GPU的TFLOPS算力怎么计算
GPU的TFLOPS(Tera FLOPS)指的是每秒可以进行的万亿次浮点运算(Floating Point Operations Per Second)。计算GPU的TFLOPS通常是基于其核心的时钟频率、每个核心的浮点运算能力以及核心的数量。FLOPS是衡量计算能力的一个指标,通常按如下方式定义:TFLOPS是FLOPS的单位换算,1 TFLOP = 1,000,000,000,000(1万亿
·
GPU的TFLOPS(Tera FLOPS)指的是每秒可以进行的万亿次浮点运算(Floating Point Operations Per Second)。计算GPU的TFLOPS通常是基于其核心的时钟频率、每个核心的浮点运算能力以及核心的数量。
1. FLOPS的定义
FLOPS是衡量计算能力的一个指标,通常按如下方式定义:
- FLOPS:浮点操作每秒(Floating Point Operations Per Second)。
2. 如何计算TFLOPS
TFLOPS是FLOPS的单位换算,1 TFLOP = 1,000,000,000,000(1万亿)次浮点运算。
3. 计算GPU TFLOPS的一般公式
GPU的TFLOPS可以通过以下公式计算:
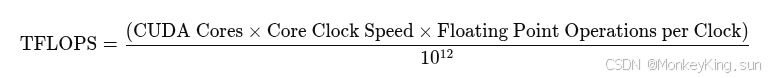
参数说明:
- CUDA Cores:GPU中的计算核心数量。例如,NVIDIA A10有多达7,680个CUDA核心。
- Core Clock Speed:核心的时钟频率,单位为赫兹(Hz)。例如,1 GHz = 1,000,000,000 Hz。
- Floating Point Operations per Clock:每个时钟周期GPU可以进行的浮点运算次数。对于浮点数计算,通常:
- FP32(单精度浮点):每个时钟周期进行2次浮点操作(加法和乘法各1次)。
- FP64(双精度浮点):通常每个时钟周期进行1次浮点操作(加法或乘法)。
4. 举例计算
以NVIDIA A10为例(假设其核心时钟为1.5 GHz,CUDA核心数为7,680):
- CUDA Cores = 7,680
- Core Clock Speed = 1.5 GHz = 1,500,000,000 Hz
- Floating Point Operations per Clock (FP32) = 2(每个时钟周期2次浮点操作)
那么,TFLOPS的计算为:
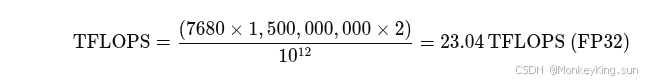
这意味着,在理论上,A10 GPU在FP32的情况下,最大能够达到23.04 TFLOPS的算力。
5. 不同精度的影响
- FP32(单精度浮点):通常用于大多数深度学习训练和推理任务,具有更高的计算能力。
- FP64(双精度浮点):在科学计算和高精度数值模拟中使用,通常每个时钟周期只能进行1次浮点操作,因此TFLOPS要低得多。
- Tensor Cores:现代GPU(如NVIDIA的Volta、Turing和Ampere架构)还有专门的Tensor Cores,可以进行混合精度计算(例如FP16、TF32、INT8等),这些操作通常能提供比传统FP32计算更高的TFLOPS。
6. 总结
- FP32 TFLOPS:用于大多数AI推理和训练任务,计算方式是基于CUDA核心数量、时钟频率和每个核心的浮点操作能力。
- Tensor Cores:专门优化过的计算单元,能够显著提高深度学习模型在低精度(如FP16)下的计算性能,因此很多现代GPU在TFLOPS表现上会使用Tensor Core加速。
这个理论计算方法给出的是一个GPU的最大计算能力,但实际性能还会受到其他因素的影响,如内存带宽、缓存、并行度、任务类型等。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)