如何使用ISAT_with_segment_anything-master进行半自动的数据标注+小车yolo循迹
参考:b站up主开源代码,直接在本站搜索“ISAT_with_segment_anything-master”即可找到开源代码,截图如下:你如果直接使用了作者的开源代码,那么在这个开源代码运行之后会得到如下的界面:你需要打开里面的main.py文件夹,运行它得到如下的界面:在这样的界面里面点击模型,你可以找到你想要下载的模型SAM(这个模型就是用于快速标注的模型),值得注意的是模型的大小是需要选择
第一步 需要下载这样的文件
参考:b站up主开源代码,直接在本站搜索“ISAT_with_segment_anything-master”即可找到开源代码,截图如下:
第二步 下载好权重文件
你如果直接使用了作者的开源代码,那么在这个开源代码运行之后会得到如下的界面:
你需要打开里面的main.py文件夹,运行它得到如下的界面: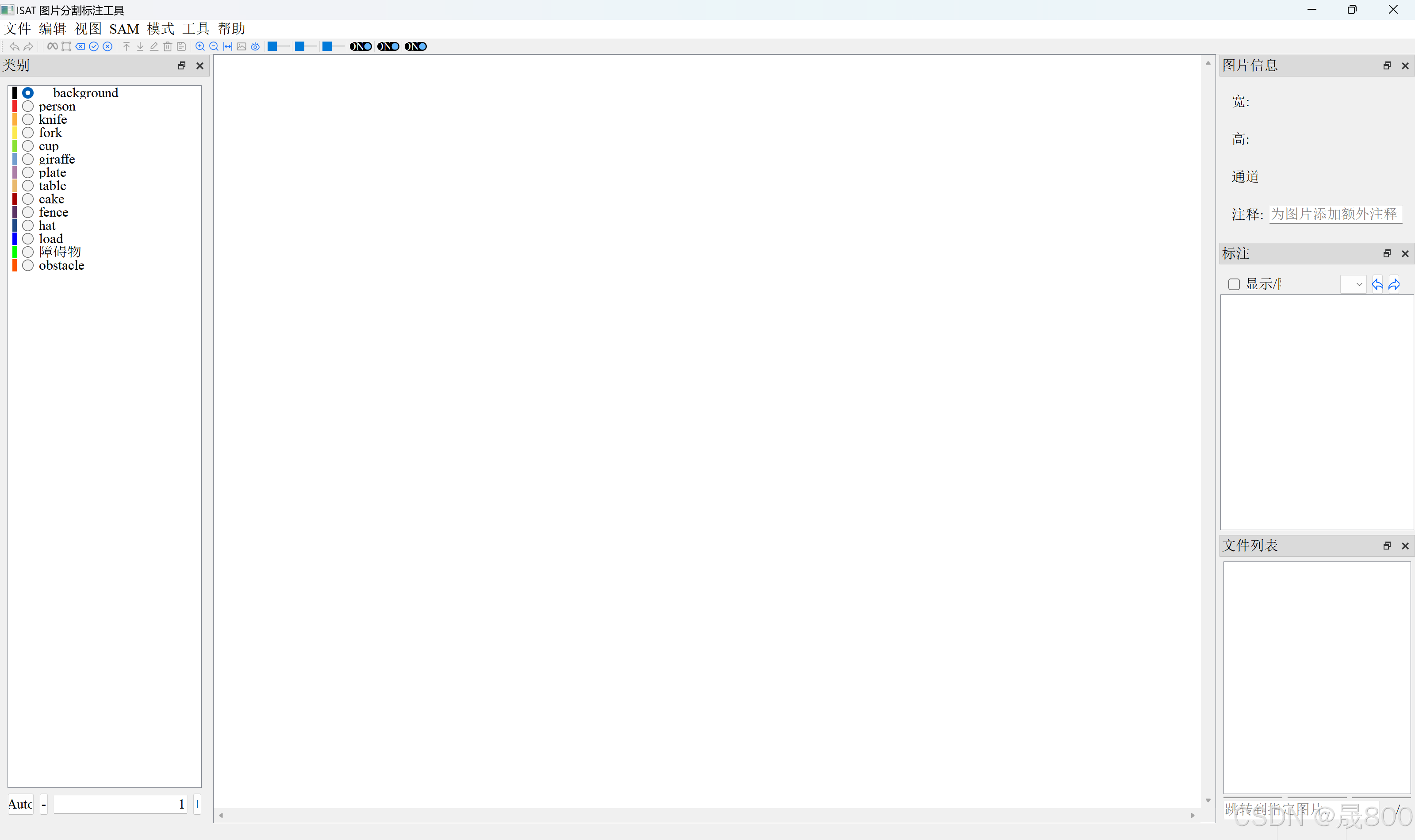
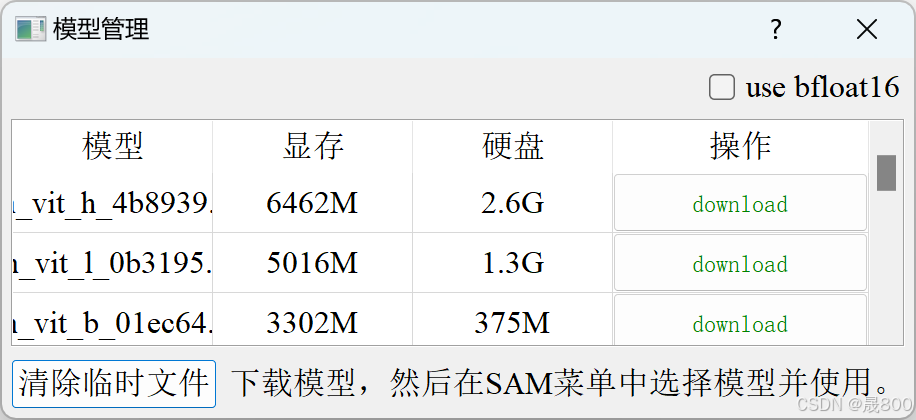
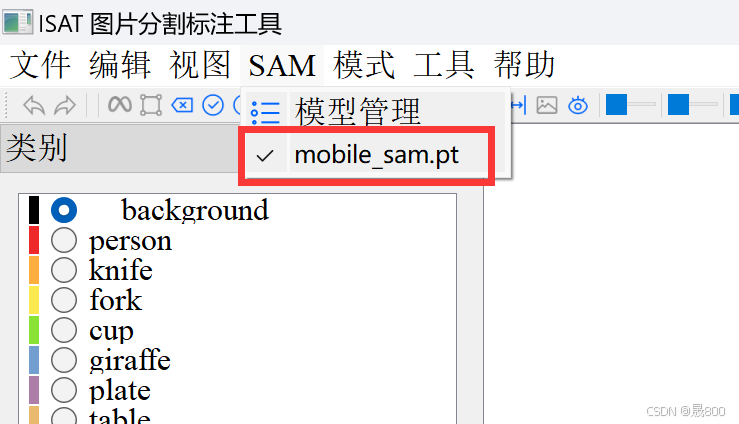
在这样的界面里面点击模型,你可以找到你想要下载的模型SAM(这个模型就是用于快速标注的模型),值得注意的是模型的大小是需要选择的,这个取决于你的电脑性能,像我的电脑只能选择最小的模型,其需要的显存为2G(所以这个方式是需要GPU的),结果如下(模型管理可以下载模型,下载之后可以在SAM当中选择你所下载的模型),如下:
选择需要的模型:
第三步 标注
1.需要增加标注的标签以及数据集的来源标注保存地址,其分别在文件这个按键当中,进行选择(请多尝试几遍即可)
2.完成模型的装载以及数据集路径定义之后,需要点击形似无限的按键进行标注(现在开始展示标注过程):
第一步:(数据集文件夹位置选择正确之后便可以看到图片),如下:

第二步:根据需要标志目标以及标签,选择左侧标签然后将十字中心移到你需要标注的目标上,注意:鼠标左键表示对此感兴趣,右键表示对此不感兴趣,完成标志之后点击E保存标注,结果如下:
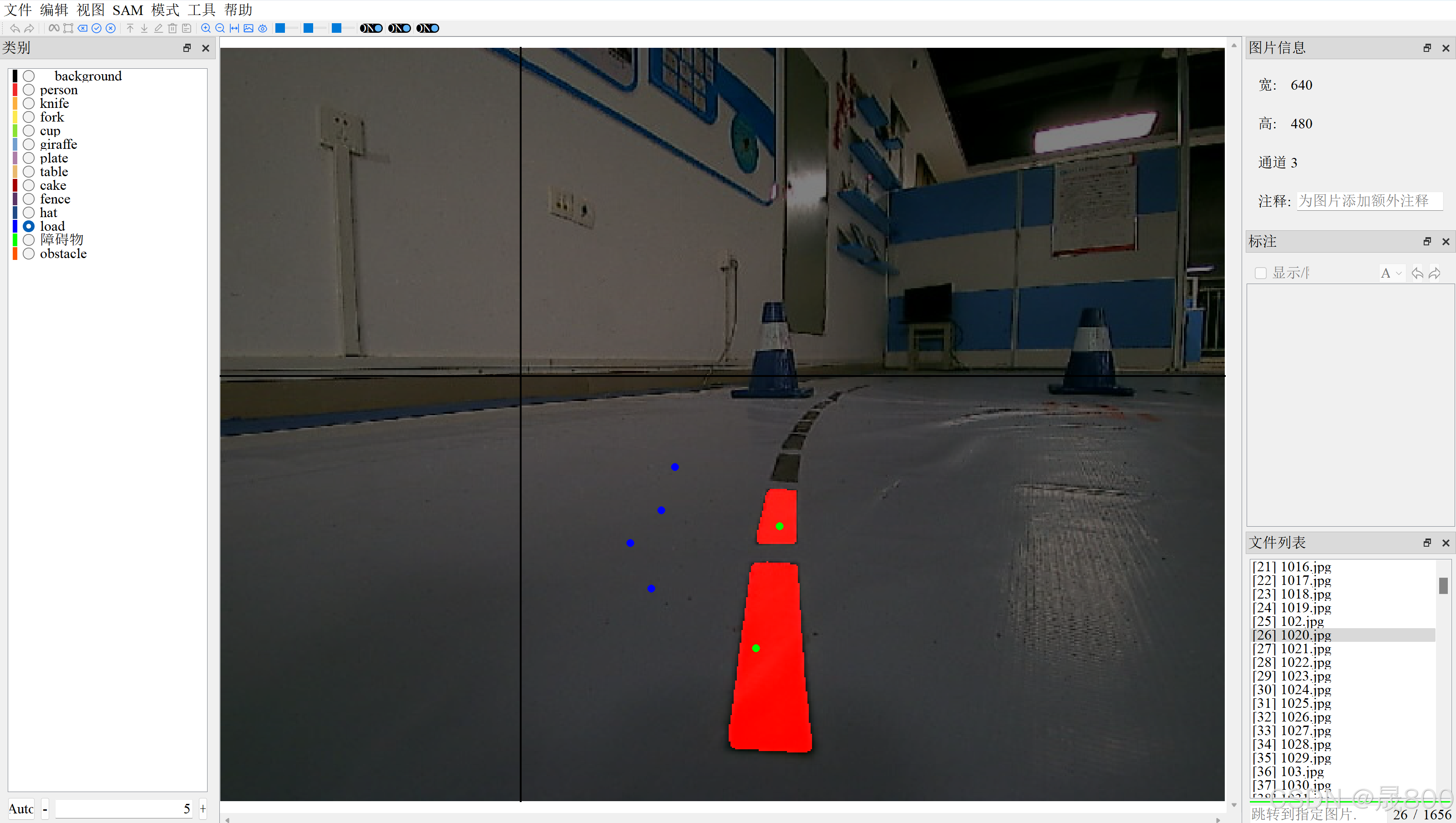
绿点表示感兴趣,蓝点表示不感兴趣,点击E之后进行可以进行调整,同时右侧回显示此时的标注结果:
第三步 保存
完成以上所有步骤之后不要忘记保存按键,不然不会保存,保存之后可以在标签文件当中看见如下界面:
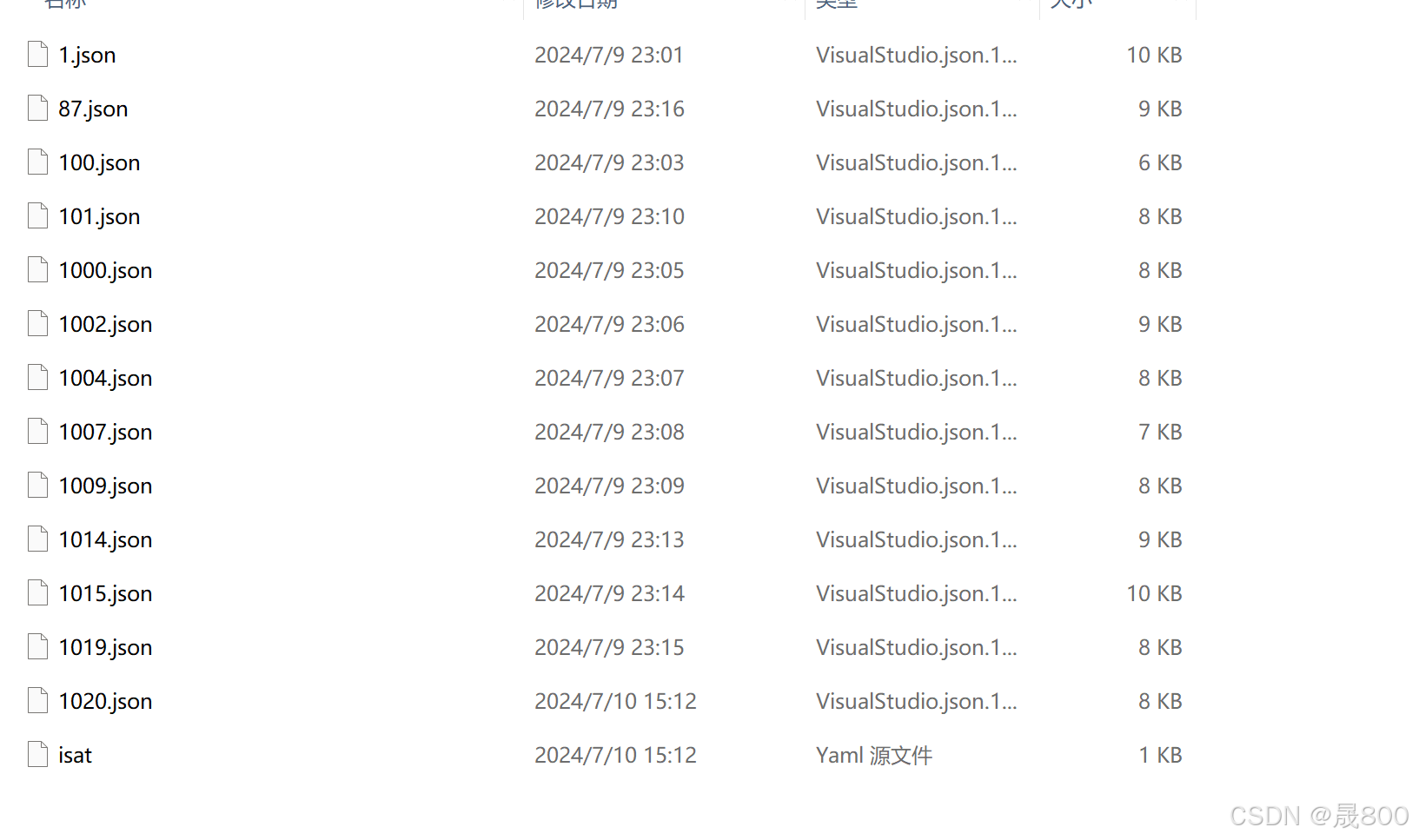
当然这个是json的标签,需要转换为txt,这个可以看之后的代码解释的
第四步 转换json→txt(适合yolo)
注意你的输出标签是JSON格式,你需要将其转换为txt格式,这样的格式才能够适合yolo训练,针对我的转化代码如下:
代码解释:
1.导入库:
import os
import cv2
import json
import numpy as np
2.定义函数txt_write:
def txt_write(x, img_x, img_y, txt):
data = x['points']
n = 1
for x in data:
for i in x:
if n % 2 == 0:
txt.write(' ' + str(round(i / img_x, 6)))
n += 1
else:
txt.write(' ' + str(round(i / img_y, 6)))
n += 1
txt.write('\n')
- 该函数用于将标注点的坐标转换为YOLO格式的归一化坐标,并写入文本文件。
x:包含点坐标的字典。img_x和img_y:图像的宽和高,用于归一化坐标。txt:输出文件对象。
3.定义函数json2txt:
def json2txt(json_path, save_path):
txt = open(save_path, 'w')
with open(json_path, "r") as f:
data = f.read()
data = json.loads(data)
img_x = data['imageHeight']
img_y = data['imageWidth']
shapes = data['shapes']
for x in shapes:
if x['label'] == 'road':
txt.write('0')
txt_write(x, img_x, img_y, txt)
if x['label'] == 'line':
txt.write('1')
txt_write(x, img_x, img_y, txt)
if x['label'] == 'sand':
txt.write('2')
txt_write(x, img_x, img_y, txt)
txt.close()
- 该函数用于读取JSON文件,提取标注信息,并将其转换为YOLO格式的文本文件。
json_path:输入JSON文件路径。save_path:输出TXT文件路径。- 打开JSON文件并读取数据。
- 获取图像的宽高。
- 遍历标注的形状,根据标签(
label)写入不同的类别标识(如0、1、2),然后调用txt_write函数写入坐标信息。
4.
json_dir = 'D:\\学习\\个人\\比赛\\智能车\\培训任务\\xx-第三次培训-5.11\\标签\\json\\'
save_dir = 'D:\\学习\\个人\\比赛\\智能车\\培训任务\\xx-第三次培训-5.11\\标签\\txt\\'
files = os.listdir(json_dir)
os.makedirs(save_dir, exist_ok=True)
num = 1
for file in files:
name = file[0:-5]
json_path = json_dir + '/' + name + '.json'
save_path = save_dir + '/' + name + '.txt'
json2txt(json_path, save_path)
print(num, '/', len(files), ':', name)
num += 1
- 指定JSON文件目录和保存TXT文件的目录。
- 获取JSON文件目录下所有文件的列表。
- 创建保存TXT文件的目录(如果不存在)。
- 遍历每个文件,调用
json2txt函数进行转换,并打印处理进度。
到此,完成本次设计的标签的转化。
完整代码如下:
import os
import cv2
import json
import numpy as np
def txt_write(x, img_x, img_y, txt):
data = x['points']
n = 1
for x in data:
for i in x:
if n % 2 == 0:
txt.write(' ' + str(round(i / img_x, 6)))
n += 1
else:
txt.write(' ' + str(round(i / img_y, 6)))
n += 1
txt.write('\n')
def json2txt(json_path, save_path):
txt = open(save_path, 'w')
with open(json_path, "r") as f:
data = f.read()
data = json.loads(data)
img_x = data['imageHeight']
img_y = data['imageWidth']
shapes = data['shapes']
for x in shapes:
# print(x['label'])
# 此处面向不同分类,需要改动下面的标签值,如果是多分类,那么需要增加新的if
# 只是单分类的话,可以直接去掉if,把里面的模块拿出来用
if x['label'] == 'road':
txt.write('0')
txt_write(x, img_x, img_y, txt)
if x['label'] == 'line':
txt.write('1')
txt_write(x, img_x, img_y, txt)
if x['label'] == 'sand':
txt.write('2')
txt_write(x, img_x, img_y, txt)
txt.close()
# 单文件测试
# save_dir = "/workspace/" #文件路径
# name = 'test'
# save_path = save_dir + name + '.txt' # 也可以是.doc
# json_path = '/json/65161.json'
# json2txt(json_path,save_path)
# 文件夹
json_dir = 'D:\\学习\\个人\\比赛\\智能车\\培训任务\\xx-第三次培训-5.11\\标签\\json\\'
save_dir = 'D:\\学习\\个人\\比赛\\智能车\\培训任务\\xx-第三次培训-5.11\\标签\\txt\\'
files = os.listdir(json_dir)
os.makedirs(save_dir, exist_ok=True)
num = 1
for file in files:
name = file[0:-5]
json_path = json_dir + '/' + name + '.json'
save_path = save_dir + '/' + name + '.txt'
json2txt(json_path, save_path)
print(num, '/', len(files), ':', name)
num += 1
第五步 配置yolo
转换为txt之后可以查看网络上关于语义分割的yolo配置方式,使用里面的segment里面的train以及predict进行检测,如下:
配置和单纯的识别大致相似,里面也需要一个yaml文件里面定义了数据集以及标签的路径以及类别种类。(注意相较于传统的yolo框选识别,他会少一个yolo的权重结构文件,或者替换成了其他的文件?这个我也不是很清楚)
第六步 开始训练
将训练后的模型放在segment下面的prediect下面检测性能,初始其输出应该为

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)