期末复习攻略——并行计算与分布式系统
《并行计算与分布式系统》课程学习
文章目录
前言
本人大三计科,学院开设了这门并行课程。在期末复习期间整理了笔记,现分享出来目的有两个:一.帮助同样有备考该课程期末需求的学弟学妹。二.如果能对学习并行该领域的learner查找资料时提供一些帮助,就也算一点贡献了。写的比较仓促,错误在所难免。欢迎提出交流,但不接受不思考的提问。
参考资料
书籍:《并行程序设计导论》,英文名:An Introduction to Parallel Programming。

实验平台:
-
Visual Studio(占内存,可以本地调试).
-
超算习堂(操作简单,但不好debug)
-
vscode(使用还可以)
教材并行程序设计导论笔记
下面是根据老师上课用的ppt进行的内容整理,如果与书上不一致,大概率书上是对的,当然也可能都是错的,自己独立思考查资料验证最重要。
Chapter1—为什么要并行计算
提纲
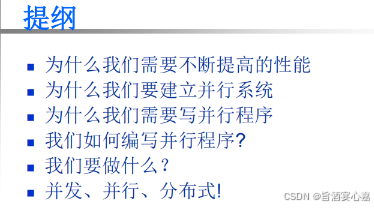
问答
Q 1 Q_1 Q1:为什么我们需要不断提高的性能
A 1 A_1 A1:复杂的问题需要更高效的计算能力与性能,如解码人类基因组问题。
Q 2 Q_2 Q2:为什么我们要建立并行系统
A 2 A_2 A2:到目前为止,性能的提升归因于晶体管密度的增加,但存在一些内在问题:
可以看到增加单个晶体管的密度存在局限,于是从单核系统向多核处理器转变。
Q 3 Q_3 Q3:为什么我们需要写并行程序
A 3 A_3 A3:对于原来的问题要用并行方案处理,可以编写自动将串行程序转换为并行程序的翻译程序,但成功案例有限,于是可以选择设计全新的算法。
Q 4 Q_4 Q4:我们如何编写并行程序?
A 4 A_4 A4:可以从两个方面来解决编写问题:
- 任务并行是指将一个大的任务分解成多个相对独立的子任务,这些子任务可以在多个处理器或计算单元上同时执行。例如,对于100份期末试卷,每张卷子四道题目。那么任务并行可以看成四个助教都只改1道题目,每人改100份。
- 数据并行是指将相同的计算任务应用于不同的数据块,这些数据块被分配到多个处理器或计算单元上同时进行处理。每个处理器执行相同的计算操作,但处理的数据不同。例如,对于100份期末试卷,每张卷子四道题目。那么数据并行可以看成四个助教改整张卷子,每人改25份。
Q 5 Q_5 Q5:我们要做什么?
A 5 A_5 A5:学习一门编程语言编写并行程序,首推C语言。使用C的三种不同的扩展(可以理解为库函数):
- MPI
- Pthreads
- OpenMP
Q 6 Q_6 Q6:并发、并行、分布式!
A 6 A_6 A6:定义辨析如下:
- 并发计算:多个任务可以在任何时刻进行。
- 并行计算:多个任务紧密合作来解决一个问题。
- 分布式计算:可能需要与其他程序合作来解决问题。
总结
- 简单的介绍课程。
Chapter2—并行硬件和并行软件
提纲

问答
Q 1 Q_1 Q1:冯诺依曼架构的瓶颈是:主存和CPU之间的分离,如何解决呢?
A 1 A_1 A1:核心是基于访存局部性原理设计的CPU缓存。
- 空间局部性(Spatial locality):访问临近的位置。
- 时间局部性(Temporal locality):最近访问的位置,在不久的将来还会访问。
- 缓存映射的三种类型:全相连,直接相连,组相联。
Q 2 Q_2 Q2:虚拟内存和虚拟页码
A 2 A_2 A2:虚拟内存:是作为二级存储器的高速缓存。它利用了时空局部性原理。
它只把正在运行的程序的活动部分保存在主存中。
虚拟页码:
-
当一个程序被编译时,它的页被分配虚拟页码/逻辑页码。
-
当程序运行时,会创建一个页表,将虚拟页码映射到物理地址。
-
页表用于将虚拟地址转换为物理地址。
Q 3 Q_3 Q3:多发射技术(Multiple Issue )
A 3 A_3 A3:多发处理器复制计算单元,同时执行程序中的不同指令,如下图: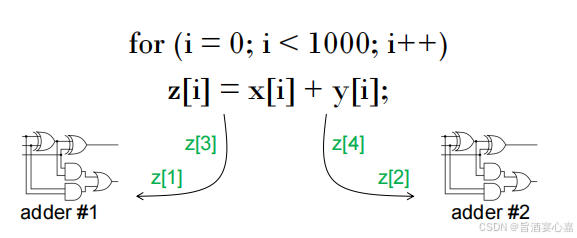
多发技术的分类:
- 静态多发:计算单元在编译时被安排。
- 动态多发:功能单元在运行时被安排。
Q 4 Q_4 Q4:硬件多线程
A 4 A_4 A4:硬件多线程提供了一种方法,当前正在执行的任务已经停止时,系统可以继续做其他有用的工作。
硬件多线程的分类:
- 细粒度的(Fine-grained ):处理器在每条指令之后,进行线程切换,跳过停止的线程。
- 粗粒度的(Coarse-grained):仅切换需要等待较长时间才能完成,而又被阻塞的线程。
Q 5 Q_5 Q5:并行硬件
A 5 A_5 A5:弗林的分类(Flynn’s Taxonomy),如下图:
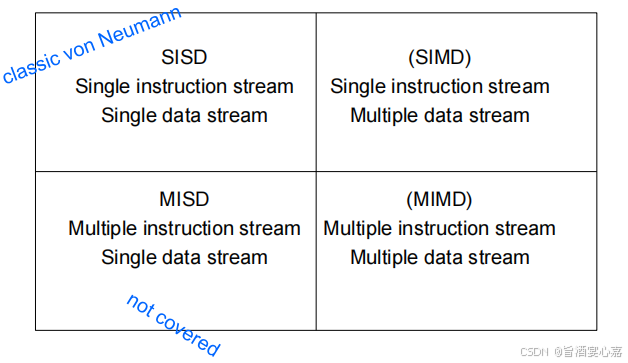
-
SIMD:通过在处理器之间划分数据而实现的并行性。将相同的指令应用于多个数据项叫做 data parallelism。例如4 个ALU 和15 数据项:
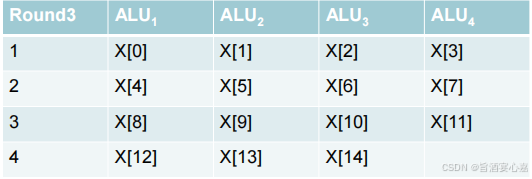
-
MIMD:支持多个数据流上同时运行多个指令流。通常由一组完全独立的处理单元或核心组成,每一个核心都有自己的控制单元(CU)和计算单元(ALU)。
Q 6 Q_6 Q6:共享存储器系统(Shared Memory System)
A 6 A_6 A6:共享存储器系统可以分为UMA和NUMA。
- UMA multicore system:统一内存访问多核系统,是一种多处理器计算机系统架构。
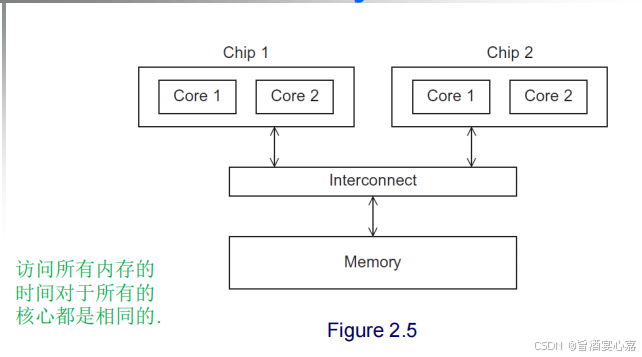
-
NUMA multicore system:非统一内存访问多核系统,是一种多处理器计算机系统架构。
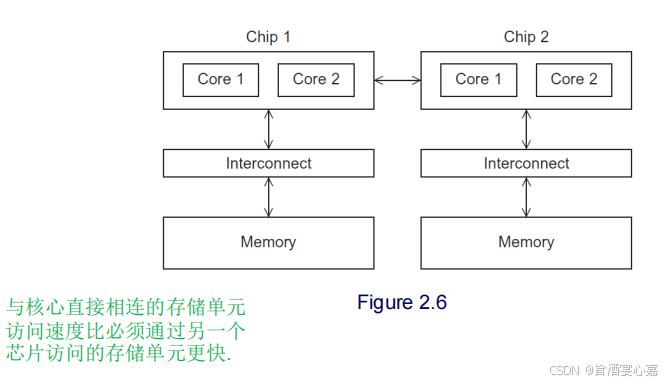
Q 7 Q_7 Q7:分布式系统(Distributed Memory System)
A 7 A_7 A7:集群的节点( Nodes )是单个计算单元,这些计算单元通过通信网络连接起来构成集群。如下图: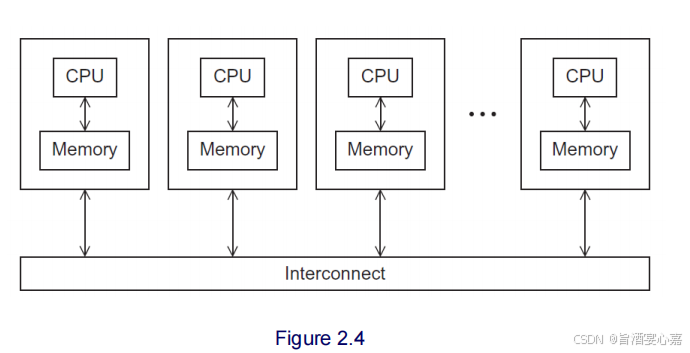
Q 8 Q_8 Q8:互联网络
A 8 A_8 A8:分为两类:共享内存互联(Shared memory interconnects)和分布式内存互联(Distributed memory interconnects)。
-
共享内存互联
- 总线互连
- 交换互联
-
分布式内存互联
- 直接互连
- 间接互连
Q 9 Q_9 Q9:性能检测指标
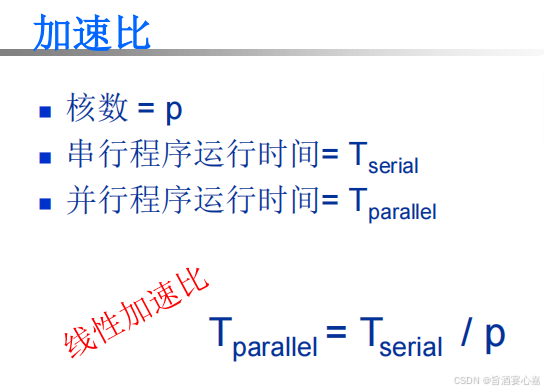
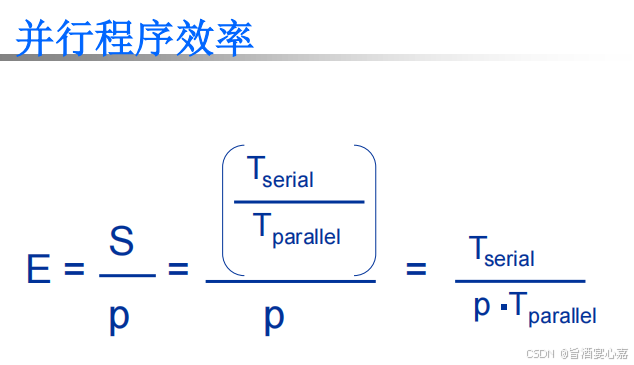
A 9 A_9 A9:加速比,效率
- 加速比 S = T s e r i a l T p a r a l l e l S = \frac{T_{serial}}{T_{parallel}} S=TparallelTserial。具体计算公式如下图:
-
效率 E = T s e r i a l P ∗ T p a r a l l e l E = \frac{T_{serial}}{P*T_{parallel}} E=P∗TparallelTserial。具体计算公式如下图:
-
可扩展性:粗略地讲,如果一个技术可以处理规模不断增加的问题,那么它就是可扩展的。
- 强可扩展(strongly scalable):如果在增加进程/线程的数量时,可以维持固定的效率,而不增加问题规模。
- 弱可扩展(weakly scalable):如果在增加进程/线程数量的同时,只有以相同倍率增加问题规模才能使效率值保持不变,
Q 10 Q_{10} Q10:Foster方法
A 10 A_{10} A10:
-
划分:将要执行的指令和数据按照计算拆分为多个小任务。
-
通信:确定前一步所识别出来的任务之间需要执行哪些通信。
-
聚集:将第一步中确定的任务和通信合并成更大的任务。
-
分配:将上一步聚合好的任务分配给进程/线程。
总结
-
基本概念居多,建议通过画图去加深理解。
-
本章是后面章节的基础
Chapter3—用MPI进行分布式内存编程
提纲

问答
Q 1 Q_1 Q1:第一个MPI程序如何运行?
A 1 A_1 A1:参考代码见下: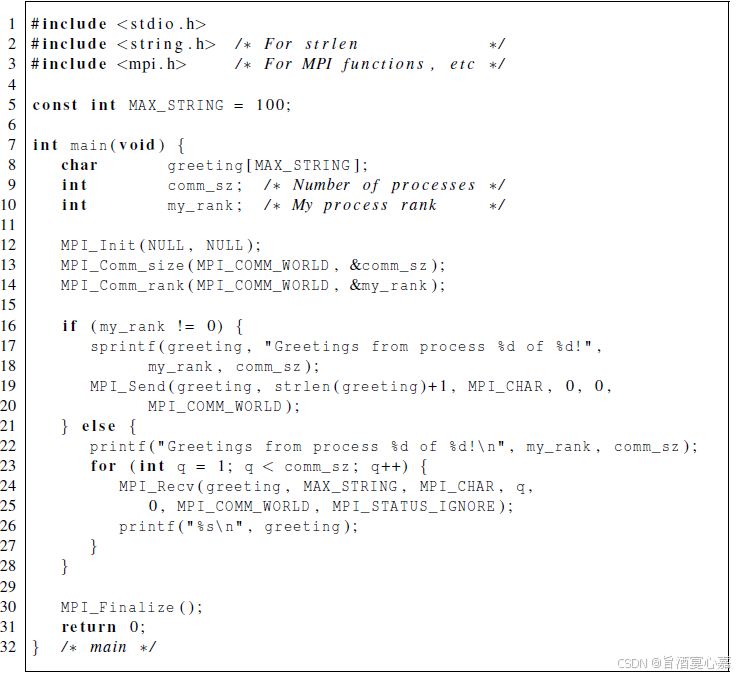
先编译后运行:
- 编译:mpicc -g -Wall -o mpi_hello mpi_hello.c
- 运行:mpiexec -n 。例如:mpiexec -n 1 ./mpi_hello
Q 2 Q_2 Q2:通信子
A 2 A_2 A2:可以互相发送信息的进程集合。特殊的,由用户启动的所有进程所组成的通信子称为’MPI_COMM_WORLD’.
Q 3 Q_3 Q3:MPI实现梯形积分法
A 3 A_3 A3:计算式子如下

并行代码如下:


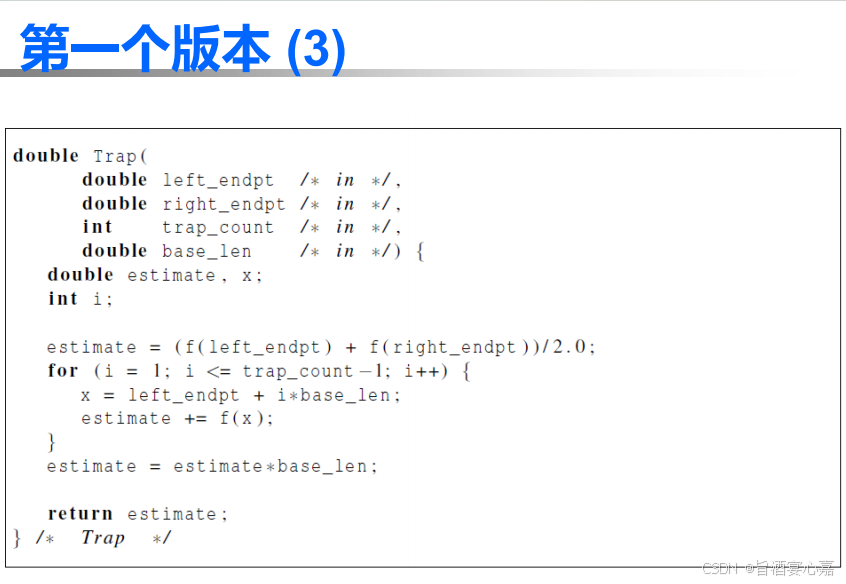
我的复习笔记批注: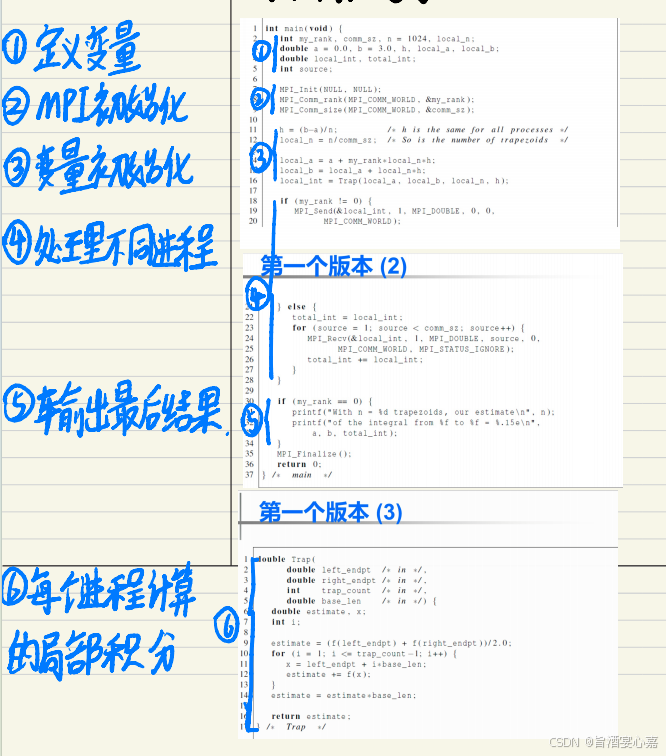
Q 4 Q_4 Q4:集合通信和点对点通信
A 4 A_4 A4:集合通信:通信子中的所有进程必须调用相同的集合通信函数。每个进程传递给 MPI 集合通信的参数必须是“相容的” 。点对点通信:通过标签和通信子来进行匹配。
Q 5 Q_5 Q5:函数MPI_Allreduce()
A 5 A_5 A5:
Q 6 Q_6 Q6:函数MPI_Bcast()
A 6 A_6 A6:
Q 7 Q_7 Q7:函数MPI_Scatter()
A 7 A_7 A7:
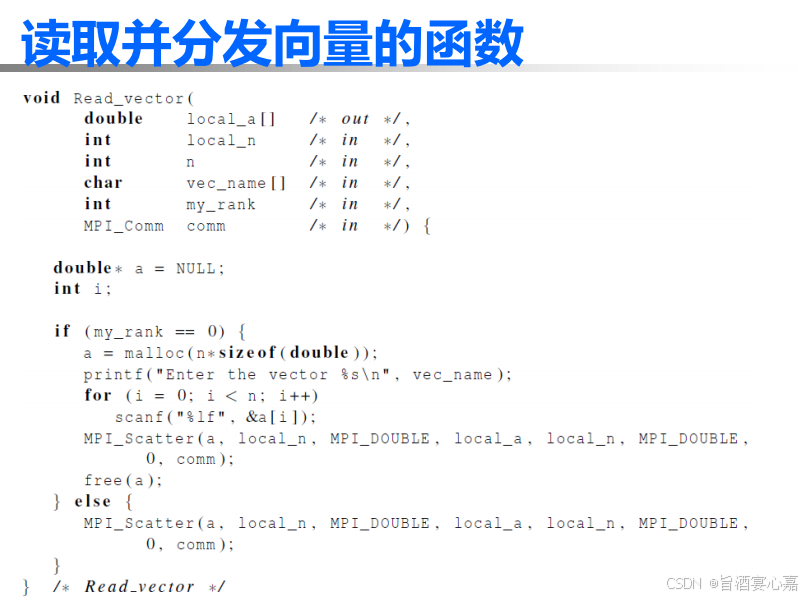
例如:

Q 8 Q_8 Q8:函数MPI_Gather()
A 8 A_8 A8:将向量的所有分量收集到进程0上,然后进程0就可以处理所有的分量了。
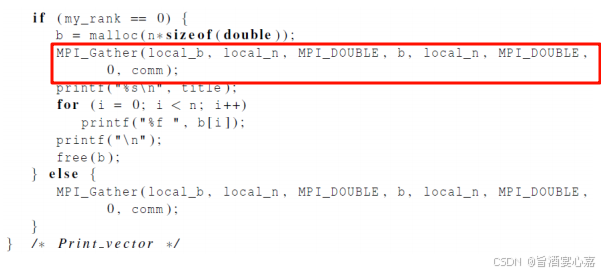
Q 9 Q_9 Q9:并行奇偶交替排序算法
A 9 A_9 A9:具体规则可以搜索,这里给一个demo
总结
- 重点了解MPI的一些函数的使用,例如MPI_Gather(),MPI_Bcast()。
- 结合经典案例强化对代码的编写,例如MPI实现梯形积分法。
Chapter4—用Pthread进行共享内存编程
提纲

问答
Q 1 Q_1 Q1:Pthreads的基本使用
A 1 A_1 A1:
编译:gcc -g wall -o pth_hello pth_hello.c -lpthread
运行:./pth_hello 4
Q 2 Q_2 Q2:pthread执行矩阵相乘
A 2 A_2 A2:
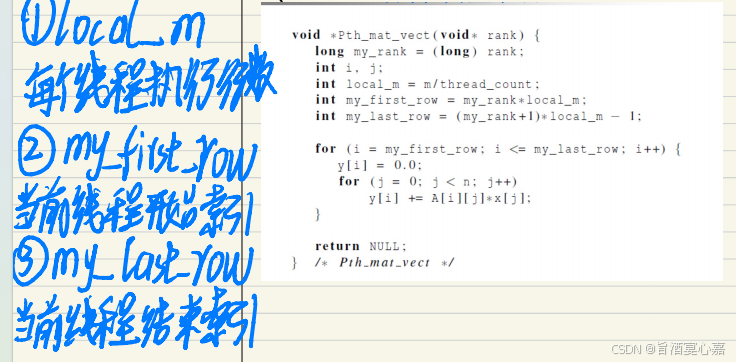
Q 3 Q_3 Q3:pthread估计Π值
A 3 A_3 A3:公式和对应代码如下: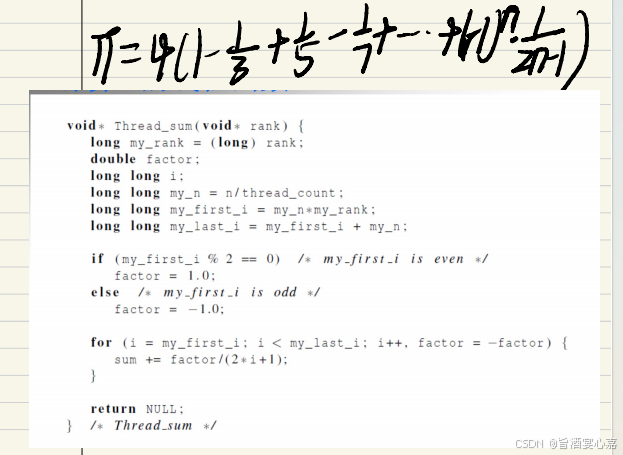
Q 4 Q_4 Q4:忙等待问题
A 4 A_4 A4:在忙等待中,线程不停地测试某个条件,但实际上,直到某个条件满足之前,不会执行任何有用的工作。

Q 5 Q_5 Q5:互斥量问题
A 5 A_5 A5:一个处于忙等待状态的线程任然会持续地使用CPU,而什么也没有完成。
互斥量(互斥锁)是一种特殊类型的变量,它可以限制每次只允许一个线程访问临界区。
Q 6 Q_6 Q6:路障和条件变量问题
A 6 A_6 A6:
- 路障:通过确保所有线程在程序中处于同一位置来同步线程,这个同步点又称为路障。
- 用信号量实现路障
- 用条件变量实现路障
Q 7 Q_7 Q7:读写锁问题
A 7 A_7 A7:使用多线程链表。例如两个线程同时访问链表。
-
解决方案1:
-
Pthread_mutex_lock(&list_mutex)
-
member(value)
-
Pthread_mutex_unlock(&list_mutex)
-
Q 8 Q_8 Q8:线程安全性
A 8 A_8 A8:
总结:
- 和MPI类似,熟悉经典案例的编程,先熟悉代码。
- 如果应付考试,比较多的零散知识点需要记忆。
Chapter5—用OpenMP进行共享内存编程
提纲

问答
Q 1 Q_1 Q1:线程组,主线程,从线程
A 1 A_1 A1:
- 线程组:执行并行块的线程集合
- 主线程:原始线程
- 从线程:额外线程
Q 2 Q_2 Q2:变量作用域
A 2 A_2 A2:
-
共享作用域:一个能够被线程组的所有线程访问的变量拥有。另外,在paralle指令前已经被声明的变量默认作用域是共享的。
-
私有作用域:一个只能被单个线程访问的变量拥有。
Q 3 Q_3 Q3:parallel for 指令
A 3 A_3 A3:系统通过在线程之间划分循环迭代来并行化循环。
Q 4 Q_4 Q4:数据依赖
A 4 A_4 A4:斐波那契数列会有数据依赖问题,所有并行会出错。
Q 5 Q_5 Q5:default子句
A 5 A_5 A5:
总结
- 和第二,三章类似。
Chapter6—并行程序开发
我们学院开设这门课程的实验是用上面学过的三种方法解决N体问题。网上应该有相应资料。认真做N体问题的实验应该可以强化理解,最后应该可以对并行计算这个方向入个门。当然我们学院这学期还开设了**‘并行计算程序设计(双语)’**课程,也就是主要学习利用GPU来并行编程,我后续整理出也发出来。
期末复习
选择题
学习通,错了就查资料。
简答题
下面是我复习时自己整理的几个可能会考的简答题,你们也可以自己整理。
1. 任务并行与数据并行
2.负载均衡,通信,同步三个概念
3.并发计算,并行计算,分布式计算三者的对比
4.冯诺依曼体系瓶颈问题及解决办法
5.缓存映射的三种方式
6. 分布式存储系统和共享式存储系统
7.阿达姆定律内容
8.Foster方法的步骤
9.缓存,缓存一致性问题,伪共享问题
10.矩阵向量乘的三种实现方式的异同
11.如何理解parallel for的静态线程和动态线程
12.Flyy的四种分类及主要特点
13.简要介绍一下流水线和多发射
14.忙等待,互斥量,信号量,临界区
15点对点通信和集合通信
15个问题的答案自己找,我举其中几个例子讲讲考试答题。
Demo1:如何理解任务并行与数据并行?
(1)任务并行是指将一个大的任务分解成多个相对独立的子任务,这些子任务可以在多个处理器或计算单元上同时执行。例如,对于100份期末试卷,每张卷子四道题目。那么任务并行可以看成四个助教都只改1道题目,每人改100份。
(2)数据并行是指将相同的计算任务应用于不同的数据块,这些数据块被分配到多个处理器或计算单元上同时进行处理。每个处理器执行相同的计算操作,但处理的数据不同。例如,对于100份期末试卷,每张卷子四道题目。那么数据并行可以看成四个助教改整张卷子,每人改25份。
(3)任务并行和数据并行是并行计算领域中的两种重要并行模式,常常需要联合两者共同解决问题,需要根据具体场景具体分析。
Demo2:如何理解共享式存储系统和分布式存储系统?
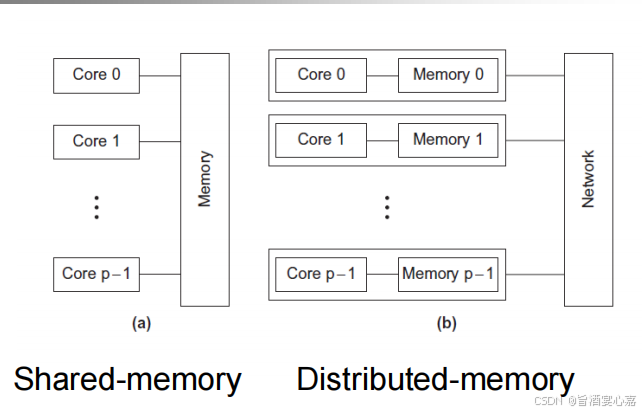
(1)共享式存储系统如图(a)所示,所有节点通过网络共享一个集中的存储设备。
(2)分布式存储系统如图(b)所示,每一个节点都有私有内存,可以独立的进行数据。存储和处理。各个节点通过网络相连。
(3)共享式存储系统和分布式存储系统是两种不同的存储架构,常常需要联合两者共同解决问题,需要根据具体场景具体分析。
举了两个例子,答题技巧悟到了嘛?
- 点面写法:比如demo1中我是不是举了一个助教批改的例子。
- 图文结合:比如demo2我是不是答题先画图再看图说话呀。
- 总分结合:比如demo1和demo2是不是都分别讲概念,再讲两者之间的联系。
其实这三个技巧就是写学术论文的基本套路,sci的论文也会用到。
注意考试答题是**“让改卷者知道你学明白这个知识点。所以怎么利于表达怎么来”。当然面试不是一样的嘛?上面的那些简答题完全可以出现在企业面试/研究生面试来提问。那么,你是否明白了“如何征服你的听众/读者”呢?**
编程题
在理解的基础上,代码多敲几次,草稿纸多默写几次就可以了。常考的就那么几个,都在ppt上。每个案例可能有多种实现方式(Mpi,Pthread,Openmp,),注意区别。
典型案例有:
- 1.矩阵向量乘法
- 2.曲边梯形面积计算
- 3.数学求和公式/蒙特卡洛方法计算π
- 4.奇偶交换排序

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)