spark连接mysql创建hive表_Spark SQL操作Hive数据库
http://kevin12.iteye.com/blog/2273532Spark集群搭建:http://kevin12.iteye.com/blog/2273532数据准备在/usr/local/sparkApps/SparkSQL2Hive/resources/目录下创建people.txt内容如下,name和age之间是"\t"分割Michael 20Andy 17Justin...
http://kevin12.iteye.com/blog/2273532
Spark集群搭建:http://kevin12.iteye.com/blog/2273532
数据准备
在/usr/local/sparkApps/SparkSQL2Hive/resources/目录下创建people.txt内容如下,name和age之间是"\t"分割
Michael 20
Andy 17
Justin 19
创建份数peopleScores.txt,内容如下,name和score之间用“\t”分割
Michael 98
Andy 95
Justin 68
代码实现
package com.imf.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.hive.HiveContext
/**
* 通过spark sql操作hive数据源
*/
object SparkSQL2Hive {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setAppName("SparkSQL2Hive for scala")
conf.setMaster("spark://master1:7077")
val sc = new SparkContext(conf)
val hiveContext = new HiveContext(sc)
//用户年龄
hiveContext.sql("use testdb")
hiveContext.sql("DROP TABLE IF EXISTS people")
hiveContext.sql("CREATE TABLE IF NOT EXISTS people(name STRING, age INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' LINES TERMINATED BY '\\n'")
//把本地数据加载到hive中(实际上发生了数据拷贝),也可以直接使用HDFS中的数据
hiveContext.sql("LOAD DATA LOCAL INPATH '/usr/local/sparkApps/SparkSQL2Hive/resources/people.txt' INTO TABLE people")
//用户份数
hiveContext.sql("use testdb")
hiveContext.sql("DROP TABLE IF EXISTS peopleScores")
hiveContext.sql("CREATE TABLE IF NOT EXISTS peopleScores(name STRING, score INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' LINES TERMINATED BY '\\n'")
hiveContext.sql("LOAD DATA LOCAL INPATH '/usr/local/sparkApps/SparkSQL2Hive/resources/peopleScore.txt' INTO TABLE peopleScores")
/**
* 通过HiveContext使用join直接基于hive中的两种表进行操作
*/
val resultDF = hiveContext.sql("select pi.name,pi.age,ps.score "
+" from people pi join peopleScores ps on pi.name=ps.name"
+" where ps.score>90");
/**
* 通过saveAsTable创建一张hive managed table,数据的元数据和数据即将放的具体位置都是由
* hive数据仓库进行管理的,当删除该表的时候,数据也会一起被删除(磁盘的数据不再存在)
*/
hiveContext.sql("drop table if exists peopleResult")
resultDF.saveAsTable("peopleResult")
/**
* 使用HiveContext的table方法可以直接读取hive数据仓库的Table并生成DataFrame,
* 接下来机器学习、图计算、各种复杂的ETL等操作
*/
val dataframeHive = hiveContext.table("peopleResult")
dataframeHive.show()
}
}
调度脚本
并将上面的程序打包成SparkSQL2Hive.jar,将SparkSQL2Hive.jar拷贝到/usr/local/sparkApps/SparkSQL2Hive/目录下面,并创建调度脚本run.sh,内容如下:
/usr/local/spark/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \
--class com.imf.spark.sql.SparkSQL2Hive \
--files /usr/local/hive/apache-hive-1.2.1-bin/conf/hive-site.xml \
--master spark://master1:7077 \
/usr/local/sparkApps/SparkSQL2Hive/SparkSQL2Hive.jar
#如果已经将msyql的驱动放到了spark的lib目录下面,则不用在添加下面的mysql的驱动了
#--driver-class-path /usr/local/hive/apache-hive-1.2.1-bin/lib/mysql-connector-java-5.1.35-bin.jar \
执行结果
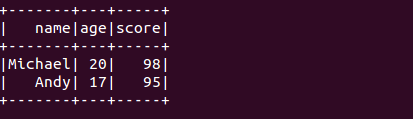
详细执行的日志见附件 run.log
用hive来查看表内容和执行结果
root@master1:/usr/local/tools# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/spark/spark-1.6.0-bin-hadoop2.6/lib/spark-assembly-1.6.0-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/spark/spark-1.6.0-bin-hadoop2.6/lib/spark-assembly-1.6.0-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/usr/local/hive/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive> show databases;
OK
default
testdb
Time taken: 1.013 seconds, Fetched: 2 row(s)
hive> use testdb;
OK
Time taken: 0.103 seconds
hive> show tables;
OK
people
peopleresult
peoplescores
student
student2
student3
student4
tbsogou
tmp_pre_hour_seach_info
Time taken: 0.082 seconds, Fetched: 9 row(s)
hive> select * from people;
OK
Michael 20
Andy 17
Justin 19
Time taken: 1.252 seconds, Fetched: 3 row(s)
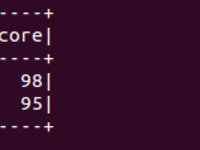
hive> select * from peoplescores;
OK
Michael 98
Andy 95
Justin 68
Time taken: 0.142 seconds, Fetched: 3 row(s)
hive> select * from peopleresult;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
Michael 20 98
Andy 17 95
Time taken: 0.298 seconds, Fetched: 2 row(s)
hive>
至此,通过SparkSQL操作hive数据库成功!
大小: 6.3 KB
下载次数: 22
分享到:


2016-04-13 22:37
浏览 17099
评论
2 楼
lwb314
2018-05-21
你的这个是创建的临时的hive表,数据也是通过文件录入进去的,如想读取hive数据库的数据应该怎么写?
1 楼
yixiaoqi2010
2017-04-13
你好 我的提交上去 总是报错,找不到hive表,可能是哪里的原因呢,--files也加上了,
但是我在./spark-shell --master 上就能访问hive表,不知道是什么问题

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)