241015_制作自己的Pix2PIx数据集
官方代码:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix首先,附官方数据集下载链接,便于大家对照查看格式,这里我下载了最小的facades数据集,毕竟我们只是对照查看格式,而不是真的拿他数据集来训练(里面最大的数据集有8G,下的时候看清楚哦)。你要是不想下也可以,我这里尽量把他数据集的格式描述清楚。首先解压出来是一个decades文件
2410115_制作自己的Pix2Pix数据集
官方数据集介绍
官方代码:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
首先,附官方数据集下载链接Index of /pix2pix/datasets (berkeley.edu),便于大家对照查看格式,这里我下载了最小的facades数据集,毕竟我们只是对照查看格式,而不是真的拿他数据集来训练(里面最大的数据集有8G,下的时候看清楚哦)。
你要是不想下也可以,我这里尽量把他数据集的格式描述清楚。首先解压出来是一个decades文件夹,下属三个文件夹train,test,val(val非必须),每个文件夹下存放了类似下图的图片
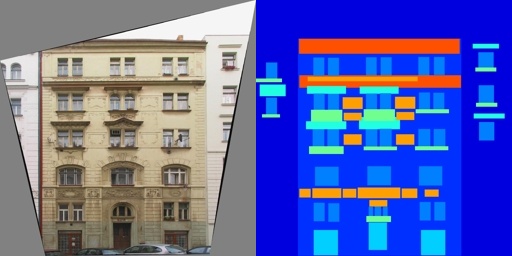
以下是文件结构
--facades
--train
--1.jpg
--2.jpg
…………
--tset
--1.jpg
--2.jpg
…………
--val
--1.jpg
--2.jpg
…………
动手
接下来,着手制作我们自己的数据集了
第一步!确保你的所有图片文件均为序列命名,避免合并数据集时产生的命名重复而自动填充(1)(2)这样的错误,这里面的括号为中文字符,无法载入。具体命名方法可参考241015_把一个文件夹中的所有图片按照序列命名-CSDN博客
第二步,确保你的image和label都有相同的尺寸size(比如都是512乘512),可能有的同学获取label的方式是使用原图载入某些成型网络(例如CycleGan)中,他的输出默认就给你修改成了512×512,但是粗心的话可能看不出来。(如产生此错误,建议先将原图调整为指定尺寸后在载入网络获取label),调整原图尺寸可参考241015_把文件夹中所有的图片缩放为指定大小(缩放数据集)-CSDN博客
确保尺寸相同是为了后续要进行concat拼接。形成上面示例图片左边原图右边标签这样的形式。

第三,确保你获取到的label和image命名严格对齐,确保一对图像(image和其对应label)有相同的命名,否则后续拼接结果会很混乱(任何一对一的数据集都要求命名对齐)。确保你所载入的成型预测网络的命名结果是参考原图命名进行命名,而不是用循环i进行序列命名。这里不提供代码,自己用眼睛瞪吧。
第四,(这里没有确保哈)这里属于便民工程,如果你确实是通过使用notebook中成型的网络获取到的label,此时你会面临一个问题,成百上千张图片的下载问题,往往全选下载是下不完全的,这里提供一种方法,在notebook中对文件夹进行压缩操作,之后就可以直接右键压缩包进行download。具体方法可参考241011-在jupyter中实现文件夹压缩后下载-CSDN博客
到这里,我默认你已经得到了512×512,后缀名为.jpg,命名严格对齐的image和label,接下来进行拼接
拼接部分官方有给代码combine_A_and_B.py,里面用到了多线程,命令行等操作,显得较为复杂,这里给一份比较简单的(文末会附官方代码),便于大家直接修改图片路径就能跑
# 自己的concat拼接代码,修改路径就能跑
from PIL import Image
import os
def merge_images_horizontally(img1_path, img2_path, output_path):
"""
横向合并两张图片并保存到指定路径
"""
image1 = Image.open(img1_path)
image2 = Image.open(img2_path)
# 确保两幅图的高度相同
if image1.height != image2.height:
raise ValueError("两幅图的高度不一致")
new_image = Image.new('RGB', (image1.width + image2.width, image1.height))
new_image.paste(image1, (0, 0))
new_image.paste(image2, (image1.width, 0))
new_image.save(output_path)
def process_folders(folder1, folder2, output_folder):
"""
处理两个文件夹中的图片,横向拼接并保存到输出文件夹
"""
# 创建输出文件夹如果不存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
files1 = sorted(os.listdir(folder1))
files2 = sorted(os.listdir(folder2))
for file_name in files1:
if file_name.endswith(('.png', '.jpg', '.jpeg')):
if file_name in files2:
img1_path = os.path.join(folder1, file_name)
img2_path = os.path.join(folder2, file_name)
output_path = os.path.join(output_folder, file_name)
merge_images_horizontally(img1_path, img2_path, output_path)
print(f"Merged {file_name} -> {output_path}")
else:
print(f"Warning: File {file_name} not found in folder2")
# 设置文件夹路径
folder1 = 'D:\Softwares\Codes\Git\GitProgram\light\data_test\\train_528p_512_xl'
folder2 = 'D:\Softwares\Codes\Git\GitProgram\light\data_test\\xt_528p_512_xl'
output_folder = 'D:\Softwares\Codes\Git\GitProgram\light\data_test\concat_528p_512_xl'
process_folders(folder1, folder2, output_folder)
以下是官方的拼接代码:
# 官方的combine_A_and_B.py
import os
import numpy as np
import cv2
import argparse
from multiprocessing import Pool
def image_write(path_A, path_B, path_AB):
im_A = cv2.imread(path_A, 1) # python2: cv2.CV_LOAD_IMAGE_COLOR; python3: cv2.IMREAD_COLOR
im_B = cv2.imread(path_B, 1) # python2: cv2.CV_LOAD_IMAGE_COLOR; python3: cv2.IMREAD_COLOR
im_AB = np.concatenate([im_A, im_B], 1)
cv2.imwrite(path_AB, im_AB)
parser = argparse.ArgumentParser('create image pairs')
parser.add_argument('--fold_A', dest='fold_A', help='input directory for image A', type=str, default='../dataset/50kshoes_edges')
parser.add_argument('--fold_B', dest='fold_B', help='input directory for image B', type=str, default='../dataset/50kshoes_jpg')
parser.add_argument('--fold_AB', dest='fold_AB', help='output directory', type=str, default='../dataset/test_AB')
parser.add_argument('--num_imgs', dest='num_imgs', help='number of images', type=int, default=1000000)
parser.add_argument('--use_AB', dest='use_AB', help='if true: (0001_A, 0001_B) to (0001_AB)', action='store_true')
parser.add_argument('--no_multiprocessing', dest='no_multiprocessing', help='If used, chooses single CPU execution instead of parallel execution', action='store_true',default=False)
args = parser.parse_args()
for arg in vars(args):
print('[%s] = ' % arg, getattr(args, arg))
splits = os.listdir(args.fold_A)
if not args.no_multiprocessing:
pool=Pool()
for sp in splits:
img_fold_A = os.path.join(args.fold_A, sp)
img_fold_B = os.path.join(args.fold_B, sp)
img_list = os.listdir(img_fold_A)
if args.use_AB:
img_list = [img_path for img_path in img_list if '_A.' in img_path]
num_imgs = min(args.num_imgs, len(img_list))
print('split = %s, use %d/%d images' % (sp, num_imgs, len(img_list)))
img_fold_AB = os.path.join(args.fold_AB, sp)
if not os.path.isdir(img_fold_AB):
os.makedirs(img_fold_AB)
print('split = %s, number of images = %d' % (sp, num_imgs))
for n in range(num_imgs):
name_A = img_list[n]
path_A = os.path.join(img_fold_A, name_A)
if args.use_AB:
name_B = name_A.replace('_A.', '_B.')
else:
name_B = name_A
path_B = os.path.join(img_fold_B, name_B)
if os.path.isfile(path_A) and os.path.isfile(path_B):
name_AB = name_A
if args.use_AB:
name_AB = name_AB.replace('_A.', '.') # remove _A
path_AB = os.path.join(img_fold_AB, name_AB)
if not args.no_multiprocessing:
pool.apply_async(image_write, args=(path_A, path_B, path_AB))
else:
im_A = cv2.imread(path_A, 1) # python2: cv2.CV_LOAD_IMAGE_COLOR; python3: cv2.IMREAD_COLOR
im_B = cv2.imread(path_B, 1) # python2: cv2.CV_LOAD_IMAGE_COLOR; python3: cv2.IMREAD_COLOR
im_AB = np.concatenate([im_A, im_B], 1)
cv2.imwrite(path_AB, im_AB)
if not args.no_multiprocessing:
pool.close()
pool.join()
执行完之后,就可以获取到左侧image右侧label的图,类似于下面:
现在我们就可以手动划分train和test了(val可选,我没选)。然后就可以直接修改官方代码的读取数据path开始跑了

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)