全球具身智能2024进展回顾
过去几个月,具身智能领域的进展可谓令人瞩目,进展速度令人振奋。尽管人工智能从数字世界向物理世界的过渡仍面临诸多挑战,但随着才华横溢的研究人员不断投入其中,我们已经见证了无数令人惊叹的突破。几年后回顾这一切,这无疑将成为人类科技史上的重要篇章。我们离创造出匹敌甚至超越人类智能的硅基生命体越来越近了。这不仅是技术的胜利,也是人类自身对智能本质的一次深刻对话。
0. 简介
具身智能是人工智能领域备受关注且发展迅速的一个方向。今年以来,无论是学术界还是工业界都在这一领域取得了令人振奋的新进展。这些进展不仅提升了具身智能系统的性能和能力,也拓展了其潜在的应用领域。无论具体的技术思路如何,它们都拥有一个共同的目标,即赋予智能系统环境感知、理解和交互的能力。
在接下来的系列文章中,CerboAI研究团队将介绍不同范式的代表作品,解读其创新之处,并洞察具身智能未来的发展趋势。
1. 控制论控制理论范式
今年 2 月,知名机器人公司波士顿动力展示了其尖端人形机器人 Atlas,该机器人可执行仓库内运输汽车零件等任务。尽管波士顿动力已经掌握了各种双足运动技能,如行走、跑步、跳跃甚至后空翻,但物体操控仍处于早期阶段。Atlas 新设计的手有三根手指,每根手指有两个关节,可以 360 度旋转。与之前的夹持式手相比,这些手指可以更精确地抓取物体。尽管 Atlas 在视频中展示的智能是预先编程的,并且它事先知道汽车支架的 3D 扫描模型,但其精确的抓取操作仍然令人印象深刻。

Atlas 学会拿起 30 磅重的汽车支架并小心地操作它
与此同时,波士顿动力公司正越来越多地将强化学习融入其机器狗 Spot 的运动控制系统中。他们宣布与 NVIDIA 和 AI 研究所合作推出新的 Spot RL 研究套件,其中包括带有关节级控制 API 的 Spot、使用 NVIDIA Jetson AGX Orin 进行计算的 RL 策略部署,以及基于 NVIDIA Isaac Lab 的 GPU 加速 Spot 模拟环境。该研究套件使开发人员能够为 Spot 创建高级技能。

波士顿动力 Spot RL 研究套件
Spot 采用两种不同的控制策略:模型预测控制 (MPC) 和强化学习 (RL)。传统的 MPC 控制器预测机器人的未来状态,并将其公式化为优化问题,以确定当前的动作。这种方法直观、可调试,适用于可以准确建模机器人状态和环境的情况。Spot 的 MPC 控制器可以在多个时间尺度上做出决策,包括路径选择、步态模式以及实时调整姿势和步态时间以保持平衡。为了实现这种多尺度决策,Spot 会同时评估多个 MPC 控制器,并选择得分最高的控制器作为输出来指挥机器人的动作。
然而,在复杂环境中,准确建模具有挑战性,Spot 采用了数据驱动的强化学习。RL 通过在模拟环境中反复试验来优化神经网络实施的策略。这种方法消除了工程师手动编写控制器代码的需求,而是专注于设计模拟场景和定义优化目标(奖励函数)。RL 擅长解决易于模拟但难以用代码描述的问题。Spot 的运动控制系统巧妙地结合了 MPC 和 RL 方法的优势,MPC 专注于基于模型的运动控制,而 RL 则专注于学习更具挑战性的策略组件。这种组合不仅充分利用了两种方法的优势,还降低了生成控制器的计算复杂性,无需同时运行多个 MPC 实例。
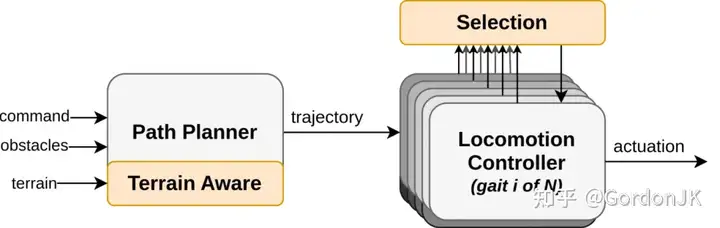
集成 RL 策略的运动控制系统
就在几周前,波士顿动力公司发布了下一代 Atlas,从液压驱动过渡到纯电动驱动,并配备了新的 AI 和机器学习工具,包括强化学习和计算机视觉。这确保了它们能够在复杂的现实环境中灵活应对各种挑战,展现出卓越的运动能力和环境适应能力。它代表了机器人控制技术的重大进步,为未来智能机器人的设计和应用提供了新的见解。
总之,传统控制理论范式正在积极拥抱AI,在机器人领域,波士顿动力公司脱颖而出,这家老牌机器人巨头通过电气化与AI的融合,焕发新生。
2. 计算机视觉思想流派
李飞飞在《寻找计算机视觉的北极星》一文中,定义了计算机视觉未来的“北极星”,即具身人工智能、视觉推理和社交智能。具身人工智能不同于简单地识别图像中的物体,它需要现实世界中的物理运动,并通过摄像头等传感器与环境交互。这需要对三维空间和动态环境有更深入的理解。具身人工智能不仅涉及视觉感知,还需要视觉推理,理解场景中的三维关系,并根据视觉信息预测和执行复杂任务。
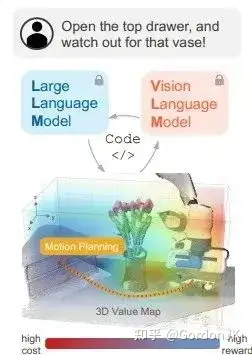
去年年底,李飞飞团队发表了一篇名为 Voxposer 的论文,介绍了一种基于 LLM(Language to Layout Module,语言到布局模块)和 VLM(Vision to Layout Module,视觉到布局模块)的开放指令和开放物体轨迹规划器。这一进步将机器人建图和任务规划的边界推向了新的阶段。例如,对于“打开抽屉,但要小心花瓶”的指令,LLM 会分析该指令,并理解抽屉是轨迹的吸引区域(affordance_map),而花瓶是约束区域(constraint_map)。然后,利用 VLM 获得花瓶和抽屉的具体位置。LLM 生成代码以构建 3D Value Map,运动规划器可以零样本方式合成机器人执行任务的轨迹。通过利用大模型的理解能力,即使是对未见过的任务,它也可以在不需要大量训练数据的情况下进行规划。这在路径规划中是前所未有的,并展示了 VLM 的视觉推理能力。在这种方法中,VLM 本质上为低级策略提供了一个奖励函数(MPC 的成本和 RL 的奖励)。它的前景依赖于大规模视觉模型和 3D 视觉的发展。这种方法的局限性在于低级运动规划器可能无法很好地推广,因此很难推广到各种场景、物体和机械臂。如果Value Map表达的容量和精度不足,可能会阻碍低级 MPC 实现预期目标。
Voxposer 从 LLM 中提取语言条件下的可供性和约束,并使用 VLM 将它们接地到感知空间
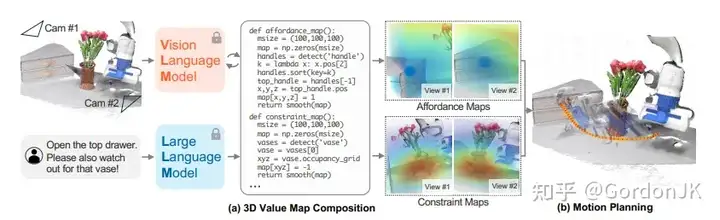
该组合图被称为 3D 价值图,它能够对具有开放指令集和开放对象集的各种日常操作任务的轨迹进行零样本合成。
Voxposer 的感知部分工作量不大,利用开放词汇检测器 OWL-ViT 获取边界框,使用 SAM 进行遮罩mask处理,使用视频跟踪器 XMEM 跟踪mask,再将跟踪到的遮罩与 RGB-D 结合重建 3D 点云。目前前端感知能力还比较有限,无法完成对形状和姿态敏感的任务。目前各个团队都在努力提升 3D 感知能力,将深度估计、光流估计、点云等 3D 相关多模态数据与大规模模型相结合,提升模型的 3D 推理、定位和空间理解能力,MIT、UCLA、北京大学等机构均已发表相关工作。
总之,计算机视觉这些年在感知方面取得了长足进步,但在认知方面还处于发展的早期阶段。VLM大模型无疑为计算机视觉领域带来了新的创新火花。未来,我们希望在三维理解、空间推理方面有更多突破,最终成为具身机器人认知世界的基础。
3. 世界模型类型
2024 年 3 月,知名 AI 机器人初创公司 Covariant 推出了机器人基础模型 1 (RFM-1),这是世界上第一个基于真实世界任务数据进行训练的大规模机器人模型,与解决真实世界任务的能力非常相似。RFM-1 拥有 80 亿个参数,被设计为多模态序列模型,已针对文本、图像、视频、机器人动作和一系列数值传感器读数进行了全面训练。通过将来自所有模态的数据投影到统一空间并执行自回归下一个标记预测任务,RFM-1 通过其灵活的输入输出模式适应不同的应用需求。
世界模型的出现代表了物理模拟领域的未来发展方向。与传统的模拟方法相比,它们具有显著的优势,能够在信息不完整的情况下推理交互,满足实时计算需求,并随着时间的推移提高预测准确性。这些世界模型的预测能力至关重要,因为它们使机器人能够发展在人类世界中运行所需的物理直觉。RFM-1 对物理世界的理解源于其生成视频的学习过程。通过将初始图像和机器人动作作为输入,它可以预测视频帧的后续变化。这种以动作为条件的视频预测任务使 RFM-1 成为能够掌握模拟世界中瞬时变化的低级世界模型。然而,在某些情况下,对机器人行为的更高级别的预测可能更有效。得益于 Covariant 提供的结构化多模态数据集和 RFM-1 灵活的“任何事物到任何事物”架构,它也能够提供这样的高级世界模型。该模型不仅可以理解预先定义的机器人动作,还可以推断这些动作是否可以成功执行,并通过预测下一个 token 来确定物料盒内容的变化。这种高保真世界模型对于在线决策和规划,以及其他模型和策略的离线训练非常有用。

RFM-1根据初始图像(左上)和指定要拾取的物品(右上)模拟拾取动作(左下),实际的真实世界选择结果位于右下角。

如果从初始手提袋(左)中选择了特定物品,则 RFM-1 生成的图像会显示手提袋的预测外观(右)。
特斯拉的 Optimus 采用与自动驾驶技术相同的 AI 系统,具有由经过充分训练的端到端神经网络管理的视觉导航系统。唯一的区别是增加了一个动作参考库,其中记录了现实世界中的人类动作并映射到机器人身上。特斯拉的全自动驾驶 (FSD) 系统经历了三个阶段,逐渐从模块化过渡到端到端架构。
-
在第一阶段,2021 年的 FSD 由两个模块组成:负责视觉任务的 HydraNet 和用于规划模块的蒙特卡洛树搜索和神经网络的组合。
-
在 2022 年推出的第二阶段,加入了Occupancy占用网络,HydraNet 检测物体、地标和车道线,而占用网络提供 3D 建模。规划模块仍然是蒙特卡洛树搜索和神经网络的组合,包括手动规划和轨迹评分。
-
在第三阶段,FSD 升级到版本 12,并在端到端架构方面取得了重大进展。将规划模块转化为深度学习,分别训练感知模块和规划模块,并联合优化两个模块,以最小化整体损失函数,使得最终输出的梯度可以传播回初始输入。
特斯拉的 FSD 越来越像一个黑匣子,虽然 Occupancy Networks、HydraNets、Planning 等模块的存在仍可见迹。这些模块组装和协调,以实现最优的总体目标。不过,埃隆·马斯克有更大的野心,要走向纯粹的端到端方法。他们计划使用 1000 万个带注释、按级别分类的视频数据来训练模型,以模仿优秀驾驶员的行为。这样,当模型遇到未知场景时,它可以通过生成找到并采用最接近的行为。
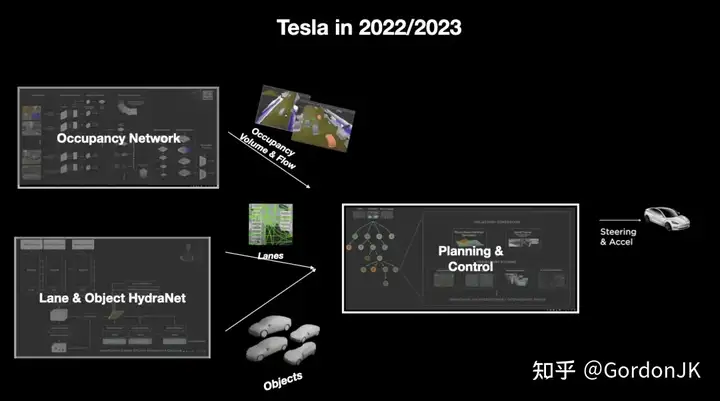
特斯拉全自动驾驶(FSD)系统的结构。
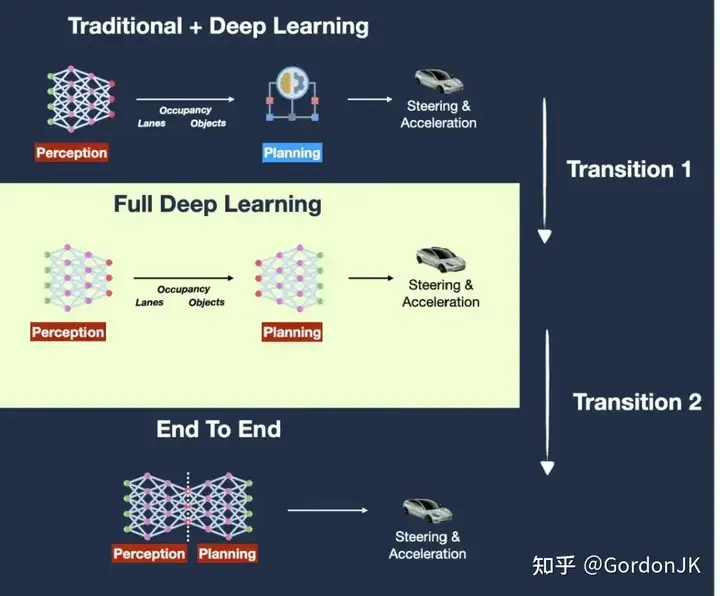
特斯拉全自动驾驶(FSD)车型的演进过程。
“端到端学习是指通过将基于梯度的学习应用于整个系统,来训练可能很复杂的学习系统。端到端学习系统经过特殊设计,所有模块都是可微分的。” 无论是 FSD 还是 RFM,都是基于基于梯度的端到端学习,使用可微分模型建立从视觉到运动的映射。它也是一种世界建模的形式,通过生成式方法预测下一帧。具有可更新状态的神经网络模块用于通过输入当前的观察结果(图像、状态等)和预期动作来记忆和建模环境。它基于模型对世界的记忆和理解,预测下一个可能的观察结果(图像、状态)和动作。特斯拉自动驾驶工程师 Dhaval Shroff 曾对马斯克说,“这就像 Chat-GPT,但适用于汽车!!!” “我们不是根据规则来确定汽车的正确路径,而是利用神经网络从数百万个人类做过的训练示例中学习,来确定汽车的正确路径。”
总之,世界模型旨在构建一个端到端的模型,建立从视觉到动作,甚至从任何事物到任何事物的映射,通过生成式方法预测下一帧来做出决策。这些世界模型与 VLA(超大型人工智能)模型的主要区别在于,VLA 模型最初在大规模互联网数据集上进行训练,以实现高级突发能力,然后与现实世界的机器人数据共同微调。另一方面,世界模型在物理世界数据上从头开始训练,并随着数据集的增长逐渐发展出某种形式的高级能力。然而,它们仍然代表低级物理世界模型,类似于人类神经反射系统的机制。它们更适合输入和输出都相对结构化的场景,例如自动驾驶(输入:视觉,输出:油门、刹车、转向)和物体分类(输入:视觉、指令、数值传感器,输出:抓取目标物体,将其放置在目标位置)。它们不太适合推广到非结构化的复杂任务。
4. 机器人学习类型
机器人学习旨在使机器人通过与环境互动和学习来获得新技能并适应环境。它将机器学习与机器人技术相结合,目标是让机器人像人类一样学习和成长。机器人学习与传统控制理论之间的关键区别在于,传统控制算法需要对整个系统进行精确的物理建模,这在无法进行精确建模的复杂场景中变得具有挑战性。相比之下,机器人学习通过与环境的互动进行学习,并使用奖励机制优化行为以获得最佳决策策略(政策),从而消除了传统物理建模方法的局限性。
机器人学习经历了以下几个研究方向的发展:
-
第一阶段,传统控制算法与强化学习相结合用于机器人控制。
-
第二阶段,深度强化学习(DRL)被引入,DeepMind 的 AlphaGo 取得了显著成功。DRL 可以处理高维数据并学习复杂的行为模式,特别适合决策和控制问题,因此 DRL 成为机器人技术的自然选择。
-
在第三阶段,DRL 的局限性变得明显,因为它需要大量的试错数据。
为了解决这个问题,引入了新的方法。
-
第一种方法是模仿学习,旨在通过收集高质量的演示来最大限度地减少所需的数据量。
-
第二种方法是离线强化学习和在线强化学习的融合,这提高了数据利用效率,降低了环境交互的成本并确保了安全性。它首先使用离线强化学习从大型静态、预先收集的数据集中学习策略,然后将它们部署到真实环境中进行实时交互并根据反馈调整策略。
-
第三种方法是 Sim2Real,即把学习到的策略从模拟环境转移到现实环境。转移的有效性取决于模拟环境的真实性,这个过程可能涉及使用 Real-to-Sim-to-Real 反馈进行迭代调整。
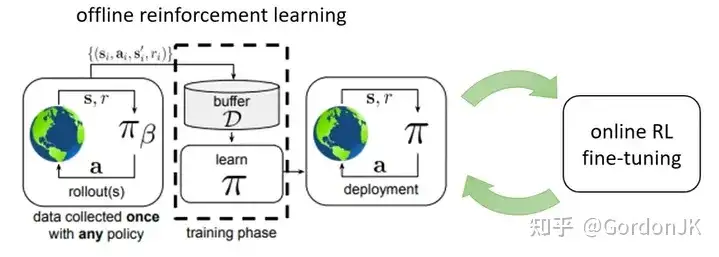
离线强化学习+在线强化学习
4.1 模仿学习
今年 1 月,谷歌 DeepMind 与斯坦福大学联合发布 Mobile ALOHA,展示了一款多功能家用机器人,引起了广泛关注,也让模仿学习成为焦点。他们开发了一款双臂轮式底盘的遥控操作系统,售价不到 20 万元人民币。该系统使用 ACT(Action Chunking with Transformers)模仿学习算法进行训练。Action Chunking 涉及将独立动作组合在一起并将它们作为一个单元执行。训练过程采用生成模型,根据输入的关节角度和图像观察,生成预测的动作序列。
在去年推出的上一代 ALOHA(Static ALOHA)中,研究人员收集了 825 个无轴距移动的教学数据样本,使用 8000 万个参数的模型,在 11GB 2080Ti GPU 上耗时 5 小时训练出单任务模型,同机同模型推理时间为 0.01 秒。而在今年的最新一代 ALOHA(Mobile ALOHA)中,他们只需要用新平台收集的 50 个全新教学数据样本,与上一代收集的教学数据相结合,机器人在移动操控任务中表现出色。
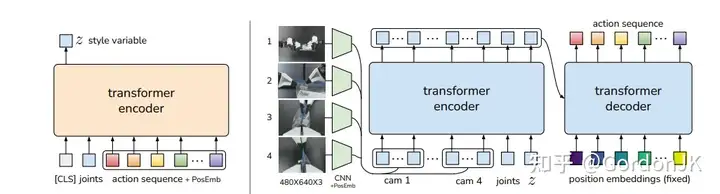
使用 Transformer 进行动作分块的架构(ACT)
4.2 强化学习
在机器人学习领域,加州大学伯克利分校的 Sergey Levine 和 Pieter Abbeel 做出了重大贡献,开创了机器人机器学习的先河。今年 3 月,一则重磅消息传出:Google Scholar 上被引用次数超过 12.7 万的知名学者 Sergey Levine 宣布成立 Physical Intelligence,简称 Pi 或 π。该公司旨在打造可增强各类机器人和机器的先进智能软件,最终目标是开发出一种通用的 AI 模型,可以控制任何机器人完成任何任务。公司联合创始人、斯坦福大学计算机科学与电子工程系教授 Chelsea Finn 表示,这是一项极具挑战性的任务,需要整合跨平台策略、从虚拟和低级运动进行迁移学习,并通过模仿学习掌握灵活的技能。另一位联合创始人兼首席执行官卡罗尔·豪斯曼(Karol Hausman)对该项目能够收集前所未有的大量机器人数据、改进算法、训练大型模型以及克服将人工智能融入物理世界的技术障碍的能力感到兴奋。尽管成立不到一个月,Pi 已经从多家风险投资公司获得了 7000 万美元的巨额资金,包括 OpenAI、Khosla Ventures、红杉资本和 Lux Capital。这笔投资不仅反映了该公司在机器人领域的巨大潜力,也表明了对创始团队实力的信心。
今年4月,卡内基梅隆大学发布了一款名为H2O的新型人形机器人,并基于强化学习开发了可扩展的框架,使机器人能够轻松学习新技能。通过引入实时遥操作系统,H2O可以学习和复制人类操作员执行的各种任务,在收集无限量的人体运动数据的同时,充当人类与人形机器人之间的无缝接口。在算法开发方面,H2O首先将人体运动重定向到人形机器人的能力,确保在物理限制内具有可行性。然后,它在模拟环境中训练基于强化学习的运动模仿算法。最后,将学习到的技能无缝转移到现实世界。H2O巧妙地结合了模仿学习和强化学习。模仿学习需要大量高质量的专家数据,适用于任务目标明确、专家策略容易获得的情况。另一方面,强化学习可以从经验中学习,适用于目标不明确、需要探索环境的情况。虽然模仿学习通常比强化学习更容易实现,但强化学习可以解决更复杂的问题。模仿学习的目标是模仿专家的行为,从而产生与数据集中的演示非常相似的策略,但泛化和通用性较弱。另一方面,强化学习的目标是最大化累积奖励,允许探索未知空间并获得超出专家演示的经验,甚至开发超越人类能力的策略,就像 AlphaGo 的情况一样。然而,强化学习极具挑战性,经常面临诸如训练时间长、奖励稀疏和策略收敛问题等问题。因此,许多研究人员将模仿学习和强化学习结合起来,以促进更快的部署。模仿学习为强化学习提供了初始策略,减少了训练时间,而强化学习则微调模仿学习策略以提高性能。
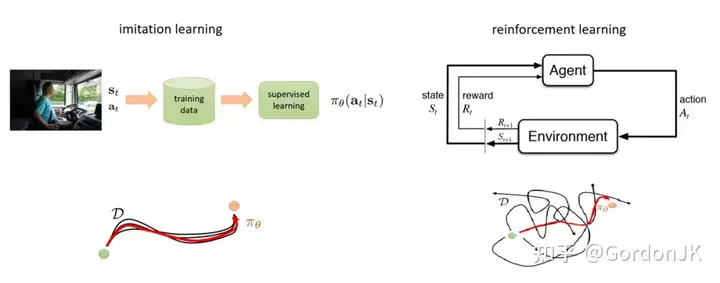
模仿学习与强化学习
4.3 Sim2Real
数据的稀缺性一直是机器人学习领域的制约因素。利用模拟环境进行训练,然后将学到的技能、知识或模型迁移到现实世界被视为一个很有前途的方向。然而,现实世界本质上比模拟环境更加复杂和动态,充满了噪音和不确定性。从模拟到现实的转移过程充满挑战,涉及的问题包括解决模拟与现实在感知和动态方面的“领域鸿沟”、结合真实和模拟数据以提高样本效率、增强模拟到现实转移的鲁棒性、训练在不同环境中能很好地泛化的模型等。这些挑战需要不断创新和研究突破。
2024年2月24日,NVIDIA宣布成立GEAR(Generalist Embodied Agent Research)新研究团队。3月18日,在GTC大会上,NVIDIA发布了通用人形机器人模型Project GR00T和基于Thor SoC的新型人形机器人计算机Jetson Tho,并宣布对Isaac机器人平台进行重大升级。GR00T代表着NVIDIA在机器人和具身智能领域的重大突破,旨在为人形机器人提供一个“大脑”,使其能够学习技能以应对各种任务,能够理解自然语言,通过语言、视频和人类演示模仿人类动作,快速学习协调性、灵活性等技能,使其能够融入现实世界并与人类互动。全新的Jetson Thor计算平台支持高效的AI计算,新开发的Isaac Perceptor工具包增强了环境感知,Isaac Manipulator优化了操作效率。在 NVIDIA 的愿景中,Omniverse 将成为机器人系统的发源地,也是 AI 的虚拟训练场。正如黄仁勋(Jensen Huang)所说,“开发通用的人形机器人模型是当今 AI 领域最令人兴奋的课题之一。”当他伸出双臂,与其他人形机器人并肩而立时,“计算机图形学、物理学和人工智能的交汇,一切都从这一刻开始。”

NVIDIA GR00T 项目
总之,机器人学习领域可以说是研究的前沿,其核心问题是让机器人学会如何自己完成各种决策和控制任务。目前的发展方向包括模仿学习与强化学习的融合、离线和在线强化学习的融合、真实数据和模拟数据的结合以及弥合 Sim2Real Gap。
机器人学习和世界模型都旨在解决低级策略问题。在这里,“世界模型”一词特指在真实数据上训练的低级物理模拟模型,是一种模仿学习。它非常适合结构化任务,但很难推广到演示数据场景之外。另一方面,机器人学习结合了强化学习和 Sim2Real,能够通过与环境的交互来优化策略,探索未知领域,甚至超越人类水平,并适应非结构化场景。在 ALOHA 的机器人故障视频中,我们看到机器人打翻玻璃杯、拿不住笔、食物洒在盘子外面的情况。虽然机器人可以模仿人类的很多行为,但如果没有基于环境反馈的强化学习,它仍然很难有效地执行任务。在 ALOHA 团队的最新研究成果中,他们引入了人类的口头指导,以动态提高机器人的运动技能并实时调整策略,让模型能够根据反馈不断自我改进。当然,最具挑战性的场景是接触密集型任务,操控需要实时反馈(包括操控对象的状态、形变、材质、力反馈)来做出调整,只有强化学习才能有效处理这样的任务。
在Virtual学习模型(VLM)和大型语言模型(LLM)飞速发展的今天,大型模型为强化学习提供了助力。一方面,大型模型对场景语义有广义的理解,可以为强化学习提供极好的奖励函数。另一方面,强化学习也是大型模型对齐过程的一部分。未来具象化的大型模型在经过预训练和微调后,仍需要通过强化学习与物理世界对齐,才能在现实世界中表现得更好。
5. 工程学科
今年3月,Figure与OpenAI的合作有了新的突破。Figure采用了分层结构,
-
上层是负责语音交互和基于图像的常识推理的OpenAI模型,它的输出是行为选择,这主要是因为Figure将场景中的任务分解成几个独立的闭环动作模型,它根据上层的指令选择执行哪一个。
-
中层是神经网络策略,它处理灵巧操控任务,以200Hz的频率输出动作。使用的模型结构是神经网络视觉运动转换器,直接将像素映射到动作上。和ALOHA类似,这里采用了模仿学习,每个任务都收集动作示范,让模型通过学习学到相应的动作模型。
-
下层是全身控制器(WBC),它提供安全稳定的动力学模型,以1kHz的频率输出关节力矩,可以协调机器人所有关节的运动完成特定的行为,中层的神经网络策略为其提供了目标函数和约束。
为什么说 Figure 是一种工程化的方法呢?因为这种分层架构是最快的方式去创建一个 demo,在场景中执行具体的任务。每一层负责不同的响应速度和输出频率,上层负责缓慢的思考和规划,中层负责快速的反射性思考,下层负责计算关节力矩。这样整体的响应速度更接近可以商业化的水平。目前这三层中最成熟的是 WBC 机器人运动控制算法,高层使用大模型的规划已经比较成熟,而低层策略还是一个相对不太成熟的领域,也是目前的热门研究方向。目前各层之间是松耦合的,主要通过调用的方式,低层模型很难发挥上层模型的泛化能力,上层模型也很难得到下层模型的即时反馈来调整策略,不同场景和任务之间的泛化能力比较弱,适合在特定环境中任务比较容易结构化的场景。

Figure01的架构
总之,分层架构是目前工程实现最快最可行的方案,将机器人的感知、规划、执行、控制等部分分离,然后级联起来,降低实现复杂度,但实现泛化难度较大,人类的行为和决策是大脑、小脑、周围神经系统共同作用的结果,这些部分的紧密耦合,才导致了智能的产生。未来,研究人员将继续探索利用统一架构实现具身智能和 AGI(Artificial General Intelligence)。
6. LLM/VLM(大型语言模型/虚拟学习模型)范式
在讨论 LLM/VLM(大型语言模型/虚拟学习模型)范式时,必须提到 Google DeepMind 的贡献。机器人技术的高效多任务学习需要高容量模型,因此 Google 研究人员推出了 Robotics Transformer(RT)系列模型。初始模型 RT-1 基于模仿学习中的行为克隆范式。它以一小段图像和一条指令作为输入,并在每个时间步骤输出一个动作。在 17 个月的时间里,使用 13 个机器人收集了 13 万个情节和 700 多个任务的数据,使机器人能够表现出一定程度的泛化能力,并在结构相似的任务之间发现模式,并将其应用于新任务。
继 RT-1 之后,Google 研究员们从未停止对大模型和scaling规模化能力的挖掘。在 SayCan 项目中,我们首次看到了基于 LLM 的高级规划与低级动作的结合,并进一步将 PALM-E 多模态大模型与 RT-1 结合。直到去年 RT-2 发布,才有了第一个真正端到端的视觉-语言-动作 (VLA) 模型。
RT-2 的训练分为两步:首先在大规模互联网数据集上对 VLM 进行预训练,然后在机器人任务上进行协同微调。
这种方式有助于更好地泛化到新的物体、环境、形状和技能。RT-2 与 RT-1 最显著的区别在于它得益于互联网规模的预训练,为下游任务提供了强大的语义推理、问题解决和视觉解释能力。VLM 模型基于来自互联网的数十亿个 token 进行训练,仅通过机器人数据在短时间内收集如此大规模的 token 是不可能的。之前的研究(如 SayCan 和 Palm-E)通常解决机器人中的高级规划问题,本质上充当状态机,解释命令并将其解析为单个原语,然后由单独的低级控制器执行。这些低级控制器在训练期间无法从互联网上可用的丰富语义知识中受益。RT-2 将语言、动作和图像标记化到统一的空间中,其中动作可以被视为一种特殊的语言形式。它们被转换成多模态序列并纳入训练集,从而利用 VLM 的功能。
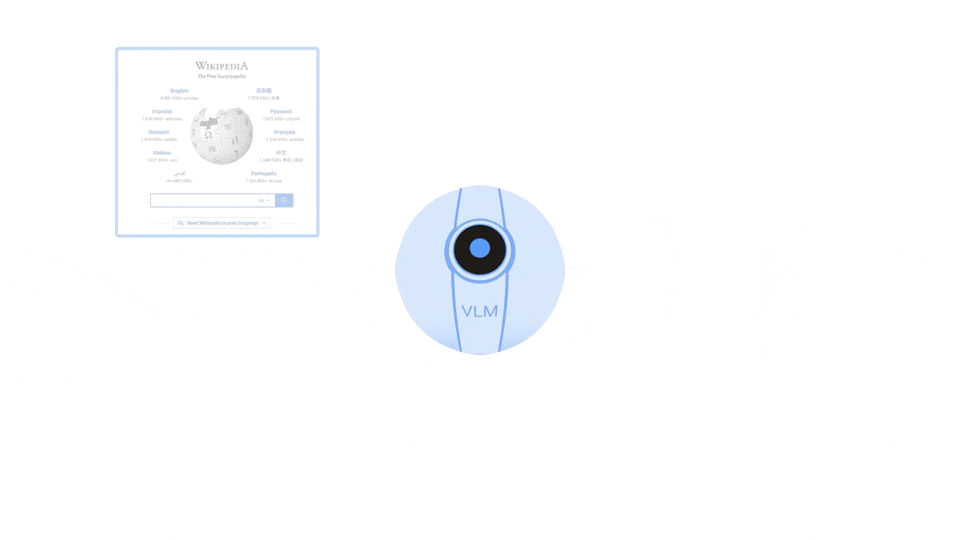
RT-2:将网络知识转移到机器人控制
去年 10 月,谷歌与研究界合作,开源了一个名为 Open X-Embodiment 的海量数据集。该数据集由 21 个组织收集,包含来自 22 个不同机器人的数据,展示了 527 种技能(160,266 个任务)和超过 100 万条机器人轨迹。它旨在探索在机器人操控的背景下训练通用型 X-robot,可以被认为是机器人领域的 ImageNet 时刻。在 RT-1 和 RT-2 架构的基础上,谷歌研究人员使用这个最新数据集训练了 RT-X,展示了积极的迁移以及利用其他平台的经验来增强多个机器人功能的能力。

Open X-Embodiment数据集
今年三月,谷歌RT机器人再次进化,推出了最新版本的RT-H,加入了动作层级,将复杂的任务分解为更简单的语言动作,再转化为机器人动作,从而提升机器人在任务完成上的准确率和学习效率。谷歌研究员的核心洞察是,语言不仅可以描述高级任务,还可以提供详细的完成指令。通过语言动作作为连接高级任务描述和低级动作的中间层,不同任务之间可以在语言动作层面实现更好的数据共享。比如,“拿起一罐可乐”这个任务,可以分解为一系列更细致的语言动作:“向前伸手臂”,然后是“抓起罐子”,最后是“举起手臂”。每个语言动作都不是简单的固定基元,而是具备灵活性和情境适应性,可以根据当前任务和场景的具体情况,通过指令和视觉观察进行学习。RT-H 采用 VLM 模型同时处理语言动作和动作查询,在处理多样化多任务数据集时取得了显著的进步,并且与 RT-2 相比表现出了更优异的泛化能力。
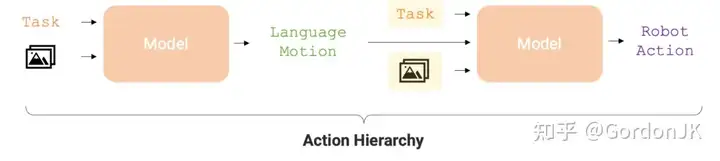
RT-H:使用语言的动作层次
除了这些进展,谷歌还宣布了三项新技术:AutoRT、SARA-RT 和 RT-Trajectory,以促进 Robotic Transformer 在现实世界中的实际应用。AutoRT 创建了一个在新环境中部署机器人以收集训练数据的系统,利用大型模型的潜力,通过收集更全面、更多样化的数据来扩展机器人的学习能力。SARA-RT 引入了一种名为“up-training”的新型模型微调方法,将二次复杂度转化为线性复杂度,显著提高了模型的效率。这项技术使 Transformer 更快、更紧凑,具有大规模采用 Transformer 技术的潜力。RT-Trajectory 自动添加机器人轨迹,为模型提供低级、实用的视觉提示,以学习机器人控制策略并增强泛化能力。这些技术使机器人能够更快地做出决策,更好地理解其环境,并引导自己更有效地完成任务。
总之,Google DeepMind 在机器人基础模型上研究了八年,不断探索如何更有效地扩展模型和数据,最终的成果是利用基础模型和大量多样化的数据集。从早期使用三个模型分别进行规划、可供性和低级策略的 SayCan,到统一可供性和低级策略的 Q-Transformer,统一规划和可供性的 PaLM-E,以及最终用一个模型完成三个任务的 RT-2,实现了联合扩展和正向迁移。这代表着机器人基础模型领域的重大进展。
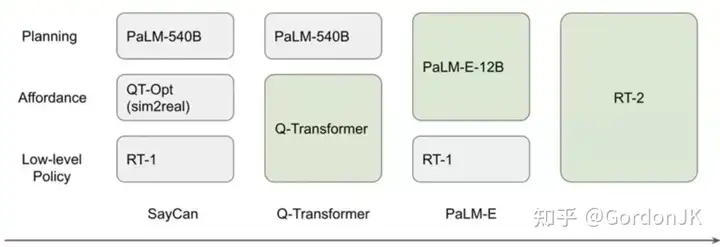
2023–2024 Google Deepmind 研究进展
RT-2 虽然功能强大,但还是存在一些局限性。例如,实时推理速度较慢,频率只有 1-3Hz。这本身就是 VLM 模型的问题。目前正在探索各种方法来解决这一痛点,例如通过模型量化和蒸馏将模型部署在边缘,或者使用 MoE(专家混合)架构,在推理期间只使用一部分参数,从而比具有相同参数的密集模型更快地进行推理。
此外,VLA(Vision-Language-Action)模型的涌现能力目前还局限于VLM相关的高层规划和可供性,无法在低层物理交互层面生成新技能,且受限于数据集中的技能类别,且物理动作往往存在笨拙性,如抓握不稳定、放置不精准等。未来需要将强化学习融入到大型模型的训练框架中,实现更强的泛化能力,让VLA模型在现实环境中自主学习和优化低层物理交互策略,从而更加灵活、准确地做出各种物理动作。
6. 总结
过去几个月,具身智能领域的进展可谓令人瞩目,进展速度令人振奋。尽管人工智能从数字世界向物理世界的过渡仍面临诸多挑战,但随着才华横溢的研究人员不断投入其中,我们已经见证了无数令人惊叹的突破。几年后回顾这一切,这无疑将成为人类科技史上的重要篇章。我们离创造出匹敌甚至超越人类智能的硅基生命体越来越近了。这不仅是技术的胜利,也是人类自身对智能本质的一次深刻对话。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)