如何训练自己的数据集之——睡岗数据集。
睡岗数据集。数据集已标注好,txt格式,yolo格式,上班睡觉数据集 yolo系列目标模型。数据集已经划分好训练集420张,验证集105张,岗位睡觉数据集,睡觉数据集分两类:实测map50为80.6%
 睡岗数据集。数据集中有相当一部分图片是监控摄像头下的真实画面。数据集已经标注好,txt格式,yolo格式,适用于训练yolo系列目标检测模型。数据集已经划分好训练集420张,验证集105张,包含类别标签文件,数据集分为两类:sleep、unsleep。数据集亲测可用,yolov8m实测map50为80.6%
睡岗数据集。数据集中有相当一部分图片是监控摄像头下的真实画面。数据集已经标注好,txt格式,yolo格式,适用于训练yolo系列目标检测模型。数据集已经划分好训练集420张,验证集105张,包含类别标签文件,数据集分为两类:sleep、unsleep。数据集亲测可用,yolov8m实测map50为80.6%

睡岗数据集介绍
数据集概述
睡岗数据集(Sleep Posture Dataset)主要用于监控摄像头下的人体姿态检测,特别是用于检测工作人员是否处于睡眠状态。该数据集已经过标注,采用YOLO格式的.txt标签文件,适用于训练YOLO系列的目标检测模型。数据集已经按比例划分成训练集和验证集,并包含两类标签:sleep(表示处于睡眠状态)和unsleep(表示未处于睡眠状态)。根据实际测试,使用YOLOv8m模型在该数据集上的mAP50达到了80.6%。
数据集特点
- 真实场景:数据集中包含大量监控摄像头下的真实画面,反映了实际工作环境中的情况。
- 清晰标注:所有图像均已经过人工标注,并转换为YOLO格式的标签文件,方便模型训练。
- 合理划分:数据集已经按照一定比例划分为训练集和验证集,便于模型训练和性能评估。
- 高准确度:使用YOLOv8m模型训练后的模型在验证集上的mAP50达到了80.6%,表明模型具有较好的检测能力。
数据集内容
- 图像文件:包含525张JPG/PNG格式的图像文件,其中训练集包含420张图像,验证集包含105张图像。
- 标签文件:每张图像对应一个
.txt格式的标签文件,包含物体的位置信息和类别标签。 - 类别标签文件:包含两个类别标签:
sleep和unsleep。
数据集结构示例
假设数据集的根目录为 sleep_posture_dataset,其结构可能如下所示:
sleep_posture_dataset/
├── images/
│ ├── train/
│ │ ├── train_0001.jpg
│ │ ├── train_0002.jpg
│ │ └── ...
│ ├── val/
│ │ ├── val_0001.jpg
│ │ ├── val_0002.jpg
│ │ └── ...
├── labels/
│ ├── train/
│ │ ├── train_0001.txt
│ │ ├── train_0002.txt
│ │ └── ...
│ ├── val/
│ │ ├── val_0001.txt
│ │ ├── val_0002.txt
│ │ └── ...
└── data.yaml # 数据集配置文件数据集配置文件 data.yaml
创建一个 data.yaml 文件来描述您的数据集。这里假设数据集被放置在一个名为 sleep_posture_dataset 的目录中,且包含 images 和 labels 子目录。
# data.yaml 文件
train: ../sleep_posture_dataset/images/train/
val: ../sleep_posture_dataset/images/val/
nc: 2 # number of classes
names: ['sleep', 'unsleep'] # class names关键训练代码
安装YOLOv8
如果您还没有安装YOLOv8框架,请按照官方文档执行以下命令:
git clone https://github.com/ultralytics/ultralytics.git # 克隆YOLOv8仓库
cd ultralytics
pip install -r requirements.txt # 安装依赖项使用YOLOv8训练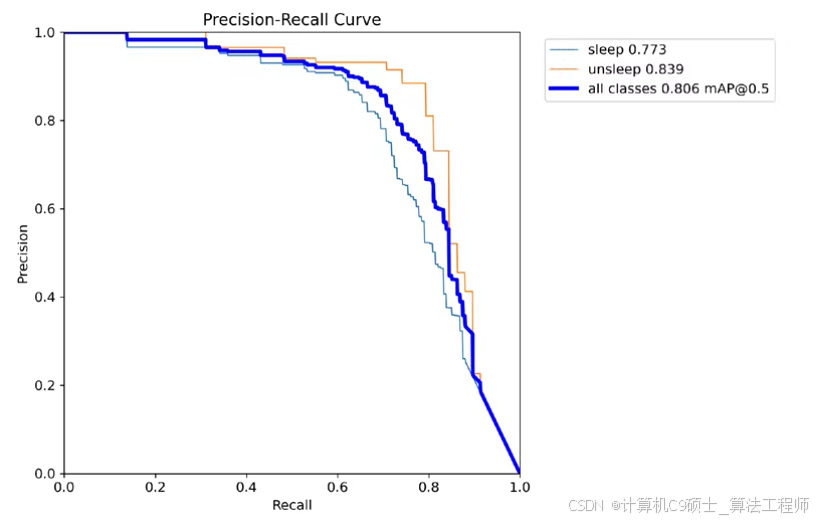
使用以下命令开始训练模型:
cd ultralytics
python train.py --img 640 --batch 16 --epochs 100 --data ../sleep_posture_dataset/data.yaml --weights yolov8m.pt --cache自定义训练脚本
如果需要更详细的控制,可以编写一个Python脚本来执行训练过程。以下是一个简单的脚本示例:
import torch
from ultralytics import YOLO # 使用YOLOv8的API
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
data_yaml = '../sleep_posture_dataset/data.yaml'
# 加载预训练模型
model = YOLO('yolov8m.pt').to(device) # 使用YOLOv8m作为基础模型
# 设置训练参数
epochs = 100
batch_size = 16
img_size = 640
# 开始训练
model.train(data=data_yaml, epochs=epochs, batch=batch_size, imgsz=img_size, device=device)
# 保存模型
model.save('trained_model.pt')
print('Training complete.')
if __name__ == '__main__':
main()注意事项
- 确保
data.yaml文件中的路径是正确的,并且数据集的结构与上面描述的一致。 - 调整批量大小、学习率、迭代次数等超参数以适应您的计算资源和任务需求。
- 如果数据集很大,您可能需要更多的计算资源和时间来完成训练。
- 这个脚本仅作为一个起点,您可能需要根据实际情况做进一步的修改。
测试模型
在训练完成后,您可以使用以下命令测试模型的性能:
python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.4 --source ../sleep_posture_dataset/images/val/使用预训练模型进行测试
如果您已经有了训练好的模型权重文件,可以直接使用它来进行测试。假设权重文件名为 best.pt,可以使用以下命令:
python detect.py --weights best.pt --img 640 --conf 0.4 --source ../sleep_posture_dataset/images/val/总结
这个示例展示了如何使用YOLOv8框架训练一个基于睡岗检测的数据集。您可以根据自己的需求调整脚本中的参数和逻辑。通过使用这个数据集和相应的训练代码,您可以有效地训练出一个能够在多种条件下检测工作人员是否处于睡眠状态的模型。在实际应用中,可以根据具体需求调整模型结构和训练参数。此外,提供的训练代码可以让您快速启动训练流程,并获得良好的检测效果。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)