flowable数据表详解
网络爬虫的是一个非常常见的需求。普通数据,各种情况都使用的数据。表分类表名描述运行实例表(10)运行实例表ACT_RU_DEADLETTER_JOB正在运行的任务表ACT_RU_EVENT_SUBSCR运行时事件运行时流程执行实例ACT_RU_HISTORY_JOB历史作业表ACT_RU_IDENTITYLINK运行时用户关系信息ACT_RU_JOB运行时作业表。
爬虫组件分析
Survive by day and develop by night.
talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for change,challenge Survive.
happy for hardess to solve denpendies.
目录

概述
网络爬虫的是一个非常常见的需求。
需求:
1.URL管理
2. 网页下载器
3. 爬虫调度器
4. 网页解析器
5. 数据处理器
设计思路
实现思路分析
1.flowable
我们在接入flowable框架的时候,运行项目如果数据库没有flowable自带的表会自动创建出来,总共60张表,每张表都有其作用,下面会具体介绍表的用途。
2.数据表的命名规则
ACT_RE_*
’RE’表示repository(存储)。RepositoryService接口操作的表。带此前缀的表包含的是静态信息,如,流程定义,流程的资源(图片,规则等)。
3.ACT_RU_*
’RU’表示runtime。这是运行时的表存储着流程变量,用户任务,变量,职责(job)等运行时的数据。flowable只存储实例执行期间的运行时数据,当流程实例结束时,将删除这些记录。这就保证了这些运行时的表小且快。
4.ACT_ID_*
’ID’表示identity(组织机构)。这些表包含标识的信息,如用户,用户组,等等。
5.ACT_HI_*
’HI’表示history。就是这些表包含着历史的相关数据,如结束的流程实例,变量,任务,等等。
数据表的介绍
普通数据,各种情况都使用的数据。
表分类 表名 描述
运行实例表(10)
运行实例表
ACT_RU_DEADLETTER_JOB 正在运行的任务表
ACT_RU_EVENT_SUBSCR 运行时事件
ACT_RU_EXECUTION *
运行时流程执行实例
ACT_RU_HISTORY_JOB 历史作业表
ACT_RU_IDENTITYLINK 运行时用户关系信息
ACT_RU_JOB 运行时作业表
ACT_RU_SUSPENDED_JOB
ACT_RU_TASK * 运行时任务表
ACT_RU_TIMER_JOB 定时作业表
ACT_RU_VARIABLE * 运行时变量表
流程历史记录(8)
ACT_HI_ACTINST * 历史的流程实例,记录流转的流程组件(节点、网关)
ACT_HI_ATTACHMENT 历史的流程附件
ACT_HI_TASKINST * 历史的任务实例
ACT_HI_VARINST * 历史的流程运行中的变量信息
ACT_HI_COMMENT 历史的流程操作信息记录
ACT_HI_DETAIL * 历史的流程变量记录表
ACT_HI_IDENTITYLINK 历史的流程身份认证记录
ACT_HI_PROCINST 历史的流程定义实例记录
资源表(2)
ACT_GE_BYTEARRAY * 存储部署的流程文件
ACT_GE_PROPERTY * 记录系统相关属性
ACT_ID_BYTEARRAY 二进制数据表
ACT_ID_GROUP 用户组信息表
ACT_ID_INFO 用户信息详情表
ACT_ID_MEMBERSHIP 人与组关系表
ACT_ID_PRIV 权限表
ACT_ID_PROPERTY 属性表
ACT_ID_TOKEN 系统登录日志表
ACT_ID_USER 用户表
ACT_ID_PRIV_MAPPING 私有人与组关系表
流程定义表(3)
ACT_RE_DEPLOYMENT * 部署单元信息 (记录部署时间)
ACT_RE_MODEL 模型信息
ACT_RE_PROCDEF * 已部署的流程定义(记录部署的资源路径)
CMMN流程引擎数据表(11)
ACT_CMMN_CASEDEF
ACT_CMMN_DATABASECHANGELOGLOCK
ACT_CMMN_DEPLOYMENT
ACT_CMMN_DEPLOYMENT_RESOURCE
ACT_CMMN_HI_CASE_INST
ACT_CMMN_HI_MIL_INST
ACT_CMMN_RU_CASE_INST
ACT_CMMN_RU_MIL_INST
ACT_CMMN_RU_PLAN_ITEM_INST
ACT_CMMN_RU_SENTRY_PART_INST
DMN流程引擎数据表(6)
ACT_DMN_DATABASECHANGELOGLOCK
ACT_DMN_DATABASECHANGELOG
ACT_DMN_DECISION_TABLE
ACT_DMN_DEPLOYMENT
ACT_DMN_DEPLOYMENT_RESOURCE
ACT_DMN_HI_DECISION_EXECUTION
表单引擎数据表(6)
ACT_FO_DATABASECHANGELOG
ACT_FO_FORM_DEFINITION
ACT_FO_FORM_DEPLOYMENT
ACT_FO_FORM_INSTANCE
ACT_DMN_DEPLOYMENT_RESOURCE
ACT_DMN_HI_DECISION_EXECUTION
表单引擎数据表(6)
ACT_FO_DATABASECHANGELOG
ACT_FO_FORM_DEFINITION
ACT_FO_FORM_DEPLOYMENT
ACT_FO_FORM_INSTANCE
ACT_FO_FORM_RESOURCE
ACT_FO_DATABASECHANGELOGLOCK
内容引擎数据表(3)
ACT_CO_DATABASECHANGELOGLOCK
ACT_CO_DATABASECHANGELOG
ACT_CO_CONTENT_ITEM
其他表(2)
ACT_EVT_LOG 事件日志记录
ACT_PROCDEF_INFO 流程定义信息
Flowable引擎:
流程引擎 (流程部署、待办查询、历史任务、身份认证、流程展示) *
CMMN引擎(支持异步服务、手动激活规则、自动完成、用户事件监听器)
DMN引擎(决策引擎, 如排他网关设置条件可以进行识别并决定走向)
IDM身份识别引擎 (自带一套身份认证体系)
表单引擎 (自带一套组件编辑器,可在界面画表单,实现流程流转)
*内容引擎 (在mybatis上封装获取表元数据、流程模型等)
自定义sql
如果你的业务对于flowable的api接口还不满足,那么你可以写一些自定义的sql。如下代码示例:
//查询待办信息
public List<Task> QueryTask(String businessType, List<String> businessIds) {
if(StringUtils.isEmpty(businessType) || ListUtil.isEmpty(businessIds)) {
logger.warn("QueryTaskRecord请求参数为空. businessType:"+businessType+" businessIds:"+businessIds);
return new ArrayList<>();
}
StringBuffer businessIdsSb = new StringBuffer();
for(int i = 0;i < businessIds.size(); i++) {
String businessId = businessIds.get(i);
if (i == businessIds.size() - 1) {
businessIdsSb.append("'" + businessId + "'");
} else {
businessIdsSb.append("'" + businessId + "',");
}
}
StringBuffer sb = new StringBuffer();
sb.append("SELECT RES.*FROM ACT_RU_TASK RES " +
"LEFT JOIN ACT_RU_VARIABLE VAR ON RES.`PROC_INST_ID_` = VAR.`PROC_INST_ID_`" +
"WHERE RES.`PROC_INST_ID_` IN (" +
"SELECT `PROC_INST_ID_` FROM ACT_RU_VARIABLE " +
"WHERE `PROC_INST_ID_` IN (" +
"SELECT `PROC_INST_ID_` FROM ACT_RU_VARIABLE " +
"WHERE `NAME_` = 'business_id' AND `TEXT_` IN (" + businessIdsSb.toString() + ")" +
") AND `NAME_` = 'business_type' AND `TEXT_` = '" + businessType + "'" +
") group by VAR.`PROC_INST_ID_`" +
"order by RES.`CREATE_TIME_` desc");
//通过传入自定义sql,返回的结果必须是ACT_RU_TASK的结果集,因为Task对应的表是ACT_RU_TASK,传入
List<Task> tasks = taskService.createNativeTaskQuery().sql(sb.toString()).parameter("business_type", businessType).list();
return tasks;
}
当然你也可以使用mybatis等orm框架去实现自定义sql,但是使用TaskService和HistoryService服务提供自定义sql的api是有一定区别。这点需要注意,flowable框架的自定义sql的api在执行方法的时候有事务的隔离性,它允许节点执行跳转到下一个节点操作的时候查询待办可以到下一节点的待办信息,而使用orm框架则无法做到在同一方法里执行
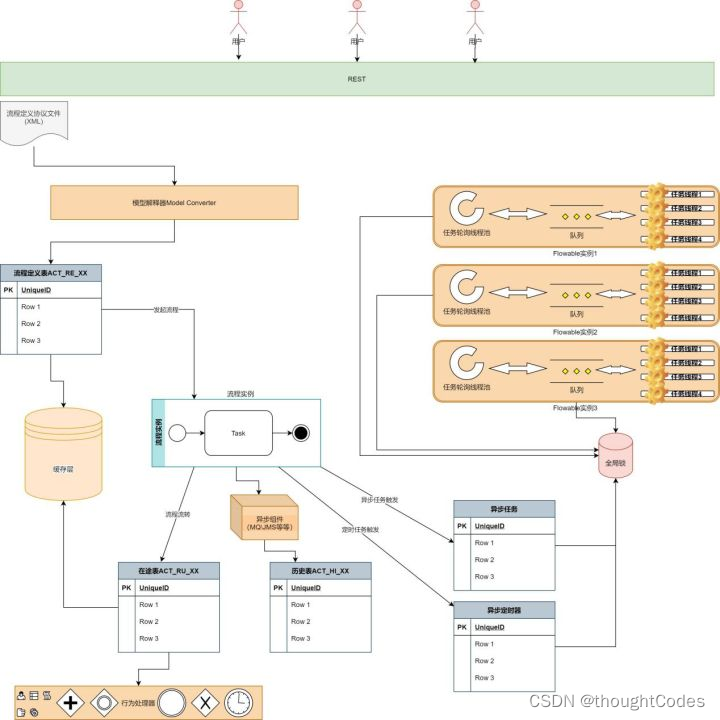
节点跳转再去查询下一节点的待办信息,因为此时的下一节点的数据还没存入到db中所以查询不到。
从架构图中可以看出,Flowable对于数据的处理是冷热分离的,热数据存在ACT_RU_系列表中,历史冷数据存在ACT_HI_系列表中,定义相关的存在ACT_RE_系列表中,而对于在途和定义相关的数据,有一层缓存,他缓存的具体实现比较复杂,这里不多赘述。
对于协议到运行态的转化,有专门一层Converter来实现,也就是说,如果你想自己定义一些协议外的东西,就需要关心这个部分。
Flowable在最新的版本中,对于历史归档和异步任务做了新的优化,具体的看下面。
新的异步执行器(ASYNC EXECUTOR)
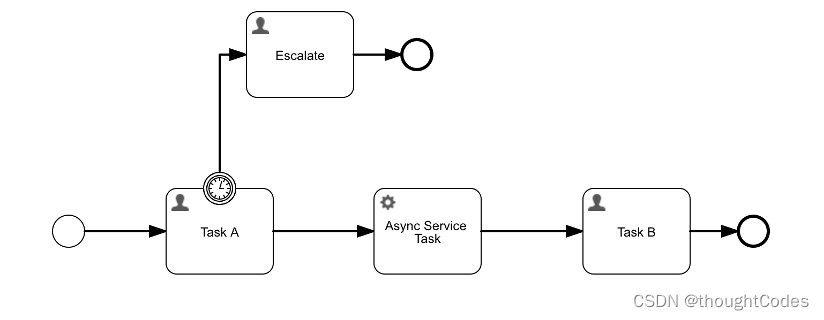
在工作流中,异步执行大概分为两类,timer和message,类似于定时事件就是timer,而异步的服务任务则为message,如上图所示,“Task A”附着的边界定时事件,在时间触发之后,会执行“Escalate”任务,而“Async Service Task”在“Task A”流转之后,会启用一个异步任务去调用其服务。
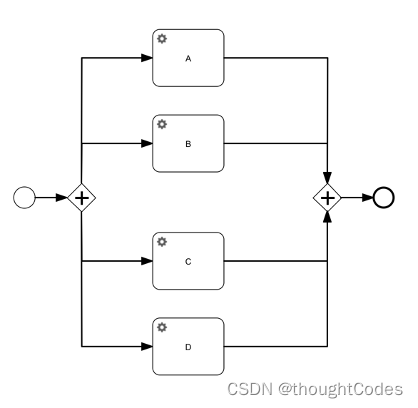
对于一种全是异步服务任务的极端情况,如上图所示,他常常出现于服务编排之类的场景之中,我们经常性的需要同时处理一系列的任务,这时候异步调度的作用就非常重要。
为了提高性能,Flowable也采用了冷热数据分离的思想,他把数据分为了4类,异步Job,定时器Timer,挂起任务,死信队列。通过测试发现,数据库是异步任务性能低下的主要瓶颈,特别是多实例竞争Job会存在潜在的问题。在分表的时候同时加上了一个全局锁,保证了同一个实例只能由一个实例去获取并锁定job(job表中有字段会被update,内容为抢占到的实例代号),这样反而能提升不少性能。为了保证各个实例不被饿死,还调整了一系列参数。
Flowable提供了一个更加优化的冷热数据分离方案,在数据敏感性比较高的领域,我们一般会把引擎的历史记录级别调到最高(包括流程流转历史、变量变动历史、签收人变动历史等等),这些历史记录在以前是在同一个上下文中执行的,虽然在最开始设计的时候,在途数据和历史数据就冷热分离了,但从权衡在途和历史的重要性的角度来讲,历史其实不是最重要的,所以Flowable提供一系列的方法使历史记录这个行为异步化,与之对应的方法可以是jms,MQ或Spring Boot listener application。 这个改动可以提升在途流程效率20%-96%。
参考资料和推荐阅读
- https://blog.csdn.net/qq_25542879/article/details/107067551
2.https://www.cnblogs.com/johnvwan/p/15630018.html
欢迎阅读,各位老铁,如果对你有帮助,点个赞加个关注呗!~
如有版权等私信联系,请私信删除

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)