ovCompose:腾讯视频跨平台框架终开源!可支持纯血鸿蒙!
以框架问题:不支持鸿蒙功能问题:如iOS混排性能问题:如卡顿、内存管理问题等可理解为「ovCompose」是的一个”增强版"。接下来,我们看下ovCompose是如何解决上述三个问题的。逻辑层:由于在鸿蒙平台采取 Kotlin-Native 方案,解决了 Kotlin-JS 使用 TaskPool 时,Kotlin 语法无法约束跨线程访问的问题,保持了高度的三端一致性。渲染层:Android(Sk
背景
- Compose Multiplatform凭借声明式UI、原生性能及Kotlin优势逐步成为大家进行跨平台的理想解决方案
- 但官方版本存在iOS平台混排能力受限、GC性能表现一般等一系列问题。
- 同时随着鸿蒙平台的推出,跨-鸿蒙平台的需求逐渐蔓延到各个跨平台框架方案里。
于是为了解决上述问题,腾讯视频团队正式开源跨平台开发框架:ovCompose。
Github:https://github.com/Tencent-TDS
简介
以Compose Multiplatform作为全跨端方案的基础,解决了Compose Multiplatform的三大问题:
- 框架问题:不支持鸿蒙
- 功能问题:如iOS混排
- 性能问题:如卡顿、内存管理问题等
可理解为「ovCompose」是 Compose Multiplatform 的一个”增强版"。接下来,我们看下ovCompose是如何解决上述三个问题的。
问题1:如何支持鸿蒙?
1. 开发方案
在方案的选择中,有JS跟Kotlin的方案:
- JS方案:先将 Kotlin 代码编译成 JS,然后通过鸿蒙的 ArkTS 引擎来运行;
- Native方案:直接将 Kotlin 代码编译成鸿蒙平台可以识别的本地机器码
腾讯视频团队选择Native优先策略,即放弃JS方案,选择Kotlin-Native(KN),保证了更好的性能。
从实际测试发现,能实现3倍于JS的纯对象创建速度(3.32ms vs 7.12ms)
官方测试数据:https://docs.qq.com/sheet/DQXB4YmxQaENSdkpD
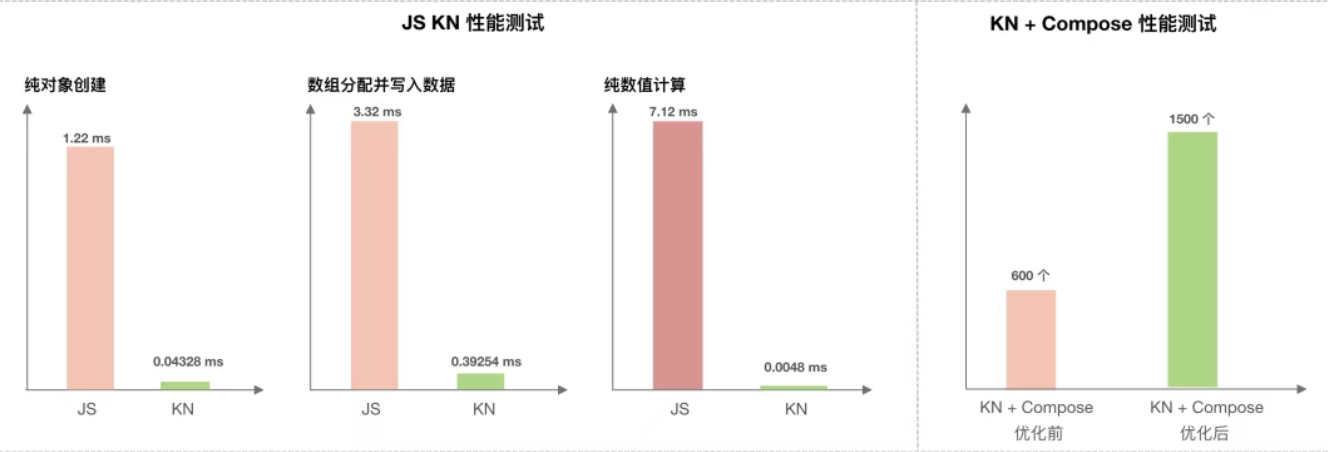
同时因为都是Kotlin,从而更好地保持三端(Android / iOS)的一致性。
2. 渲染方案
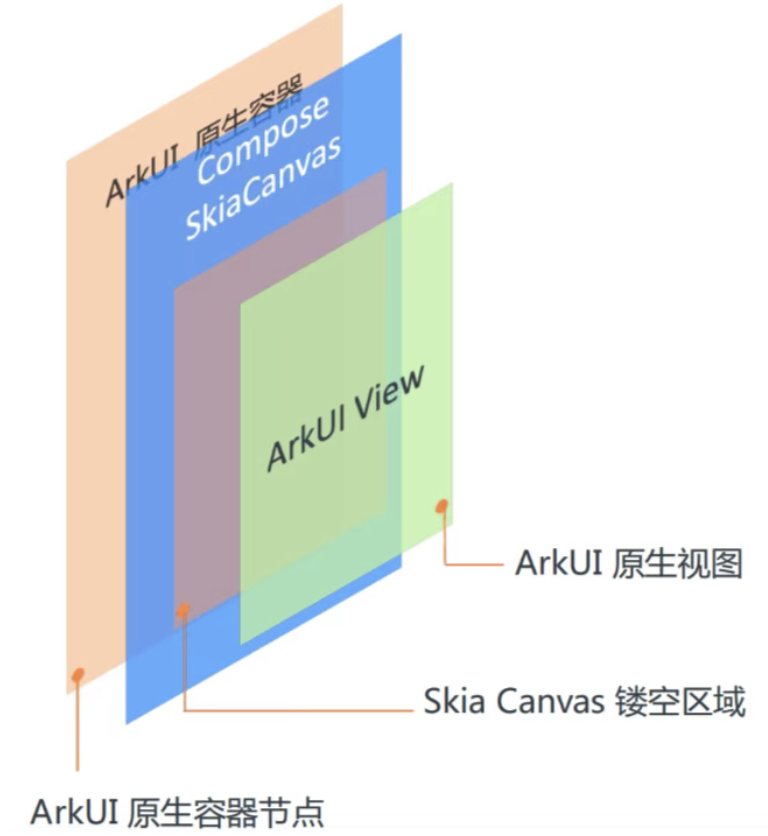
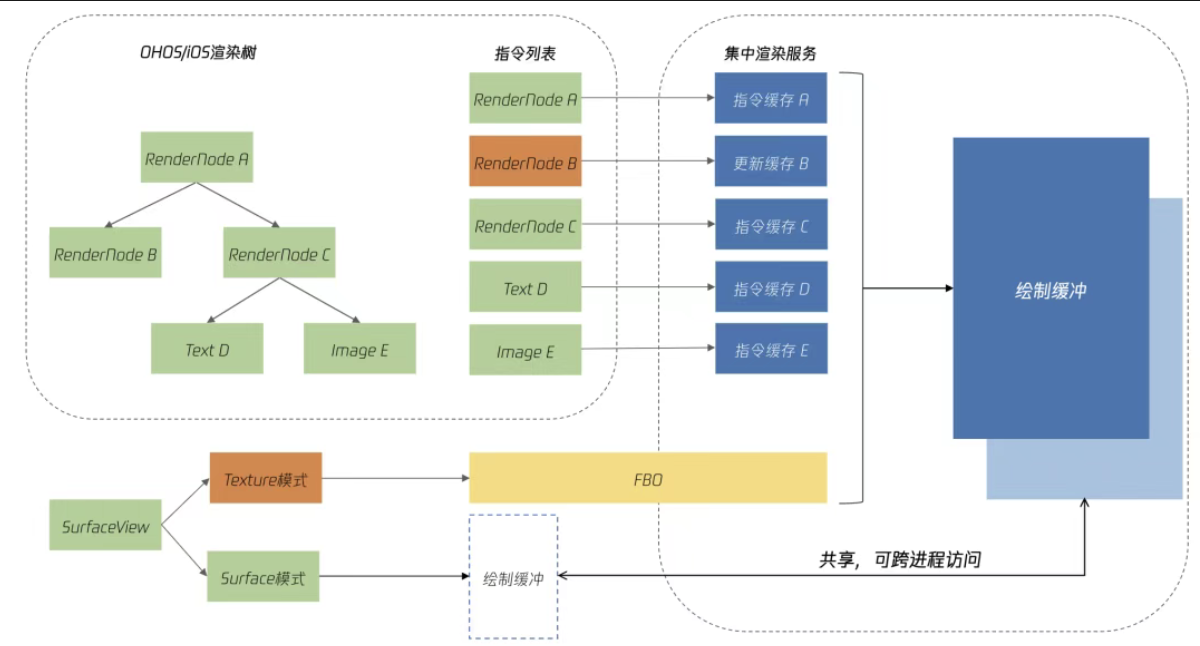
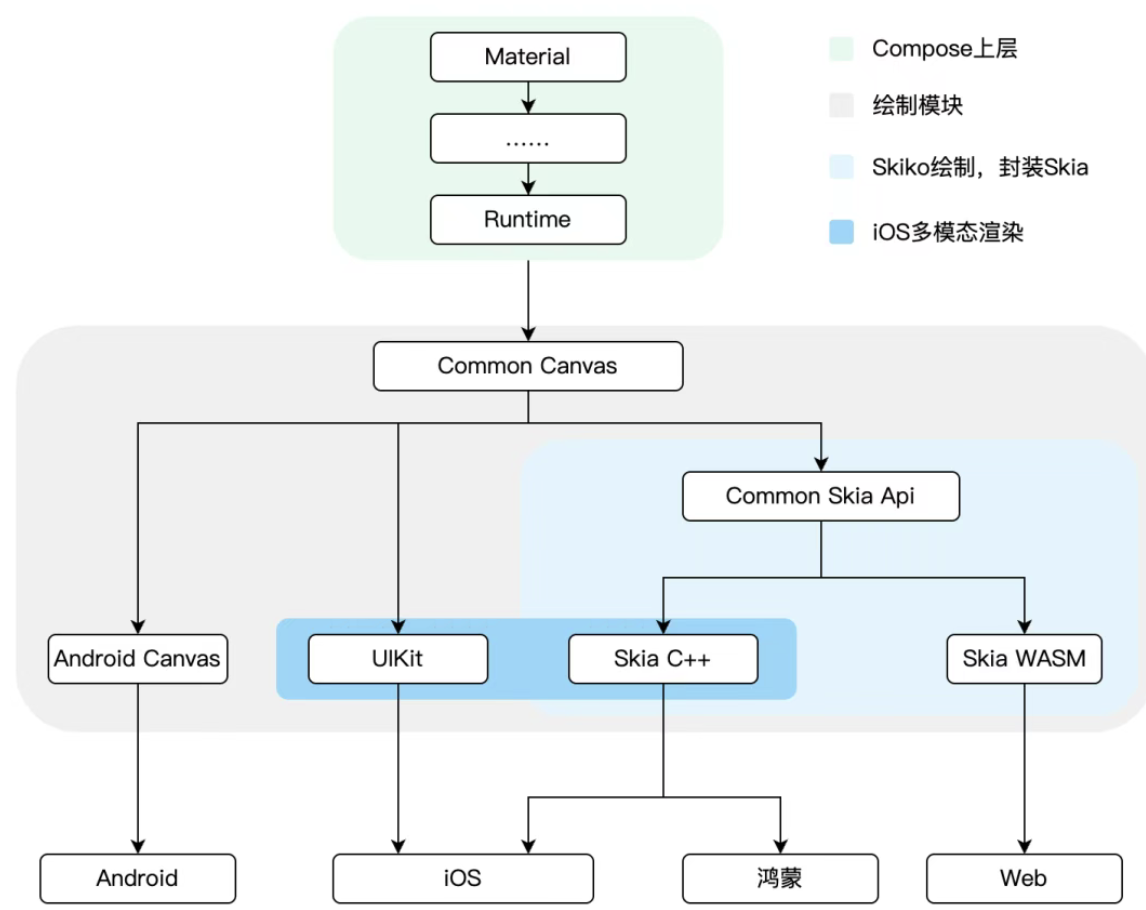
- 鸿蒙平台采用了 Skia 的渲染方案,能够100%支持 Compose 语法和渲染能力,同时保证三端统一;
- Skia 渲染使用 XComponent 组件作为画布,通过三明治镂空结构,利用XComponent的Texture模式,将Skia绘制内容通过FBO融入ArkUI渲染流程,彻底解决Compose与原生组件滚动断层问题
3. 编译方案
在编译方面,存在的问题是:
- Kotlin 编译所依赖的底层工具链(LLVM)版本,和鸿蒙系统所支持的版本不兼容;
- 如果单独为鸿蒙平台维护一个独立的、魔改过的 Kotlin 编译器版本,但这会导致项目分裂,开发和维护成本极高。
ovCompose采用了一种非常巧妙的"两个阶段" 策略:
- 第一阶段:Kotlin IR → LLVM IR(采用苹果LLVM 11)
即先用苹果兼容的 LLVM 工具链将 Kotlin 代码转换成一种中间语言(LLVM IR)。 - 第二阶段:LLVM IR → 鸿蒙可执行文件(采用鸿蒙LLVM 12)
即再用鸿蒙的 LLVM 工具链将这个中间语言编译成最终的可执行文件。
通过这种方式,既避免Kotlin架构改动,又实现单代码库同时输出鸿蒙产物。
总结
通过上述三个支持鸿蒙的核心方案,ovCompose不仅实现了鸿蒙的跨端实现,同时还能保持Android、iOS三端的跨平台高一致性:
- 逻辑层:由于在鸿蒙平台采取 Kotlin-Native 方案,解决了 Kotlin-JS 使用 TaskPool 时,Kotlin 语法无法约束跨线程访问的问题,保持了高度的三端一致性。
- 渲染层:Android(Skia)、iOS(Skia+CALayer)、鸿蒙(Skia)统一渲染管线
- 开发层:三平台均可100%使用Compose标准API、控件与绘制能力,支持全套Material组件
问题2:如何解决性能问题
2.1 内联优化
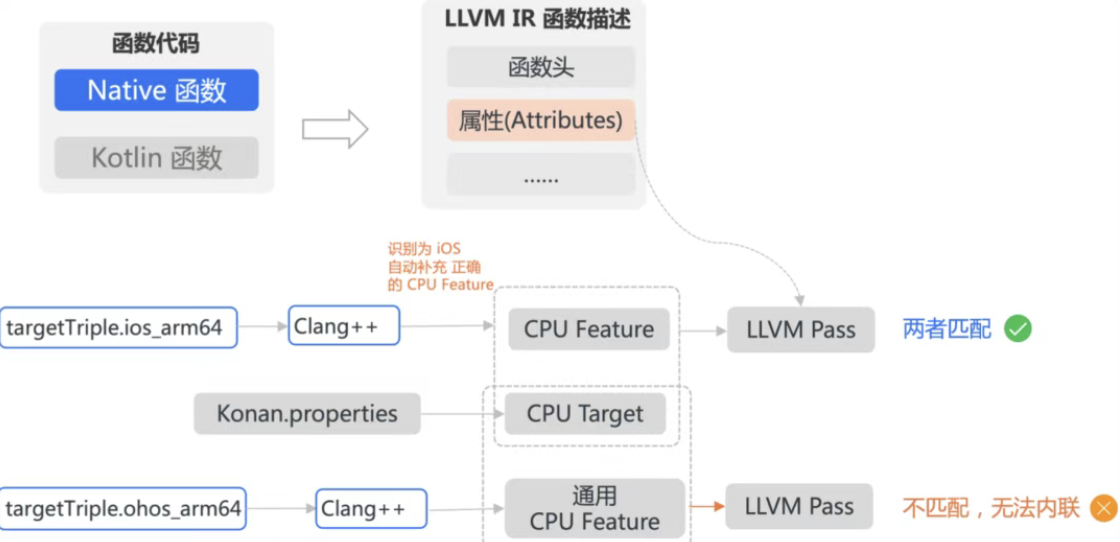
通过分析LLVM的内联发现:
- 在处理 EnterFame等关键函数时,会对比cpu feature的兼容性;
- Kotlin和框架内部C++代码在生成LLVM的函数时,他们各自携带的cpu feature不一致,导致无法进行内联。
配置正确的属性后,此问题得到修复。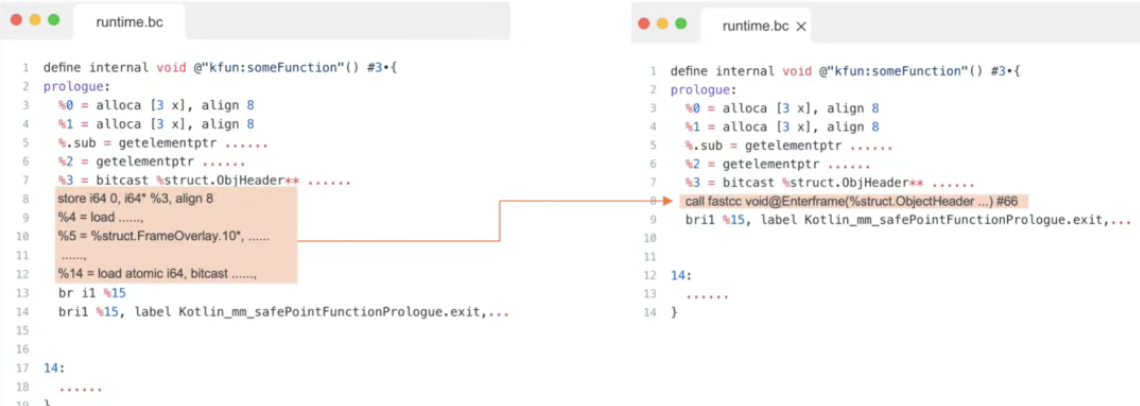
2.2 优化线程数据访问
鸿蒙平台默认采用了软件模拟的thread_local。所以在编译时通过参数强制使用硬件thread_local,整体性能提升了30%。
2.3 内存管理优化
主要包括:GC抑制、Sweep优化和堆Dump。
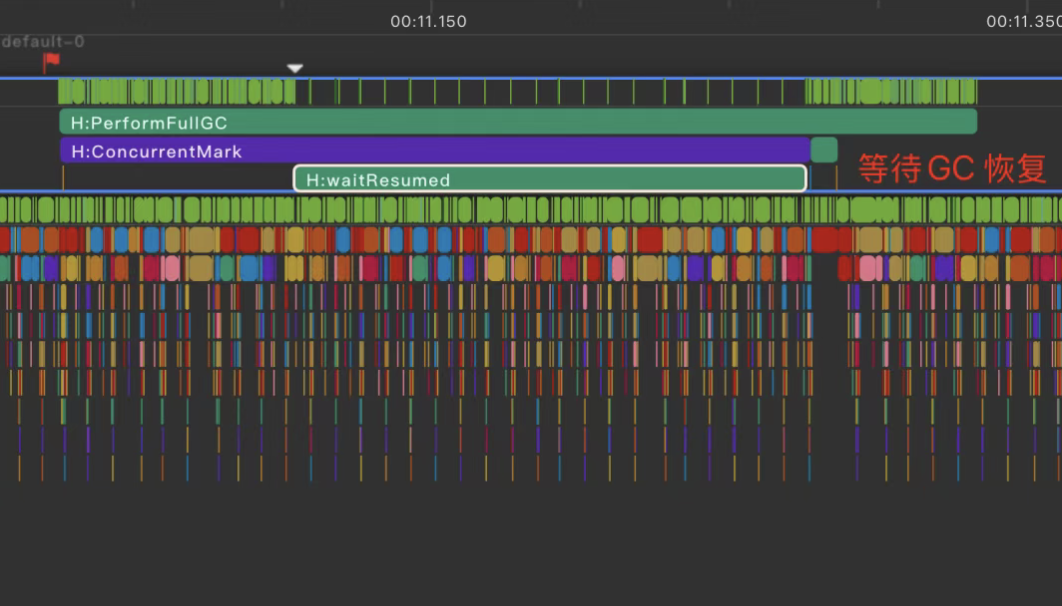
1. GC抑制
利用 GC 挂起的能力,在 Vsync 时进行 GC挂起,在 idle时进行 GC恢复。最终效果是滑动帧率波动降低40%,具体如下:
2. Sweep优化
- 将munmap移出STW阶段;
- 在STW阶段仅做Page收集;
- 在Resume后再进行集中 munmap
最终效果:将STW时间压缩至1ms内。
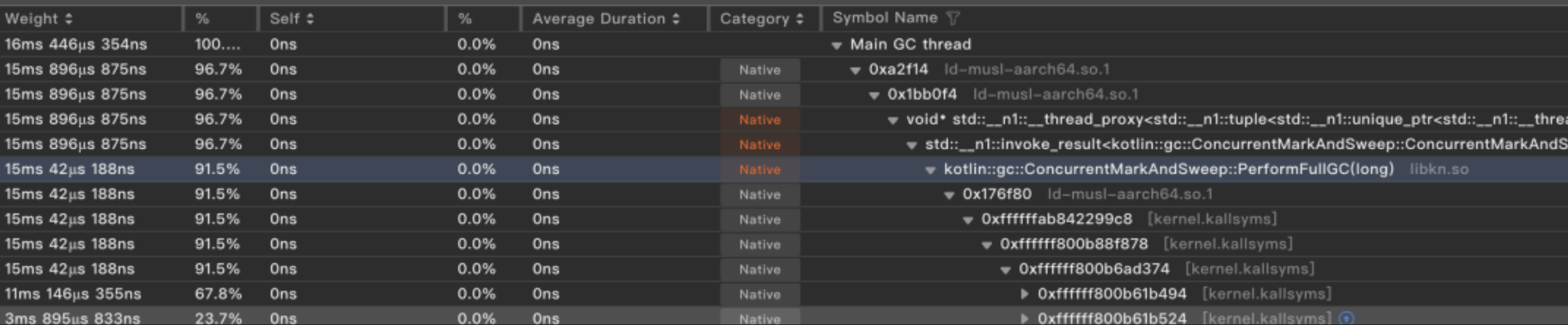
3. 堆Dump优化
Kotlin Native(KN)支持生成堆内存转储文件,但Dump过程需暂停所有KN线程,导致秒级界面冻结。针对不同平台特性采用了不同优化方案:
- 鸿蒙:基于 Linux 内核的 fork() 系统调用特性,采用「父进程无感知-子进程异步转储」方案实现零延迟内存快照。
- iOS:针对iOS系统无法支持fork的限制,重新设计了堆内存分析流程,在保持性能的同时显著降低主线程阻塞时间
优化效果:450MB堆转储耗时从2.8s→410ms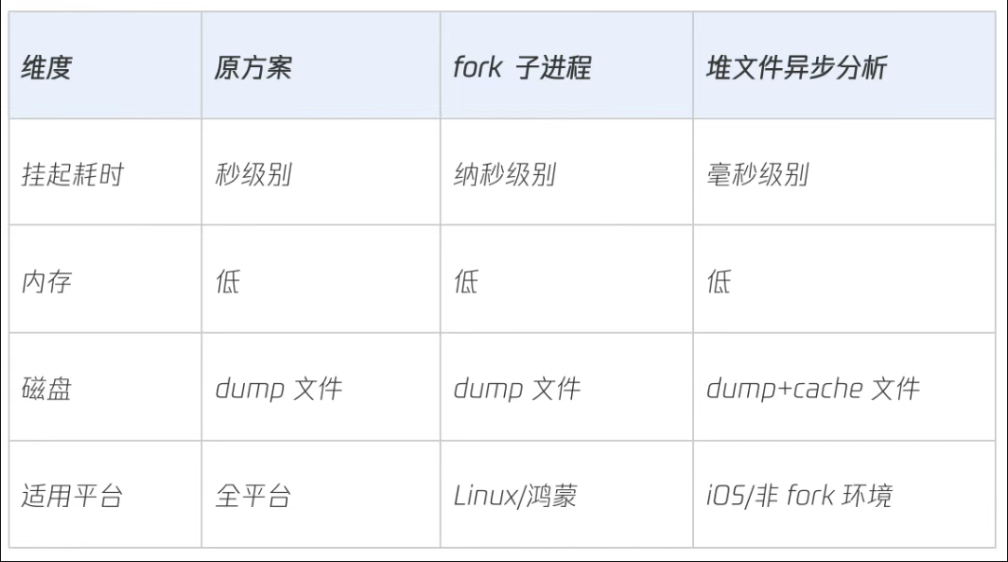
问题3:如何解决iOS混排问题
为了让 Compose 界面能和原生 UIKit 界面灵活、高性能地共存,ovCompose独创的"iOS多模态渲染":把 Compose 的"绘制指令"巧妙地"翻译"成苹果 UIKit 自己的绘制指令,并交由系统去渲染。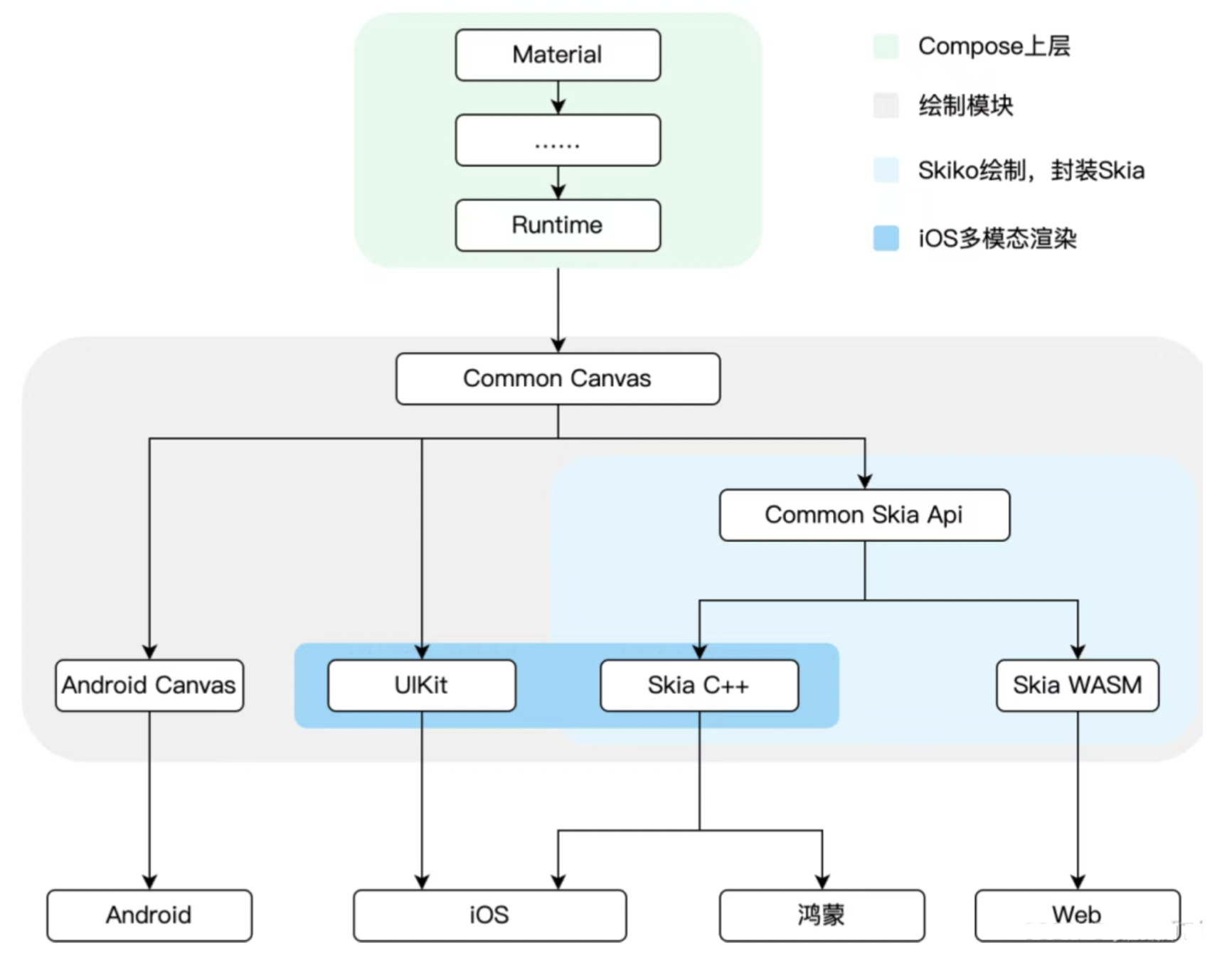
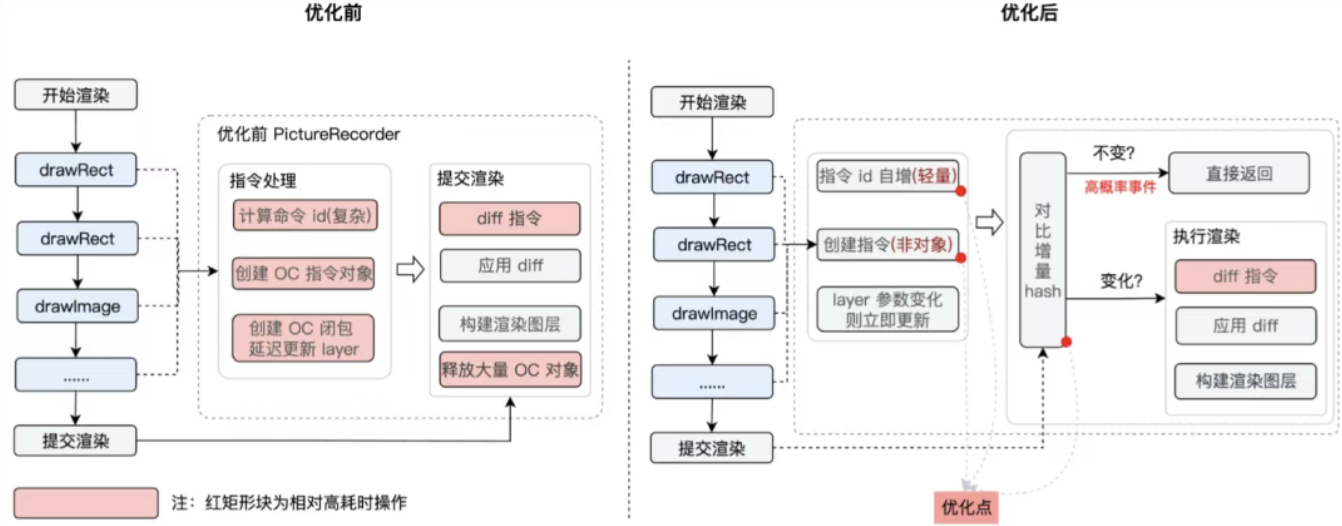
同时通过基于iOS的PictureRecorder局部更新架构,从而提高渲染效率。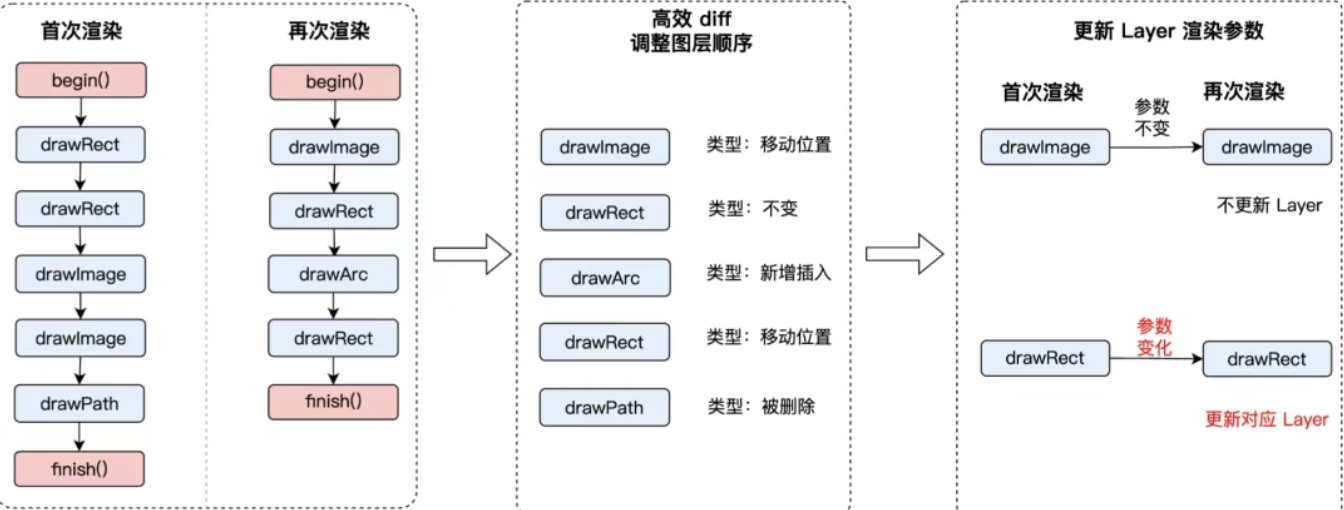
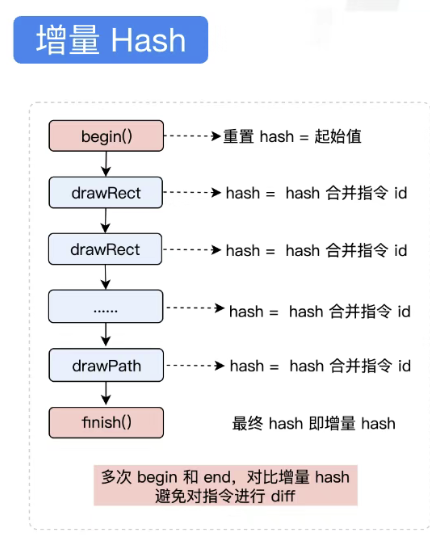
在PictureRecorder中对绘制命令进行差量,只更新变化的部分,从而提升绘制效率。优化的核心思路是:通过增量hash来减少hash的计算量。具体是:每一个 draw 函数执行时,都会对将当前的 hash 和 指令id 进行一次合并。并计算出最终的 hash。这个 hash 记录了一次完整的使用。增量 hash 的目的是减少 diff操作,这种方式可以有效地减少两次指令相同的比较。
优化效果:以腾讯视频的视频播放页面为例,首次渲染耗时降低13%,再次渲染耗时降低56%。
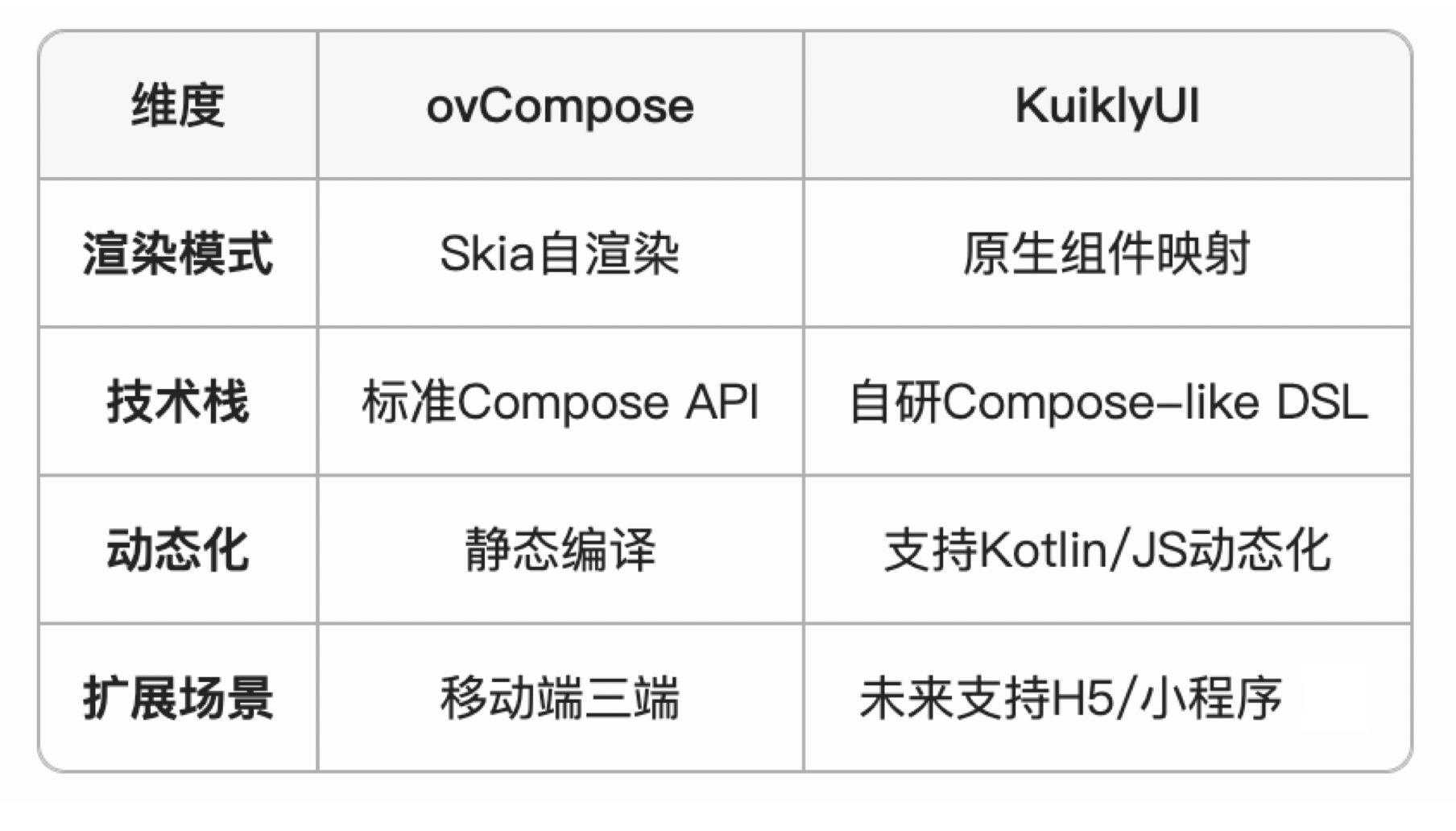
与KuiklyUI的差异化定位
腾讯Oteam之前推出的KuiklyUI同样基于KuiklyBase,二者的区别在于:
- ovCompose:需要极致性能、专注移动端的场景;
- KuiklyUI:需动态更新、多端(含Web)覆盖、快速迭代的业务。
应用情况
腾讯视频鸿蒙版:行业首个全跨端鸿蒙应用,三端代码复用率超90%。
如何评价?
我认为ovCompose更多的意义在于:
- 鸿蒙跨端平台的新思路:特别是对于正在使用KMP的团队来说,这可能是目前适配鸿蒙成本最低、体验最好的方案;
- KMP 技术的可行性:在腾讯视频这样体量的应用已经完全落地,这说明KMP技术路线已经足够成熟,可以承载亿万级用户的复杂业务场景。
您怎么看待腾讯视频开源的跨平台框架ovCompose呢?评论区留下您的看法吧!
参考文章:
- https://blog.csdn.net/linshantang/article/details/148495663
- https://mp.weixin.qq.com/s/GTkzHTvWIdDmxtlRVpNgfw

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)