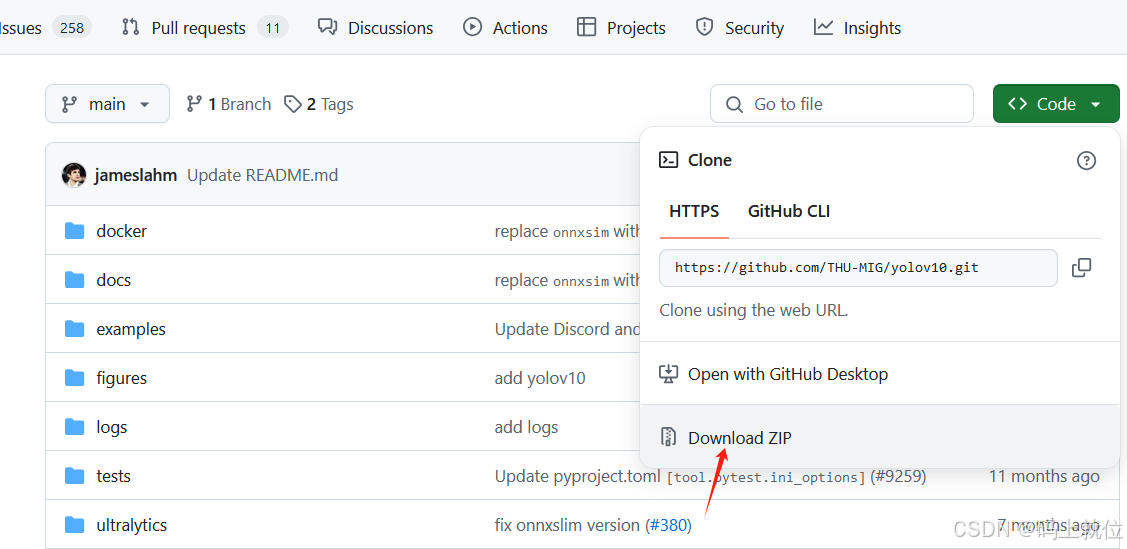
二、下载YOLOv10代码到自己的电脑
点击上面链接 点击Code 再点击 Download ZIP
三、环境配置
有些同学在配置环境时会懒省事,直接使用之前的虚拟环境,我在这里建议大家新建一个虚拟环境,因为不同的模型所需要的虚拟环境是不同的,如果使用之前的环境,出问题的时候进行修改(比如修改某个依赖包的版本),这样可能会使当前的模型代码正常运行,但往往会导致之前的模型代码运行报错,所以建议大家还是新建一个虚拟环境。
为了避免大家在实际运行时出现不必要的错位,建议大家按照我的步骤来!
3.1 新建虚拟环境
第一步:新建一个名为yolov10的虚拟环境(自己操作时可以换名字,但自己一定不要记混!)
conda create -n yolov10 python=3.9第二步:激活新建的虚拟环境
conda activate yolov10第三步:使cd命令使命conda窗口的命令行目录前缀为刚才下载YOLOv10的根目录
第四步:安装所需要的依赖包
pip install -r requirements.txt
第五步:验证是否安装成功(具体验证方案可观看这篇博客)(已解决)安装CUDA总是出错,torch和torchvision能正常使用,版本匹配问题,安装命令问题_cuda 12.4 安装 出错-CSDN博客
3.2 在PYcharm中进行虚拟环境的切换
第一步:
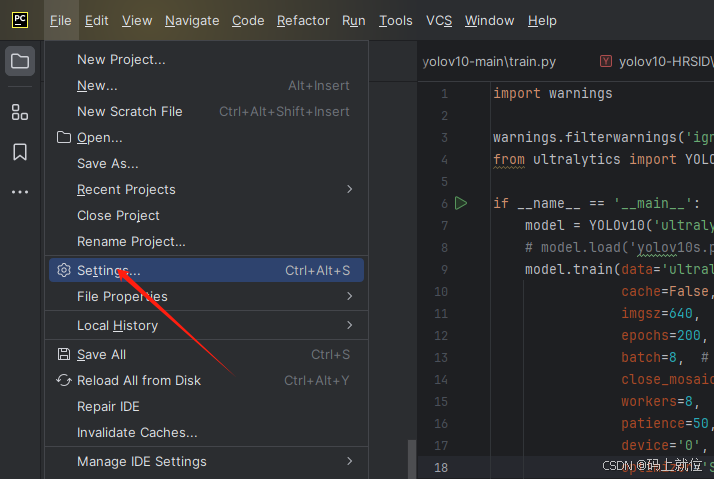
第二步:

第三步:选择YOLOv10
四、引入自己想要训练的数据集
第一步:在根目录下创建一个名为datasets的文件,文件具体目录如下,其中Annotations中存放的是xml标签文件,images中存放的是数据集对应的图片,ImageSets和labels可以先创建(里面不需要放东西,一会根据代码自动生成)
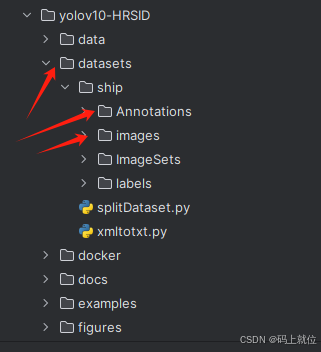
第二步:新建一个将xml文件格式转换成txt文件格式的python代码(我这里取名为xmltotxt.py)
代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
# size=(width, height) b=(xmin, xmax, ymin, ymax)
# x_center = (xmax+xmin)/2 y_center = (ymax+ymin)/2
# x = x_center / width y = y_center / height
# w = (xmax-xmin) / width h = (ymax-ymin) / height
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
# print(x, y, w, h)
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
# print(xml_files)
for xml_name in xml_files:
# print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
# print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 把forklift_pallet的voc的xml标签文件转化为yolo的txt标签文件
# 1、需要转化的类别
classes = ['ship']
# 2、voc格式的xml标签文件路径
xml_files1 = r'E:\Space-python\Space-7\yolov10-HRSID\datasets\ship\Annotations'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'E:\Space-python\Space-7\yolov10-HRSID\datasets\ship\labels'
convert_annotation(xml_files1, save_txt_files1, classes)
然后运行xmltotxt.py,注意里面的标签文件路径需要修改为自己的
第三步:划分数据集(训练集、验证集、测试集)
我在这里创建一个名为splitData.py的python文件,可以直接使用,代码如下:
import os, shutil, random
from tqdm import tqdm
"""
标注文件是yolo格式(txt文件)
训练集:验证集:测试集 (7:2:1)
"""
def split_img(img_path, label_path, split_list):
try:
Data = r'E:\Space-python\Space-7\yolov10-HRSID\datasets\ship\ImageSets'
# Data是你要将要创建的文件夹路径(路径一定是相对于你当前的这个脚本而言的)
# os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
test_img_dir = Data + '/images/test'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
test_label_dir = Data + '/labels/test'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
os.makedirs(test_img_dir)
os.makedirs(test_label_dir)
except:
print('文件目录已存在')
train, val, test = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = random.sample(all_img_path, int(val / (val + test) * len(all_img_path)))
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
all_img_path.remove(val_img[i])
test_img = all_img_path
test_label = [toLabelPath(img, label_path) for img in test_img]
for i in tqdm(range(len(test_img)), desc='test ', ncols=80, unit='img'):
_copy(test_img[i], test_img_dir)
_copy(test_label[i], test_label_dir)
def _copy(from_path, to_path):
shutil.copy(from_path, to_path)
def toLabelPath(img_path, label_path):
img = img_path.split('\\')[-1]
label = img.split('.jpg')[0] + '.txt'
return os.path.join(label_path, label)
if __name__ == '__main__':
img_path = 'E:\Space-python\Space-7\yolov10-HRSID\datasets\\ship\images' # 你的图片存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
label_path = 'E:\Space-python\Space-7\yolov10-HRSID\datasets\\ship\labels' # 你的txt文件存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
split_list = [0.7, 0.2, 0.1] # 数据集划分比例[train:val:test]
split_img(img_path, label_path, split_list)运行splitDataset.py时注意修改文件路径
五、开始训练
第一步:在根目录下创建一个名为train.py的文件
代码如下:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOv10
if __name__ == '__main__':
model = YOLOv10('ultralytics/cfg/models/v10/yolov10m.yaml') # 指定YOLO模型对象,并加载指定配置文件中的模型配置
# model.load('yolov10s.pt') #加载预训练的权重文件'yolov10s.pt',加速训练并提升模型性能
model.train(data='ultralytics/cfg/datasets/ship.yaml', # 指定训练数据集的配置文件路径,这个.yaml文件包含了数据集的路径和类别信息
cache=False, # 是否缓存数据集以加快后续训练速度,False表示不缓存
imgsz=640, # 指定训练时使用的图像尺寸,640表示将输入图像调整为640x640像素
epochs=200, # 设置训练的总轮数为200轮
batch=8, # 设置每个训练批次的大小为16,即每次更新模型时使用16张图片
close_mosaic=10, # 设置在训练结束前多少轮关闭 Mosaic 数据增强,10 表示在训练的最后 10 轮中关闭 Mosaic
workers=8, # 设置用于数据加载的线程数为8,更多线程可以加快数据加载速度
patience=50, # 在训练时,如果经过50轮性能没有提升,则停止训练(早停机制)
device='0', # 指定使用的设备,'0'表示使用第一块GPU进行训练
optimizer='SGD', # 设置优化器为SGD(随机梯度下降),用于模型参数更新
)第二步:在 ultralytics/cfg/datasets 目录下创建一个名为ship.yaml的文件(注意修改路径)
代码如下:
#path: D:/TestMain/yolov9-main/datasets/fish # dataset root dir
train: E:\Space-python\Space-7\yolov10-HRSID\datasets\ship\ImageSets\images\train # train images (relative to 'path') 118287 images
val: E:\Space-python\Space-7\yolov10-HRSID\datasets\ship\ImageSets\images\val # val images (relative to 'path') 5000 images
test: E:\Space-python\Space-7\yolov10-HRSID\datasets\ship\ImageSets\images\test # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
0: ship
#放你数据集类型对应的类别,多个就0,1,2,3往后排
# stuff names
stuff_names: [
'ship',
# other
'other',
# unlabeled
'unlabeled'
]
# Download script/URL (optional)
download: |
from utils.general import download, Path
# Download labels
#segments = True # segment or box labels
#dir = Path(yaml['path']) # dataset root dir
#url = 'https://github.com/WongKinYiu/yolov7/releases/download/v0.1/'
#urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
#download(urls, dir=dir.parent)
# Download data
#urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
# 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
# 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
#download(urls, dir=dir / 'images', threads=3)第三步:运行train.py
注意:如果你按照我上面的操作,在运行时,控制会报个错误:
RuntimeError: Dataset ultralytics/cfg/datasets/ship.yaml error No module named utils
你只需要打开刚创建的虚拟环境,更换一下numpy的版本
conda activate yolov10
pip uninstall numpy然后会提示你是否真的要删除,输入y,接着安装另一个版本的numpy (经过我的实验,发现这个版本能正常运行)
pip install numpy==1.26.4到这里你就完成了对自己数据集在YOLOv10上的训练!
训练结束后会自动生成一些指标。
整理不易,如果帮到你一点,麻烦动动手给个小红心!!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)