国产数据库 - 架构设计 - 初识Doris
国产数据库 - 架构设计 - 初识DorisDoris是一款基于MPP架构的分析型数据库。整体架构很简单,只有两类进程FE和BE。其中FE(Frontend)主要负责用户请求的接入、查询解析规划、元数据管理和节点管理相关工作;BE(Backend)主要负责数据存储、查询计划的执行。1、架构业界比较有名另一款的MPP分布式数据库GreenPlum,对照其来说,这里的FE和GPDB的Master相对应
国产数据库 - 架构设计 - 初识Doris
Doris是一款基于MPP架构的分析型数据库。整体架构很简单,只有两类进程FE和BE。其中FE(Frontend)主要负责用户请求的接入、查询解析规划、元数据管理和节点管理相关工作;BE(Backend)主要负责数据存储、查询计划的执行。
1、架构
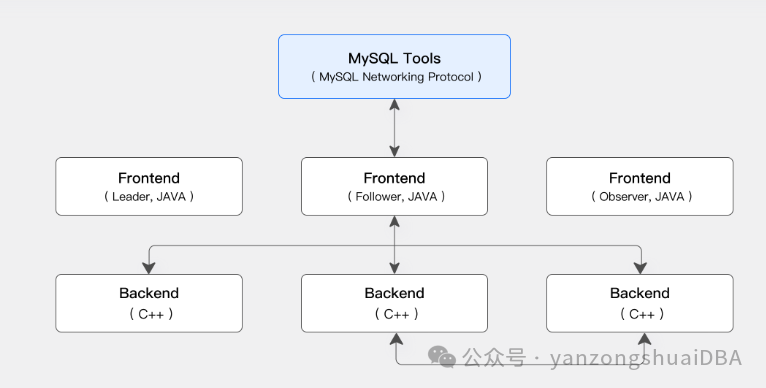
业界比较有名另一款的MPP分布式数据库GreenPlum,对照其来说,这里的FE和GPDB的Master相对应,BE对应于Segment。
2、存储引擎
采用列存,支持比较丰富的索引:
1)Sorted Compound Key Index,可以最多指定三个列组成复合排序键,通过该索引,能够有效进行数据裁剪,从而能够更好支持高并发的报表场景
2)Min/Max:有效过滤数值类型的等值和范围查询
3)Bloom Filter:对高基数列的等值过滤裁剪非常有效
4)Inverted Index:能够对任意字段实现快速检索
3、查询执行引擎
采用 MPP 的模型,节点间和节点内都并行执行,也支持多个大表的分布式 Shuffle Join,从而能够更好应对复杂查询:
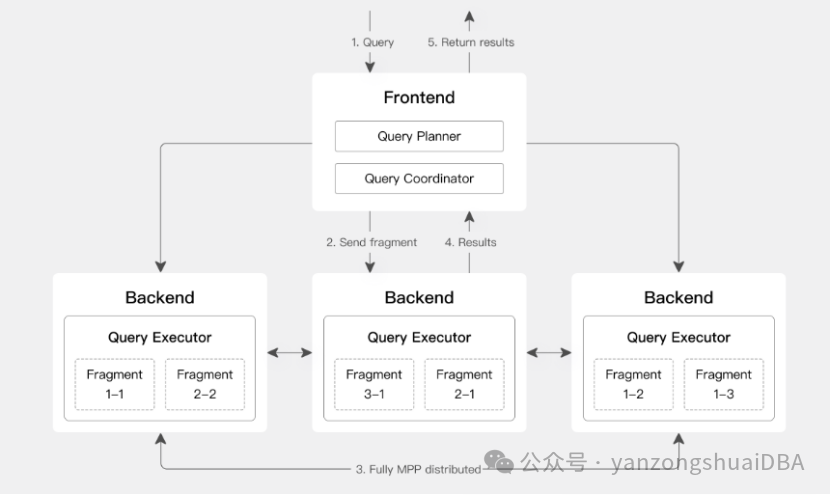
Doris 查询引擎是向量化的查询引擎,所有的内存结构能够按照列式布局,能够达到大幅减少虚函数调用、提升 Cache 命中率,高效利用 SIMD 指令的效果。在宽表聚合场景下性能是非向量化引擎的 5-10 倍。
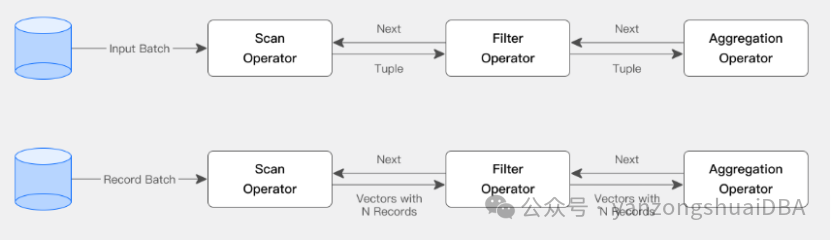
Doris 采用了 Adaptive Query Execution 技术, 可以根据 Runtime Statistics 来动态调整执行计划,比如通过 Runtime Filter 技术能够在运行时生成 Filter 推到 Probe 侧,并且能够将 Filter 自动穿透到 Probe 侧最底层的 Scan 节点,从而大幅减少 Probe 的数据量,加速 Join 性能。Doris 的 Runtime Filter 支持 In/Min/Max/Bloom Filter。
4、几个重要概念
4.1 分区、分桶与Tablet
和GPDB一样,Doris也支持表分区,支持的分区方式有Round-Rbin、Range、List和Hash,他是一个逻辑概念。第二层数据划分就是分桶:表定义时可以定义分为几个桶,然后一个分区里面的数据按照:分桶键%分桶数,hash出位于哪个桶上,该桶可以认为是一个Tablet;它是一个物理概念,以多副本的形式均匀分布在BE节点上。
1)分区的作用可以按照分区键拆分成不同的管理单元,针对每个分区制定相应存储策略:比如副本数、分桶数、冷热策略、存储介质等。
2)有了分区,就可以有效地进行分区裁剪,减少扫描数据量
3)Tablet(数据分片)以多副本形式存储,是数据均衡和恢复的最小单位。
4.2 物理执行计划
物理执行计划由FE生成,由物理算子构成执行计划树。
4.3 计划碎片
和GPDB的slice概念有些类似。GPDB中的执行计划由Motion算子进行划分,两边分为不同slice,即不需要发生数据交换的一批算子组成一个slice。而Doris中的计划碎片类似,如下图,左边是一个物理执行计划,同样是以发生数据交换的节点进行分割,右边分割为4个计划碎片:碎片3和碎片4分别通过DataStreamSink 算子发送数据给碎片2,碎片2通过Exchange算子接收。
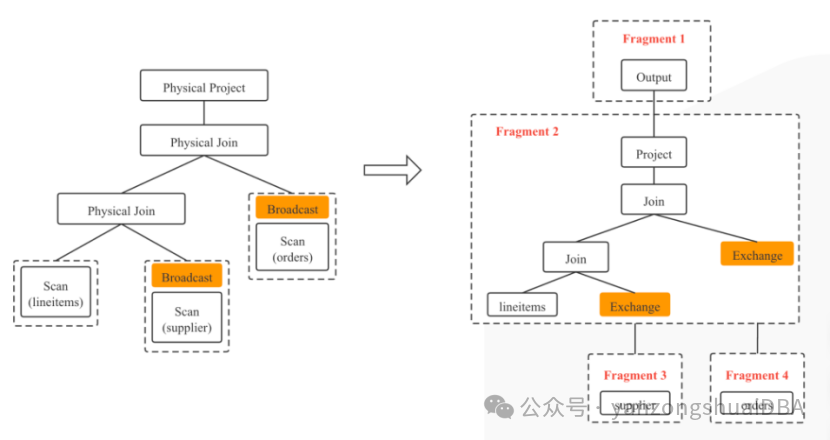
4.4 计划碎片实例
Fragment Instance 是 PlanFragment 的一个执行实例,StarRocks 的 table 经过分区分桶被拆分成若干 tablet,每个 tablet 以多副本的形式存储在计算节点上。可以将 PlanFragment 的实例化成多个 Fragment Instance 处理分布在不同机器上的 tablet,从而实现数据并行计算。FE 确定 Fragment Instance 的数量和执行 Fragment Instance 的目标 BE,然后 FE 向 BE投递 Fragment Instance。这里的意思是:以tablet副本数为基础进行并行。比如tablet有3个副本,那么就生成3个计划碎片实例,而这个三个计划碎片实例分别发送到不同BE上(tablet的3个副本位于3个不同BE上),三个BE分别并行执行这个计划碎片。当然,理想状态是3个BE负责扫不同的tablet。当BE数目小于tablet数时,每个BE就要负责多个tablet的扫描了。
这里说一个简单的例子:
select A.c0, B.c1 from A, B where A.c0 = B.c0
1)FE 产生物理计划并且拆分计划碎片,如下图所示,物理计划被拆分成三个计划碎片,其中 Fragment 1 包含 HashJoinNode,Fragment 0 为 HashJoinNode 的右孩子。
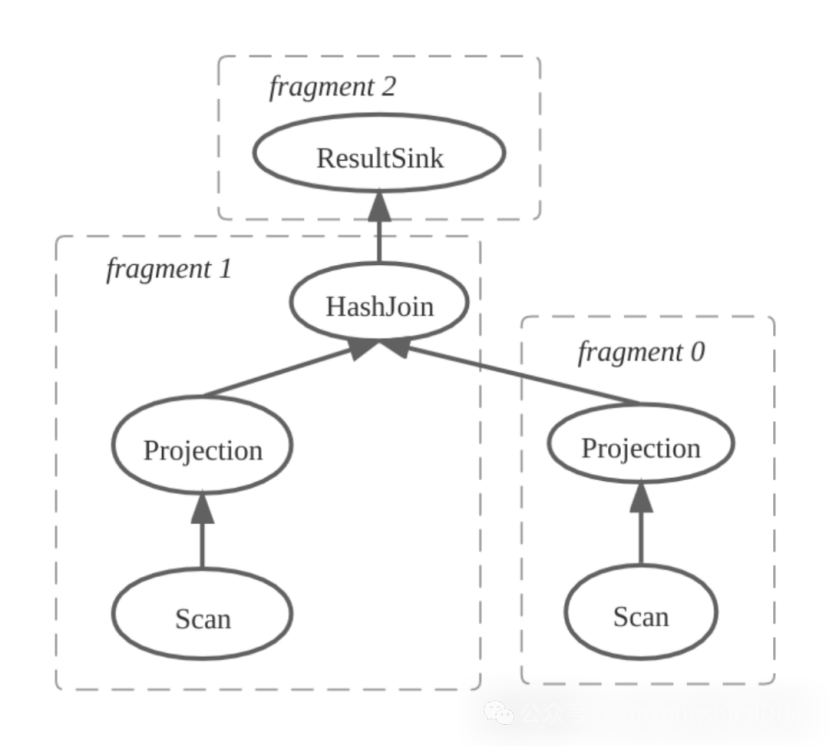
2)FE确定计划碎片实例数量并创建碎片实例。这里默认tablet副本为3,这3个副本分别位于不同的BE中,所以计划碎片1生成3个碎片实例,让不同BE并行JOIN
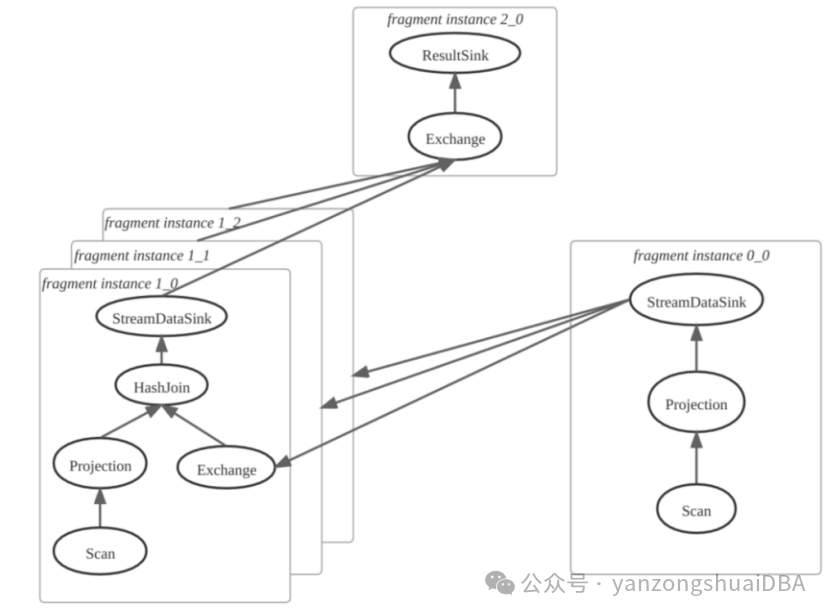
3)FE 将所有 Fragment Instance,一次性(all-at-once)投递给 BE,BE 执行 Fragment Instance。
4.5 物理算子
物理算子是构成物理执行计划 PlanFragment 的基本元素,例如 OlapScanNode,HashJoinNode 等等。另外,在 Fragment Instance 中,一般用 DataSink 的子类描述该 Fragment Instance 计算结果的去向,比如 DataStreamSink 会把计算结果发给下游 Fragment Instance的ExchangeNode。
4.6 Pipeline算子
Pipeline 算子是组成 Pipeline 的元素,BE 的 PipelineBuilder 拆分 PlanFragment 为 Pipeline 时,物理算子需要转换为成 Pipeline 算子,给Pipeline执行引擎去执行。比如DataStreamSind和ExchangeNode会转换成ExchangeSinkOperator和ExchangeSourceOperator。当然,Pipeline算子会比物理算子多,因为一个pipeline算子最多仅能有一个数据输入和一个数据输出,对于需要两个或多个输入的算子比如HashJoinNode来说(需要左节点和右节点的数据)需要转换成HashJoinBuildOperator和HashJoinProbeOperator,顾名思义,分别用来构建hash表和进行hash探测。
参考
https://cwiki.apache.org/confluence/display/DORIS/DSIP-035%3A+PipelineX+Execution+Engine
https://www.modb.pro/db/1791005929474445312
https://www.modb.pro/db/529387
https://www.modb.pro/db/397988
https://www.modb.pro/db/518212
https://www.ihnfsa.com/database/mpp-in-doris/
https://doris.apache.org/zh-CN/docs/dev/lakehouse/lakehouse-overview
https://docs.starrocks.io/zh/docs/2.5/introduction/Features/
https://zhuanlan.zhihu.com/p/596838323
https://my.oschina.net/u/5658056/blog/5519656

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)