打造专属AI聊天机器人:ServBay、Python与ChromaDB本地部署全攻略
想要打造专属AI聊天机器人,看这篇就够了,一步步教给你
在数据隐私至关重要的时代,搭建本地语言模型(LLM)为公司和个人提供了一种重要的解决方案。本教程旨在指导您使用 ServBay、 Python 3和ChromaDB创建一个自定义聊天机器人,全部在您的系统上本地托管。实际上,您只需下载 ServBay,而无需任何其他软件。以下是您需要本教程的关键原因:
-
完全自定义:在本地托管您自己的检索增强生成(RAG)应用程序使您完全控制其配置和个性化。您可以根据特定需求调整模型,而不必依赖第三方服务。
-
提高隐私保护:在本地设置语言模型(LLM)使您能避开在线传输敏感信息的风险。这对于处理私人数据的组织尤为重要,因为使用本地资源训练模型可以确保您的信息保持安全和受到保护。
-
数据安全保障:依赖外部 LLM 模型可能会使您的数据面临潜在的安全威胁。通过本地部署模型,您可以最大限度地降低这些风险,确保您的训练材料(如 PDF 文件)在您自己的环境中受到保护。
-
数据管理控制:运营自己的 LLM 使您可以根据个人意愿处理和管理数据。这包括将您的专有信息嵌入 ChromaDB 向量存储,确保您的数据处理符合特定标准和要求。
-
独立于互联网:本地运行聊天机器人意味着您不必依赖互联网连接。这确保了服务的一致性,并且即使在离线情况下也能持续访问您的聊天机器人。
本教程将使您能够构建一个强大且安全的本地聊天机器人,根据您的需求量身定制,而不妥协隐私或控制。

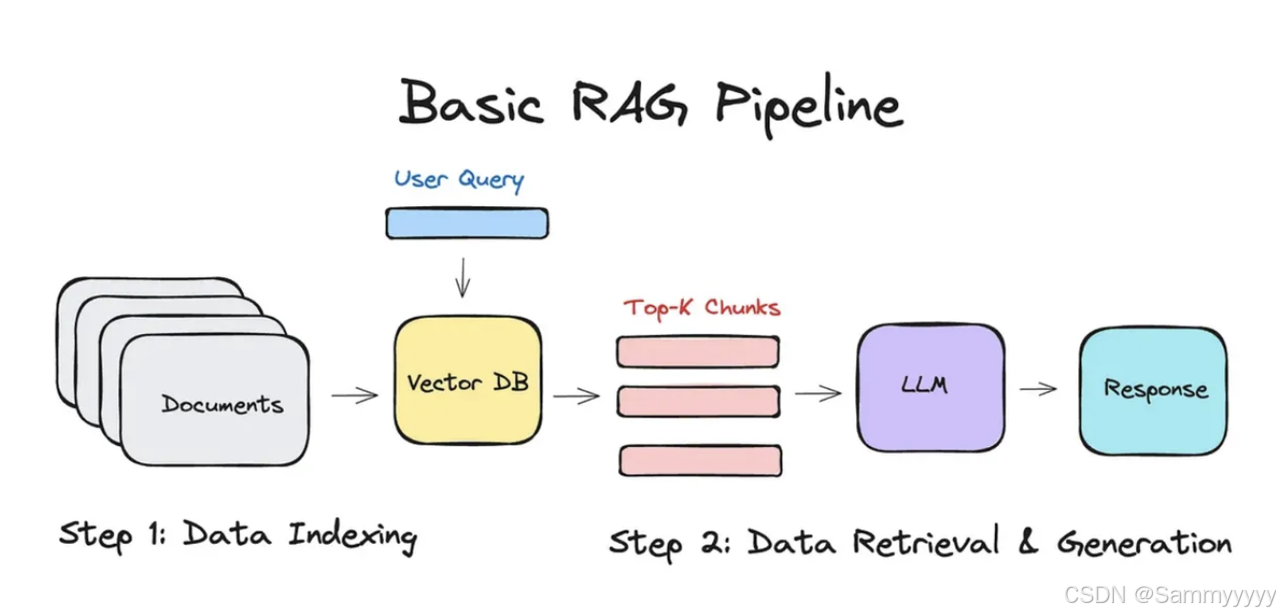
检索增强生成(RAG)
检索增强生成(RAG)是一种先进的技术,它结合了信息检索和文本生成的优势,以生成更准确和上下文相关的响应。以下是对 RAG 工作原理及其好处的详细解析:
什么是 RAG?
RAG 是一种混合模型,通过结合外部知识库或文档存储,增强语言模型的能力。这个过程主要包括两个组件:
-
检索:在此阶段,模型根据输入查询,从外部来源(例如数据库或向量存储)检索相关文档或信息片段。
-
生成:然后,所检索的信息被生成式语言模型用于生成连贯且上下文适当的响应。
RAG 是如何工作的?
-
查询输入:用户输入查询或问题。
-
文档检索:系统使用查询在外部知识库中搜索,检索出最相关的文档或信息片段。
-
响应生成:生成模型处理所检索的信息,将其与自己已知的信息结合,生成详细和准确的响应。
-
输出:最终的响应,融入了来自知识库的具体和相关细节,展示给用户。
RAG 的好处
-
增强精确度:通过利用外部数据,RAG 模型可以提供更准确和详细的答案,尤其是针对特定领域的查询。
-
上下文相关性:检索组件确保生成的响应基于相关和最新的信息,从而提高响应的整体质量。
-
可扩展性:RAG 系统可以轻松扩展,以纳入大量数据,使其能够处理广泛的查询和主题。
-
灵活性:这些模型可以通过简单地更新或扩展外部知识库来适应不同的领域,因此具有很高的通用性。
为什么要在本地使用 RAG?
-
隐私和安全:在本地运行 RAG 模型可确保敏感数据保持安全和私密,因为数据不需要发送到外部服务器。
-
自定义:您可以根据具体需求定制检索和生成过程,包括集成专有数据源。
-
独立性:本地设置确保您的系统在没有互联网连接的情况下依然能正常运行,提供持续可靠的服务。
通过使用 Ollama、Python 和 ChromaDB 等工具设置本地 RAG 应用程序,您可以享受到先进语言模型的优势,同时保持对数据和自定义选项的控制。
ServBay
ServBay 是一个集成的图形化、本地一键安装的网页开发环境,专为网页开发者、Python 开发者、AI 开发者和 PHP 开发者设计。该软件特别适合 macOS 系统。它包括一系列常用的网页开发服务和工具,涵盖了网页服务器、数据库、编程语言、邮件服务器、队列服务等。ServBay 旨在为开发者提供一个方便、高效和统一的开发环境。
ServBay 的核心特点
-
支持多版本 Python:同时运行多个 Python 版本,满足不同项目的需求。
-
自定义域名和 SSL 支持:轻松配置本地域名和 SSL 证书,以模拟真实的生产环境。
-
快速操作:支持开机启动、通过菜单栏快速访问以及命令行管理,提高开发效率。
-
统一服务管理:集成 Python、PHP、Node.js 和 Ollama,方便管理多个开发服务。
-
清洁的系统环境:通过在隔离环境中运行所有服务,避免系统污染。
-
内网穿透和共享:支持内网穿透实现本地网站的共享,便于与团队成员共享开发成果。
ServBay 安装指南
系统要求:macOS 12.0 Monterey 或更高版本
下载 ServBay 最新版本
安装:
-
双击下载的 .dmg 文件以打开它。
-
在打开的窗口中,将 ServBay.app 图标拖入“应用程序”文件夹中。

首次使用 ServBay 时,需要进行初始化。通常,您可以选择默认安装,或者可选地选择 Ollama 以支持 AI 编程。

安装完成后,打开ServBay。

-
输入您的密码。安装完成后,您可以在“应用程序”目录中找到 ServBay。
-
访问主界面。
除了 Python,ServBay 还提供对 PHP 和 Node.js 的强大支持,涵盖从 PHP 5.6 到 PHP 8.5 和 Node.js 12 到 Node.js 23 的广泛版本。
ServBay 的一个关键特性是能够快速切换不同的软件版本。这种灵活性对于需要在各种环境中测试和部署应用程序的开发者至关重要。
所有 Python 版本的一键安装。
所有 Ollama 模型的一键安装:
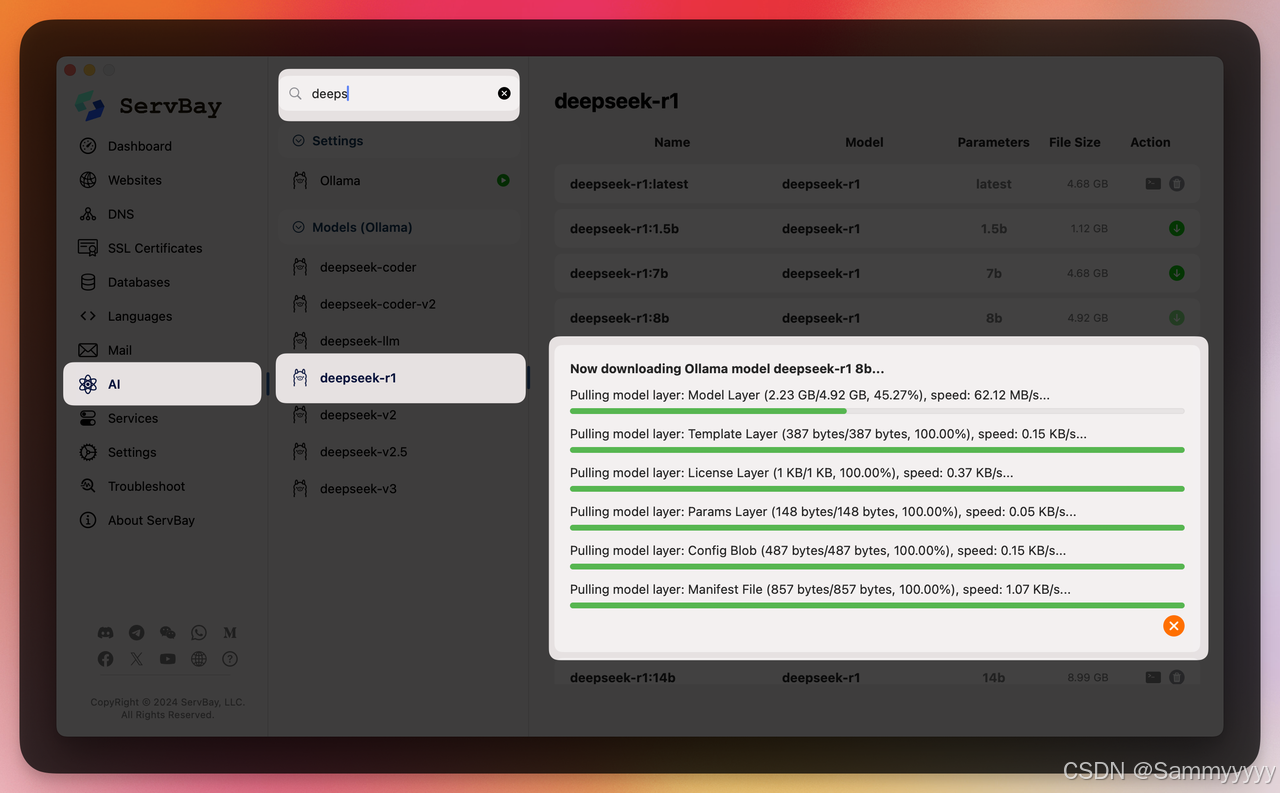
前提条件
在开始设置之前,请确保您具备以下前提条件:
-
Python 3:Python是一种多用途的编程语言,您将用它编写RAG应用程序的代码。
-
ChromaDB:一个向量数据库,用于存储和管理我们的数据嵌入。
-
Servbay:用于在本地机器上下载和提供自定义LLM。
第 1 步:安装 Python 3 并设置环境
要安装和设置我们的 Python 3 环境,请按照以下步骤操作:
-
点击 Servbay 的 Python 按钮,然后选择一个 Python 版本。
-
确保您的 Python 3 安装成功并能够正常运行。
$ python3 --version# Python 3.12.9为您的项目创建一个文件夹。例如,可以命名为 local-rag:
$ mkdir local-rag
$ cd local-rag创建一个名为 venv 的虚拟环境:
$ python3 -m venv venv激活虚拟环境
$ source venv/bin/activate
# Windows# venv\Scripts\activate第 2 步:安装 ChromaDB 和其他依赖
使用 pip 安装 ChromaDB:
$ pip install --q chromadb安装 Langchain 工具,以便与您的模型无缝协作:
$ pip install --q unstructured langchain langchain-text-splitters
$ pip install --q "unstructured[all-docs]"安装 Flask 以将您的应用作为 HTTP 服务提供:
$ pip install --q flask第 3 步:安装 Ollama
要安装 Ollama,请按照以下步骤操作:
1. 点击 Servbay 的 AI 按钮,然后选择您喜欢的模型。
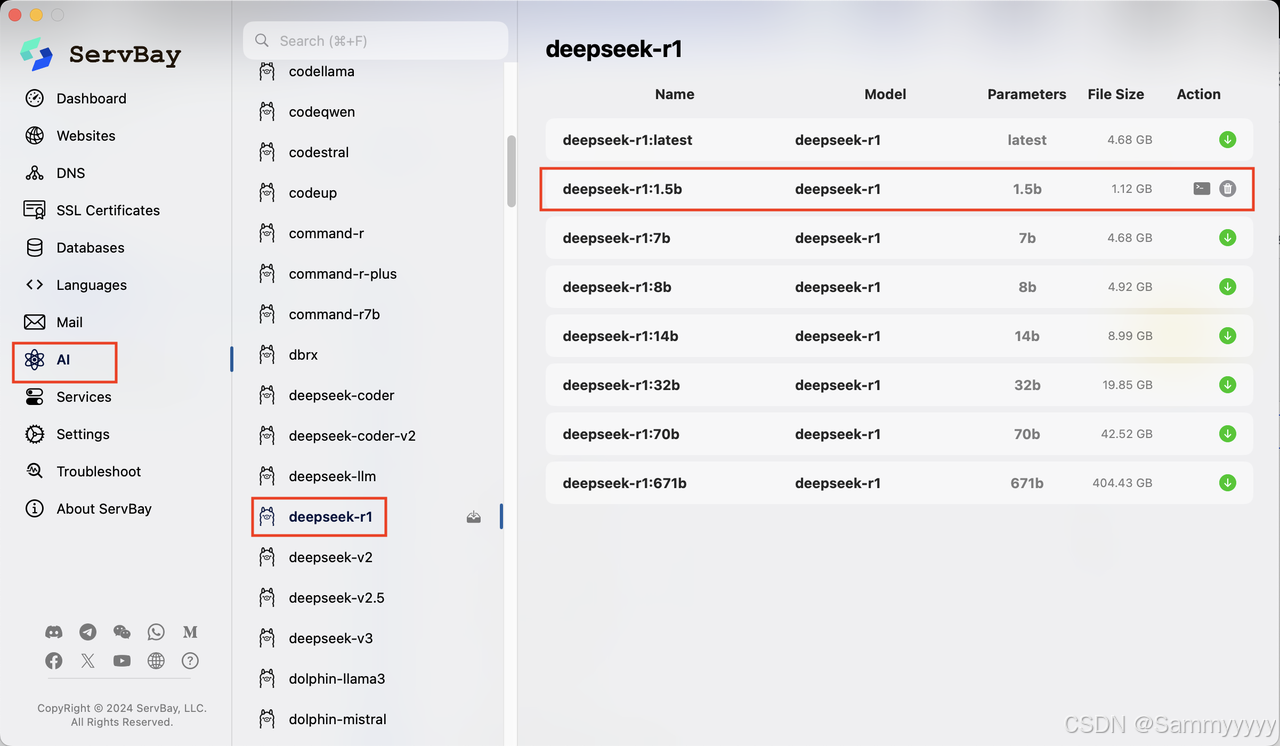
构建 RAG 应用
现在您已经使用 Python、Ollama、ChromaDB 和其他依赖项设置好了环境,是时候构建您自定义的本地 RAG 应用程序了。在本部分中,我们将逐步介绍 Python 代码,并提供有关如何构建应用程序结构的概述。
app.py
这是主要的 Flask 应用程序文件。它定义了将文件嵌入到向量数据库中和从模型检索响应的路由。
import os
from dotenv import load_dotenv
from flask import Flask, request, jsonify
from embed import embed
from query import query
from get_vector_db import get_vector_db
# 设置临时文件夹
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
os.makedirs(TEMP_FOLDER, exist_ok=True)
app = Flask(__name__)
@app.route('/embed', methods=['POST'])
def route_embed():
if 'file' not in request.files:
return jsonify({"error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
embedded = embed(file)
if embedded:
return jsonify({"message": "File embedded successfully"}), 200
return jsonify({"error": "File embedded unsuccessfully"}), 400
@app.route('/query', methods=['POST'])
def route_query():
data = request.get_json()
response = query(data.get('query'))
if response:
return jsonify({"message": response}), 200
return jsonify({"error": "Something went wrong"}), 400
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8080, debug=True) embed.py
该模块处理嵌入过程,包括保存上传的文件、加载和拆分数据,以及将文档添加到向量数据库中。
import os
from datetime import datetime
from werkzeug.utils import secure_filename
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
# Function to check if the uploaded file is allowed (only PDF files)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pdf'}
# Function to save the uploaded file to the temporary folder
def save_file(file):
# Save the uploaded file with a secure filename and return the file path
timestamp = datetime.now().timestamp()
filename = f"{timestamp}_{secure_filename(file.filename)}"
file_path = os.path.join(TEMP_FOLDER, filename)
file.save(file_path)
return file_path
# Function to load and split the data from the PDF file
def load_and_split_data(file_path):
# Load the PDF file and split the data into chunks
loader = UnstructuredPDFLoader(file_path=file_path)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=7500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
return chunks
# Main function to handle the embedding process
def embed(file):
# Check if the file is valid, save it, load and split the data, add to the database, and remove the temporary file
if file.filename != '' and file and allowed_file(file.filename):
file_path = save_file(file)
chunks = load_and_split_data(file_path)
db = get_vector_db()
db.add_documents(chunks)
db.persist()
os.remove(file_path)
return True
return False query.py
该模块通过生成查询的多个版本、检索相关文档,以及根据上下文提供答案来处理用户查询。
import os
from langchain_community.chat_models import ChatOllama
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.retrievers.multi_query import MultiQueryRetriever
from get_vector_db import get_vector_db
LLM_MODEL = os.getenv('LLM_MODEL', 'deepseek-r1:1.5b')
# Function to get the prompt templates for generating alternative questions and answering based on context
def get_prompt():
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from
a vector database. By generating multiple perspectives on the user question, your
goal is to help the user overcome some of the limitations of the distance-based
similarity search. Provide these alternative questions separated by newlines.
Original question: {question}"""
)
template = """Answer the question based ONLY on the following context:
{context}
Question: {question}"""
prompt = ChatPromptTemplate.from_template(template)
return QUERY_PROMPT, prompt
# Main function to handle the query process
def query(input):
if input:
# Initialize the language model with the specified model name
llm = ChatOllama(model=LLM_MODEL)
# Get the vector database instance
db = get_vector_db()
# Get the prompt templates
QUERY_PROMPT, prompt = get_prompt()
# Set up the retriever to generate multiple queries using the language model and the query prompt
retriever = MultiQueryRetriever.from_llm(db.as_retriever(), llm, prompt=QUERY_PROMPT)
# Define the processing chain to retrieve context, generate the answer, and parse the output
chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
response = chain.invoke(input)
return response
return None get_vector_db.py
该模块初始化并返回用于存储和检索文档嵌入的向量数据库实例。
import os
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores.chroma import Chroma
CHROMA_PATH = os.getenv('CHROMA_PATH', 'chroma')
COLLECTION_NAME = os.getenv('COLLECTION_NAME', 'local-rag')
TEXT_EMBEDDING_MODEL = os.getenv('TEXT_EMBEDDING_MODEL', 'nomic-embed-text')
def get_vector_db():
# Create an instance of the embedding model
embedding = OllamaEmbeddings(model=TEXT_EMBEDDING_MODEL, show_progress=True)
# Initialize the Chroma vector store with specified parameters
db = Chroma(
collection_name=COLLECTION_NAME,
persist_directory=CHROMA_PATH,
embedding_function=embedding
)
return db 运行您的APP!
1. 创建 .env 文件以存储您的环境变量:
在项目根目录下创建一个名为 .env 的文件,并添加您的环境变量,例如大模型等等参数。
TEMP_FOLDER = './_temp'
CHROMA_PATH = 'chroma'
COLLECTION_NAME = 'local-rag'
LLM_MODEL = 'mistral'
TEXT_EMBEDDING_MODEL = 'nomic-embed-text'2. 运行 app.py 文件以启动您的应用服务器:
在终端中,使用以下命令启动您的 Flask 应用:
$ python3 app.py3. 一旦服务器运行,您可以开始向以下端点发送请求:
-
嵌入 PDF 文件的示例命令(例如,
resume.pdf):
#!/bin/bash
curl --request POST \
--url http://localhost:8080/embed \
--header 'Content-Type: multipart/form-data' \
--form file=@/Users/liyinan/Documents/works/matrix_multi.pdfResponse
{
"message": "File embedded successfully"
}Example command to ask a question to your model:
$ curl --request POST \
--url http://localhost:8080/query \
--header 'Content-Type: application/json' \
--data '{ "query": "Who is Nasser?" }'
# Response
{
"message": "Nasser Maronie is a Full Stack Developer with experience in web and mobile app development. He has worked as a Lead Full Stack Engineer at Ulventech, a Senior Full Stack Engineer at Speedoc, a Senior Frontend Engineer at Irvins, and a Software Engineer at Tokopedia. His tech stacks include Typescript, ReactJS, VueJS, React Native, NodeJS, PHP, Golang, Python, MySQL, PostgresQL, MongoDB, Redis, AWS, Firebase, and Supabase. He has a Bachelor's degree in Information System from Universitas Amikom Yogyakarta."
}结论
通过遵循这些说明,您可以有效地运行并与您的自定义本地 RAG 应用进行交互,使用 Python、Ollama 和 ChromaDB,满足您的需求。根据需要调整和扩展功能,以增强应用程序的能力。
利用本地部署的优势,您不仅可以保护敏感信息,还可以优化性能和响应速度。无论是提升客户互动还是简化内部流程,本地部署的 RAG 应用程序都提供了灵活性和稳健性,能够适应和发展以满足您的需求。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)