C++软件开发常见面试题【涵盖C++基础、操作系统、网络、数据结构,计算机组成原理等总字数约7w字】
由本人整理的非常详细的C++开发面经
目录
11、指针*和引用&的区别,用sizeof时有什么不同,为什么需要引用?
85、构造函数初始化列表和直接在构造函数内初始化有什么区别?
135、析构函数是虚函数:cpp但凡涉及继承析构函数必是虚的
1、C++里指针和数组的区别
先来看一个经典问题
char s1[]="hello";
char *s2 ="hello";1、s1的值是放在栈上的,值是可以修改的,而hello是一个字符串常量放在静态存储区是不能修改的。
2、内存大小不一样
#include<stdio.h>
int main(){
char s1[]="hello";
char *s2="hello";
puts(s1);
puts(s2);
printf(""%ld %ld\n",sizeof(s1),sizeof(s2));
return 0;
}
3、无法返回局部变量的地址,栈上的值随着函数调用结束,内存已经回收了

上面这种编译器会报警,下面则不会

数组:一块连续的内存空间,其大小在编译时确定
指针:一个变量,存储地址值、大小固定
2、C++中空指针请使用nullptr不要使用NULL
C++中NULL定义就是整数字面量0
对于C++函数,由于存在重载,使用NULL而不是nullptr可能导致函数走错重载。
C中定义NULL为(void* )0,确实是代表空指针。使用时隐式转换成对应的需要类型的空指针。
C++中void指针不能隐式转换成其他指针,所以无法按照C那样定义。
C++中保留NULL可以兼容一些C style的代码,对于这些库,不会使用到函数重载,不会产生对应的问题。但对于纯C++程序,请使用nullptr表示空指针。
3、http/https区别和头部结构?
HTTP:超文本传输协议,被用于在web浏览器和网站服务器之间传递消息,以明文的方式发送内容,不提供任何方式的数据加密,传输端口为80,特点是简单快捷,灵活,无状态,每次请求都是独立的,上一次请求和下一次请求互不相干。比如登录某个网站后,本来不需要再登陆,不知道上次请求已经登陆过了
HTTPS:HTTP+SSL/TLS 基于TLS/SSL协议加密进行,引入了会话保持,session和cookie,状态记录-登录验证,TCP传输,拿到的是密文,传输端口为443,SSL/TLS协议依靠证书来验证服务器的身份。
4、有了mac地址为什么还要ip地址?ip地址的作用
IP(包裹地址):一个为互联网的每一个网络和每一台主机分配的逻辑地址
Mac(收件人信息):媒体访问控制地址,局域网地址,以太网地址,物理地址,是一个用来确认网上设备位置的地址
Mac地址用于标示一个网卡,一台设备若有一个或多个网卡,则每个网卡都需要并会有一个唯一的Mac地址,表明身份
只有Mac地址可以传输数据,只要同处于一个局域网内
ISP:互联网服务提供商。
5、有了路由器为什么还要交换机?
路由器:与外部通讯
交换机:提供内网通讯
不是每个网络需要路由器,比如企业,学习,医院等,内部通信需要大量的接入设备,只需要交换机,一台交换机可以接入几十台设备,而仅需一个路由器提供对外访问,更大型的网络里,需要对内部网进行划分若干小内网,实现内部小网之间互相访问,可采用带路由功能的交换机,即三层交换机
路由器侧重点是共享,交换机功能不强,侧重点是多口,构成局域网
如果有50台computer,不得不用交换机,小路由器便宜,但代理能力更弱,只能代理几台,若加很多口,又没有能力代理,没用,但口多代理强的路由器很贵如只要交换机,加了路由,价也贵了,功能也多余的.
6、面向对象三大特性
(1)封装性:将客观事物抽象成类,每个类对自身的数据和方法实行protection
(2)继承性:广义的继承有三种实现形式:实现继承(使用基类的属性和方法而无需额外编码的能力)、可视继承(子窗体使用父窗体的外观和实现代码)、接口继承(仅使用属性和方法,实现滞后到子类实现)。
(3)多态性:是将父类对象设置成为和一个或更多它的子对象相等的技术。用子类对象给父类对象赋值之后,父类对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。
封装是实现面向对象程序设计的第一步,将数据或函数等集合在一个个的单元(类)中。封装的意义就是保护或防止数据被无意破坏。
继承主要用来实现重用代码,节省开发时间,子类可以继承父类。
多态是指同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。在运行时,可以通过指向基类的指针来调用实现派生类中的方法。
继承是面向对象编程中实现代码复用的重要手段。通过继承,子类可以继承父类的属性和方法,并可以添加或覆盖父类的方法。这使得子类能够共享父类的代码,并扩展或修改其功能。
|
public继承 |
protected继承 |
private继承 |
|
|
基类的public |
派生出public |
派生出protected |
派生出private |
|
基类的protected |
派生出protected |
派生出protected |
派生出private |
|
基类的private |
在派生类不可见 |
在派生类不可见 |
在派生类不可见 |
private基类无论以什么方式继承到派生类中都是不可见的
使用class时默认是private,使用struct默认是public
封装是面向对象编程的核心概念之一,它通过将数据和操作数据的方法绑定到一个对象中,隐藏对象的内部状态和实现细节,只对外提供公共接口。这样可以提高代码的安全性和可维护性。
封装:将类的实现细节隐藏,暴露一个简洁。清晰的接口,提高代码的可重用性、实用性、耦合度、可维护性
访问控制权限:
一个类的public变量、函数可以通过类的实例变量访问,
protected无法通过变量访问,但可以通过类的友元函数、友元类访问
private同protected
多态:多种形态去完成某个行为,当不同对象去完成时会产生不同的状态
买票:学生半价、普通人全价
实现:重写/覆盖:子类有一个跟父类完全相同的虚函数,子类的虚函数重写了基类的虚函数
子类父类都要这个虚函数
多态是面向对象编程中实现接口统一和灵活性的关键特性。通过多态,不同的对象可以对同一消息作出不同的响应。这使程序在运行时能够根据对象的实际类型来执行相应的操作,提高了代码的灵活性和可扩展性。分为静态和动态两种
静态(编译时):重载、泛型编程、重载运算符、模板,编译时自动绑定好
动态(运行时):虚函数、virtual、回调函数
虚函数有一个虚函数表,虚函数表指针一般有四个字节,虚表指针在内存哪个分区取决于在堆上创建还是栈上
虚函数和纯虚函数,通过使用指向基类对象的指针或引用调用虚函数
多态分为两种,一种是编译时多态,比如函数重载和模板,编译器在编译代码时会根据不同的代码匹配相应的函数。另一种是运行时多态,主要通过虚函数实现。在定义类时,定义一个虚函数,当在子类中使用时,只需要重写这个虚函数。
重写虚函数:一般先写函数的返回值、函数名和形参,然后在形参后面加上override关键字。如果是纯虚函数,必须重写才能使用。如果不是纯虚函数,override关键字可以不加。
C++在运行时,虚函数通过虚表(vtable)实现。当一个对象调用虚函数时,程序会通过该对象的虚表指针找到相应的函数地址并进行调用。
虚函数重写使用override关键字重写虚函数。纯虚函数必须重写,非纯虚函数可以不加override。
封装(Encapsulation):
封装是将数据和操作封装在一个单元(类)中的机制。对外部隐藏具体实现细节
通过封装,实现类的成员变量和成员函数作为一个整体进行管理和操作。
封装隐藏了数据的具体实现细节,提高安全性,提高可维护性。
访问修饰符如 private、public、protected 等限制对类成员的访问。
继承(Inheritance):
继承是通过创建派生类来扩展和重用已有类的机制。
继承是指一个类(子类)从另一个类(父类)继承属性和方法的过程。子类可以自定义新的属性和方法,也可以覆盖或扩展继承的父类的属性和方法。子类继承了父类的属性和方法,可以直接使用父类的成员,也可以对继承的父类方法进行重写。
继承的优势包括代码复用,创建类的层次结构使代码更有组织和易于理解,同时也是实现多态的基础。
多态(Polymorphism):
多态是指同一类型的对象,在不同情况下表现出不同的行为。
多态允许使用基类的指针或引用来引用派生类的对象,实现了多种形态的使用。
编译时多态使用函数重载和运算符重载;运行时多态通过虚函数实现(动态绑定)。
多态的优势包括灵活性和可扩展性,代码重用,提供统一接口使代码更加通用和可维护。
实现多态的三个必要条件为继承、重写、父类引用指向子类对象。
7、友元函数
友元函数是 一个特性,它允许一个或多个非成员函数访问一个类的私有和保护成员。友元函数不是类的成员函数,但它可以访问类的所有成员,包括私有成员。这种机制提供了一种突破数据封装和隐藏的方式,使得非成员函数能够直接操作类的内部数据。然而,使用友元函数需要谨慎,因为它可能会破坏封装性并增加代码的复杂性。
8、大端小端
大端小端是计算机存储数据的一种字节序方式。
大端模式(Big-Endian)是指高位字节存储在内存的低地址处,而低位字节存储在内存的高地址处;
小端模式(Little-Endian)则相反,低位字节存储在内存的低地址处,高位字节存储在内存的高地址处。这两种模式在跨平台编程和网络通信中需要特别注意。
如果数据类型占用的内存空间大于1字节,CPU把数据存放在内存中的方式有两种:
(1)大端序(Big Endian):低位字节存放在高位,高位字节存放在低位。
(2)小端序(Little Endia):低位字节存放在低位,高位字节存放在高位
大端:低地址存放数据的高位,高地址存放数据的低位. 即CPU对操作数的存放顺序为高字节到低字节。如存放数据0x123456:
数据: 0x56 | 0x34 | 0x12
地址: 0x01 | 0x02 | 0x03
小端:低地址存放数据的低位,高地址存放数据的高位. 即CPU对操作数的存放顺序为低字节到高字节。如存放数据0x123456:
数据: 0x12 | 0x34 | 0x56
地址: 0x01 | 0x02 | 0x03
判断大小端
1.联合体判断:因为联合体的大小为联合体中所有数据当中类型最大那个类型的大小,则通过char和int可以判断.
#include<iostream>
using namespace std;
union A{
char a;
int b;
/*
char 占一个字节,int占四个字节
所以联合体的大小为四个字节,且a b公用一块内存
当对b赋值为1时,则b=0x00 00 00 01;
当为大端模式时:读取a得到的值为0;
当为小端模式时:读取a得到的值为1;
*/
};
int main(){
A U;
U.b=1;
if(U.a){
cout<<"小端模式"<<endl;
}
else{
cout<<"大端模式"<<endl;
}
return 0;
}通过对四字节的 int* 强转为一字节的 char*
#include<iostream>
using namespace std;
int main()
{
int i = 1;
//&i为i的地址,此时为int*类型
//(char*)将int*强转为char*
//*取该char*的内容
if (*(char*)&i) {
cout<<"小端模式"<<endl;
}
else{
cout<<"大端模式"<<endl;
}
return 0;
}9、野指针
野指针是指指向已经被释放的内存空间的指针,或者是一个未被初始化的指针。使用野指针可能会导致程序崩溃或数据损坏。为了避免野指针问题,需要在使用指针前进行初始化,并在释放内存后将指针置为nullptr。
11、指针*和引用&的区别,用sizeof时有什么不同,为什么需要引用?
指针:内存地址,指针变量是用来存放内存地址的变量
引用:给已存在的变量取一个别名,编译器不会给引用变量开辟内存空间,共用一块内存空间,主要作用是修饰函数的形参和返回值
在C++中,函数和返回值的传递方式有三种:值传递、指针传递、引用传递,引用具有指针的效率,有=又具有变量使用的方便性
区别:
引用给予程序元素完成其功能的最小权限,指针能无约束地操作内存中的任何东西,非常危险
引用定义必须初始化,指针没有,但尽量初始化,防止野指针
引用在初始化后不能再引用其他实体,指针可以
没有null引用,但是有nullptr指针
在sizeof中含义不同,引用结果为引用类型大小,但指针是地址空间所占字节个数(32位平台占4个字节)
有多级指针,但没有多级引用
12、静态变量什么时候初始化
初始化只有一次,但可以多次复制,在主程序之前编译器已经为其分配好了内存
静态变量和全局变量一样,都存放在全局区域(数据区)
如果是c:int a=1;int b=a; 是错误的,在编译时才初始化
C++:int a=1;static int b=a;
由于C++引入对象后要进行初始化必须执行相应的构造函数和析构函数,经常会进行特定操作,所以C++为全局或静态对象时有首次用到时才会进行构造,C++中内置类型比如int、double、char都升级成了类,在对象第一次使用时初始化.
13、new和malloc区别
new、delete是关键字,需要编译器支持,
malloc、free是库函数,需要引入相应头文件
malloc:申请空间时要填入申请内存大小,int *m=(int*)malloc(4);堆空间
new:根据类型分配内存 int *a=new int(0); 自由存储区
c++内存分为:堆、栈、自由存储区、全局/静态存储区、常量存储区
堆是操作系统维护的一块特殊内存,提供了动态分配功能,当运行程序调用malloc时会从中分配,调用free归还内存
自由存储区是c++中动态分配和释放对象的概念
通过new分配的内存区域可以称为自由存储区,自由存储区可以是堆、全局/静态存储区等
new返回对象类型的指针,类型与对象匹配
malloc内存分配成功返回void *,需要通过强制类型转换将void*转换成所需,分配失败返回null
new失败会抛出异常,
malloc可以通过realloc扩张,new没有
(1)new是C++中的操作符,malloc是C中的一个函数。
(2)new不止分配内存,而且会调用类的构造函数,同理delete调用类的析构函数,而malloc只分配内存,不会进行初始化类成员的工作,同样free也不会调用析构函数。
(3)内存泄露对于malloc或者new都可以检查出来,区别在于new可以指明是文件的哪一行,而malloc没有这些信息。
(4)new可以认为是malloc加构造函数的执行,new出来的指针是直接带类型信息的,而malloc返回的值都是void指针
14、内存泄漏、如果出现怎么排查和定位?
分配的内存没有被正确释放,导致内存被占用过多,主要与动态内存分配有关,
int *p=new int;
delete p;
对同一个指针重新分配内存:
int *p=new int;
p=new int;
导致程序运行效率下降、程序出现安全漏洞、内存资源枯竭
15、const以及函数后加const?
const int a 常整型数
int const a 常整型数
const int *a 指向常整型数的指针,即a的值可以变,*a不可变
int* const a 常指针,a的值不能变,*a可变
int const *a const 指向常整型数的常指针
const修饰函数参数:只能修饰输入作用的参数,如果输入参数为指针,加上const起到保护指针意外修改的作用,
const int fun();没有必要,只是个临时值,最终这个值会复制给接受它的变量
const修饰成员函数:为了保护成员变量,要求const函数不能修改成员变量,否则编译报错
const对象只能访问const成员函数,非const对象可以访问任何成员函数,包括const成员函数
const成员函数可以分为所有成员变量,但只能访问const的成员函数
const成员函数不能修改任何成员变量,除非变量用mutable修饰
在const成员函数中成员变量都变成const属性,无法再次修改
16、堆和栈的区别
堆:由程序员分配释放,若不释放,程序结束时可能由OS回收,堆的内部地址生长方向与栈相反,由低到高
栈:由操作系统自动分配释放,存放函数的参数值,局部变量,栈的内部地址是由高到低分配的,因此后定义的变量在栈中的地址低于先定义的变量
空间大小:栈的值是固定的,由编译器不同而不同,一般为2M,较小堆理论上可以分配虚拟内存大小的空间,堆区的内存空间是由链表组织的,是不连续的
17、基类和派生类中构造函数和析构函数的顺序
构造:先基类,再派生类
析构:先派生类,再基类
多个基类的调用跟基类继承的顺序有关
18、strcpy和memcpy的区别,谁的性能好?
strcpy和memcpy都是C语言中常用的字符串复制函数。
复制内容:
strcpy:只能复制以'\0'结尾的字符串。
memcpy:可以复制任意内容,包括字符数组、整型、结构体、类等,只要指定了正确的长度。
复制方法:
strcpy:不需要指定长度,遇到字符串结束符'\0'时停止复制。如果目标空间不够大,可能会导致缓冲区溢出。
memcpy:根据其第三个参数(即要复制的字节数)来决定复制的长度,不会自动停止。因此,需要确保目标空间足够大以容纳要复制的数据。
参数类型:
strcpy:参数是字符指针(char*)。
memcpy:参数是void指针(void*),提供了更大的灵活性,可以复制任何类型的数据。
安全性:
strcpy:由于不检查目标空间是否足够大,可能会导致缓冲区溢出,存在安全隐患。
memcpy:在正确使用时(即确保目标空间足够大),相对更安全。但如果不小心指定了错误的长度,也可能导致内存问题。
性能表现
对于较短的字符串,strcpy可能需要额外的处理来查找字符串结束符'\0',这可能会使其比memcpy稍微慢一些。然而,这种差异通常非常小,并且在大多数情况下可以忽略不计。
对于较长的字符串或需要复制非字符串数据时,memcpy的性能可能会更好,因为它不需要处理字符串结束符,并且可以直接根据指定的长度进行复制。
如果需要复制以'\0'结尾的字符串,并且目标空间足够大以容纳整个字符串(包括结束符),则可以使用strcpy。但需要注意避免缓冲区溢出的问题。
如果需要复制任意类型的数据或指定长度的字符数组,并且希望避免字符串结束符的处理,则可以使用memcpy。但需要确保目标空间足够大以容纳要复制的数据。
19、malloc和new的区别
malloc函数用于在堆上分配指定字节数的内存,并返回一个指向该内存的指针(类型为void*,通常需要强制类型转换)。
初始化:malloc分配的内存是未初始化的,即内存中的值是未定义的。
释放:使用malloc分配的内存必须使用free函数来释放,否则会导致内存泄漏。
灵活性:malloc只负责分配内存,不涉及对象的构造。因此,对于类类型的对象,仅使用malloc是不足够的,还需要手动调用构造函数。
new运算符是C++中特有的。它用于在堆上分配内存并构造对象。new运算符返回一个指向新创建对象的指针。
初始化:使用new分配并构造的对象会被自动初始化。对于内置类型,将调用默认构造函数(如果适用)或进行零初始化;对于类类型,将调用其构造函数。
释放:使用new分配并构造的对象必须使用delete运算符来释放和销毁。delete运算符会首先调用对象的析构函数,然后释放内存。
便利性:new运算符结合了内存分配和对象构造两个步骤,使代码更加简洁和易于管理。
malloc和new都用于在堆上动态分配内存,但new还负责对象的构造。
malloc返回的是void*类型的指针,需要手动进行类型转换;而new返回的是具体类型的指针。
使用malloc分配的内存必须使用free释放;而使用new分配并构造的对象必须使用delete释放和销毁。
new运算符在分配内存时会进行初始化(对于类类型会调用构造函数),而malloc不会。
在C++中,推荐使用new和delete进行动态内存管理,因为它们更符合C++的面向对象特性。然而,在处理某些与C语言接口的代码或需要精确控制内存布局的场景中,malloc和free仍然是有用的。
20、静态多态和动态多态
静态多态,又称编译期多态,是指在编译时就能确定对象的类型和方法调用的多态性。
实现方式:
函数重载和运算符重载。在C++中,函数重载是指在同一个作用域内,可以声明多个具有相同名字但参数列表不同的函数。运算符重载则是对已有的运算符进行重新定义,使其能够用于用户自定义的类型。特点:
效率较高:由于静态多态在编译时确定,编译器可以进行优化,提高程序运行效率。
适配性和松耦合性:通过模板和特化等技术,静态多态可以处理不同类型的数据,实现代码的复用和扩展。
泛型设计:静态多态为C++带来了泛型设计的概念
动态多态是指在运行时才能确定对象的类型和方法调用的多态性。
实现方式:
继承和虚函数来实现。一个基类中的成员函数可以被声明为虚函数,这意味着该函数在派生类中可以被重写(Override)。当使用基类指针或引用来调用虚函数时,程序会在运行时根据实际对象的类型来确定调用哪个函数。特点:
灵活性高:动态多态允许程序在运行时根据对象的实际类型来选择合适的方法,提高了程序的灵活性和可扩展性。
接口与实现分离:通过虚函数和继承,动态多态实现了接口与实现的分离,使得代码更加清晰和易于维护。
处理异质对象集合:动态多态可以处理同一继承体系下的异质对象集合,实现多态性。
示例:
在C++中,可以通过继承和虚函数实现动态多态。例如,一个基类中包含一个虚函数,派生类重写该虚函数。当使用基类指针指向派生类对象并调用虚函数时,程序会调用派生类中的重写函数。
比较
本质区别:
静态多态在编译时确定对象的类型和方法调用,由模板具现完成。
动态多态在运行时确定对象的类型和方法调用,由继承和虚函数实现。
接口形式:
静态多态的接口是隐式的,以有效表达式为中心,多态通过模板具现在编译期完成。
动态多态的接口是显式的,以函数签名为中心,多态通过虚函数在运行期实现。
优缺点:
静态多态的优点包括效率高、适配性强、支持泛型设计等;缺点包括调试困难、编译耗时、代码膨胀等。
动态多态的优点包括灵活性高、接口与实现分离、处理异质对象集合等;缺点包括运行期绑定导致一定的运行时开销、编译器无法对虚函数进行优化等。
22、文件编译过程
文件编译的过程是将源代码转换为可执行文件的过程,这个过程通常包括预处理、编译、汇编和链接四个阶段。
预处理(Preprocessing)
主要任务是对源代码进行初步的处理,为后续的编译阶段做准备。
处理头文件:通过#include指令,将所需的头文件内容插入到源文件中,形成一个整体的源代码文件。头文件通常包含函数声明、宏定义、类型定义等。
宏替换:将所有定义的宏进行替换,例如将所有出现的宏名替换为对应的宏定义内容。宏定义通常使用#define指令进行。
条件编译:根据预处理指令(如#ifdef、#ifndef、#if、#elif等)的条件判断,选择性地编译代码段。
删除注释:删除所有的注释内容,包括单行注释(//)和多行注释(/* */)。
预处理后的结果通常是一个中间文件,这个文件包含了经过宏替换、条件编译等处理后的源代码。
编译(Compilation)
编译是编译过程中的核心阶段,主要任务是将预处理后的源代码转换为汇编语言。
词法分析:将源代码划分为一个个的标记(token),如关键字、标识符、运算符等。
语法分析:根据语法规则,将标记组合成语法树,并检查代码是否符合语法规范。
语义分析:对语法树进行语义检查,包括类型检查、变量声明检查等。如果源代码有语法或语义错误,编译器会报错并停止编译过程。
编译后的结果通常是汇编代码,这些代码包含了程序的基本逻辑和运算指令。
汇编(Assembly)
汇编是将编译生成的汇编代码转换为机器指令的过程。
符号解析:将变量和函数引用与其定义进行关联,生成符号表。
生成机器码:将汇编指令翻译成机器指令,并生成目标文件(通常是.o或.obj文件)。目标文件包含了程序的可执行代码以及相关的调试信息。
链接(Linking)
链接是将多个目标文件和所需的库文件链接在一起,生成最终的可执行文件的过程。
符号解析:将各个目标文件中的符号引用与其定义进行关联,解决符号引用问题。
重定位:将目标文件中的地址引用转换为实际的内存地址。
合并代码和数据:将各个目标文件中的代码和数据合并到一起,生成最终的可执行文件。
链接过程中还会处理程序的静态库和动态库依赖关系,确保程序在运行时所需的库文件已经被正确地加载。
通过预处理、编译、汇编和链接这四个阶段,源代码最终被转换为可执行文件,并在计算机上运行。在实际的软件开发中,这些阶段通常由编译器和链接器自动完成。了解文件编译的过程有助于程序员更好地理解程序的底层机制和运行原理,从而更好地优化代码和提高编译效率。
23、虚拟内存
虚拟内存是计算机系统内存管理的一种技术,它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上这部分内存是被分隔成多个物理内存碎片的,有时部分数据还会暂时存储在外部磁盘存储器上,在需要时进行数据交换。
定义
虚拟内存是操作系统用来扩展可用内存容量的一种技术。它通过将部分数据暂时存储在硬盘上,使得超出物理内存限制的数据也能被有效使用。每个程序都使用虚拟地址空间来访问内存,而非直接访问物理内存。虚拟内存管理器负责将虚拟地址转换为物理地址。
原理
虚拟内存的核心在于分页(Paging)技术。操作系统将内存划分为固定大小的块,称为页面(Page),每一页通常为4KB。在实际运行时,操作系统会将所需的页面从虚拟内存调入物理内存。当某个页面不再需要时,它会被换出(Swapped Out)到虚拟内存。以下是虚拟内存工作原理的详细步骤:
地址映射:每个进程都有自己的页面表,用于记录虚拟地址和物理地址的映射关系。当进程访问内存时,CPU会使用页面表来转换虚拟地址为物理地址。
页面调度:当程序需要访问一个页面时,虚拟内存管理器会检查该页面是否已经在物理内存中。如果已经在物理内存中,则直接访问;如果不在,则发生页面错误(Page Fault)。
页面错误:当进程访问的页面不在物理内存中时,会发生页面错误。操作系统会暂停进程,将所需的页面从虚拟内存调入物理内存(通常是从硬盘上的页面文件中读取),然后恢复进程的执行。
页面置换:当物理内存已满时,操作系统会选择不常用的页面进行置换,将其换出到虚拟内存(即硬盘上的页面文件中),从而腾出空间给新的页面。页面置换算法有多种,如最近最少使用(LRU)等。
优缺点
优点
扩展内存空间:虚拟内存使得计算机能够运行比物理内存更大的应用程序,有效扩展了系统的内存容量。
提高多任务处理能力:通过虚拟内存,操作系统可以在有限的物理内存上运行多个程序,提高了系统的多任务处理能力。
提高内存利用率:虚拟内存允许程序使用比物理内存更多的内存,而不会因此而崩溃。同时,通过页面置换算法,可以更有效地利用物理内存空间。
简化内存管理:虚拟内存为程序员提供了一个更大的、连续的地址空间,简化了内存管理的工作。
缺点
占用一定的物理硬盘空间:虚拟内存需要在硬盘上存储页面文件,因此会占用一定的物理硬盘空间。
加大了对硬盘的读写:由于页面置换和页面调度等操作,虚拟内存会加大对硬盘的读写频率,可能会影响硬盘的寿命和性能。
设置不当会影响整机稳定性与速度:如果虚拟内存设置不当(如页面文件大小设置不合理、虚拟内存与系统设在同一分区内等),可能会影响整机的稳定性和速度。
应用场景
大型数据处理:在处理大数据集或运行大型应用程序时,虚拟内存可以提供更大的内存空间,避免内存不足的问题。
多任务操作:虚拟内存允许同时运行多个应用程序,提高了多任务处理能力,适用于需要同时运行多个程序的场景。
内存保护:通过虚拟内存提供的内存保护机制,可以防止不同进程之间的内存互相干扰,从而提高系统稳定性和安全性。
配置与优化
根据内存大小和电脑用途设定:虚拟内存的设定主要根据电脑的内存大小和用途来设定。一般来说,可以让操作系统自动分配管理虚拟内存,它能根据实际内存的使用情况动态调整虚拟内存的大小。
避免与系统设在同一分区内:为了避免系统在此分区内进行频繁的读写操作而影响系统速度,最好将虚拟内存设置在其它分区中磁盘剩余空间较大而又不常用的盘中(如D、E盘)。
合理配置虚拟内存大小:一般默认的虚拟内存大小是取一个范围值,但最好给它一个固定值以减少磁盘碎片的产生(但需要注意的是固态硬盘不会产生磁盘碎片)。具体数值可以根据物理内存大小来定。
选择速度较快的硬盘或SSD:为了提高虚拟内存的性能,可以选择速度较快的硬盘或固态硬盘(SSD)来存储页面文件。
综上所述,虚拟内存是计算机系统内存管理的一种重要技术,它通过分页技术和页面置换算法实现了内存扩展和多任务处理等功能。虽然虚拟内存有一定的缺点和限制,但通过合理的配置和优化,可以充分发挥其优势并提高系统的性能和稳定性。
24、浏览器输入网址后执行的过程?
当在浏览器中输入网址并按下回车键后:
DNS解析:浏览器首先将输入的网址发送给DNS服务器,以获取该网址对应的IP地址。DNS服务器会查询其数据库,在找到匹配的域名时返回对应的IP地址给浏览器。
TCP连接建立:浏览器使用获取到的IP地址与服务器建立TCP连接。这涉及到使用TCP三次握手的过程,确保客户端与服务器之间的可靠连接。
发起HTTP请求:一旦建立了TCP连接,浏览器会发送HTTP请求到服务器。请求包含请求方法(例如GET、POST)、请求的URL、HTTP版本以及其他可能的请求头信息,如用户代理、Cookie等。
服务器处理请求:服务器收到HTTP请求后,会根据请求的URL和其他请求信息来处理请求。服务器可能会读取请求中的参数,查询数据库,执行相应的逻辑处理,并生成HTTP响应。
HTTP响应:服务器生成完整的HTTP响应后,将其返回给浏览器。响应包括一个状态码表示请求的结果(例如200表示成功,404表示资源未找到等),响应的内容,以及其他响应头信息,如Content-Type、Content-Length等。
接收和解析响应:浏览器接收到服务器的HTTP响应后,开始解析响应。它会检查状态码,根据响应头中的Content-Type确定响应内容的类型,并将响应的内容保存下来。
渲染页面:如果响应的内容是HTML页面,浏览器会开始解析HTML,并构建DOM树。然后,将CSS文件加载和解析为样式规则,并将其应用于DOM树,生成渲染树。最后,浏览器使用渲染树将页面内容绘制到用户的屏幕上。
关闭TCP连接:一旦页面完全加载并渲染完成,浏览器会关闭与服务器之间的TCP连接。但是,如果页面中存在其他的资源(如图片、脚本、样式表等),浏览器可能会继续发送HTTP请求获取这些资源。
25、进程和线程区别
进程
是操作系统资源分配的最小单元,操作系统的基本单位,有独立的句柄,内存空间,一个进程拥有的资源有字节的堆、栈、虚存空间(页表)等。进程是系统进行资源分配和调度的基本单位,它包含了执行一个程序所需的所有资源。每个进程都有自己独立的内存空间和系统资源,这使得进程间具有较高的隔离性。进程间通信需要通过特定的机制(如管道、共享内存、消息队列等)来实现,相对复杂且开销较大。
可以看作是一个类或PCB(进程控制块)的结构体,进程是操作系统堆一个正在运行的程序的一种抽象,可以把进程看作程序运行的一次运行过程
程序是在一个静态磁盘上的一个可执行文件
进程是将可执行文件加载到系统中,加载就是将信息放在内存中,分配资源并执行指令,
进程本质PCB:代表一个实实在在运行着的程序,也就是进程
包括PID:进程ID
进程状态:新建状态,就绪,运行,阻塞,销毁
优先级:决定进程的执行顺序
记账信息:记录CPU调用次数和执行间隔
上下文信息:保存本次执行状态
一组内存:指定进程需要使用的资源
线程
被包含在进程中,是进程中实际运行的单位。CPU的最小调度,一个进程最多有1024个线程,多个线程可以共享一个全局区堆区域,协同工作。
是进程中的一个执行单元,它共享进程所拥有的资源,是CPU调度的基本单位。
线程间共享同一个进程的内存空间和系统资源,这使得线程间通信更加便捷,但也需要考虑同步和互斥问题以防止数据竞争和死锁。
线程的创建、销毁以及切换的开销通常比进程小,这使得线程更适合处理大量并发任务。
一个进程可以并发多个线程,每个线程执行不同的任务,是操作系统进行运算调度的最小单元,进程中包含了线程,线程属于进程。
每个进程有自己的内存和资源,一个进程中的线程会共享这些内存和资源。
区别:
资源分配:进程是资源分配的基本单位,拥有独立的内存空间和系统资源;而线程是CPU调度的基本单位,共享进程的资源。
独立性:进程间具有较高的独立性,一个进程的崩溃影响其他进程的运行;而线程间由于共享进程的资源,一个线程的崩溃可能导致整个进程的崩溃(除非采取了相应的保护措施)。
开销:进程的创建、销毁以及切换的开销较大,因为涉及到操作系统资源的分配和释放;而线程的创建、销毁以及切换的开销较小,因为线程共享进程的资源,无需进行资源的重新分配和释放。
通信:进程间通信需要通过特定的机制来实现,相对复杂且开销较大;而线程间通信更加便捷,因为它们共享同一个进程的内存空间和系统资源。
进程:分配资源的基本单位
线程:执行的基本单位
联系:
线程是进程的一部分,一个进程可以包含多个线程。
线程和进程都用于实现并发编程,但线程更适合处理大量并发任务,因为它具有较小的开销和更高的执行效率。
应用场景
进程:
适用于需要隔离资源的独立任务,如服务器中多个应用程序的并行运行。
适用于分布式计算和集群计算,因为进程可以在不同的计算机上运行并通过网络进行通信。
线程:
适用于轻量级并发任务的场景,如计算密集型任务或需要共享资源的任务。
适用于多线程程序,可以充分利用多核处理器的并行计算能力来提高程序的执行效率。
注意事项
同步与互斥:由于线程间共享同一个进程的内存空间和系统资源,因此需要采取适当的同步和互斥措施来防止数据竞争和死锁问题。
线程安全:编写多线程程序时需要注意线程安全性,确保多个线程在并发执行时相互干扰导致程序崩溃或产生错误结果。
性能优化:虽然线程具有较小的开销和较高的执行效率,但过多的线程也会导致上下文切换频繁、系统资源紧张等问题。因此,在编写多线程程序时需要进行性能优化,合理控制线程的数量和优先级等参数。
(1)进程包含线程,一个进程里可以有一个或多个线程;
(2)进程和线程都是为了处理并发编程这样的场景,但是进程创建和释放的时候效率低,相比之下,线程更轻量,创建和释放效率更好;
(3)操作系统创建进程是给进程分配资源,进程是操作分配资源的基本单位,操作系统创建的线程是在CPU上调度执行,线程是操作系统调度执行的基本单位;
(4)进程具有独立性,每个进程有各自的虚拟地址空间,一个进程挂了影响其他进程,同一个进程的多个线程共用同一个内存空间,一个线程挂了很可能会影响其他的线程,甚至导致整个进程崩溃。
一、定义与概念
进程:进程是资源分配的基本单位,是系统进行资源分配和调度的独立实体。进程是程序在某个数据集合上的一次运行活动,是程序执行的一个实例。每个进程都有自己独立的地址空间和系统资源,如内存、文件、设备等。
线程:线程是CPU独立运行和独立调度的基本单位,是进程中实际运行的单位。一个进程可以包含多个线程,这些线程共享进程的资源,如内存和文件句柄等。线程的执行是并发的,即多个线程可以在同一时间内交替执行。
二、资源占用与开销
资源占用:进程拥有独立的地址空间和系统资源,因此每个进程都需要占用一定的系统资源。而线程共享进程的地址空间和资源,因此线程的资源占用相对较少。
开销:由于进程拥有独立的地址空间和资源,因此在进程切换时需要保存和恢复大量的上下文信息,导致进程切换的开销较大。而线程切换时只需要保存和恢复线程的上下文信息,因此线程切换的开销相对较小。
三、独立性与共享性
独立性:进程之间具有独立性,一个进程的崩溃影响其他进程的运行。而线程之间共享进程的地址空间和资源,因此一个线程的崩溃可能会导致整个进程的崩溃。
共享性:线程之间可以共享进程的地址空间和资源,这使得线程间的通信和数据共享变得更加容易。而进程之间需要通过进程间通信(IPC)机制来实现数据的共享和通信。
四、并发执行与效率
并发执行:进程和线程都可以实现并发执行,但线程的并发执行效率更高。因为线程切换的开销较小,且线程之间可以共享资源,减少了资源竞争和同步的开销。
效率:由于线程切换的开销较小且可以共享资源,因此线程在并发执行时通常比进程具有更高的效率。然而,这也增加了线程管理的复杂性,因为需要处理线程间的同步和互斥问题。
五、应用场景
进程:进程适用于需要独立运行、资源占用较大且对安全性要求较高的应用场景。例如,在操作系统中运行不同的用户程序时,通常会使用进程来隔离不同的程序运行空间。
线程:线程适用于需要高效并发执行、资源共享且对安全性要求相对较低的应用场景。例如,在编写多线程程序时,可以使用线程来实现任务的并发执行和数据共享。
综上所述,进程和线程在定义、资源占用、独立性、共享性、并发执行效率以及应用场景等方面都存在显著的区别。在选择使用进程还是线程时,需要根据具体的应用需求和系统环境进行权衡和选择。
进程通信和线程通信区别
一、通信主体与共享资源
线程通信:
通信主体:线程是CPU独立运行和调度的基本单位,线程之间共享进程的地址空间和资源。因此,线程间的通信相对简单,可以直接通过共享内存和变量来实现。
共享资源:线程间可以直接访问和修改共享内存中的变量和数据结构,无需额外的通信机制。
二、通信机制与方式
进程通信机制:
管道(Pipe):一种半双工的通信方式,数据只能单向流动,且只能在具有亲缘关系的进程间使用。
有名管道(Named Pipe):允许无亲缘关系进程间的通信,但仍然是半双工的。
信号量(Semaphore):用于控制多个进程对共享资源的访问,实现进程间的同步和互斥。
消息队列(Message Queue):允许进程间通过消息进行通信,消息可以是有格式的,克服了管道只能承载无格式字节流的缺点。
共享内存(Shared Memory):映射一段能被其他进程所访问的内存,是最快的IPC方式,但需要配合其他通信机制(如信号量)来实现同步和通信。
套接字(Socket):可用于不同设备及其间的进程通信,是一种更为通用的进程间通信机制。
线程通信机制:
共享内存:线程间可以直接通过读写共享内存中的变量来进行通信。
锁机制:包括互斥锁、条件变量、读写锁等,用于保证线程间的同步和互斥,防止数据竞争和不一致。
信号量机制:类似于进程间的信号量,但用于线程间的同步和互斥。
消息传递:虽然线程间可以直接通过共享内存通信,但有时也会采用显式的消息传递方式(如使用条件变量和信号量配合实现)。
三、通信复杂度与开销
进程通信:
复杂度:由于进程间不直接共享内存和变量,需要通过特定的通信机制来实现数据的共享和通信,因此进程通信的复杂度相对较高。
开销:进程间通信需要操作系统内核的参与和调度,因此通信开销较大。
线程通信:
复杂度:线程间可以直接通过共享内存和变量进行通信,无需额外的通信机制,因此线程通信的复杂度相对较低。
开销:线程间通信不需要操作系统内核的频繁参与和调度,因此通信开销较小。
四、应用场景与需求
进程通信:
应用场景:适用于需要独立运行、资源占用较大且对安全性要求较高的应用场景。例如,在操作系统中运行不同的用户程序时,通常会使用进程来隔离不同的程序运行空间,并通过进程间通信机制来实现数据的共享和通信。
需求:需要高效的进程间同步和互斥机制来确保数据的一致性和安全性。
线程通信:
应用场景:适用于需要高效并发执行、资源共享且对安全性要求相对较低的应用场景。例如,在编写多线程程序时,可以使用线程来实现任务的并发执行和数据共享。
需求:需要简单的线程间同步和互斥机制来确保数据的正确性和一致性。
综上所述,进程通信和线程通信在通信主体、共享资源、通信机制与方式、通信复杂度与开销以及应用场景与需求等方面都存在显著的区别。在选择使用哪种通信方式时,需要根据具体的应用需求和系统环境进行权衡和选择。
26、死锁?怎么产生的?
两个或多个并发进程中,如果每个进程持有某种资源而又都等待着别的进程释放它或它们现在保持着的资源,否则就不能向前推进,此时每个进程都占用了一定的资源,但又都不能向前推进,称这一组进程产生了死锁
产生原因:系统资源不足,进程推进顺序非法
必要条件:
互斥条件:涉及的资源是非共享的
不剥夺条件:进程所获得的资源在未使用完毕之前不能被其他进程强行夺走
部分分配:进程每次申请它所需的一部分资源,在等待新资源的同时继续占用已分配到的资源
环路条件
线程状态,它们是怎么转换的?
新建状态:新创建了一个线程对象
就绪状态:线程对象创建后,只等待获取cpu的使用权
运行状态:就绪状态的线程获得了cpu执行程序代码
阻塞状态:线程因某种原因放弃cpu使用权,暂时停止运行,直到线程进入就绪状态,才有机会转到运行状态
死亡状态:线程执行完了或因异常退出了run方法,该线程结束生命周期
死锁是指两个或两个以上的进程(或线程)在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程(或线程)称为死锁进程(或死锁线程)。
具体来说,当多个进程(或线程)在并发执行时,如果每个进程(或线程)都持有某种资源而又等待其他进程(或线程)释放它所占有的资源,那么这些进程(或线程)就会陷入一个无限等待的循环中,即发生死锁。
如何避免死锁
确保资源分配的顺序一致:
引入资源有序分配策略,要求每个进程(或线程)按照相同的顺序获取资源,从而避免进程(或线程)间因资源获取顺序不同而发生死锁。
避免资源的永久占用:
如果一个进程(或线程)已经占有了一些资源,但又申请了其他进程(或线程)当前持有的资源,导致两个进程(或线程)互相等待对方的资源释放,可以通过设置超时机制或者强制释放一部分已占有资源来避免死锁的发生。
使用资源分配图:
资源分配图可以帮助系统检测和避免死锁。图中的节点表示进程(或线程)和资源,边表示进程(或线程)对资源的请求和释放情况。系统通过检测图中是否存在环来判断是否有死锁,如果存在环,则可能发生死锁。
实现资源预先分配:
对于必须同时拥有多个资源才能进行的任务,可以采用资源预分配的策略,即进程(或线程)在开始执行之前就获取所有需要的资源,以确保没有其他进程(或线程)可以抢占这些资源导致死锁。
使用锁机制时遵循最佳实践:
在多线程编程中,使用锁(如互斥锁、读写锁等)来同步对共享资源的访问时,应遵循一些最佳实践,如尽量缩短锁的持有时间、避免嵌套锁等,以降低死锁的风险。
定期监控和诊断:
定期检查系统的性能指标、日志和错误信息,及时发现潜在的死锁问题。使用专门的工具(如Java中的jstack、MySQL的SHOW ENGINE INNODB STATUS等)来检测死锁线程(或进程)的状态和调用栈信息,从而及时发现和解决死锁问题。
综上所述,避免死锁需要从多个方面入手,包括确保资源分配的顺序一致性、避免资源的永久占用、使用资源分配图进行检测、实现资源预先分配、遵循锁机制的最佳实践以及定期监控和诊断等。这些措施的综合应用可以有效降低系统发生死锁的风险。
27、设计模式
工厂模式:定义创建对象的接口,封装对象的创建,使得具体化类的工作延迟到了子类中
Return new ConcreteProduct();
仅局限于一类的类,
AbstactFactory模式:抽象工厂模式
28、右值引用
左值可以取地址,可以修改,可以放在等号两边,右值不可以取,只能放在右边,没有名称
区分:放在等号左边的是左值,右边的是右值
Int a=3;//a是左值,3是右值
Int b=a;//a,b都是左值
Int &&b=a;//右值引用左值不行
右值引用&&
右值引用必须初始化:int &&a=10;
不能用左值初始化
当对右值加上引用后可以修改值也可以修改地址,从功能上升为左值,右值引用的本质是不用拷贝的左值,
引用的目的:传递参数有两种方式:值传递和引用传递
左值引用:函数传参,函数返回值,相比于值传递减少了拷贝次数
当返回值为右值引用时,会把返回的临时变量中的内存据为己有,仍保持了有效性,避免拷贝。
29、MVC
MVC模式,即Model-View-Controller模式,是一种经典的软件设计模式。它通过分离应用程序的输入、处理和输出,使得代码更加清晰、可维护和可扩展。
MVC模式旨在将应用程序的输入、处理和输出分开,使得数据(Model)、视图(View)和控制逻辑(Controller)相互独立,从而提高代码的可扩展性、可复用性、可维护性以及灵活性。
组成部分
模型(Model):
是应用程序中的数据部分,表示应用程序中的状态和行为。
负责处理应用程序的数据逻辑和业务规则。
可以是一个或多个JavaBean对象,它们封装了数据的属性和对这些数据的方法操作。
视图(View):
是用户的操作界面,负责显示应用程序的用户界面。
对于Web应用来说,视图可以是JSP页面、HTML页面或其他类型的用户界面。
视图只负责数据的显示和采集,而不包含任何业务逻辑或数据处理。
控制器(Controller):
处理从视图层发送的请求,并选取模型层的业务模型完成响应的业务实现。
控制器接收用户的输入,并将其转化为对模型或视图的操作。
在Web应用中,控制器通常是一个Servlet对象,它接收用户的请求,并根据请求来调用相应的模型和视图。
工作原理
用户通过视图层与应用程序进行交互,发送请求。
控制器接收用户的请求,并根据请求的类型和参数来选择相应的模型和视图。
控制器调用模型层来处理用户请求的数据逻辑和业务规则。
模型层处理完数据后,将结果返回给控制器。
控制器选择相应的视图来显示处理结果。
视图从模型中获取数据,并将其展示给用户。
优点
模块化:MVC模式将应用程序划分为三个独立的模块,提高了代码的可维护性和可扩展性。
灵活性:由于视图、模型和控制器的相互独立,可以方便地对其中任何一部分进行更改、替换或扩展,而不会影响到其他部分。
可重用性:模型可以被多个视图共享,提高了代码的重用性。
分离关注点:MVC模式将用户界面的设计、数据逻辑的处理和业务流程的控制分离开来,使得开发人员可以更加专注于各自的领域。
30、分布式项目中客户端与服务端通信流程
一、建立连接
首先需要建立连接。这一步骤通常通过TCP/IP协议完成,包括三次握手以确保双方能够稳定、可靠地通信。
二、发送请求
客户端准备请求:
客户端根据业务需求,准备要发送的请求数据。
请求数据通常包括请求头(如方法、路径、协议版本等)和请求体(如请求参数、业务数据等)。
序列化请求数据:
为了在网络中传输,请求数据需要被序列化为二进制格式。
序列化过程将数据结构转换为一系列字节,以便通过网络发送。
发送请求:
客户端通过已建立的连接,将序列化后的请求数据发送给服务端。
这一步骤通常使用Socket编程或类似机制完成。
三、接收响应
服务端接收请求:
服务端通过监听端口接收来自客户端的请求数据。
接收到的数据被反序列化为原始数据结构,以便后续处理。
处理请求:
服务端根据请求的内容和方法,执行相应的业务逻辑。
这一步骤可能涉及数据库查询、计算、文件操作等。
准备响应:
服务端将处理结果封装为响应数据。
响应数据通常包括状态码、响应头和响应体(如处理结果、错误信息等)。
序列化响应数据:
为了将响应数据发送给客户端,服务端需要将其序列化为二进制格式。
发送响应:
服务端通过已建立的连接,将序列化后的响应数据发送给客户端。
四、处理响应
客户端接收响应:
客户端通过已建立的连接,接收来自服务端的响应数据。
反序列化响应数据:
客户端将接收到的二进制数据反序列化为原始数据结构。
处理响应结果:
客户端根据响应数据的内容,执行相应的业务逻辑。
这一步骤可能涉及更新UI、存储数据、处理错误等。
五、断开连接
在完成通信后,客户端与服务端通常会断开连接,以释放资源。这一步骤通常通过四次挥手等过程完成。
六、通信过程中的注意事项
异常处理:
在通信过程中,可能会出现网络故障、超时、数据错误等异常情况。
客户端和服务端需要设计合理的异常处理机制,以确保系统的稳定性和可靠性。
安全性:
分布式系统中的通信通常涉及敏感数据的传输。
因此,需要采用加密、签名、身份验证等安全措施来保护通信过程和数据安全。
性能优化:
为了提高通信效率,可以采用压缩、缓存、异步通信等技术手段来优化通信过程。
31、TCP和UDP的区别
TCP(传输控制协议)和UDP(用户数据报协议)都是传输层(第四层)的协议,
一、连接
TCP:面向连接的协议。在数据传输之前,需要通过三次握手建立连接,确保通信双方准备就绪。数据传输结束后,需四次挥手释放连接。这种面向连接的特性使得TCP能够提供可靠的通信服务。
UDP:无连接的协议。在数据传输之前,不需要建立连接,直接发送数据包。每个UDP数据报都是独立的,不会保存连接状态。这种无连接的特性使得UDP的传输效率更高,但可能牺牲一定的可靠性。
二、可靠性
TCP:提供可靠的数据传输服务。通过序列号、确认应答、重传机制等手段,确保数据能够按照发送的顺序正确、无差错地到达接收方。如果数据包在传输过程中丢失或损坏,TCP会触发重传机制,直到数据成功传输为止。
UDP:不保证数据的可靠传输。没有重传机制和顺序控制机制,发出的数据包一旦发生丢失就无法恢复,也无法保证接收方接收到数据的顺序一定是发送方发送的顺序。因此,UDP的传输可靠性较低,但传输速度更快。
三、拥塞控制
TCP:具有拥塞控制机制。可以根据网络的拥塞程度动态调整发送数据的速率,避免网络拥塞导致数据丢失和延迟增加。TCP的拥塞控制机制包括慢启动、拥塞避免、快重传和快恢复等算法。
UDP:没有内置的拥塞控制机制。它会将所有数据发送到网络上,无论网络状态如何。这可能导致网络拥塞,但在某些实时性要求高的应用场景中,UDP的这种特性反而能够提高其传输效率。
四、传输效率
TCP:由于需要建立连接、进行确认应答和重传等操作,TCP的传输效率相对较低。但这也保证了其数据传输的可靠性和稳定性。
UDP:没有建立连接的过程,也不需要确认应答和重传等操作,因此UDP的传输效率更高。这使得UDP在实时性要求高的应用场景中更具优势。
五、使用场景
TCP:适用于需要可靠数据传输的场景,如文件传输、电子邮件、网页浏览等。在这些场景中,数据的完整性和顺序性至关重要。
UDP:适用于实时性要求高、但对数据可靠性要求不高的场景,如实时视频、音频传输、在线游戏、实时监控等。在这些场景中,数据的实时性更为重要,而少量数据的丢失或顺序错乱是可以容忍的。
为什么项目中采用的是tcp而不是udp
1、TCP被广泛使用在许多重要的应用层协议中,如HTTP、HTTPS、FTP和SMTP等。这些协议的成熟和普遍使用使得TCP成为了互联网的基石。相比之下,UDP虽然在一些特定场景下(如实时音视频传输、在线游戏和广播应用)具有优势,但在需要确保数据完整性和可靠性的场景中,TCP仍然是首选。
2、许多开发者选择TCP是因为它更容易管理和调试连接的可靠性,而不必担心手动处理重传和顺序问题。
3、在许多情况下,用户更关心数据的可靠传输,而不是速度。例如,在电子邮件和文件下载中,数据完整性和可靠性是关键因素。
32、RAII
RAII(Resource Acquisition Is Initialization)设计思想,即“资源获取即初始化”,是C++中的一种管理资源、避免泄漏的惯用法。核心是将资源的管理(如动态内存的分配和释放、文件句柄的打开和关闭等)与对象的生命周期紧密绑定。具体来说,资源在对象的构造函数中被分配(或获取)并初始化,而在对象的析构函数中被释放(或回收)。这种方式确保了资源总是被正确管理,即使在发生异常的情况下也能保证资源被正确释放,从而避免了资源泄漏等问题。
一、资源分配与初始化
在对象的构造函数中,通过适当的操作(如new操作符、文件打开函数等)分配或获取所需的资源。将这些资源保存在对象的成员变量中,以便在对象的其他成员函数中使用。
二、资源释放与析构
在对象的析构函数中,通过适当的操作(如delete操作符、文件关闭函数等)释放或回收在构造函数中分配或获取的资源。析构函数会在对象生命周期结束时被自动调用,从而确保资源总是被正确释放。
三、异常安全性
由于RAII利用了C++中对象自动调用析构函数的特性,即使在发生异常的情况下,也能保证资源被释放。这使得使用RAII管理资源的代码更加健壮和可靠。
四、智能指针与RAII
智能指针是RAII思想的一个重要应用。智能指针类封装了常规指针,并在内部使用引用计数或其他机制来自动管理内存的分配和释放。智能指针对象不再被使用时(如超出作用域、被显式删除或被赋予新值等),其所指向的内存会被自动释放,从而避免了内存泄漏问题。
五、RAII的优势
简化资源管理:通过将对资源的管理封装在对象中,简化了资源管理的代码。
提高代码可读性:使用RAII可以使代码更加清晰和易于理解,因为资源的分配和释放都在对象的构造函数和析构函数中完成。
增强异常安全性:即使在发生异常的情况下,也能保证资源被正确释放。
六、应用场景
RAII广泛应用于C++等支持对象导向编程的语言中,用于管理各种资源,如动态内存、文件句柄、网络连接等。在实际开发中,可以使用标准库中的智能指针(如std::unique_ptr、std::shared_ptr等)来方便地实现RAII。
RAII设计思想是一种非常有效的资源管理方式,它通过将资源的管理与对象的生命周期紧密绑定,确保了资源的正确分配和释放。
遵循RAII原则:RAII(Resource Acquisition Is Initialization)是一种管理资源的技术,它要求资源(如内存、文件句柄等)的获取和释放与对象的生命周期绑定。在对象的构造函数中分配资源,在析构函数中释放资源。
33、分布式系统
C++中实现分布式系统是一项复杂的任务,通常涉及网络通信、数据同步、并发处理等多个方面。
1. 网络通信
分布式系统的核心在于节点之间的通信。
Boost.Asio:一个跨平台的C++库,用于网络和底层I/O编程。支持TCP、UDP、串口等通信方式。
ZeroMQ:一个高性能的异步消息库,支持多种传输协议(如TCP、IP多播、in-process等)。
gRPC:高性能、开源和通用的RPC框架
2. 数据同步和一致性
确保分布式系统中各个节点之间的数据一致性是关键。
分布式锁:使用Redis或ZooKeeper实现分布式锁,确保在多个节点之间对共享资源的互斥访问。
分布式事务:如Google的Spanner和Percona的XtraDB Cluster等数据库系统提供了分布式事务的支持。
一致性算法:如Paxos、Raft等,用于确保分布式系统中的日志或配置数据的一致性。
3. 并发处理
C++11及更高版本提供了多线程支持,但处理分布式系统中的并发任务通常需要更复杂的机制。
C++标准库中的线程和同步原语:如std::thread、std::mutex、std::condition_variable等。
任务队列:使用线程池和任务队列来管理并发任务,如Intel TBB(Threading Building Blocks)或Boost.Thread。
4. 序列化与反序列化
在分布式系统中,数据需要在不同节点之间传输,通常需要进行序列化和反序列化。
Protocol Buffers:Google开发的一种与语言无关、平台无关的可扩展机制,用于序列化结构化数据。
Boost.Serialization:一个C++库,用于序列化和反序列化C++对象。
JSON/XML:简单的文本格式,便于调试和跨语言使用。
5. 集群管理与部署
管理和部署分布式系统的集群节点也是一个重要方面。
Kubernetes:一个开源的容器编排和管理平台,支持自动化部署、扩展和管理容器化应用程序。
Docker:一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化。
34、jsoncpp
JsonCpp是一个用于解析和生成JSON数据的C++库,它提供了DOM风格的API来处理JSON数据,可以将整个JSON文档加载到内存中,然后像操作树结构一样操作它。
JsonCpp的序列化过程通常涉及创建一个Json::Value对象,然后使用它的方法来构建JSON结构,最后使用Json::StreamWriterBuilder将其转换为字符串。
一、工作模式
基于对象的模型:将JSON结构映射到C++对象,适合于需要深度访问JSON树的情况。在这种模式下,你可以像操作C++对象一样操作JSON数据,这使得数据访问和操作更加直观和方便。
基于值的模型:更适用于简单的读写操作。在这种模式下,JsonCpp内部实现了自动内存管理,使用更为简便。你可以直接使用JsonCpp提供的Json::Value类型来存储和操作JSON数据。
二、使用方法
使用API:
使用Json::Reader类来解析JSON字符串。
使用Json::Value类来表示和操作JSON数据。
使用Json::StreamWriterBuilder类来将Json::Value对象序列化为JSON字符串。
三、应用场景
配置文件读取:JsonCpp可以方便地用于读取或保存应用程序的配置信息,因为JSON格式清晰易读,相比XML更简洁。
网络通信:在网络API调用中,JsonCpp常用于解析返回的JSON数据,或者将C++对象转换为JSON字符串发送给服务器。
数据分析:在数据分析领域,JsonCpp可以作为数据导入导出工具,帮助你将JSON数据轻松转换为C++中的结构化数据。
日志记录:生成结构化的JSON格式日志,便于后续进行自动化处理和分析。
35、为什么int是四个字节?
C标准没有规定各类数据所占内存字节数,通常int为32位,每种编译器可以位硬件选择合适的长度,仅受一些限制,如short和int至少16位,long32位,short不能超过int,int不能超过long。
36、C和C++区别
|
C |
C++ |
|
数据和函数都是独立且自由的实体 |
以对象的形式封装在一起 |
|
不支持函数和运算符重载 |
支持 |
|
不支持引用变量 |
支持 |
|
不支持虚拟化和友元函数 |
支持 |
37、如何实现队列
Typedef int QDataType;
Typedef struct QueueNode{
QDataType val;//节点存储的数据
Struct QueueNode* next;//指向下一个节点的指针
}QNode
Typedef struct Queue{
QNode* phead;//指向队头的指针
QNode* ptail;//指向队尾的指针
Int size;//队列大小
}Queue;38、sort函数内部实现
底层是内省式排序以及插入排序,内省排序首先从快速排序开始,当递归深度超过一定深度(深度为排序元素数量的对数值)后转为堆排序。
39、程序编译过程
源程序—可执行程序的过程:预编译,编译,汇编,链接
编译:词法分析,语法分析,语义分析,中间代码生成,目标代码生成和优化
编译就是把文本形式源代码翻译成机器语言形成的目标文件的过程
链接是把目标文件、操作系统的启动代码和用到的库文件进行组织,形成最终可执行代码
源代码—编译器—汇编代码—汇编器—目标代码—连接器—可执行程序
编译是读取源程序(字符流),对之进行词法和语法的分析,将高级指令转换成功能等效的汇编代码
源文件的编译包括两个主要阶段:
编译预处理:读取源程序,对其中的伪指令(以#开头的指令)和特殊符号进行处理
#define 宏定义
#include 头文件
预编译程序所完成的基本上是对源程序的替代工作,生成一个没有宏定义,没有特殊符号的输出
40、动态库和静态库分别在编译哪个阶段得到?
库就是现有的、写好的、成熟的、可复用的代码,库是一种可执行代码的二进制形式,是预编译代码的集合,可以被重复使用。
静态库(.a/.lib)动态库(.so/.dll)
42、vector容器内部扩容机制?
当向vector push_back一个元素时,如果此时元素个数超过了vector的容量,会触发扩容,开辟新空间—拷贝旧空间的内容—释放旧元素。
43、多态的虚函数?
静态:函数重载
多态是在不同继承关系的类对象,去调用同一函数,产生了不同的行为
在继承中,要构成多态:必须通过基类的指针或引用调用虚函数
被调用的函数必须是虚函数,且派生类必须对基类的虚函数进行重写
Virtual 虚函数的作用是用来实现多态
内联函数不能是虚函数
虚函数不可以是static的,因为静态函数没有this指针,虚函数的调用时通过this指针来调用对象的信息
子类虚函数可以不加virtual,但不推荐
派生类重写基类虚函数时,返回值可以不同,但是要求返回值必须是一个父子类关系的指针或引用
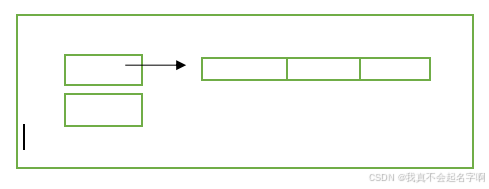
虚函数指针内部数据结构
虚函数表的内部结构:
45、语法分析和语义分析的区别
词法分析:把程序分割成一个个token的过程(有限自动机),把程序的结构识别处理,并形成一棵便于由计算机处理的抽象语法树。
语法分析:将由扫描器产生的记号进行语法分析,进而产生语法树,上下文无关语法。
语义分析:消除语义模糊,给这棵树一些属性信息,编译器后端是把这棵树生成汇编代码。
46、有哪些函数不能有virtual关键字
静态成员函数:不与类的任何特定实例关联,因此不能被重写
友元函数:不是类的成员函数
全局函数:不属于任何类
47、多重继承时,两个类对同一个函数有不同实现,合法吗?
本身导致编译错误,但如果试图在派生类中直接调用这个未明确指定的基类函数(即存在名称冲突),编译器将会不知道你想要调用哪个基类的实现,要用作用域解析运算符::来明确调用的基类函数
48、在定义函数接口时,如何设计参数类型以提高传递效率?
可以使用引用来传递参数,这样拷贝对象,节省内存和时间。如果传递的是临时对象,可以使用右值引用(&&)和std::move来避免拷贝。
49、 CDN?
内容分发网络Content Delivery Network,服务器离得太远,先分发给各个CDN,然后CDN发送到各个主机
分发内容:静态内容、动态内容
50、自旋锁?
自旋锁是一种忙等待的方式适用于临界区执行时间短暂、锁冲突概率低的情况,信号量会进入休眠。
信号量是一种阻塞机制,适用于临界区执行时间长,所冲突概率高的情况,自旋锁进入休眠。
51、判断链表是否有环?
使用快慢指针:创建两个指针,一个指针为快指针,另一个为慢指针。初始时都指向链表的头节点快指针每次向前移动两个节点,慢指针每次向前移动一个节点。如果链表中存在环,那么快慢指针最终会相遇。如果链表中不存在环,那么快指针最终会先到达链表尾部,此时可以判断链表无环。
52、使用多线程时应注意什么呢?
线程安全:多线程环境下多个线程同时访问共享资源可能会引发竞态条件,导致数据不一致,可以通过使用互斥锁,条件变量等同步机制来保护共享资源的访问
线程间通信:队列、信号量、事件等实现线程间的同步和传递消息
死锁:两个或多个线程在互相等待对方释放资源而无法继续执行的状态
上下文切换开销
共享资源的合理使用
有效的线程调度和任务划分
错误处理和异常处理
53、构造函数不能是虚函数
54、进程间的通信方式?线程的通讯方式呢?怎么实现
管道
半双工通信,从内核中划出一片空间用作缓存,一个进程往这片缓存中写入数据,另一个进程读取这个缓存中的数据,分为匿名管道和命名管道,匿名管道是半双工通信,数据只能在管道中单向流动,如果想要进行双向通信,则需要建立两条管道,且一般只用于父子进程之间的通信。一个进程采用pipe()函数,创建管道,该函数返回两个文件描述符,一个是写描述符,一个是读描述符。通过fork()创建一个子进程,然后实现父子进程之间的通信。
信号
是一种软中断,产生方式有两种,一种为硬件产生,即采用终端设备比如键盘来产生信号,另一种是通过调用系统函数给一个进程发送信号。进程收到信号之后并不会立刻执行,而是在cou由内核态转变为用户态之前会检查是否有未处理的信号
消息队列
进程给进程发送数据时,只需要即将数据放在消息队列中便可以立即返回而不需要阻塞。
消息队列是保存在内核中的消息链表,通信双方会约定好收发数据的格式,而不是无格式的字节流。
共享内存
可以理解为操作系统内核所划分出的一段物理地址空间,由于每一个进程都有自己的虚拟地址空间,且通过页表完成地址的映射,所以可以通过借助页表完成进程中的一段虚拟地址空间和共享内存的映射
信号量
当使用共享内存的通信方式,如果有多个进程同时往共享内存写入数据,有可能先写的进程的内容被其他进程覆盖了,因此需要一种保护机制,信号量本质是一个整型的计数器,用于实现进程间的互斥和同步。
信号量代表资源的数量,操作信号量的方式有两种:
P操作:将信号量减一,相减后信号量如果小于0,则表示资源已经被占用了,进程需要阻塞等待,如果大于等于0,则说明还有资源可用,进程可以正常执行。
V操作:将信号量加一,相加后如果小于等于0,则表明当前有进程阻塞,于是将该进程唤醒,如果大于0,则表明当前没有阻塞的进程。
55、数组和链表的区别
数组:具有相同数据类型的变量集合,通过下标来区别并访问数组元素,在内存中连续,固定数组长度,不支持动态改变,从栈上分配内存
链表:物理存储上非连续,非顺序的存储结构,在任意位置插入和删除都非常快,不需要移动其他元素,支持动态增加和删除元素,从堆上分配内存,访问效率低,需从头遍历
56、反向代理和正向代理的区别,应用场景
反向代理和正向代理是代理服务器的两种不同使用方式。
一、区别
部署位置与代理对象
正向代理:通常部署在客户端所在网络的边缘,如企业的局域网出口或用户的个人设备上。它代表客户端(用户)向远程服务器发起请求,客户端直接与正向代理交互,而服务器端只知道代理的存在,不知道真实的客户端信息。
反向代理:则部署在服务器端,通常靠近目标服务器或服务集群,作为公共入口点。它代表服务器接收客户端的请求,客户端不知道它实际上是在与代理服务器通信,而认为是直接与目标服务器通信。
作用目的
正向代理:主要解决访问限制问题,如匿名浏览和流量控制。它还能提供缓存功能,减少对外部资源的直接访问,提高访问速度。
反向代理:主要用于负载均衡,将客户端请求分布到后端服务器集群上,提高网站的可用性和扩展性。
客户端与代理的交互
在正向代理中,客户端需要配置代理设置,明确知道代理的存在。
在反向代理中,客户端通常不知道代理的存在,它直接访问的是代理服务器提供的公共地址。
二、应用场景
反向代理的应用场景
负载均衡:根据预设的算法,将请求分发到多个后端服务器上,以达到负载均衡的目的。
缓存加速:缓存静态内容或动态内容的结果,将来自目标服务器的响应缓存起来,并在后续的请求中直接返回缓存的响应,从而提高响应速度和减轻目标服务器的负载。
安全性与保护:用作安全层,保护目标服务器免受直接暴露在公共网络中的攻击。
域名和路径重定向:根据不同的域名或路径,将请求重定向到不同的目标服务器上。
正向代理的应用场景
提供匿名访问:屏蔽客户端的真实IP地址,使得客户端可以通过代理服务器访问目标资源,隐藏自己的身份。
突破网络限制:帮助用户绕过特定网站或内容的访问限制。
加速访问:缓存经常访问的资源,并在客户端请求时直接返回缓存的内容,从而加快访问速度。
安全性增强:过滤恶意请求、防止攻击和窃取敏感信息。例如,在企业内部,公司可以设置正向代理服务器来过滤员工对外访问的流量,保护内部网络的安全。
57、指针函数和函数指针:
指针函数:一个函数的返回值是指针
函数指针:一个指向函数的指针,它里面存放了指向函数的地址
58、内存映射
将一块内存空间映射到不同的进程空间中
59、define和const
define:预处理命令,用于创建符号常量 预处理阶段
const:关键字,创建具有常量值的变量,本质是只读变量,编译阶段
60、Linux怎么实现同步
互斥锁,信号量,条件变量
61、IO多路(poll、epoll和select)
IO多路复用是一种高效的I/O处理方式,它允许单个线程同时监视多个文件描述符(socket),以处理多个并发连接。在Linux系统中,IO多路复用的三种主要实现方式是poll、epoll和select。以下是这三种方式的详细介绍:
1. select
工作原理:
创建一个文件描述符集合,用于存放需要监视的文件描述符(socket)。
调用select函数,将文件描述符集合传递给内核,让内核监视这些文件描述符的状态变化(如可读、可写、异常)。
select函数会阻塞当前线程,直到一个或多个文件描述符就绪,或者超时发生。
当select函数返回时,检查文件描述符集合,找出哪些文件描述符就绪,并进行相应的读写操作。
优缺点:
优点:将监视文件描述符是否就绪的工作由用户态放到了内核态,效率更高。
缺点:
可监控的文件描述符数量有限制(通常为1024个),这限制了最大能支持的并发数。
用户进程的文件描述符集合需要从用户进程拷贝到内核,有一定的性能开销。
select函数返回后,用户进程只知道某个或某几个文件描述符满足要求,但不知道是哪个,因此需要遍历所有文件描述符,复杂度为O(n)。
2. poll
工作原理:
与select类似,poll也使用一个结构体数组来存储需要监视的文件描述符及其事件。
调用poll函数,将结构体数组传递给内核进行监视。
poll函数同样会阻塞当前线程,直到有文件描述符就绪或超时发生。
返回后,用户进程需要遍历结构体数组,找出哪些文件描述符就绪
优缺点:
优点:解决了select的文件描述符数量限制问题,可以监视更多文件描述符。
缺点:
仍然存在文件描述符状态在用户态和内核态的频繁拷贝问题。
需要遍历所有文件描述符来检查哪些已经就绪,复杂度同样为O(n)。
只能在Linux平台使用,跨平台性较差。
3. epoll
工作原理:
epoll是select和poll的增强版本,它使用红黑树和链表来优化性能。
调用epoll_create函数创建一个epoll实例(红黑树的根节点)。
使用epoll_ctl函数向epoll实例中添加、修改或删除需要监视的文件描述符及其事件。
调用epoll_wait函数等待事件发生。当有文件描述符就绪时,epoll_wait会返回就绪的文件描述符数量及其相关信息。
优缺点:
优点:
没有文件描述符数量的限制。
避免了文件描述符状态在用户态和内核态的频繁拷贝。
只需遍历就绪的文件描述符集合,复杂度为O(1)。
支持水平触发和边缘触发两种模式。
缺点:只能在Linux平台使用,跨平台性较差(但这对大多数使用epoll的场景来说通常不是问题,因为epoll本身就是Linux特有的)。
综上,在需要跨平台支持且并发连接数较少的情况下,可以选择select;在Linux平台上且需要监视大量文件描述符时,epoll是更好的选择。
Windows IOCP(I/O Completion Ports):Windows操作系统提供的一个高性能的线程同步机制,专门为高吞吐量的服务器应用程序设计。
Linux io_uring:Linux内核中的一个比较新的接口,用于提供高效的异步I/O。
Boost.Asio C++库:一个跨平台的C++库,用于编写基于网络和低级I/O操作的程序,支持在Windows上通过IOCP和在POSIX系统上通过aio_calls或epoll实现异步I/O操作。
62、野指针
指向已被释放或无效内存地址的指针
63、互斥锁
一种用于线程同步的机制,用于确保同一时间只有一个线程访问资源
64、如何处理多线程中的互斥?
在多线程编程中,互斥(Mutex,全称Mutual Exclusion)是用来防止多个线程同时访问共享资源,从而避免数据竞争和不一致性的重要机制。
1. 使用互斥锁(Mutex)
互斥锁是最直接和常用的互斥机制。它允许一个线程锁定某个资源,从而阻止其他线程访问该资源,直到锁被释放。
创建和销毁:在大多数编程环境中,都有创建和销毁互斥锁的API。
加锁和解锁:线程在访问共享资源前需要加锁,访问完成后解锁。
死锁和优先级反转:使用互斥锁时需要小心死锁和优先级反转问题。
2. 使用读写锁(Read-Write Lock)
读写锁允许多个线程同时读取共享资源,但写入时只有一个线程可以访问。这提高了读取操作的并发性。
共享锁(读锁):允许多个线程同时持有。
排他锁(写锁):只有一个线程可以持有。
3. 使用信号量(Semaphore)
信号量是一种更通用的同步机制,可以看作是一个计数器,用于控制对共享资源的访问。
初始化:信号量通常被初始化为一个正整数,表示可用的资源数量。
等待(P操作):线程在访问资源前需要等待信号量,如果信号量大于0,则减一并继续;否则阻塞。
信号(V操作):线程在访问完资源后释放信号量,即加一,并可能唤醒等待的线程。
4. 使用条件变量(Condition Variable)
条件变量用于线程间的同步,它允许线程等待某个条件成立。
等待:线程可以在条件变量上等待,直到被其他线程唤醒。
通知:线程在满足某个条件时可以通知等待的线程。
5. 使用原子操作(Atomic Operations)
原子操作是不可被中断的操作,它们通常用于实现低级的同步机制。
原子读/写:确保读/写操作是原子的,即不可被其他线程中断。
原子比较并交换(CAS):比较并交换操作,如果当前值与预期值相等,则设置为新值。
6. 使用高级并发数据结构
一些编程语言或库提供了高级的并发数据结构,如并发队列、并发哈希表等,它们内部已经实现了必要的同步机制。
注意事项
避免死锁:确保每个线程都能最终释放它持有的锁。
避免优先级反转:高优先级的线程不应该被低优先级的线程阻塞。
减少锁粒度:尽量缩小锁的范围,以减少锁竞争和提高并发性。
使用锁超时:在尝试获取锁时设置超时,以避免线程无限期地等待。
考虑性能影响:锁的使用会影响性能,因此应该仔细权衡同步需求和性能要求。
通过合理地使用上述机制,可以有效地处理多线程中的互斥问题,确保程序的正确性和性能。
65、虚函数在子类中如何重新定义?
当子类继承有虚函数的父类时,子类可以重新定义父类的虚函数。如果基类的成员函数设为 virtual,其派生类的相应函数也会自动变为虚函数。在重写虚函数时,子类中的函数名、函数类型、返回值类型、函数参数个数和类型都要与父类的虚函数相同,并根据子类的需要重新定义函数功能。
例如有一个父类 Shape,其中有虚函数 calcArea,子类 Circle 和 Rect 分别重写了这个函数来计算圆形和矩形的面积。子类在重写虚函数时,不一定要在函数声明前加上 virtual 关键字,但最好加上以便更清晰地看出这是虚函数。如果子类不重写虚函数,则它会继承父类的虚函数。
66、中断
是异步调用,无法知道什么时候会被调用,不能像函数一样主动调用
串口数据帧格式:起始位、数据位、校验位、停止位
中断是计算机系统中一种重要的处理机制,用于响应某种事件或条件的发生,它是一种异步的事件,可以打断当前正在执行的程序或任务,以处理紧急情况或外部设备的请求
68、单片机驱动和Linux驱动的区别:
单片机用的是物理地址,Linux编程都是虚拟地址,经过MMU(内存管理单元)后才是物理地址
单片机驱动简单,直接操作物理地址的寄存器,代码量少,Linux驱动引入了虚拟地址于MMU,故需要操作虚拟地址,经过MMU转化为时机物理地址才可以对寄存器进行操作,而且Linux代码量大
Linux驱动中,设备和驱动都是分离的,而且驱动也是分层的
Linux内核中,提供了大量的驱动接口。
69、extern
extern 关键字,置于变量或函数前,标识变量或函数的定义在其他文件中,声明作用。
extern声明的全局变量和函数可以实现跨文件访问。
声明可以多次出现,但定义只能出现一次。
用法:
1、extern "C" :指示编译器按C的规则查找。因为C++和C的编译器的处理存在差异。
extern "C" {
#include "xxx.h"
#include "yyy.h"
void func(int x, int y);
void func();
}2、同一文件中,变量num声明放在main()函数后,通过extern声明后,编译器会进行搜索。
#include<studio.h>
int func();
int main(){
func();
extern int num;
printf("%d", num);
}
int num;
int func(){
printf("%d", num);
}3、nums与mian()在不同文件中,num定义为全局变量,main中用extern声明。
//1
#include<stdio.h>
int main(){
extern int num; //声明
printf("%d", num);
return 0;
}
//2
#inclue<stdio.h>
int num = 5; //定义4、通常将extern声明的全局变量和全局函数的实现放在一个.cpp文件,用同名的.h文件包括变量和函数的声明。
extern 和 static不能同时修饰一个变量。
extern表示该变量已经定义过了,这里使用。
static表示静态的变量,分配内存存储在静态区,不存储在栈上。作用于是本身的编译单元。
71、内核与线程
内核是操作系统(OS)对于所有硬件的协调软件,它的初始目的是去协调硬件,以根据用户给予的指令进行硬件操作。
组成:
进程管理子系统:负责CPU资源的分配和管理,对于想要在当前OS上运行的软件,内部称之为进程。
内存管理子系统:主要是对内存的管理建立起更加方便的操作方案,例如建立页表机制,以4K为单位对所有地址进行统一规划。
文件子系统:对于文件建立索引及管理策略。
网络子系统:TCP/UDP/IP等基层协议的解析实现者,网卡驱动的管理协调者。
设备子系统:包括输入/输出设备管理、外置设备管理。
线程是操作系统能够进行运算调度的最小单位,被包含在进程之中,是进程中的实际运作单位。
产生原因:由于进程调度对CPU开销大,所以产生了线程的概念。
实现方案:
用户级线程:在用户空间运行线程库,任何应用程序都可以通过使用线程库被设计成多线程程序。线程库包含用于创建和销毁线程、在线程间传递数据和消息、调度线程执行以及保存和恢复线程上下文的代码。用户级线程的创建、消息传递、线程调度、保存/恢复上下文都由线程库来完成。内核感知不到多线程的存在,继续以进程为调度单位。
内核级线程:通常使用几个进程表在内核中实现,每个任务都会对应一个进程表。内核会在每个进程的时间片内调度每个线程,所有能够阻塞的调用都会通过系统调用的方式来实现。当一个线程阻塞时,内核可以选择运行在同一个进程中的另一个线程(如果有就绪线程的话)还是运行另一个进程中的线程。这种实现的好处是由时钟决定线程切换时间,因此不太可能将时间片与任务中的其他线程占用时间绑定到一起。
混合实现:结合用户空间和内核空间的优点,设计人员采用了一种内核级线程的方式,然后将用户级线程与某些或者全部内核线程多路复用起来。在这种模型中,编程人员可以自由控制用户线程和内核线程的数量,具有很大的灵活度。采用这种方法,内核只识别内核级线程,并对其进行调度,其中一些内核级线程会被多个用户级线程多路复用。
三、C++与线程
线程创建:C++11提供了语言层面上的多线程支持,包含在头文件<thread>中。使用std::thread可以创建新的线程,并将函数或可调用对象作为参数传递给std::thread构造函数,以在新线程中执行该函数或可调用对象。
线程管理:std::thread对象代表一个线程,可以通过该对象来管理线程的状态和行为,如启动线程、等待线程结束、查询线程ID等。
线程同步:在多线程编程中,通常需要使用同步机制来确保线程间的协调和数据的正确访问。std::thread可以与其他同步原语(如互斥量、条件变量等)一起使用,实现线程间的同步和通信。
线程销毁:当std::thread对象被销毁时,它代表的线程也会被销毁。如果线程还在运行,通常会调用std::terminate终止程序;如果线程已经结束,会释放线程的资源。
四、内核与线程的交互
内核程序既没有窗口,也没有控制台,唯一能看到结果的是调试日志。如果想要用户“看到”些什么,很多情况下,内核需要与应用层通信。
内核程序必须要用某种方式和应用软件互通信息。如果一个驱动需要和应用程序通信,那么首先要生成一个设备对象(DeviceObject),往往称之为控制设备对象。设备对象是非常重要的元素,可以在内核中暴露出来给应用层,应用层可以像操作文件一样操作它。
72、内存泄漏
C++中(Memory Leak)是一个严重的问题,它指的是程序未能正确释放已经不再使用的动态分配内存,导致这些内存无法被重新利用,进而可能造成系统内存的耗尽,影响程序的稳定性和性能。
原因:
1、忘记释放内存:这是最常见的内存泄漏原因。程序员在动态分配内存后(通常使用new或malloc),可能会忘记在适当的时候使用delete或free来释放这些内存。
2、异常处理不当:在C++中,如果在使用new分配内存后,构造函数抛出异常而没有适当的异常处理机制来释放已分配的内存,那么就会发生内存泄漏。
3、指针重新赋值:如果一个指针被重新赋值指向新的内存地址,而原来的内存地址没有被释放,那么原来的内存就会发生泄漏。
4、容器管理不当:使用STL等容器时,如果容器对象被销毁而其中的指针指向的内存没有被释放,或者容器中的元素被删除而相应的内存没有被释放,也会导致内存泄漏。
5、库函数使用不当:一些库函数可能会分配内存,而程序员可能不知道这一点,或者忘记了在不再需要时释放这些内存。
检测内存泄漏
1、工具检测:可以使用各种内存泄漏检测工具,如Valgrind(Linux)、Visual Studio的诊断工具(Windows),来帮助检测内存泄漏。
2、手动检查:通过仔细的代码审查,检查所有动态内存分配和释放的地方,确保每次分配都有对应的释放。
3、使用智能指针:智能指针可以自动管理内存的生命周期,当智能指针对象被销毁时,它所管理的内存也会被自动释放。
4、异常安全:在编写可能抛出异常的代码时,要确保在异常发生时也能正确释放资源。可以使用智能指针、try-catch块或者析构函数中的清理代码来实现。
5、定期检查和测试:定期使用内存泄漏检测工具检查代码,并在单元测试中包含内存泄漏的测试。
6、代码审查:通过代码审查来发现潜在的内存泄漏问题,并鼓励团队成员之间互相学习和分享最佳实践。
73、多线程竞态条件和同步
一、多线程竞态条件
多线程竞态条件(Race Condition)是多线程编程中常见的问题,它指的是多个线程同时访问共享资源,由于访问顺序的不确定性,导致程序的执行结果不确定。这种情况通常发生在两个或多个线程在没有适当的同步机制下,尝试同时访问或修改同一个共享资源(如全局变量、共享内存、文件等)。
竞态条件可能导致数据不一致、程序崩溃或产生不可预期的行为。例如,如果两个线程同时对一个全局变量进行写操作,而没有适当的同步机制,那么最终的结果可能是不确定的,可能是最后一个写操作覆盖了之前的结果,也可能是两个写操作的结果以某种不确定的方式混合在一起。
二、多线程同步
为了解决多线程竞态条件问题,需要引入多线程同步机制。同步机制可以确保多个线程在访问共享资源时保持一致的顺序和互斥性,从而避免竞态条件的发生。
在C++中,常用的多线程同步机制包括:
互斥量(Mutex):
互斥量是一种用于保护共享资源的锁机制。当一个线程想要访问共享资源时,它必须先获取互斥量。如果互斥量已经被其他线程获取,那么该线程将被阻塞,直到互斥量被释放为止。可以使用std::mutex类来实现互斥量。例如,使用std::lock_guard或std::unique_lock来自动管理互斥量的获取和释放。
条件变量(Condition Variable):条件变量是一种用于线程间同步的机制。它允许一个线程等待某个条件成立(通常是由另一个线程设置的某个标志位或变量),然后才能继续执行。在C++中,可以使用std::condition_variable类来实现条件变量。条件变量通常与互斥量一起使用,以确保在等待条件成立时发生竞态条件。
原子操作(Atomic Operations):原子操作是一种被中断的操作,它可以确保操作的完整性。在C++中,可以使用std::atomic模板类来实现原子操作。原子操作通常用于对简单数据类型的访问和修改,如整数、指针等。通过使用原子操作,可以避免竞态条件的发生,并提高代码的性能。
信号量(Semaphore)是一种用于控制多个线程对共享资源访问的计数器。它允许一定数量的线程同时访问共享资源,当计数器达到零时,其他线程将被阻塞,直到有线程释放资源并减少计数器的值。C++中虽然标准库没有直接提供信号量的实现,但可以使用其他同步机制(如互斥量和条件变量)来模拟信号量的行为。
读写锁(Reader-Writer Lock):是一种允许多个线程同时读取共享资源,但只允许一个线程写入共享资源的锁机制。它提高了读取操作的并发性,同时保证了写入操作的原子性和一致性。在C++中,可以使用第三方库(如Boost库)来实现读写锁。
三、注意事项
避免死锁:死锁是指两个或多个线程互相等待对方释放资源,从而导致程序无法继续执行。为了避免死锁,可以使用资源申请顺序、避免多锁等待等方法。
避免饥饿:饥饿是指某个线程由于某种原因无法获取到所需的资源而无法继续执行的情况。为了避免饥饿,可以使用锁的优先级、公平调度等机制来确保线程公平地获取资源。
合理使用同步机制:过多的同步机制可能会降低程序的性能。因此,在使用同步机制时需要根据实际情况进行选择和优化。例如,对于简单的数据类型可以使用原子操作来提高性能;对于复杂的共享资源可以使用互斥量和条件变量等机制来确保数据的一致性和完整性。
通过合理使用多线程同步机制,可以避免竞态条件的发生,提高程序的稳定性和性能。
74、左值引用和右值引用的区别
右值引用解决的是避免右值切换上下文的时候进行拷贝的开销
75、指针和引用的区别?
(1)指针是一个变量,存储的是变量的地址,引用是变量的别名,内部实现是只读指针;
(2)指针可以为空,引用不能为空,定义时必须初始化;
(3)指针在初始化之后可以改变指向,引用在初始化之后不能改变;
(4)指针可以有多级,引用只有一级;
(5)当把指针作为参数进行传递时,也是将实参的一个拷贝传递给形参,二者指向的地址相同,但不是同一个变量,在函数中改变该变量的指向不影响实参,而引用是可以的;
(6)指针是具体变量,需要占用存储空间,引用的本质是一个指针,会占据4个字节的内存;
76、堆和栈的区别
(1)堆和栈在空间分配方面的区别:
堆一般由程序员分配释放,如果程序员不释放,程序结束后可能有操作系统回收,分配方式类似于链表。栈一般由操作系统自动分配释放,存放函数的参数值和局部变量的值等,操作方式类似于数据结构中的栈。
(2)堆和栈在缓存方式方面的区别:
堆存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定,所以调用这些对象的速度比较慢。栈使用一级缓存,通常是被调用时处于存储空间中,调用完毕后立即释放。
(3)堆和栈在数据结构方面的区别:
堆一般被看做一棵树,比如堆排序。栈是一种先进后出的数据结构。
78、生产者消费者模式
它用于解决在多线程环境下,一个或多个生产者线程生成数据,一个或多个消费者线程消费数据的同步问题。这种模式通过平衡生产者和消费者之间的速度差异,确保数据的有效传递和系统的稳定运行。以下是对生产者消费者模式管理的详细探讨:
一、基本概念
生产者(Producer):负责生成数据,并将其放入缓冲区(Buffer)中供消费者使用。生产者线程通常会在生成数据后,将数据放入共享缓冲区,并通知消费者有新数据可供消费。
消费者(Consumer):负责从缓冲区中取出数据,并进行处理。消费者线程通常会在缓冲区中有数据时,取出数据进行处理,并在处理完成后通知生产者缓冲区已空,可以继续生产新数据。
缓冲区(Buffer):用于存储生产者生成的数据,供消费者使用。缓冲区通常是一个先进先出的队列(FIFO Queue),以确保数据的顺序性。
二、管理策略
同步机制:
使用互斥锁(Mutex)来确保对缓冲区的访问是线程安全的。即,在同一时间内,只有一个线程可以访问缓冲区。
使用条件变量(Condition Variable)或信号量(Semaphore)来协调生产者和消费者之间的同步。当缓冲区满时,生产者会等待消费者消费数据;当缓冲区空时,消费者会等待生产者生产数据。
缓冲区大小:
缓冲区的大小是一个重要的设计参数。如果缓冲区太小,可能会导致生产者频繁等待消费者,降低生产效率;如果缓冲区太大,可能会占用大量内存资源,并增加消费者处理数据的延迟。
缓冲区的大小应根据实际应用场景进行权衡和选择。
生产者和消费者的数量:
在多线程环境下,可以根据系统资源和性能需求,灵活地配置生产者和消费者的数量。
如果生产者数量多于消费者数量,可能会导致缓冲区快速填满,增加等待时间;如果消费者数量多于生产者数量,可能会导致缓冲区中的数据被快速消费完,增加消费者的等待时间。
因此,应根据实际情况合理配置生产者和消费者的数量,以实现最佳的性能和资源利用率。
异常处理:
在生产者消费者模式中,应充分考虑异常处理机制。例如,当生产者无法生成数据时,应通知消费者停止消费;当消费者无法处理数据时,应通知生产者停止生产。
同时,还应考虑在异常情况下对缓冲区的清理和释放工作,以避免资源泄露和内存泄漏等问题。
三、实现方式
生产者消费者模式可以通过多种方式实现,如使用C++中的std::thread、std::mutex、std::condition_variable等标准库组件
在实现时,应注意以下几点:
确保对缓冲区的访问是线程安全的。
正确地使用同步机制来协调生产者和消费者之间的同步。
根据实际需求合理配置缓冲区大小和生产者消费者的数量。
充分考虑异常处理机制,确保在异常情况下能够正确地释放资源和处理数据。
通过以上策略和管理方式,可以有效地实现生产者消费者模式,提高系统的性能和稳定性
79、C和C++的区别是什么?
C是结构化语言,其重点是算法和数据结构,C++在C的基础上增加类。C程序考虑的是如何通过一个过程,对输入进行运算处理得到输出,而对于C++而言,首先考虑的是如何构造一个对象模型,使得该模型与之对应的问题域契合,就可以通过获取对象的状态信息得到输出或实现过程控制。
80、const的用途是什么?
const用来定义只读变量,也就是常量。
const修饰函数的参数和函数的返回值。
const修饰函数的定义体,这里的函数是类的成员函数,被const修饰的成员函数代表不修改成员变量的值。
(1)const修饰类的成员变量,表示成员常量,不能被修改。
(2)const修饰函数承诺在本函数内部修改类内的数据成员,调用其他非const成员函数。
(3)如果const构成函数重载,const对象只能调用const函数,非const对象优先调用非const函数。
(4)const函数只能调用const函数,非const函数可以调用const函数。
(5)类体外定义的const成员函数,在定义和声明外都需要const修饰符。
81、数组和链表有什么区别?
(1)在存储形式方面,数组是一块连续的空间,声明时就要确定长度;链表是一块可以不连续的动态空间,长度可以改变,每个结点都要保存相邻结点的指针。
(2)在数据查找方面,数组的线性查找速度快,查找操作直接使用偏移地址;链表需要按照顺序检索结点,效率较低。
(3)在数据的插入或删除方面,链表可以快速插入和删除结点,但数组需要大量的数据移动。
(4)在越界问题方面,链表不存在越界问题,数组存在越界问题。
(5)数组的优点:随机访问性强,查找速度快;数组的缺点:插入和删除效率低,可能浪费内存,内存空间要求高,必须有足够的连续空间,数组大小固定,不能动态拓展。链表的优点:插入删除速度快,内存利用率高,浪费内存,大小没有固定,拓展很灵活;链表的缺点:不能随机查找,必须从第一个开始遍历,查找效率低。
82、重载和重写的区别是什么?
重载指的是同一个访问区被声明的几个具有不同参数列(参数的类型,个数,顺序不同)的同名函数,根据参数列表确定调用哪个函数,重载不关心函数的返回类型。
重写指的是派生类中存在重新定义的函数,它的函数名,参数列表,返回值类型,所有都必须和基类中被重写的参数一致。只有函数体不同,派生类调用时会调用派生类的重写函数,调用被重写函数。重写的基类中被重写的挂不是关于不需要有virtual修饰。
83、常用的排序算法的优缺点和特点是什么?
(1)选择排序法的优点是移动数据的次数少,缺点是比较数据的次数多。
(2)冒泡排序法的优点是数据稳定,误差小,缺点是速度慢。
(3)快速排序是冒泡排序的一种改进,其优点是速度快,数据移动少,缺点是稳定性不足。
(4)希尔排序先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行依次直接插入排序。其优点是速度快,数据移动少,缺点是不稳定。
(5)归并算法是一种分治法排序,该算法比较稳定,一般用于对总体无序但局部有序的数列。其优点是效率较高,稳定,缺点是比较占用内存。
(6)堆排序在直接选择排序的基础上利用了比较结果。因此它的优点是效率提高很大,缺点是对数据的有序性不敏感。
84、快速排序使用代码简单实现
#include<iostream>
using namespace std;
int n,a[1000001];
void qsort(int l,int r)//应用二分思想
{
int mid=a[(l+r)/2];//中间数
int i=l,j=r;
do{
while(a[i]<mid) i++;//查找左半部分比中间数大的数
while(a[j]>mid) j--;//查找右半部分比中间数小的数
if(i<=j)//如果有一组不满足排序条件(左小右大)的数
{
swap(a[i],a[j]);//交换
i++;
j--;
}
}while(i<=j);//这里注意要有=
if(l<j)
qsort(l,j);//递归搜索左半部分
if(i<r)
qsort(i,r);//递归搜索右半部分
}
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
cin>>a[i];
qsort(1,n);
for(int i=1;i<=n;i++)
cout<<a[i]<<" ";
}85、构造函数初始化列表和直接在构造函数内初始化有什么区别?
在进入派生类的构造函数内的时候,基类的部分已经构造完成了,你没有使用成员初始化列表初始化基类,因此基类采用的是基类自己默认的构造函数初始化的,然后进入构造函数后,又使用基类的构造函数构造一次,说明基类部分构造了两次,肯定报错。在构造函数初始化赋值效率低,常数据成员的初始化必须在初始化列表里完成。
以下几种情况必须使用初始化列表去初始化类成员:
当初始化一个reference member时,即成员类型是引用。
当初始化一个const member时,即成员类型是常量。
当调用一个基类的constructor,而它拥有一组参数时。如果此时不使用列表初始化,那么就需要自己重载赋值运算符。
当调用一个类成员的constructor,而它拥有一组参数时。
若某个类成员没有定义无参构造函数,而定义了其它的构造函数,也必须使用初始化列表。
总之,为了标准化,建议使用列表初始化。不过小心一些陷阱:
因为类成员的初始化顺序不是按照初始化列表的顺序来的,而是按照类成员的声明顺序。
86、描述sizeof和strlen的区别
(1)sizeof 是一个操作符,strlen 是库函数。
(2)sizeof 的参数可以是数据的类型,也可以是变量,而 strlen 只能以结尾为‘\0‘的字符串作参数。
(3)编译器在编译时就计算出了 sizeof 的结果。而 strlen 函数必须在运行时才能计算出来。并且 sizeof 计算的是数据类型占内存的大小,而 strlen 计算的是字符串实际的长度。
(4)数组做 sizeof 的参数不退化,传递给 strlen 就退化为指针了。
注意:有些是操作符看起来像是函数,而有些函数名看起来又像操作符,这类容易混淆的名称一定要加以区分,否则遇到数组名这类特殊数据类型作参数时就很容易出错。最容易混淆为函数的操作符就是 sizeof。
87、strcpy、sprintf和memcpy的区别
(1) 操作对象不同,strcpy 的两个操作对象均为字符串,sprintf 的操作源对象可以是多种数据类型,目的操作对象是字符串,memcpy 的两个对象就是两个任意可操作的内存地址,并不限于何种数据类型。
(2) 执行效率不同,memcpy 最高,strcpy 次之,sprintf 的效率最低。
(3) 实现功能不同,strcpy 主要实现字符串变量间的拷贝,sprintf 主要实现其他数据类型格式到字符串的转化,memcpy 主要是内存块间的拷贝。
说明:strcpy、sprintf 与 memcpy 都可以实现拷贝的功能,但是针对的对象不同,根据实际需求,来选择合适的函数实现拷贝功能。
88、C++空类有哪些成员函数?
缺省构造函数、缺省拷贝构造函数、缺省析构函数、缺省赋值运算符、缺省取址运算符、缺省取地址运算符const。
this指针有哪些特性呢?
1)this是一个指针,它时时刻刻指向你这个实例本身。
2)this指针的类型类类型 *const
3)this指针并不是对象本身的一部分,不影响sizeof的结果
4)this指针的作用域在类成员函数的内部
5)只有在类的非静态成员函数中才可以使用,其它任何函数都不可以
89、对拷贝构造函数和赋值运算符的理解。
拷贝构造函数和赋值运算符重载有以下两个不同之处:
(1)拷贝构造函数生成新的类对象,而赋值运算符不能。
(2)由于拷贝构造函数是直接构造一个新的类对象,所以在初始化这个对象之前不用检验源对象是否和新建对象相同。而赋值运算符则需要这个操作,另外赋值运算中如果原来的对象中有内存分配要先把内存释放掉
注意:当有类中有指针类型的成员变量时,一定要重写拷贝构造函数和赋值运算符,不要使用默认的。
90、描述类成员函数的重写、重载和隐藏的区别。
(1)重写和重载主要有以下几点不同。
范围的区别:被重写的和重写的函数在两个类中,而重载和被重载的函数在同一个类中。
参数的区别:被重写函数和重写函数的参数列表一定相同,而被重载函数和重载函数的参数列表一定不同。
virtual的区别:重写的基类中被重写的函数必须要有virtual 修饰,而重载函数和被重载函数可以被virtual修饰,也可以没有。
(2)隐藏和重写、重载有以下几点不同。
与重载的范围不同:和重写一样,隐藏函数和被隐藏函数不在同一个类中。
参数的区别:隐藏函数和被隐藏的函数的参数列表可以相同,也可不同,但是函数名肯定要相同。当参数不相同时,无论基类中的参数是否被 virtual 修饰,基类的函数都是被隐藏,而不是被重写。
说明:虽然重载和覆盖都是实现多态的基础,但是两者实现的技术完全不相同,达到的目的也是完全不同的,覆盖是动态态绑定的多态,而重载是静态绑定的多态。
91、多态实现的原理。
编译器发现一个类中有虚函数,便会立即为此类生成虚函数表 vtable。虚函数表的各表项为指向对应虚函数的指针。编译器还会在此类中隐含插入一个指针 vptr(对 vc 编译器来说,它插在类的第一个位置上)指向虚函数表。调用此类的构造函数时,在类的构造函数中,编译器会隐含执行 vptr 与 vtable 的关联代码,将 vptr 指向对应的 vtable,将类与此类的 vtable 联系了起来。另外在调用类的构造函数时,指向基础类的指针此时已经变成指向具体的类的this指针,这样依靠此this指针即可得到正确的vtable。
如此才能真正与函数体进行连接,这就是动态联编,实现多态的基本原理。
注意:一定要区分虚函数,纯虚函数、虚拟继承的关系和区别。牢记虚函数实现原理,因为多态。
92、队列和栈的区别。
队列和栈都是线性存储结构,但是两者的插入和删除数据的操作不同,队列是“先进先出”,栈是“后进先出”。
注意:区别栈区和堆区。堆区的存取是“顺序随意”,而栈区是“后进先出”。栈由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。堆一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。分配方式类似于链表。
栈用于表达式求值,函数调用的调用栈,括号匹配,队列则用于任务调度,缓冲区管理,消息传递。
93、typedef和define有什么区别?
(1)用法不同:typedef 用来定义一种数据类型的别名,增强程序的可读性。define 主要用来定义常量,以及书写复杂使用频繁的宏。
(2)执行时间不同:typedef 是编译过程的一部分,有类型检查的功能。define 是宏定义,是预编译的部分,其发生在编译之前,只是简单的进行字符串的替换,不进行类型的检查。
(3)作用域不同:typedef 有作用域限定。define 不受作用域约束,只要是在 define 声明后的引用都是正确的。
(4)对指针的操作不同:typedef 和 define 定义的指针时有很大的区别。
注意:typedef 定义是语句,因为句尾要加上分号。而 define 不是语句,千万不能在句尾加分号。
94、指针常量和常量指针的区别。
指针常量是指定义了一个指针,这个指针的值只能在定义时初始化,其他地方不能改变。常量指针是指定义了一个指针,这个指针指向一个只读的对象,不能通过常量指针来改变这个对象的值。
指针常量强调的是指针的不可改变性,而常量指针强调的是指针对其所指对象的不可改变性。
注意:无论是指针常量还是常量指针,其最大的用途就是作为函数的形式参数,保证实参在被调用函数中的不可改变特性。
95、如何避免“野指针“?
“野指针”产生原因及解决办法如下:
(1)指针变量声明时没有被初始化。解决办法:指针声明时初始化,可以是具体的地址值,也可让它指向 NULL。
(2)指针p被 free 或者 delete 之后,没有置为 NULL。解决办法:指针指向的内存空间被释放后指针应该指向 NULL。
(3)指针操作超越了变量的作用范围。解决办法:在变量的作用域结束前释放掉变量的地址空间并且让指针指向 NULL。
野指针的解决方法也是编程规范的基本原则,平时使用指针时一定要避免产生“野指针”,在使用指针前一定要检验指针的合法性。
96、常引用的作用。
常引用的引入主要是为了避免使用变量的引用时,在不知情的情况下改变变量的值。常引用主要用于定义一个普通变量的只读属性的别名、作为函数的传入形参,避免实参在调用函数中被意外的改变。
说明:很多情况下,需要用常引用做形参,被引用对象等效于常对象,不能在函数中改变实参的值,这样的好处是有较高的易读性和较小的出错率。
97、构造函数能否为虚函数?
构造函数不能是虚函数。而且不能在构造函数中调用虚函数,因为那样实际执行的是父类的对应函数,因为自己还没有构造好。析构函数可以是虚函数,而且,在一个复杂类结构中,这往往是必须的。
析构函数也可以是纯虚函数,但纯虚析构函数必须有定义体,因为析构函数的调用是在子类中隐含的。
说明:虚函数的动态绑定特性是实现重载的关键技术,动态绑定根据实际的调用情况查询相应类的虚函数表,调用相应的虚函数。
99、一个指针可以是volatile吗?
可以,因为指针和普通变量一样,有时也有变化程序的不可控性。常见例:子中断服务子程序修改一个指向一个 buffer 的指针时,必须用 volatile 来修饰这个指针。
指针是一种普通的变量,从访问上没有什么不同于其他变量的特性。其保存的数值是个整型数据,和整型变量不同的是,这个整型数据指向的是一段内存地址。
100、变量的声明和定义有什么区别?
为变量分配地址和存储空间的称为定义,不分配地址的称为声明。一个变量可以在多个地方声明,但是只在一个地方定义。加入 extern 修饰的是变量的声明,说明此变量将在文件以外或在文件后面部分定义。说明:很多时候一个变量,只是声明不分配内存空间,直到具体使用时才初始化,分配内存空间,如外部变量。
101、结构体struct内存对齐的三大规则
(1)对于结构体的各个成员,第一个成员的偏移量是0,排列在后面的成员其当前偏移量必须是当前成员类型的整数倍;
(2)结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍;
(3)如程序中有#pragma pack(n)预编译指令,则所有成员对齐以n字节为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型。
102、联合体union内存对齐的2大原则
(1)找到占用字节最多的成员;
(2)union的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员
103、位域
C语言允许在一个结构体中以位为单位来指定其成员所占内存长度,这种以位为单位的成员称为“位段”或称“位域”( bit field) 。利用位段能够用较少的位数存储数据。一个位段必须存储在同一存储单元中,不能跨两个单元。如果第一个单元空间不能容纳下一个位段,则该空间不用,而从下一个单元起存放该位段。
(1)位段声明和结构体类似
(2)位段的成员必须是int、unsigned int、signed int
(3)位段的成员名后边有一个冒号和一个数字
104、attribute((packed))取消对齐
GNU C的一大特色就是__attribute__机制。__attribute__可以设置函数属性(Function Attribute)、变量属性(Variable Attribute)和类型属性(Type Attribute)。
__attribute__书写特征是:__attribute__前后都有两个下划线,并且后面会紧跟一对括弧,括弧里面是相应的__attribute__参数。
跨平台通信时用到。不同平台内存对齐方式不同。如果使用结构体进行平台间的通信,会有问题。例如,发送消息的平台上,结构体为24字节,接受消息的平台上,此结构体为32字节(只是随便举个例子),那么每个变量对应的值就不对了。不同框架的处理器对齐方式会有不同,这个时候不指定对齐的话,会产生错误结果
105、inline内联函数
在C语言中,如果一些函数被频繁调用,不断地有函数入栈,即函数栈,会造成栈空间或栈内存的大量消耗。为了解决这个问题,特别的引入了inline修饰符,表示为内联函数。
大多数的机器上,调用函数都要做很多工作:调用前要先保存寄存器,并在返回时恢复,复制实参,程序还必须转向一个新位置执行。C++中支持内联函数,其目的是为了提高函数的执行效率,用关键字 inline 放在函数定义(注意是定义而非声明)的前面即可将函数指定为内联函数,内联函数通常就是将它在程序中的每个调用点上“内联地”展开。
内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。
在C++中,多态(Polymorphism)是指一种机制,使得基类的指针或引用可以用来调用派生类的函数,从而实现对不同数据类型的统一操作。多态主要通过以下两种方式实现:
编译时多态(静态多态):
1.函数重载(Function Overloading):多个同名函数但参数列表不同。
2.运算符重载(Operator Overloading):重载运算符以适应不同的数据类型。
class Print {
public:
void display(int i) {
std::cout << "Integer: " << i << std::endl;
}
void display(double d) {
std::cout << "Double: " << d << std::endl;
}
};
运行时多态
虚函数(Virtual Functions):通过基类指针或引用调用派生类的函数。实现需要使用关键字 virtual。
class Base {
public:
virtual void show() {
std::cout << "Base class" << std::endl;
}
};
class Derived : public Base {
public:
void show() override {
std::cout << "Derived class" << std::endl;
}
};
int main() {
Base* b;
Derived d;
b = &d;
b->show(); // 输出:Derived class
return 0;
}在这个例子中,基类 Base 中的函数 show 被声明为虚函数(virtual),这样在调用 b->show() 时,会动态地绑定到派生类 Derived 的 show 函数,实现了运行时多态。
106、C++所有的构造函数都有什么?
构造函数的特点:
函数名与类名相同
这是构造函数最重要的特点之一。例如,对于类MyClass,其构造函数的名字必须是MyClass。这种命名规则使得编译器能够在创建对象时准确地识别出应该调用的构造函数。
在对象创建时自动调用
当创建一个类的对象时,相应的构造函数会自动被调用。这个调用过程是由编译器在后台完成的。
没有返回值类型(包括void)
构造函数不能指定返回值类型,这是因为构造函数的主要目的是初始化对象,而不是返回一个值。它的任务是在对象创建时为对象的成员变量分配内存空间并进行初始化。
可以用于初始化成员变量
构造函数的主要用途之一是初始化对象的成员变量。可以在构造函数的函数体中或者使用初始化列表来完成成员变量的初始化。
可以有多个重载形式
可以根据不同的参数列表来定义多个构造函数,这就是构造函数的重载。这样可以通过不同的方式初始化对象。
C++中的构造函数分类:
默认构造函数
定义:用于创建对象并初始化其成员。如果类中没有定义任何构造函数,编译器会自动生成一个默认构造函数。这个默认构造函数会对类中的基本数据类型成员进行默认初始化(例如,int型成员初始化为 0,指针型成员初始化为nullptr)。
例子:
class MyClass {
public:
int num;
// 这是一个默认构造函数
MyClass() {
num = 0;
}
};
int main() {
MyClass obj;
return 0;
}在这个例子中,MyClass类有一个默认构造函数。当在main函数中创建obj对象时,默认构造函数被调用,将num成员初始化为 0。
带参数的构造函数
定义:带参数的构造函数允许在创建对象时传递参数,用于初始化对象的成员。通过这种方式,可以根据不同的参数值来创建具有不同初始状态的对象。例:
class Rectangle {
public:
int width;
int height;
Rectangle(int w, int h) {
width = w;
height = h;
}
};
int main() {
Rectangle rect(5, 3);
return 0;
}这里的Rectangle类有一个带两个参数的构造函数。在main函数中创建rect对象时,传递了两个参数 5 和 3,分别用于初始化width和height成员。
拷贝构造函数
定义:用于创建一个新对象,这个新对象是另一个现有对象的副本。当使用一个已存在的对象来初始化一个新对象时,拷贝构造函数会被调用。例:
class Point {
public:
int x;
int y;
Point(int a, int b) : x(a), y(b) {}
// 拷贝构造函数
Point(const Point& other) {
x = other.x;
y = other.y;
}
};
int main() {
Point p1(2, 3);
Point p2 = p1;
return 0;
}在这个例子中,Point类有一个拷贝构造函数。当执行Point p2 = p1;语句时,拷贝构造函数被调用,将p1对象的x和y成员的值复制到p2对象中。
107、析构函数可以是虚函数吗?
1.析构函数可以是虚函数
2.为什么需要虚析构函数
避免资源泄漏:如果析构函数不是虚函数,当通过基类指针删除派生类对象时,只会调用基类的析构函数,而派生类中特有的资源(如动态分配的内存)将被正确释放,从而导致资源泄漏。
多态销毁对象:虚析构函数支持多态行为。在面向对象编程中,多态允许通过基类指针或引用来操作派生类对象。虚析构函数确保在销毁对象时,能够根据对象的实际类型(派生类类型)来调用正确的析构函数序列。
3.注意事项
虽然析构函数可以是虚函数,但也不是所有情况都需要将析构函数定义为虚函数。如果一个类被用作基类(即有派生类),那么将其析构函数定义为虚函数是不必要的,因为这会增加一些额外的开销(主要是虚函数表的维护开销)。
例如,一个简单的只用于存储数据的类:
class SimpleData {
public:
int data;
~SimpleData() {
}
};在这里,SimpleData类的析构函数不需要是虚函数,因为这个类被用作基类,不存在通过基类指针删除派生类对象的情况。
108、拷贝构造函数?浅拷贝深拷贝区别?
拷贝构造函数是一种特殊的构造函数,用于创建一个新对象,这个新对象是另一个现有对象的副本。它的主要功能是用一个已存在的同类型对象来初始化新创建的对象。拷贝构造函数自动调用情况:
用一个已存在的对象初始化一个新定义的对象。例如:MyClass newObj(existingObj);
函数参数按值传递对象时。例如:void func(MyClass obj);当调用func(existingObj)时,会调用拷贝构造函数来创建obj。
函数返回一个对象时。例如,在函数MyClass func()中返回一个局部对象,会调用拷贝构造函数来返回一个副本。
语法:拷贝构造函数的参数通常是一个常引用(const T&,其中T是类名),这是为了避免在参数传递过程中进行不必要的拷贝。其函数名与类名相同,且没有返回值类型(包括void)。例如:
class MyClass {
public:
MyClass(const MyClass& other) {
// 拷贝操作的具体实现
}
};深拷贝与浅拷贝
浅拷贝:如果拷贝构造函数只是简单地将源对象的成员变量的值复制到目标对象中,而这些成员变量包含指针类型,那么就只是复制了指针的值,而不是指针所指向的数据。这种情况称为浅拷贝。浅拷贝可能会导致问题,例如两个对象的指针成员指向同一块内存,当其中一个对象释放这块内存时,另一个对象的指针就会变成悬空指针。
深拷贝:深拷贝会为目标对象的指针成员分配新的内存,并将源对象指针所指向的数据复制到新分配的内存中。避免了两个对象的data指针共享同一块内存的问题。
1.请你说说虚函数的是怎样工作的,大概流程是什么?
定义虚函数首先,在基类中使用关键字virtual来声明一个虚函数。
继承和重写(覆盖)虚函数当一个类继承自包含虚函数的基类时,派生类可以选择重写(覆盖)基类中的虚函数。
通过基类指针或引用调用虚函数(多态性体现)
虚函数表(v - table)机制当一个类包含虚函数时,编译器会为这个类创建一个虚函数表。虚函数表是一个函数指针数组,其中每个元素指向一个虚函数的实现。对于每个包含虚函数的类的对象,对象内存布局的开头会有一个隐藏的指针(通常称为vptr),它指向类的虚函数表。当通过基类指针或引用调用虚函数时,程序会根据对象的vptr找到对应的虚函数表,然后在虚函数表中查找并调用正确的函数。
动态绑定和多态当子类继承了父类的时候,子类对象也会继承父类的虚函数表。当子类重写(override)父类中的虚函数时,会将虚函数表中对应的函数地址替换为子类的虚函数地址,从而实现了动态绑定和多态。
109、纯虚函数?
纯虚函数(Pure Virtual Function)是在基类中声明但没有提供实现的虚函数。它的声明形式为在函数原型后面加上= 0。例:
class Shape {
public:
virtual double area() = 0;
// 这是一个纯虚函数,意味着在Shape类中没有area函数的具体实现
};纯虚函数在基类中起到以下作用:
接口定义:纯虚函数主要用于定义接口。它可以让多个不同的派生类遵循相同的函数接口规范,使得程序能够以统一的方式处理不同类型的对象。例如,在图形处理程序中,可以有多种图形(如圆形、三角形等),通过定义Shape抽象类中的纯虚函数area,可以确保每个图形类都有计算面积的功能,并且接口统一。
多态性和抽象设计:可以通过基类指针或引用调用纯虚函数,根据对象的实际类型(在运行时确定)来执行相应派生类中的函数实现。这种抽象设计方式可以提高代码的可维护性和可扩展性。例如:在一个绘图系统中,可能会有一个函数接收Shape类型的引用,然后调用area函数来计算要绘制的图形的面积,不管这个图形是矩形、圆形还是其他自定义的图形,只要它是Shape的派生类并且正确实现了area函数,这个函数都能正确工作。
110、多态?多态是需要满足的条件以及优缺点是什么?
多态(Polymorphism)是面向对象编程中的一个重要概念,多态就是不同对象对同一行为会有不同的状态。
是指在面向对象编程中,子类对象可以以父类引用的方式存在,从而实现用父类接口调用子类方法的功能。
例如,有一个 “动物” 基类,它有 “发出声音” 的行为。“狗”和“猫” 是 “动物” 的派生类,它们都继承了 “发出声音” 这个行为。但是狗的叫声是 “汪汪”,猫的叫声是 “喵喵”。当使用一个统一的方式(比如调用 “发出声音” 这个函数)来处理狗和猫的对象时,它们会表现出不同的行为,这就是多态。
实现多态需要满足的条件:
虚函数:基类中被派生类重写的函数必须被声明为虚函数。使用virtual关键字来定义虚函数。
继承关系:存在基类(父类)和派生类(子类)之间的继承关系。
基类指针或引用调用虚函数:可以创建基类指针或引用,让它们指向派生类对象,然后通过这些指针或引用调用虚函数。在运行时,会根据对象的实际类型来调用相应的函数。
优点:
提高代码的可维护性和可扩展性,使代码可以重复利用,并且易于添加新功能。
增强程序的灵活性和通用性,统一接口处理多种类型。
缺点:
性能开销较大,存在虚函数表和虚指针对内存占用,并且动态绑定的时间成本。
增加代码的复杂性,多态的实现涉及到虚函数、派生类的重写、基类指针或引用等概念,这使得代码的结构和逻辑相对复杂。
111、继承是如何实现的?
继承是面向对象编程中的一个重要概念,它允许创建一个新类(称为派生类或子类),这个新类可以从一个现有的类(称为基类或父类)获取属性(成员变量)和行为(成员函数)。这就好比子女继承父母的特征一样,派生类继承基类的特性,并且可以在这个基础上添加新的属性和行为,或者修改从基类继承来的属性和行为。
继承的实现语法格式使用:(冒号)和public(或private、protected)关键字来实现继承。public表示公有继承,private表示私有继承,protected表示受保护继承。例如:
class Vehicle {
// 基类的成员变量和成员函数定义
};
class Car : public Vehicle {
// 派生类Car从Vehicle公有继承
// 可以在这里添加新的成员变量和成员函数,并且可以访问Vehicle类的公有和受保护成员
};成员访问控制
公有继承:使用public关键字来指定基类与派生类之间的继承关系。在公有继承中,基类的公有成员在派生类中仍然是公有成员,基类的受保护成员在派生类中仍然是受保护成员,基类的私有成员在派生类中不可直接访问。例如,对于上面的Vehicle和Car类,如果Vehicle类有一个公有函数getSpeed(),在Car类中可以直接调用这个函数。
私有继承:使用protected关键字基类的公有成员和受保护成员在派生类中都变为私有成员。这种继承方式在实际应用中相对较少使用,因为它会限制派生类对象对基类成员的访问。例如,如果Car类是私有继承自Vehicle,那么Vehicle类的公有函数getSpeed()在Car类中虽然可以访问,但在Car类外部通过Car类对象将无法访问getSpeed()函数。
保护继承:使用protected关键字基类的公有成员在派生类中变为受保护成员,基类的受保护成员在派生类中仍然是受保护成员。这种继承方式用于当希望派生类能够访问基类的成员,但又不希望外部通过派生类对象访问这些成员的情况。
112、虚继承,如何实现的?
虚继承的定义
虚继承是一种在多重继承中解决菱形继承问题的机制。当一个派生类从多个基类派生,而这些基类又有一个共同的基类时,就会出现菱形继承结构。例如,有类 A,类 B 和类 C 都继承自 A,然后类 D 同时继承自 B 和 C,这种结构形状类似菱形。在这种情况下,如果没有虚继承,就可能会导致类 D 中包含两份来自 A 的成员(数据成员和函数成员),这会带来数据冗余和潜在的二义性问题。
虚继承通过在继承时使用特定的关键字(在 C++ 中是virtual关键字)来确保在派生类中只有一份共同基类的成员副本。
例:
class Base {
// 基类成员定义
};
class Derived1 : virtual public Base {
// 派生类1的成员定义
};
class Derived2 : virtual public Base {
// 派生类2的成员定义
};
class FinalDerived : public Derived1, public Derived2 {
// 最终派生类的成员定义
};在这个例子中,Base是虚基类,Derived1和Derived2虚继承自Base,然后FinalDerived继承自Derived1和Derived2。这样,在FinalDerived类中只会有一份Base类的成员副本,避免了数据冗余。
113、构造函数
构造函数是一种特殊的成员函数,用于在创建对象时初始化对象的成员变量。它与类同名,没有返回值类型(包括void)。当创建一个类的对象时,构造函数会自动被调用,以确保对象在使用前处于一个合理的初始状态。
例如,对于一个表示二维点的类Point,构造函数可以用于初始化点的x和y坐标:
class Point {
public:
int x;
int y;
Point(int a, int b) {
x = a;
y = b;
}
};在这里,Point(int a, int b)就是Point类的构造函数,当创建Point类的对象时,如Point p(3, 4);,构造函数会被调用,将p的x坐标初始化为 3,y坐标初始化为 4。
默认构造函数
如果一个类没有定义任何构造函数,编译器会自动生成一个默认构造函数。这个默认构造函数会对类的成员变量进行默认初始化(对于基本数据类型,如int、double等会初始化为 0 或类似的默认值;对于类类型成员,会调用其默认构造函数)。
构造函数的作用
对象初始化:构造函数确保对象的成员变量在创建时被正确初始化,这对于程序的正确性和稳定性至关重要。如果对象的成员变量没有初始化,可能会导致程序出现未定义行为,如访问未初始化的内存地址导致程序崩溃或产生错误的计算结果。
资源分配和初始化相关操作:在构造函数中,除了初始化成员变量,还可以进行一些其他的操作,如动态内存分配(例如,在构造函数中使用new关键字为对象的成员指针分配内存)、打开文件、连接数据库等操作,以确保对象在使用前已经完成了所有必要的准备工作。
114、析构函数?
析构函数是一种特殊的成员函数,主要用于在对象销毁时执行清理工作。它的名字是在类名前面加上一个波浪号(~),并且没有返回值类型,也不能有参数。
例如,对于一个简单的类MyClass,析构函数可以这样定义:
class MyClass {
public:
~MyClass() {
// 这里进行清理工作
}
};自动调用机制 :
析构函数会在对象生命周期结束时自动被调用。对象生命周期结束的情况有多种。
局部对象:当一个局部对象(在函数内部定义的对象)所在的函数执行结束时,这个对象就会被销毁,析构函数会被调用。例如:
void myFunction() {
MyClass obj;
// 函数体部分
}
// 当myFunction函数执行结束,obj的析构函数会被调用动态分配的对象被释放:如果使用new关键字在堆上创建了一个对象,当使用delete关键字删除这个对象时,析构函数会被调用。例如:
MyClass* ptr = new MyClass();
// 使用ptr指向的对象
delete ptr;
// 此时ptr指向对象的析构函数会被调用清理工作的内容:
释放资源:最常见的用途是释放对象在生命周期内占用的资源。
释放动态分配的内存:如果对象在构造函数或者其他成员函数中使用new操作符分配了内存,析构函数就需要使用delete操作符来释放这些内存。
115、构造函数和析构函数在继承中的情况?
构造函数:派生类的构造函数需要调用基类的构造函数来初始化从基类继承来的成员。如果没有在派生类构造函数中显式地调用基类构造函数,编译器会尝试调用基类的默认构造函数。例如:
class Vehicle {
public:
Vehicle(int s) : speed(s) {}
int speed;
};
class Car : public Vehicle {
public:
Car(int s, int n) : Vehicle(s), numberOfSeats(n) {}
int numberOfSeats;
};这里Car类的构造函数通过Vehicle(s)显式地调用了基类Vehicle的构造函数来初始化从Vehicle继承来的speed成员,同时初始化自己的numberOfSeats成员。
析构函数:在继承关系中,当派生类对象销毁时,析构函数的调用顺序是先调用派生类的析构函数,然后调用基类的析构函数。这是为了确保对象的成员按照正确的顺序释放资源。例如,在Car类对象销毁时,先执行Car类的析构函数,清理Car类自己分配的资源,然后执行Vehicle类的析构函数,清理从Vehicle类继承来的资源。
116、说说操作符重载?哪些操作符不能重载?
操作符重载,就是把已经定义的、有一定功能的操作符进行重新定义,来完成更为细致具体的运算等功能。
在 C++中,当用户定义了类的对象时,两个对象之间是不能进行内置类型的操作符运算的,比如两个自定义类的对象相加,如果没有重载+运算符就会出错。但 C++允许用户把这些运算符添加到自己的类中以方便类对象之间的运算,就像内置类型的运算一样方便。
可以重载的运算符:
算数运算符
自增自减
比较运算
位运算
赋值运算
不能被重载的运算符:
成员选择操作符(.):无法改变点操作符的行为。点运算符“.”不能重载是为了保证访问成员的功能不能被改变
sizeof:它是一个关键字,无法重载。
typeid:它是一个运算符,无法重载。
条件运算符(?:):无法改变条件运算符的行为。条件运算符“?:”不能重载是因为如果能够重载,该运算符的本意是执行 exp2 和 exp3 中的一个,可是重载后,不能保证只执行了一个,还是说两个都能执行?亦或两条都不能执行?
展开操作符(::):它用于指定作用域,不能被重载。域解析符“::”不能重载是因为它只是在编译的时候进行域解析,而没有运算的参与进来。如果重载之后,“::”运算符有了新的语义,那会引起混淆。
117、在C++中重写、重载和隐藏的区别是什么?
重写(Override):
重写是指子类重新定义从父类继承的虚函数,使其具有不同的实现。
重写的函数签名(函数名、参数列表和返回类型)必须与被重写函数相同。
在运行时,根据具体的对象类型,调用的是子类重写的版本。例如,“// 父类 classA { public:virtual int fun (int a){} };// 子类 classB : public A { public:virtual int fun (int a) override {} }”。重写是父类和子类之间的垂直关系,在重写关系中,调用方法根据对象类型决定。
重载(Overloading):
函数名相同但参数列表(类型、个数、顺序)不同,返回值类型无要求
隐藏(Hiding):
隐藏是指在派生类中定义与父类具有相同名称的成员函数,使其隐藏父类中的同名函数。
隐藏函数与父类的函数没有多态性,只有通过对象的实际类型调用时才会调用相应的函数。举个例子:// 父类 classA { public:void fun (int a){ cout << "A 中的 fun 函数" << endl;} };// 子类 classB : public A { public:// 隐藏父类的 fun 函数 void fun (int a){ cout << "B 中的 fun 函数" << endl;} }”。总结,重写发生在不同的类之间且要求严格,重载发生在同一个类内,隐藏发生在不同类间
118、关于虚函数表的注意事项
每个含有虚函数的类都有一个虚函数表,表中存放着虚函数的地址。当通过基类指针或引用调用虚函数时,实际上是通过虚函数表来找到正确的函数地址进行调用。
虚函数表只有一份,而有多少个对象,就对应多少个虚函数表指针。
静态成员函数不能是虚函数,因为静态成员函数不受限与某个对象。
inline 函数不能是虚函数,因为 inline 函数是不能在运行中动态确定其位置的,即使虚函数在类的内部定义,编译时,仍将其视为非 inline 的。
使用虚函数,系统要有一定的空间开销,当一个类带有虚函数时,编译器会为该类构造一个虚函数表,虚函数表在编译时候就已经生成了。它是一个指针数组,存放每个虚函数的入口地址。
119、虚函数?虚函数存在哪?虚函数的优点有哪些?
虚函数是在普通函数前面加了 virtual 关键字的成员函数,在某基类中声明为 virtual 并在一个或多个派生类中被重新定义,实现多态性,通过指向派生类的基类指针或引用,访问派生类中同名覆盖成员函数。
关于虚函数的存在位置,虚函数表是与类关联的,一个类只有一张虚函数表。虚函数和普通函数一样的,都是存在代码段的。
优点:
实现多态性:通过使用虚函数,可以创建一个统一接口,以便处理具有不同类型但具有相似功能和行为的对象。
简化代码逻辑:通过将通用操作放在基类中定义,并使用派生类覆盖特定功能,可以减少代码冗余并提高可维护性。
扩展性和灵活性:通过添加新的派生类并覆盖虚函数,可以轻松地扩展和修改现有的代码结构。
120、虚函数如何实现多态性?
虚函数是 C++ 中实现多态的重要机制。多态就是用父类型别的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数,让父类的指针有 “多种形态”。
例:有基类 A 和派生类 B,A 中有虚函数 print,B 重写了这个函数。在主函数中,先创建 A 和 B 的对象,然后用 A * 类型的指针分别指向 A 和 B 的对象,调用 print 函数时,如果 A 的 print 不是虚函数,那么无论指针指向的是哪个对象,都只会调用 A 的 print 函数;但当 A 的 print 是虚函数时,根据指针实际指向的对象来调用相应的函数,即如果指针指向 B 的对象,就会调用 B 重写后的 print 函数,从而实现多态性。
121、extern的作用
extern是C和C++语言中的一个关键字,主要用于声明变量或函数是在当前源文件外部定义的
声明外部变量:
当一个全局变量在另一个源文件中定义时,如果想在当前源文件中访问该变量,可以使用extern关键字进行声明。这告诉编译器该变量的定义在其他文件中,当前文件只是引用它。
声明外部函数:
同样地,如果一个函数在另一个源文件中定义,而当前源文件需要调用该函数,也可以使用extern进行声明(尽管对于函数来说,extern是可选的,因为函数默认就是extern的)。这有助于在多个文件中共享函数的声明,而不必在每个文件中都重新定义函数。
122、面向对象和面向过程的区别
面向对象以对象为核心:将相关的数据和方法组织为一个整体,即对象。对象包含数据和行为,通过调用对象的方法或属性来实现功能。面向对象更关注事物的自然运行模式,将现实世界的事物抽象成对象,现实世界中的关系抽象成类、继承等。
面向过程以过程为核心,按照完成一个步骤或事件的过程来进行编程。它关注的是解决问题所需的步骤,并使用函数将这些步骤逐一实现。
123、类和对象联系与区别
联系
抽象与具体:类是一个模板或蓝图,是对一类事物的抽象描述,它定义了对象的属性和行为。对象则是类的具体化或实例,是类的一个实际存在。对象是类的实例,通过类可以创建出具有相同属性和行为的多个对象。
属性与行为:类中定义了对象的属性和行为(方法)。属性是对象的状态或特征,而行为是对象可以执行的操作或功能。对象继承了类中的属性和行为,并可以具有自己独特的状态和行为(如果类允许的话)。
内存中的存在:当类被定义时,它本身并不占用内存空间,因为它只是一个抽象的概念。但是,当通过类创建对象时,对象会在内存中占用一定的空间来存储其属性和状态。
区别
抽象与具体性:类是一个抽象的概念,它不存在于现实中的时间、空间里。类只是为所有的对象定义了抽象的属性和行为。对象则是具体的、实实在在存在的东西。每一个对象都存在着有别于其它对象的属于自己的独特的属性和行为。
静态与动态:类是一个静态的概念。在没有为类创建任何对象之前,类本身不存在于内存空间中。它只是一个定义或模板。对象是一个动态的概念。对象的属性可以随着它自己的行为而发生改变。对象在内存中占用空间,并可以与其他对象进行交互。
定义与实例化:类是用于创建对象的蓝图或模板。它定义了对象的属性和行为。
对象是通过类实例化得到的。在实例化过程中,会根据类的定义在内存中分配空间来存储对象的属性和状态。
用途与功能:
类的主要用途是定义对象的属性和行为,以及提供创建对象的机制。
对象的主要功能是执行类的行为(方法),并存储其独特的属性和状态。对象可以与其他对象进行交互,以实现更复杂的功能。
124、匿名函数
匿名函数,也被称为lambda函数或lambda表达式,是一种没有具体名称的函数。它们通常用于需要函数对象的地方,但又不想在程序中显式定义一个完整的函数。匿名函数提供了一种简洁的方式来编写简单的函数。
可读性:虽然匿名函数提供了简洁性,但它们可能会降低代码的可读性。特别是当匿名函数变得复杂时,理解它们的逻辑可能会变得更加困难。
调试:由于匿名函数没有名称,因此在调试过程中可能会更加困难。当需要跟踪或修改函数的行为时,命名函数通常更容易处理。
用途限制:匿名函数通常用于简单的、一次性的函数。对于更复杂的逻辑,建议使用命名函数来提高代码的可读性和可维护性。
125、浅拷贝深拷贝
拷贝操作指的是复制数据或对象的过程
浅拷贝指的是创建一个新的对象,这个新对象与原对象共享内存中的引用类型成员(比如指针、引用、动态分配的内存等)。换句话说,浅拷贝只复制了对象本身和值类型成员,而没有复制引用类型成员所指向的数据。因此,如果原对象中的引用类型成员被修改,浅拷贝得到的新对象中的对应成员也会受到影响,因为它们指向的是同一个数据。
深拷贝则不同,它不仅复制了对象本身和值类型成员,还递归地复制了对象中的所有引用类型成员所指向的数据。这样,新对象与原对象在内存中是完全独立的,修改新对象不会影响原对象,反之亦然。深拷贝通常比浅拷贝更耗时,因为它需要复制更多的数据
126、序列化和反序列化
序列化和反序列化主要涉及到将对象状态转换为可存储或可传输的格式,以及将这种格式还原为对象状态的过程。
序列化(Serialization)是指将对象的状态信息转换为可以存储或传输的形式的过程。这种形式通常是一个字节流,它包含了对象的类型信息和属性值等。序列化的主要目的是:
持久化保存对象:通过序列化,可以将对象的状态保存到文件中或数据库中,以便在需要时重新加载。
网络传输:序列化后的对象可以通过网络传输给远程主机,远程主机再通过反序列化将其还原为对象。
远程调用:在分布式系统中,序列化常用于实现远程方法调用(RPC),即将方法调用和参数序列化为字节流发送给远程服务,远程服务再反序列化并执行相应的方法。
反序列化(Deserialization)是指将序列化后的字节流还原为对象状态的过程。它是序列化的逆操作。通过反序列化,可以从存储的字节流中恢复对象的状态,或者在接收到序列化后的字节流后,将其转换为可操作的对象。
版本兼容性:在序列化和反序列化过程中,要保证被序列化和反序列化的类具有相同的serialVersionUID值(如果定义了的话)。serialVersionUID是用于验证版本一致性的版本号,如果类在序列化后发生了变化(如字段的增减、类型的改变等),可能会导致反序列化时抛出异常。
安全性:反序列化过程可能引发安全风险,因为攻击者可能会构造恶意的序列化数据来攻击系统。因此,在反序列化时要确保字节序列的来源是可信的。
静态字段和transient标记的字段:在序列化过程中,静态字段和用transient关键字标记的字段不会被序列化。静态字段属于类本身,而不是类的实例,因此不需要序列化。而transient关键字用于指示某个字段在序列化时应该被忽略。
总的来说,序列化和反序列化是实现对象状态持久化、网络传输和远程调用的重要手段。在使用它们时,需要注意版本兼容性、安全性和字段的序列化规则等问题。
127、int和float区别
int:用于存储整数。
float:用于存储浮点数,即带有小数部分的数。
int占用的内存少于float(在大多数现代平台上,int通常是32位,而float也是32位,但int的存储效率可能更高,因为整数可以更有效地利用内存)。
128、函数指针和指针函数区别
函数指针:
定义:函数指针是指向函数的指针。它存储了函数的地址,因此可以通过该指针调用函数。在C语言中,函数指针的声明通常类似于返回类型 (*指针名)(参数类型)。例如,int (*funcPtr)(int)是一个指向接受一个int参数并返回int的函数的指针。
函数指针常用于回调函数、实现函数表(函数指针数组)等高级编程技术。
指针函数是返回指针的函数。它本身是一个函数,其返回类型是某种类型的指针。
在C语言中,指针函数的声明通常类似于返回类型的指针 (*函数名)(参数类型)。但更常见的写法是省略括号中的*与函数名之间的空格,如返回类型的* 函数名(参数类型)。例如,int* createArray(int size)是一个创建并返回一个指向int数组的指针的函数。指针函数常用于动态内存分配、创建复杂数据结构(如链表、树等)时返回指向这些结构的指针。
函数指针是指向函数的指针,用于存储和调用函数的地址。
指针函数是返回指针的函数,其返回类型是指针,用于返回动态分配的内存或指向其他数据结构的指针
129、tcp通过什么保证稳定性?
TCP协议是面向连接的,可靠的,基于字节流的传输层协议,通过检验和序列号、确认应答、重发控制、连接管理及窗口控制等实现。
130、如何处理tcp的粘包问题
TCP粘包问题是指在TCP传输过程中,由于TCP是基于字节流的传输协议,没有消息边界的概念,因此当发送方发送的多个数据包到达接收方时,可能会粘成一个数据包,导致接收方无法正确区分每个数据包。以下是一些处理TCP粘包问题的方法:
一、发送端处理
定长发送:
发送端在发送数据时,将每个数据包都设置为固定长度。如果数据长度不足,则通过填充空字节来补齐。
接收端在接收数据时,也按照固定长度来读取数据。
这种方法实现简单,但可能会浪费带宽,特别是在数据长度变化较大的情况下。
尾部标记序列:
在每个数据包的尾部添加一个特殊的字节序列作为标记,用来标示数据包的末尾。
接收端在接收数据时,通过检测这个标记来确定数据包的边界。
这种方法需要确保标记序列的唯一性和不可预测性,以避免与数据内容冲突。
头部标记分步接收:
在每个数据包的头部添加一个长度字段,用来标示该数据包的总长度。
接收端在接收数据时,首先读取头部信息,然后根据长度字段的值来读取整个数据包。
这种方法相对灵活,能够处理不同长度的数据包,但需要在每个数据包中添加额外的头部信息。
禁用Nagle算法:
Nagle算法是TCP中用来减少小数据包数量的一种优化算法,但可能会导致粘包问题。
通过设置TCP_NODELAY选项来禁用Nagle算法,可以减少粘包的发生。
二、接收端处理
缓冲区管理:
接收端在接收数据时,需要合理管理缓冲区,确保能够及时读取和处理数据。
如果缓冲区过小,可能会导致数据丢失;如果缓冲区过大,可能会增加处理延迟和内存占用。
消息定界符:
在接收端,通过检测特定的字符或字符序列作为消息的定界符,来确定数据包的边界。
这种方法需要确保定界符的唯一性和不可预测性,以避免与数据内容冲突。
应用层协议设计:
在设计应用层协议时,可以明确数据包的格式和边界标识。
例如,可以在每个数据包的头部添加长度字段和校验和等信息,以确保数据的完整性和正确性。
拆包和重组:
在接收端,如果检测到粘包问题,可以通过拆包和重组的方式来恢复原始数据包。
这通常需要根据应用层协议的具体规定来实现。
三、综合处理
选择合适的传输协议:
根据具体应用场景的需求,选择合适的传输协议。如果可靠性要求较高,可以选择TCP;如果实时性要求较高,可以考虑使用UDP或其他实时传输协议。
优化网络性能:
优化网络性能,减少网络延迟和抖动,可以降低粘包问题的发生概率。
例如,可以通过增加网络带宽、优化网络拓扑结构等方式来提高网络性能。
131、互斥,信号量,条件变量的区别
互斥、信号量、条件变量是多线程编程中用于同步和互斥的重要概念
互斥(Mutex)是一种用于保护临界区的同步机制,确保同一时刻只有一个线程可以访问临界区。
互斥量只有两种状态:已加锁和已解锁。
访问方式:独占访问,即当一个线程持有互斥量时,其他线程必须等待直到该线程释放互斥量。
所有者概念:互斥量有所有者的概念,通常是由加锁的线程持有并解锁。
应用场景:适用于需要严格互斥访问的场景,如保护共享数据不被多个线程同时修改。
信号量(Semaphore)是一种更通用的同步机制,可以用于实现线程间的同步和互斥访问。
信号量的状态由一个计数器表示,可以初始化为大于1的值,表示可用的资源数量。
访问方式:信号量允许多个线程同时访问(只要计数器大于0),当一个线程访问时,计数器减1;当线程释放资源时,计数器加1。
所有者概念:信号量没有所有者的概念,它是基于计数器的机制。
应用场景:适用于需要控制对多个资源的访问的场景,如限制同时访问某个资源的线程数量。
条件变量(Condition Variable)是一种用于线程同步的机制,它允许线程在某个条件满足时进行等待,并在条件满足时被唤醒。
条件变量本身没有状态,它依赖于与之关联的互斥量和共享数据状态。
访问方式:条件变量通常与互斥量一起使用,以确保线程在访问共享数据时引发竞态条件。线程在调用wait方法时会释放互斥量并进入等待状态,直到另一个线程调用notify_one或notify_all方法唤醒它。
应用场景:适用于线程间需要基于某个条件进行同步的场景,如生产者-消费者模型中生产者等待缓冲区有空间、消费者等待缓冲区有数据。
133、程序的“标准”入口点为什么是main函数
在大多数编程语言中,特别是像C、C++、Java高级编程语言,程序的“标准”入口点是main函数。当程序启动时,操作系统会调用main函数作为程序的起点。然而,确实有一些方法可以让程序从其他函数开始执行
1. 使用main函数作为跳板
最常见的方法是通过main函数作为程序的入口点,然后在main函数中调用你希望作为实际起点的函数。例如,在C语言中:
2. 使用链接器脚本(Linker Script)
在某些情况下,你可以通过修改链接器脚本来改变程序的入口点。这通常用于嵌入式系统或需要精确控制程序启动行为的场景。链接器脚本允许你指定程序的入口地址,这可以是任何有效的函数地址。例如,在GCC中,你可以使用 -Wl,-T,your_linker_script.ld 选项来指定一个自定义的链接器脚本。链接器脚本中可能包含类似以下的条目:
3. 动态加载和执行代码(如插件系统)
在更高级的应用中,你可以通过动态加载和执行代码来改变程序的执行流程。例如,在C++中,你可以使用动态链接库(DLLs)或共享对象(SOs),在运行时加载它们并调用其中的函数。
4. 使用操作系统特性
在某些操作系统中,你可以利用特定的系统调用来改变程序的执行起点。例如,在Windows中,你可以使用CreateThread或CreateProcess来启动一个新线程或进程,并指定一个函数作为该线程或进程的入口点。
5. 特定框架或环境
一些编程框架或环境可能提供了改变程序入口点的机制。例如,在Web应用程序中,框架可能会处理HTTP请求并调用相应的处理函数,而不是从main函数开始。
这些方法通常涉及到对程序构建和链接过程的控制,或者利用操作系统和框架提供的特性。
134、对计算机系统结构有了解吗?说下对CPU架构的理解吧
cpu当中至少包括fetch code单元,alu计算单元,context(上下文,保存线程状态,寄存器单元,还有一些基本的存储空间),cache(MESI)
135、析构函数是虚函数:cpp但凡涉及继承析构函数必是虚的
虚析构的场景在使用多态时,以父指针调用子类,此时如果单纯析构父指针会调用父析构,那么父类外的子类部分就没有被析构,所以声明父析构为虚析构,此时调用的析构则为子类的析构。
136、贪心算法?
又名贪婪法,是寻找最优解问题的常用方法,这种方法模式一股将求解过程分成若千个步骤,但每个步骤都应该应用贪心原则,选取当前状态下最好/最优的选择。贪心法的基本步骤:
1、从某个初始解出发
2、采用迭代的过程,当可以向目标进一步时,就根据局部最优策略,得到一部分解,缩小问题规模
3、将所有解综合起来
137、介绍数据结构中二叉树的排序算法?
二叉树算法排序的原则:1.选择第一个元素作为根节点2.之后如果元素大于根节点放在右子树,如果元素小于根节点,则放在左子树,最后按照中序遍历的方式进行输出,则可以得到排序的结果(左>根>右)
138、vector、list、set区别
vector是一个变长一维数组,连续存放的内存块,支持高效的随机访问。
插入效率:
在尾部插入元素时,由于vector预分配了额外的内存空间(通常是以倍增或1.5倍增的方式),所以在大多数情况下插入操作是常数时间复杂度O(1)的(均摊后)。
但在中间或开始位置插入元素时,需要移动其他元素以腾出空间,这会导致线性时间复杂度O(n)的插入操作。
list是一个双向链表,内存空间上可能是不连续的,不支持随机存取。
插入效率:在任何位置插入元素时,只需调整指针即可,因此是常数时间复杂度O(1)的插入操作。
set是一个有序集合,使用平衡二叉树(如红黑树)存储,不支持直接存取元素,元素按排序规则自动排序。
插入效率:插入元素时,需要找到合适的位置并保持树的平衡,这通常是O(log n)的时间复杂度。但由于不需要内存拷贝和内存移动(节点以指针方式存储),相对于vector在中间或开始位置插入时的效率要高。
139、vector扩容机制
扩容方式:
vector通常使用倍增或1.5倍增的扩容策略。例如,当元素数量达到当前容量时,会分配一个新的、更大的内存块,并将旧内存块中的元素复制到新内存块中。
扩容次数与元素拷贝:
扩容次数与元素数量成对数关系(log2N),每次扩容都会引起元素拷贝。
总的操作次数(包括元素拷贝和插入)在均摊后是O(1)的(因为扩容次数较少,且每次扩容后容量翻倍)。
扩容开销:
虽然扩容时会有一定的开销(包括内存分配和元素拷贝),但由于扩容次数较少且每次扩容后容量显著增加,因此总体上vector的插入效率仍然较高。
综上所述,对于插入效率的要求:
如果需要在vector的尾部频繁插入元素,且对内存使用效率要求不高(因为会有一定的内存浪费在预分配的空间上),则vector是一个不错的选择。
如果需要在任意位置频繁插入元素,且希望保持元素的有序性,则set可能更适合。
如果需要在任意位置频繁插入和删除元素,且不关心元素的顺序,则list可能是一个更好的选择。
140、这段代码执行会发生什么
#include<iostream>
class A{
public:
void f(){
}
};
int main(){
A* a=nullptr;
a->f();
return 0;
}(一开始在我看来,这就是未定义行为,应该是指向内存空间中的保留区或者是任意的一个地址;之后我查了,是因为类的成员函数保存在代码段,然后被所有对象所共享吗?然后没有通过this指针去访问类中的相应成员变量,所以仍然是可以调用的嘛)
141、计算这个类的大小
#include<iostream>
class base1{
private:
int a;
char c;
public:
virtual void fun1(){}
virtual void fun2(){}
};
int main(){
std::cout<<(sizeof(base1));
return 0;
}C++中,类的sizeof结果不仅取决于类中声明的成员变量的大小,还受到编译器实现、对齐要求(alignment)以及虚函数表(vtable,如果存在虚函数的话)等因素的影响。
base1类包含两个私有成员变量:一个int类型的a和一个char类型的c。此外,还声明了两个虚函数fun1和fun2。由于存在虚函数,编译器会为这个类生成一个虚函数表(vtable),用于在运行时确定调用哪个函数。
int类型通常占用4个字节(这取决于编译器和平台,但4字节是常见的)。
char类型占用1个字节。
虚函数表(vtable)
虚函数表是一个指向函数指针数组的指针,它存储在类的实例中,用于在运行时解析虚函数的调用。vtable本身的大小和位置取决于编译器的实现,但它通常会增加类实例的大小。
对齐要求
编译器可能会根据平台的要求对成员变量进行对齐,以确保访问速度。这可能会增加类实例的总大小。
对于base1类,即使它只有两个相对较小的成员变量,但由于存在虚函数,其sizeof结果通常会大于这两个成员变量的大小之和(即5字节)。实际上,由于对齐和vtable的存在,sizeof(base1)的结果可能会是8字节或更多,具体取决于编译器的实现和平台。
142、如何判断程序是由C编译还是C++编译
C和C++虽然共享部分语法,但它们的编译器有显著区别。C语言遵循的是ANSI C(C89/C99/C11等)标准,而C++是基于ISO C++标准(C++98/C++11/C++17/C++20等)发展的。
主要差异:
-
语言特性: C++支持面向对象编程、模板、命名空间等高级特性,而C语言以过程式编程为主。
-
类型检查: C++的类型检查更为严格。
-
库支持: C++有标准模板库(STL),C语言主要依赖标准库(stdlib.h、stdio.h等)。
-
编译器: 常见的C编译器有gcc、clang等,而C++编译器如g++、clang++在支持C++特性时行为不同。
判断方法
方法一:利用C与C++语法特性的差异
C与C++在语法支持上有显著不同,可以利用这些特性编写特定代码,观察其编译结果。
1. 强制类型转换
C语言允许隐式转换,而C++对某些类型转换有严格限制。例如:
int main() {
void *ptr = 0;
int value = ptr; // C允许隐式转换,但C++编译会报错。
return 0;}解释:
如果代码能够编译通过,则使用的是C编译器。
如果报类型转换错误,则使用的是C++编译器。
2. 函数声明差异
在C语言中,函数参数可以不指定类型,而C++要求显式声明。例如:
int func(); // C中合法,但C++中会被解释为int func(void)。
int main() {
func(10); // C中合法,但C++中会报错。
return 0;}解释:
C允许函数调用时传递参数,即使函数原型未声明参数。
C++编译器会严格检查参数与函数声明是否匹配。
3. bool类型
C++支持内建的bool类型,而C语言没有。例如:
int main() {
bool flag = true; // C++中合法,C中会报错。
return 0;
}
解释:
如果bool和true能够编译通过,则是C++编译器。
如果报未定义符号错误,则是C编译器。
方法二:利用编译器预定义宏
C和C++编译器会预定义一些特定的宏,可以通过编写代码检查这些宏来判断。例如:
#include <stdio.h>
int main() {
#ifdef __cplusplus
printf("This is compiled with a C++ compiler.\n");
#else
printf("This is compiled with a C compiler.\n");
#endif
return 0;}解释:
__cplusplus是C++编译器自动定义的宏,其值对应C++标准的版本号。例如:
C++98:199711L
C++11:201103L
C++17:201703L
如果宏未定义,则说明使用的是C编译器。
方法三:观察生成的符号表
C和C++的编译器在生成符号表时存在差异。C++支持函数重载,因此其符号表会经过名称修饰(Name Mangling),而C语言则不会。例如:
extern "C" void func() {}
void func(int) {}用nm命令查看生成的目标文件:
nm a.out结果:
C编译器生成的符号名为原始名称,例如func。
C++编译器生成的符号名为修饰过的名称,例如_Z4funci(GCC名称修饰规则)。
方法四:链接错误提示
在链接阶段,C和C++编译器对符号处理的方式不同。例如:
void func();
int main() {
func();
return 0;}假设未提供func的实现:
如果是C编译器,链接器会报"undefined reference to `func'"。
如果是C++编译器,链接器会报"undefined reference to `_Z4funcv'",因为C++编译器进行了名称修饰。
方法五:运行时行为
C和C++的运行时特性不同。例如,C++支持构造函数和析构函数的自动调用,可以利用这一点进行判断:
#include <iostream>
class Test {
public:
Test() { std::cout << "C++ Compiler\n"; }
~Test() {}
};
Test t; // 如果是C++编译器,会自动调用构造函数。
int main() {return 0;}解释:
如果运行程序时输出C++ Compiler,则是C++编译器。
如果运行时报错,则是C编译器。
如果无法访问源码,现在只有程序,又该如何确认呢?
如果无法获取程序源码,但可以接触到其二进制文件或运行结果,仍可以通过以下方式判断:
一:分析符号表
使用工具如nm或objdump提取符号表:
名称修饰: C++符号表中包含名称修饰(如_Z4funci),而C符号表中则保留原始符号(如func)。
构造函数与析构函数: 如果符号表中存在类似_ZN4TestC1Ev的符号,则为C++编译器。
二:查看运行时依赖
运行ldd(Linux)或Dependency Walker(Windows)查看依赖:
C库依赖: C程序仅依赖libc。
C++库依赖: C++程序依赖libstdc++或msvcpp等库。
方法三:读取调试信息
通过readelf -p .comment提取编译器版本信息:
C编译器: 注释可能显示GCC或其他C编译器版本。
C++编译器: 注释可能显示G++或Clang++。
方法四:运行动态链接调试
通过设置LD_DEBUG=all运行程序,查看动态加载过程:
LD_DEBUG=all ./program判断依据:
如果加载过程中出现类似std::或__cxa_atexit等符号,则为C++程序。
如果仅加载了libc相关符号,则为C程序。
五:观察异常机制
C++支持异常处理,而C语言不支持。如果在运行过程中捕获到类似std::exception或type_info相关信息,则可以确认程序是由C++编译器生成。
./program 2>&1 | grep exception如果输出中有C++特定的异常相关内容,例如terminate called after throwing an instance of 'std::exception',则可以判断是C++程序。
实践中注意事项
-
交叉编译环境: 在嵌入式开发中,工具链可能限定语言特性,需要明确工具链配置。
-
工具与选项:GCC支持通过-x强制指定语言类型,避免歧义。
-
混合开发:C++调用C代码时需使用extern "C"以避免符号修饰。
总结
通过语法特性、预定义宏、符号表分析、链接错误提示、运行时行为以及二进制文件的依赖关系,可以有效判断程序是由C还是C++编译器编译。即使无法访问源码,工具如nm、ldd、readelf等也能提供重要线索。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)