DWS 层-访客主题宽表的计算
设计一张 DWS 层的表其实就两件事:维度和度量(事实数据)➢ 度量包括 PV、UV、跳出次数、进入页面数(session_count)、连续访问时长➢ 维度包括在分析中比较重要的几个字段:渠道、地区、版本、新老用户进行聚合1.1、需求分析与思路➢ 接收各个明细数据,变为数据流➢ 把数据流合并在一起,成为一个相同格式对象的数据流➢ 对合并的流进行聚合,聚合的时间窗口决定了数据的时效性➢ 把聚合结果
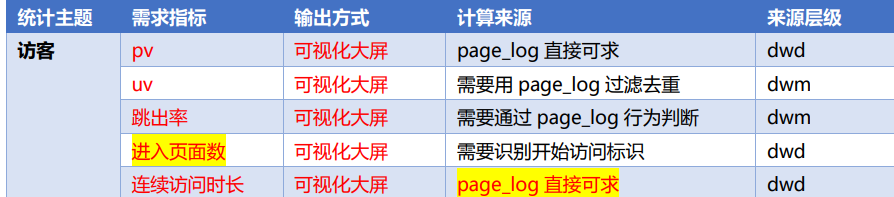
设计一张 DWS 层的表其实就两件事:维度和度量(事实数据)
➢ 度量包括 PV、UV、跳出次数、进入页面数(session_count)、连续访问时长
➢ 维度包括在分析中比较重要的几个字段:渠道、地区、版本、新老用户进行聚合
1.1、需求分析与思路
➢ 接收各个明细数据,变为数据流
➢ 把数据流合并在一起,成为一个相同格式对象的数据流
➢ 对合并的流进行聚合,聚合的时间窗口决定了数据的时效性
➢ 把聚合结果写在数据库中
1.2、功能实现
1.2.1、读取 Kafka 各个流数据
//TODO 2.从kafka主题中读取数据
//2.1 声明读取的主题名以及消费者组
String pageViewSourceTopic = "dwd_page_log";
String uniqueVisitSourceTopic = "dwm_unique_visit";
String userJumpDetailSourceTopic = "dwm_user_jump_detail";
String groupId = "visitor_stats_app";
//2.2 从dwd_page_log主题中读取日志数据
FlinkKafkaConsumer<String> pageViewSource = MyKafkaUtil.getKafkaSource(pageViewSourceTopic, groupId);
DataStreamSource<String> pvJsonStrDS = env.addSource(pageViewSource);
//2.3 从dwm_unique_visit主题中读取uv数据
FlinkKafkaConsumer<String> uvSource = MyKafkaUtil.getKafkaSource(uniqueVisitSourceTopic, groupId);
DataStreamSource<String> uvJsonStrDS = env.addSource(uvSource);
//2.4 从dwm_user_jump_detail主题中读取跳出数据
FlinkKafkaConsumer<String> userJumpSource = MyKafkaUtil.getKafkaSource(userJumpDetailSourceTopic, groupId);
DataStreamSource<String> userJumpJsonStrDS = env.addSource(userJumpSource);
1.2.2、合并数据流
把数据流合并在一起,成为一个相同格式对象的数据流
合并数据流的核心算子是 union。但是 union 算子,要求所有的数据流结构必须一致。所以 union 前要调整数据结构
1.2.2.1、访客统计实体类
为了能够合并为一个相同格式对象的数据流
@Data
@AllArgsConstructor
public class VisitorStats {
//统计开始时间
private String stt;
//统计结束时间
private String edt;
//维度:版本
private String vc;
//维度:渠道
private String ch;
//维度:地区
private String ar;
//维度:新老用户标识
private String is_new;
//度量:独立访客数
private Long uv_ct=0L;
//度量:页面访问数
private Long pv_ct=0L;
//度量: 进入次数 (session_count)
private Long sv_ct=0L;
//度量: 跳出次数
private Long uj_ct=0L;
//度量: 持续访问时间
private Long dur_sum=0L;
//统计时间
private Long ts;
}
1.2.2.2、对读取的各个数据流进行结构的转换

// TODO 3.对各个流的数据进行结构的转换 jsonStr->VisitorStats
// 3.1 转换pv流
SingleOutputStreamOperator<VisitorStats> pvStatsDS = pvJsonStrDS.map(
new MapFunction<String, VisitorStats>() {
@Override
public VisitorStats map(String jsonStr) throws Exception {
//将json格式字符串转换为json对象
JSONObject jsonObj = JSON.parseObject(jsonStr);
VisitorStats visitorStats = new VisitorStats(
"",
"",
jsonObj.getJSONObject("common").getString("vc"),
jsonObj.getJSONObject("common").getString("ch"),
jsonObj.getJSONObject("common").getString("ar"),
jsonObj.getJSONObject("common").getString("is_new"),
0L,
1L,
0L,
0L,
jsonObj.getJSONObject("page").getLong("during_time"),
jsonObj.getLong("ts")
);
return visitorStats;
}
}
);
// 3.2 转换uv流
SingleOutputStreamOperator<VisitorStats> uvStatsDS = uvJsonStrDS.map(
new MapFunction<String, VisitorStats>() {
@Override
public VisitorStats map(String jsonStr) throws Exception {
//将json格式字符串转换为json对象
JSONObject jsonObj = JSON.parseObject(jsonStr);
VisitorStats visitorStats = new VisitorStats(
"",
"",
jsonObj.getJSONObject("common").getString("vc"),
jsonObj.getJSONObject("common").getString("ch"),
jsonObj.getJSONObject("common").getString("ar"),
jsonObj.getJSONObject("common").getString("is_new"),
1L,
0L,
0L,
0L,
0L,
jsonObj.getLong("ts")
);
return visitorStats;
}
}
);
//3.3 转换sv流(Session_count) 其实还是从dwd_page_log中获取数据
SingleOutputStreamOperator<VisitorStats> svStatsDS = pvJsonStrDS.process(
new ProcessFunction<String, VisitorStats>() {
@Override
public void processElement(String jsonStr, Context ctx, Collector<VisitorStats> out) throws Exception {
//将json格式字符串转换为json对象
JSONObject jsonObj = JSON.parseObject(jsonStr);
//获取当前页面的lastPageId
String lastPageId = jsonObj.getJSONObject("page").getString("last_page_id");
if (lastPageId == null || lastPageId.length() == 0) {
VisitorStats visitorStats = new VisitorStats(
"",
"",
jsonObj.getJSONObject("common").getString("vc"),
jsonObj.getJSONObject("common").getString("ch"),
jsonObj.getJSONObject("common").getString("ar"),
jsonObj.getJSONObject("common").getString("is_new"),
0L,
0L,
1L,
0L,
0L,
jsonObj.getLong("ts")
);
out.collect(visitorStats);
}
}
}
);
//3.4 转换跳出流
SingleOutputStreamOperator<VisitorStats> userJumpStatsDS = userJumpJsonStrDS.map(
new MapFunction<String, VisitorStats>() {
@Override
public VisitorStats map(String jsonStr) throws Exception {
//将json格式字符串转换为json对象
JSONObject jsonObj = JSON.parseObject(jsonStr);
VisitorStats visitorStats = new VisitorStats(
"",
"",
jsonObj.getJSONObject("common").getString("vc"),
jsonObj.getJSONObject("common").getString("ch"),
jsonObj.getJSONObject("common").getString("ar"),
jsonObj.getJSONObject("common").getString("is_new"),
0L,
0L,
0L,
1L,
0L,
jsonObj.getLong("ts")
);
return visitorStats;
}
}
);
1.2.2.3、合并数据流
//TODO 4. 将4条流合并到一起 注意:只能合并结构相同的流
DataStream<VisitorStats> unionDS = pvStatsDS.union(uvStatsDS, svStatsDS, userJumpStatsDS);
1.2.3、维度聚合
1.2.3.1、设置时间标记及水位线
//TODO 5.设置Watermmark以及提取事件时间
SingleOutputStreamOperator<VisitorStats> visitorStatsWithWatermarkDS = unionDS.assignTimestampsAndWatermarks(
WatermarkStrategy.<VisitorStats>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
new SerializableTimestampAssigner<VisitorStats>() {
@Override
public long extractTimestamp(VisitorStats visitorStats, long recordTimestamp) {
return visitorStats.getTs();
}
}
)
);
1.2.3.2、分组
分组选取四个维度作为 key , 使用 Tuple4 组合
//TODO 6.分组 按照地区、渠道、版本、新老访客维度进行分组,因为我们这里有4个维度,所以将它们封装为一个Tuple4
KeyedStream<VisitorStats, Tuple4<String, String, String, String>> keyedDS = visitorStatsWithWatermarkDS.keyBy(
new KeySelector<VisitorStats, Tuple4<String, String, String, String>>() {
@Override
public Tuple4<String, String, String, String> getKey(VisitorStats visitorStats) throws Exception {
return Tuple4.of(
visitorStats.getAr(),
visitorStats.getCh(),
visitorStats.getVc(),
visitorStats.getIs_new()
);
}
}
);
1.2.3.3、开窗
//TODO 7.开窗
WindowedStream<VisitorStats, Tuple4<String, String, String, String>, TimeWindow> windowDS = keyedDS.window(
TumblingEventTimeWindows.of(Time.seconds(10))
);
1.2.3.4、窗口内聚合及补充时间字段
通过上线文获取窗口的开始结束时间 context.window().getStart())
//TODO 8.对窗口的数据进行聚合 聚合结束之后,需要补充统计的起止时间
SingleOutputStreamOperator<VisitorStats> reduceDS = windowDS.reduce(
new ReduceFunction<VisitorStats>() {
@Override
public VisitorStats reduce(VisitorStats stats1, VisitorStats stats2) throws Exception {
stats1.setPv_ct(stats1.getPv_ct() + stats2.getPv_ct());
stats1.setUv_ct(stats1.getUv_ct() + stats2.getUv_ct());
stats1.setSv_ct(stats1.getSv_ct() + stats2.getSv_ct());
stats1.setDur_sum(stats1.getDur_sum() + stats2.getDur_sum());
return stats1;
}
},
new ProcessWindowFunction<VisitorStats, VisitorStats, Tuple4<String, String, String, String>, TimeWindow>() {
@Override
public void process(Tuple4<String, String, String, String> tuple4, Context context, Iterable<VisitorStats> elements, Collector<VisitorStats> out) throws Exception {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for (VisitorStats visitorStats : elements) {
//获取窗口的开始时间
String startDate = sdf.format(new Date(context.window().getStart()));
//获取窗口的结束时间
String endDate = sdf.format(new Date(context.window().getEnd()));
visitorStats.setStt(startDate);
visitorStats.setEdt(endDate);
visitorStats.setTs(new Date().getTime());
out.collect(visitorStats);
}
}
}
);
1.2.4、写入 OLAP 数据库
为何要写入 ClickHouse 数据库,ClickHouse 数据库作为专门解决大量数据统计分析的数据库,在保证了海量数据存储的能力,同时又兼顾了响应速度。而且还支持标准 SQL,即灵活又易上手。
1.2.4.1、ClickHouse 数据表准备
create table visitor_stats (
stt DateTime,
edt DateTime,
vc String,
ch String ,
ar String ,
is_new String ,
uv_ct UInt64,
pv_ct UInt64,
sv_ct UInt64,
uj_ct UInt64,
dur_sum UInt64,
ts UInt64
) engine =ReplacingMergeTree( ts)
partition by toYYYYMMDD(stt)
order by ( stt,edt,is_new,vc,ch,ar);
之所以选用 ReplacingMergeTree 引擎主要是靠它来保证数据表的幂等性。
➢ paritition by 把日期变为数字类型(如:20201126),用于分区。所以尽量保证查询条件尽量包含 stt 字段。
➢ order by 后面字段数据在同一分区下,出现重复会被去重,重复数据保留 ts 最大的数据。
1.2.4.2、依赖包
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
其中 flink-connector-jdbc 是官方通用的 jdbcSink 包。只要引入对应的 jdbc 驱动,flink 可以用它应对各种支持 jdbc 的数据库,比如 phoenix 也可以用它。但是这个 jdbc-sink 只支持数据流对应一张数据表。如果是一流对多表,就必须通过自定义的方式实现了,比如之前的维度数据。
虽然这种 jdbc-sink 只能一流对一表,但是由于内部使用了预编译器,所以可以实现批量提交以优化写入速度。
1.2.4.3、增加 ClickhouseUtil
JdbcSink.<T>sink( )的四个参数说明
➢ 参数 1: 传入 Sql,格式如:insert into xxx values(?,?,?,?)
➢ 参数 2: 可以用 lambda 表达实现(jdbcPreparedStatement, t) -> t 为数据对象,要装配到语句预编译器的参数中。
➢ 参数 3:设定一些执行参数,比如重试次数,批次大小。
➢ 参数 4:设定连接参数,比如地址,端口,驱动名。
1、ClickhouseUtil 中获取 JdbcSink 函数的实现
com.chb.realtime.utils.ClickHouseUtil.getJdbcSink
2、创建 TransientSink 注解,该注解标记不需要保存的字段
由于之前的 ClickhouseUtil 工具类的写入机制就是把该实体类的所有字段按次序一次写入数据表。但是实体类有时会用到一些临时字段,计算中有用但是并不需要最终保存在临时表中。我们可以把这些字段做一些标识,然后再写入的时候判断标识来过滤掉这些字段。
为字段打标识通常的办法就是给字段加个注解,这里我们就增加一个自定义注解@TransientSink 来标识该字段不需要保存到数据表中。
1.2.4.4、为主程序增加写入 ClickHouse 的 Sink
//TODO 9.向Clickhouse中插入数据
reduceDS.addSink(
ClickHouseUtil.getJdbcSink("insert into visitor_stats values(?,?,?,?,?,?,?,?,?,?,?,?)")
);
1.2.5、 整体测试
➢ 启动 ZK、Kafka、logger.sh、ClickHouse、【HDFS】
➢ 运行 BaseLogApp
➢ 运行 UniqueVisitApp
➢ 运行 UserJumpDetailApp
➢ 运行 VisitorStatsApp
➢ 运行 rt_applog 目录下的 jar 包
➢ 查看控制台输出
➢ 查看 ClickHouse 中 visitor_stats 表数据

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)