AI代码助手Tabby项目源码学习记录(从0开始构建专属代码机器人)
通过阅读本文档,您可以快速了解开源代码项目Tabby的核心模块与服务流程,并且参照文档可以在本地部署一个Tabby AI代码助手进行使用。文末附上鼠鼠我在学习Tabby项目中的一些心得分享,希望对零大型项目代码阅读经验的小白有所帮助捏~ :D(PS:本文是鼠鼠之前7月学习的笔记,距离现在有一段时间了,学习的版本是v0.13.1。截至到2024.10.28,已发布到v0.18.0,仅供参考捏~)
感谢您点开这篇文章:D,鼠鼠我是一个代码小白,下文是学习开源项目Tabby过程中的一点笔记记录,希望能帮助到你~本人菜鸟,持续成长,能力不足有疏漏的地方欢迎一起探讨指正~
通过阅读本文档,您可以快速了解开源代码项目Tabby的核心模块与服务流程,并且参照文档可以在本地部署一个Tabby AI代码助手进行使用。
文末附上鼠鼠我在学习Tabby项目中的一些心得分享,希望对零大型项目代码阅读经验的小白有所帮助捏~ :D
(PS:本文是鼠鼠之前7月学习的笔记,距离现在有一段时间了,学习的版本是v0.13.1。截至到2024.10.28,已发布到v0.18.0,仅供参考捏~)
目录
3.1、completion.rs和completion_prompt.rs
一、Tabby简介
Tabby是一款开源、自托管的 AI 编码助手。它提供了一个开源且可本地部署的替代方案,与 GitHub Copilot 类似。
GitHub Copilot 是一个由 GitHub 提供的 AI 编码助手,它集成在 Visual Studio Code 编辑器和 JetBrains 系列 IDE中。GitHub Copilot 利用机器学习技术,根据开发者的代码上下文提供自动完成建议、代码补全、快速注释生成等功能,旨在提高开发效率和代码质量。
借助 Tabby,每个团队都可以轻松设置自己的 LLM 驱动的代码完成服务器。
-
Tabby Github官网:GitHub - TabbyML/tabby: Self-hosted AI coding assistant
-
Tabby文档:👋 What's Tabby | Tabby

二、Tabby安装
1、安装运行服务
运行环境:Ubuntu24.04、纯CPU环境
1.1、通过可执行文件形式运行

下载对应压缩包后,解压后给文件添加可执行权限

chmod +x tabby llama-server运行
# For CPU-only environments
./tabby serve --model StarCoder-1B --chat-model Qwen2-1.5B-Instruct
# For GPU-enabled environments (where DEVICE is cuda or vulkan)
./tabby serve --model StarCoder-1B --chat-model Qwen2-1.5B-Instruct --device $DEVICE1.2、通过项目代码运行
参考文档:tabby/CONTRIBUTING.md at main · TabbyML/tabby
1.2.1、本地设置
参考文档:Getting started
#1、安装Rusttup:Rust 安装程序和版本管理工具
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
#Rust更新非常频繁,如果之前安装了 Rustup,那么Rust 版本很可能已经过时。更新:
rustup update
#Cargo:Rust 构建工具和包管理器。测试是否安装Rust和Cargo
cargo --version安装依赖项及其他前置操作
# For Ubuntu / Debian
apt-get install protobuf-compiler libopenblas-dev
# For Ubuntu
sudo apt install make sqlite3 graphviz
#一些测试需要 mailpit SMTP 服务器,安装
sudo bash < <(curl -sL https://raw.githubusercontent.com/axllent/mailpit/develop/install.sh)
#继续之前,请确保所有测试都在本地通过:
cargo test -- --skip golden问题:下载包遇到网络问题
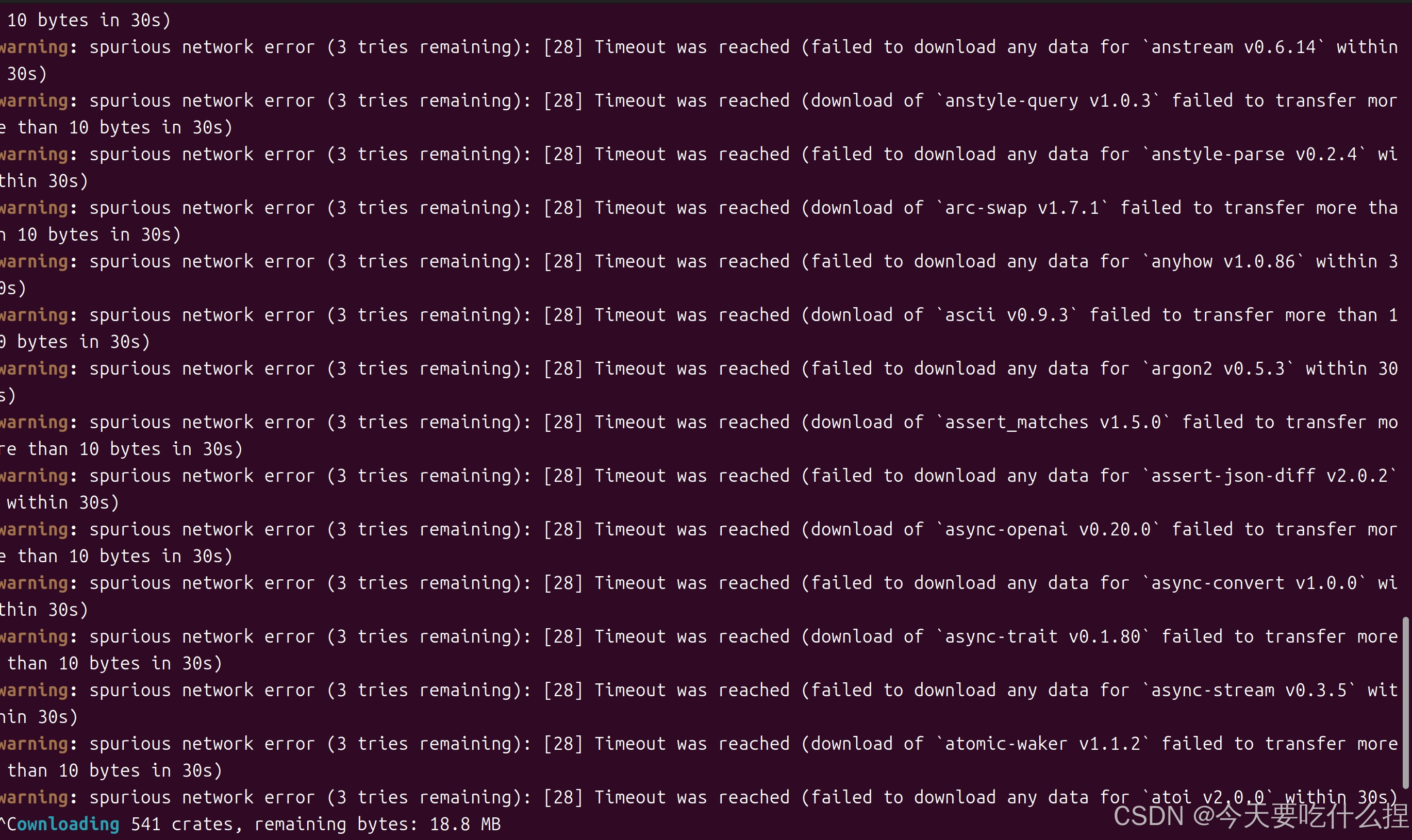
解决措施:更换源
参考:rust crate.io 配置国内源(cargo 国内源) warning: spurious network error (2 tries remainin..._warning: spuriou
sudo vim ~/.cargo/config
#添加以下内容
[source.crates-io]
replace-with='rsproxy'
[source.rsproxy]
registry="https://rsproxy.cn/crates.io-index"
[registries.rsproxy]
index = "https://rsproxy.cn/crates.io-index"
[net]
git-fetch-with-cli = true
问题:构建失败
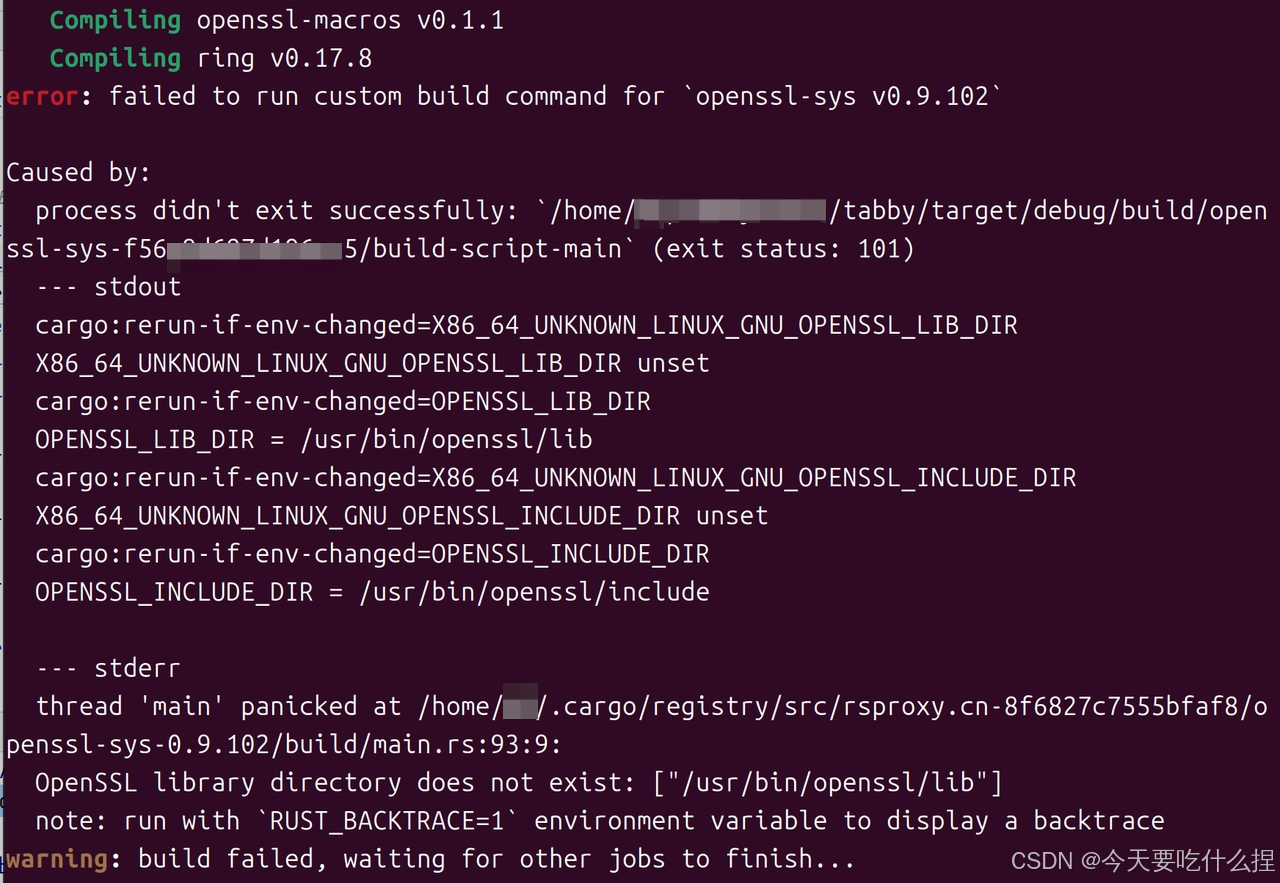
解决方法:(期间还涉及缺少cmake等包,对症下药下载就行)
参考:https://stackoverflow.com/questions/65553557/why-rust-is-failing-to-build-command-for-openssl-sys-v0-9-60-even-after-local-in
sudo apt install pkg-config
sudo apt install libssl-dev
sudo apt-get install libudev-dev
//在[dependencies]下添加
openssl = { version = "0.10", features = ["vendored"] }
1.2.2、构建和运行
在CPU上执行:
cargo run serve --model TabbyML/StarCoder-1B默认情况下,Tabby 将启动localhost:8080并处理请求。
问题:
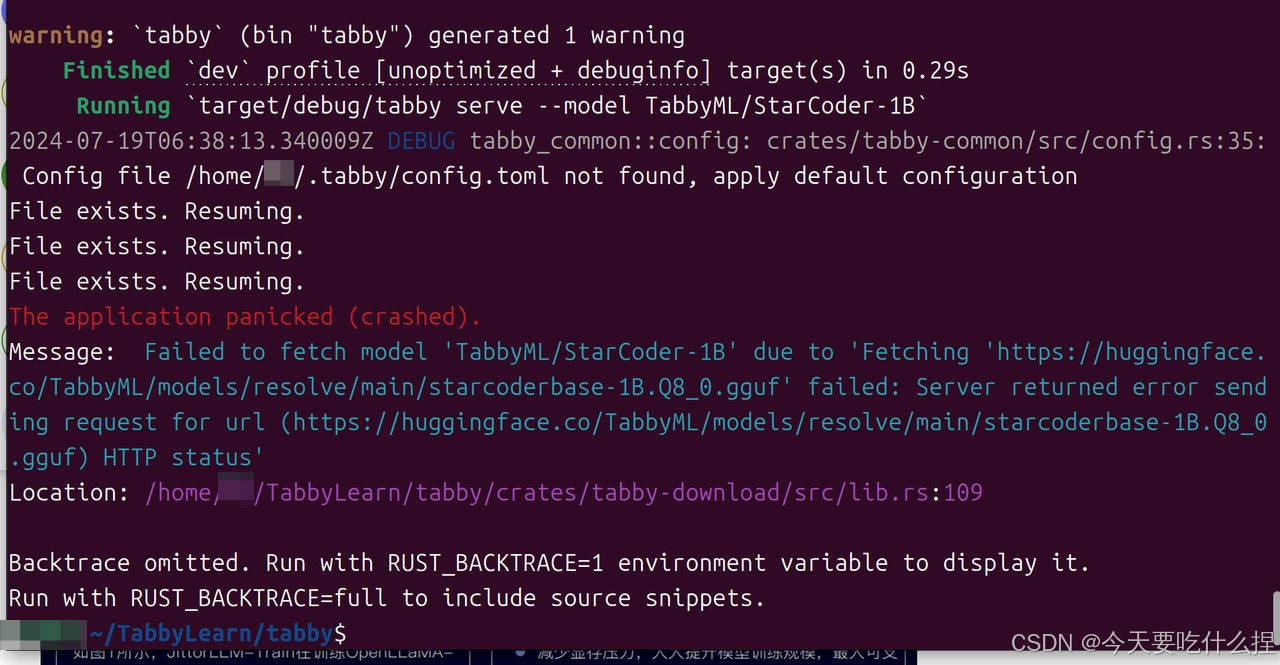
原因:网络问题去不了外网下载模型:https://huggingface.co/TabbyML/models/resolve/main/starcoderbase-1B.Q8_0.gguf

解决方法:
1、下载模型文件
starcoderbase-1B.Q8_0.gguf · TabbyML/models at main
下载StarCoder-1B模型
nomic-ai/nomic-embed-text-v1.5-GGUF at main
下载nomic-embed-text-v1.5.Q8_0.gguf
Qwen/Qwen2-1.5B-Instruct-GGUF at main
下载 qwen2-1_5b-instruct-q8_0.gguf
2、将模型文件放到指定文件夹下面
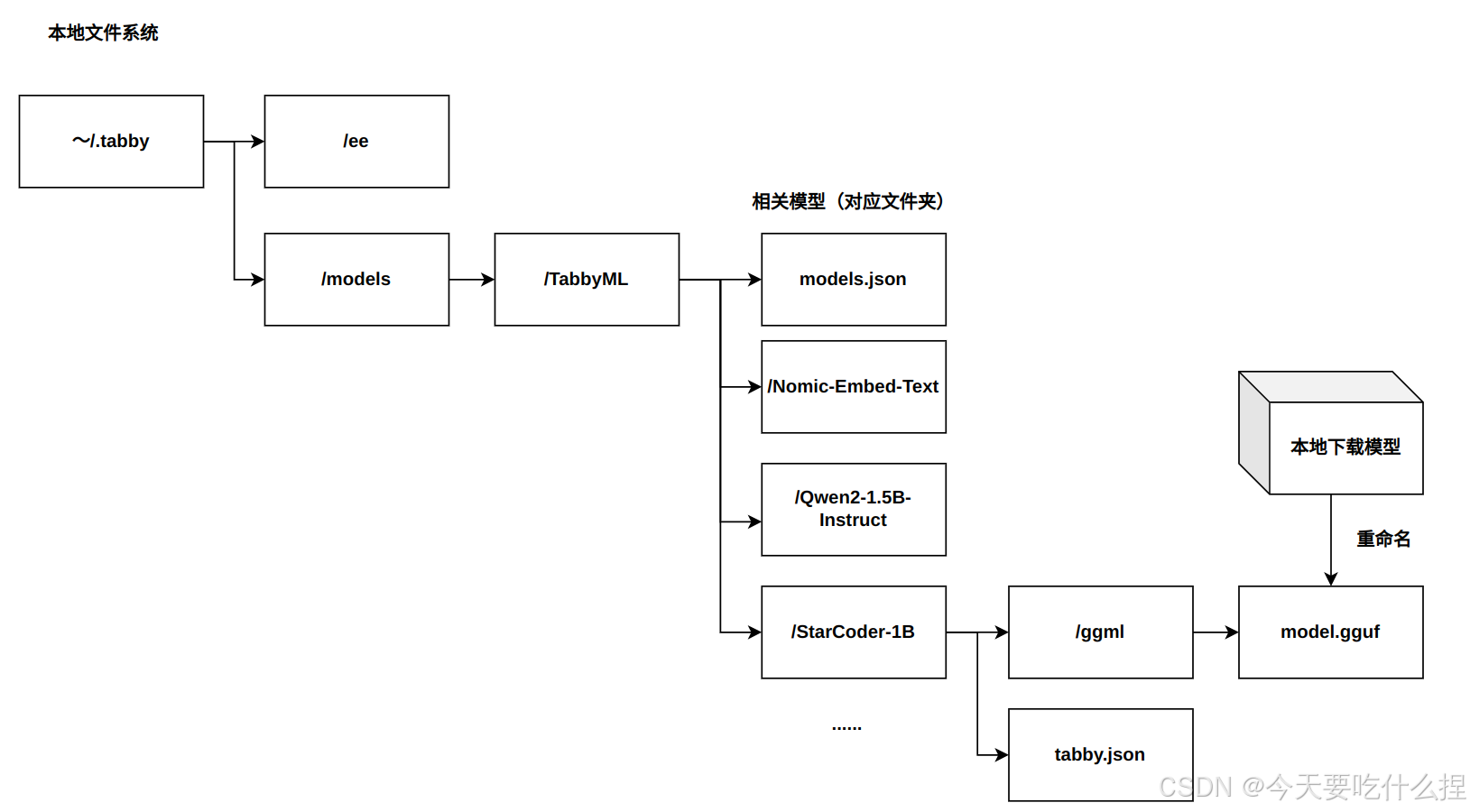
#Nomic-Embed-Text模型,StarCoder-1B模型同理
***:~/.tabby/models/TabbyML/Nomic-Embed-Text/ggml$ mv '/home/***/下载/nomic-embed-text-v1.5.Q8_0.gguf' ~/.tabby/models/TabbyML/Nomic-Embed-Text/ggml/
***:~/.tabby/models/TabbyML/Nomic-Embed-Text/ggml$ ls
model.gguf.tmp nomic-embed-text-v1.5.Q8_0.gguf
#重命名文件
***:~/.tabby/models/TabbyML/Nomic-Embed-Text/ggml$ mv nomic-embed-text-v1.5.Q8_0.gguf model.gguf
***:~/.tabby/models/TabbyML/Nomic-Embed-Text/ggml$ ls
model.gguf model.gguf.tmp3、再次执行命令即可
cargo run serve --model StarCoder-1B --chat-model Qwen2-1.5B-Instruct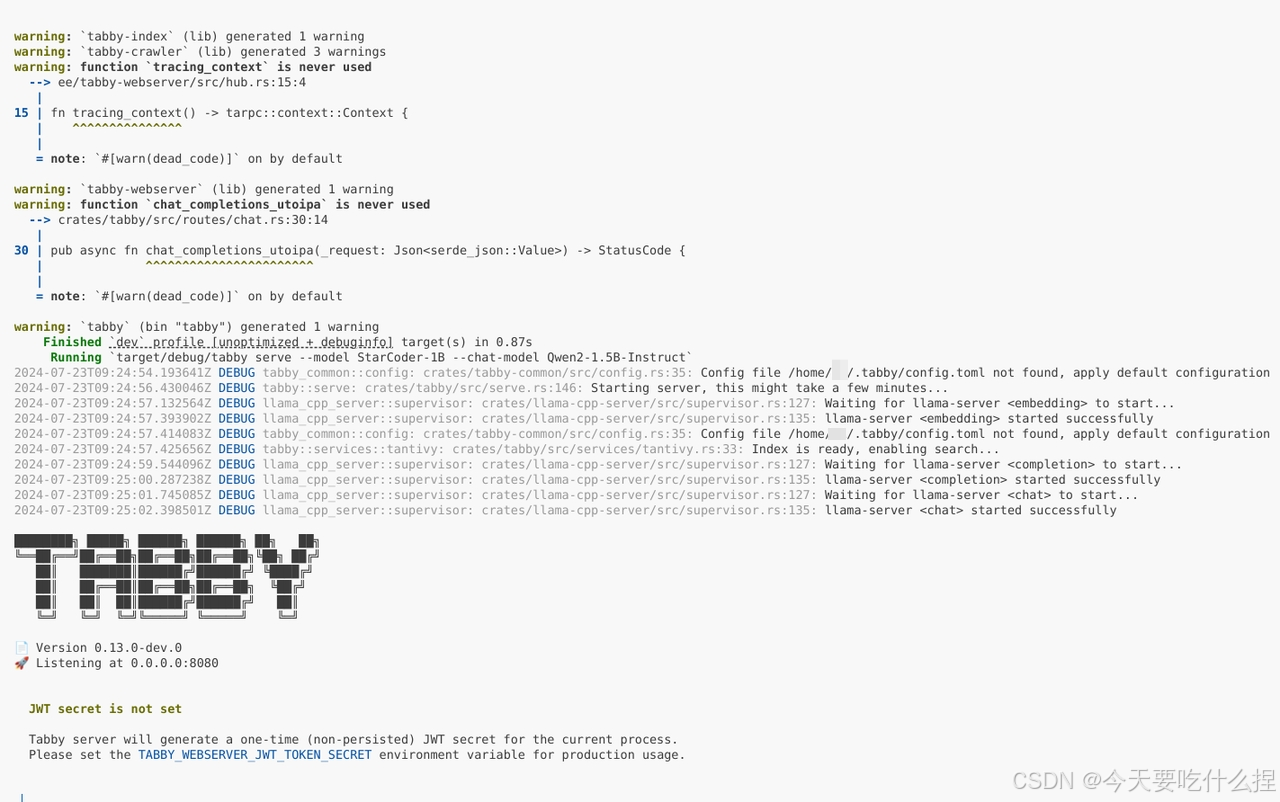
2、注册账户
浏览器进入网页进行注册(http://0.0.0.0:8080/)
3、安装IDE插件
即可使用
三、Tabby项目代码结构
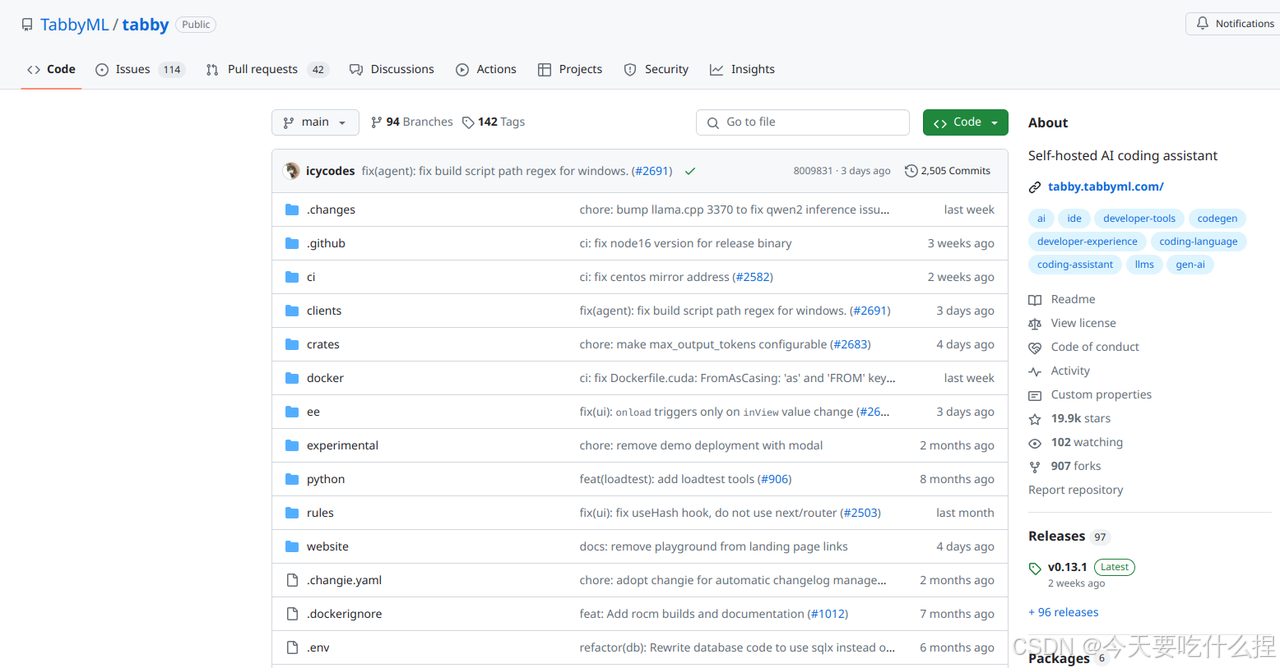
1、crates目录和ee目录
Tabby项目很大分为多个包,每个包负责不同的功能部分。位于tabby/crates目录下的为完全开源功能设置,位于tabby/ee下的为企业功能。(目前更新为如下)
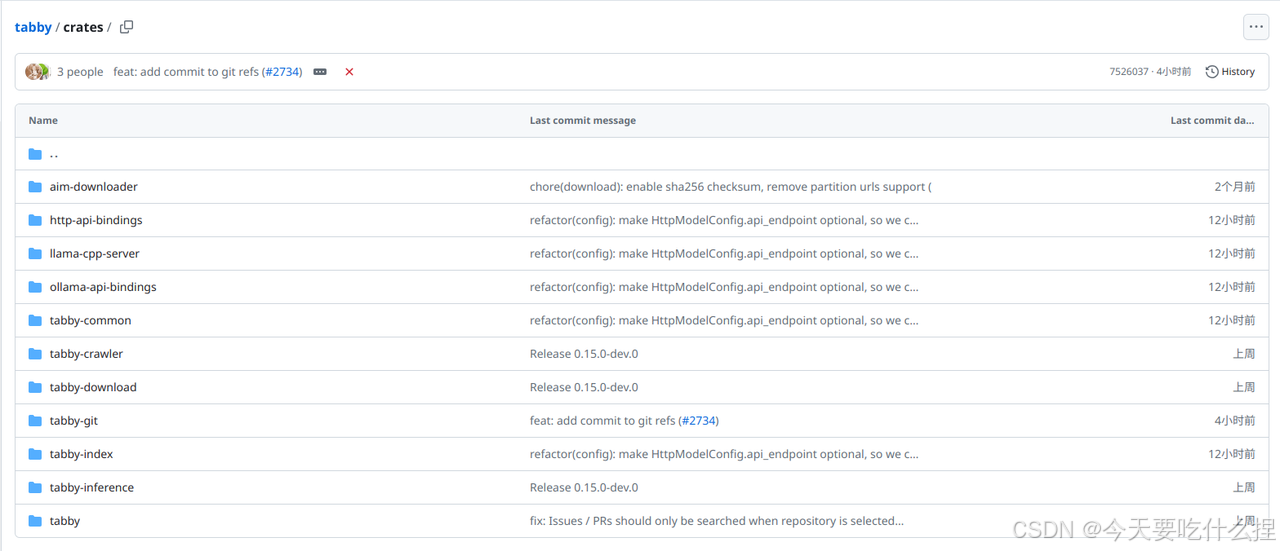
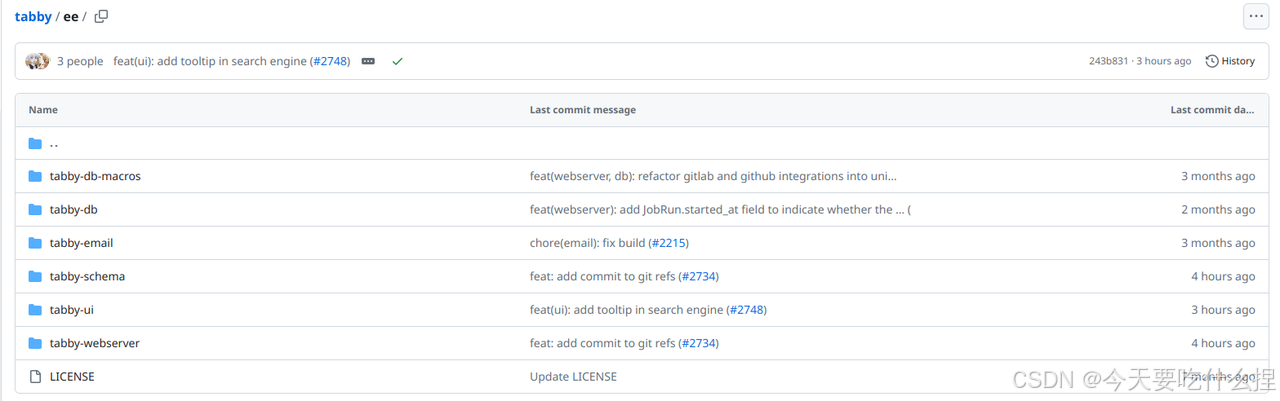
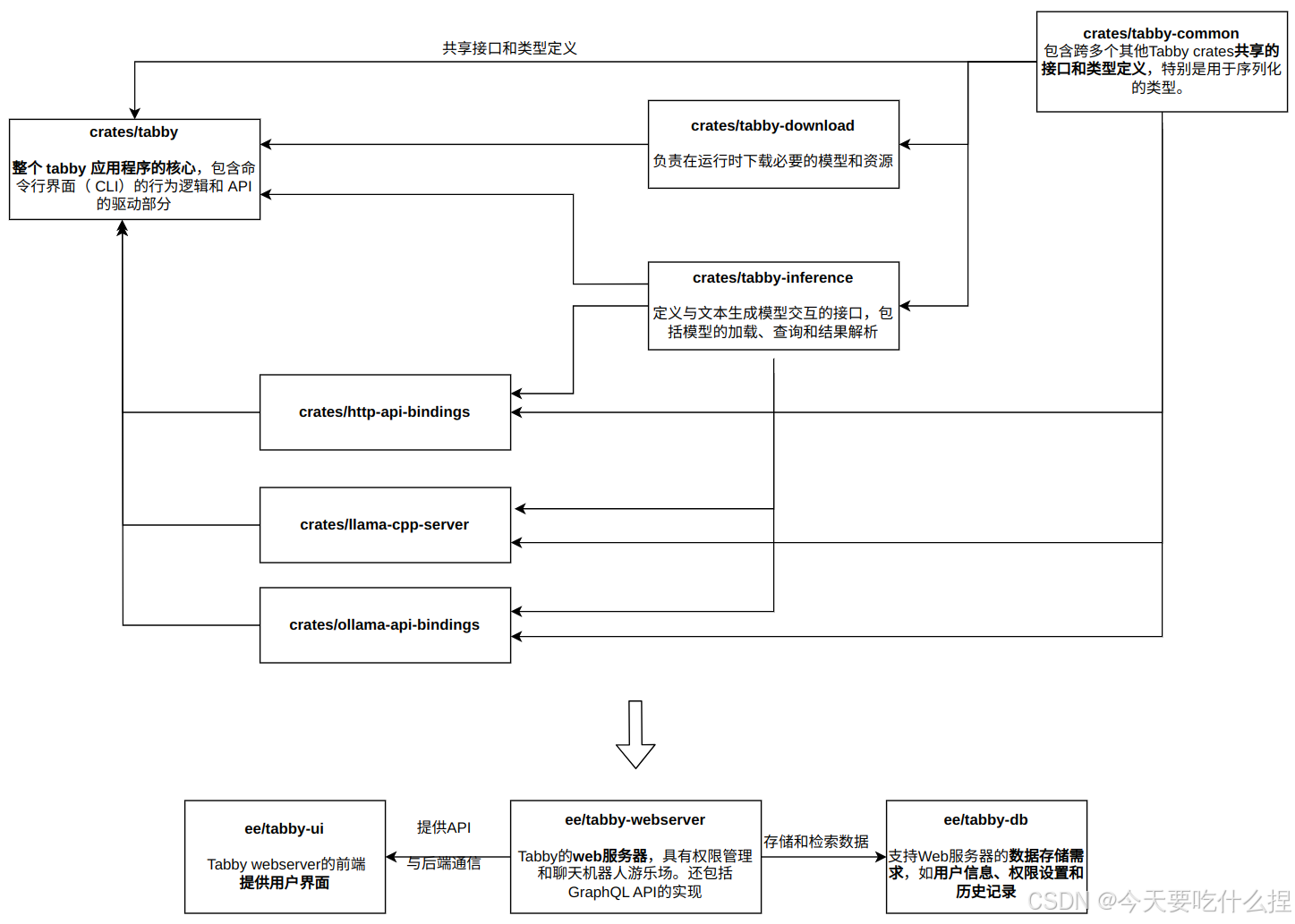
ps:数据序列化指将数据结构或对象状态转为可存储或传输的格式的过程。常为某种形式的字节流或字符序列
上面的模块通过依赖注入、消息传递、API调用等方式相互协作。
LLaMA和Ollama:
LLaMA是开源大语言模型。llama.cpp 项目用 C/C++ 重写了推理代码,既避免了 PyTorch 引入的复杂依赖,又提供了更为广泛的硬件支持,包括纯 CPU 推理、Apple Silicon 在内的各类底层计算架构都得以充分发挥对应的推理加速。
Ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型,降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Llama 3、Phi 3、Mistral、Gemma等开源的大型语言模型。
Ollama与Llama的关系:Llama是大语言模型,而Ollama是大语言模型(不限于Llama模型)便捷的管理和运维工具
Q:ee和crates的功能区别,和在整个项目中的关系?
A:
ee目录主要为企业用户提供额外的功能和优化,如特权管理、聊天机器人游戏场和更高级的服务。
crates则包含了项目的核心功能和特性,这些模块对所有用户开放,并构成了Tabby项目的基础。
ee目录下的模块如 ee/tabby-webserver 和 ee/tabby-db 都引用了crates目录下的模块,如tabby-common、tabby-index、tabby-inference等,这些模块为ee目录下的模块提供了基本的功能和定义。
项目中代码结构体风格写法:
pub struct 和 impl 的关系:
pub struct :定义结构体的公共接口,即结构体的字段和类型。(数据的 "形状")
impl 块:提供结构体的行为,即定义方法来操作结构体的字段。(数据的 "行为")
这种分离使得结构体的定义更加清晰,并且可以针对同一个结构体有不同的行为实现。
2、clients目录
tabby -agent是用于与Tabby服务器通信的代理。它基于 Node.js v18,作为语言服务器运行。
该目录下是tabby-agent的源码,并对于想要手动设置 tabby-agent 作为语言服务器的用户提供指南。
注意:对于 VSCode、IntelliJ Platform IDE 和 Vim/NeoVim,建议使用 Tabby 提供的扩展,其底层运行 Tabby Agent。
项目庞大,下方介绍核心部分(以代码补全功能为核心介绍)
四、crates/tabby/src
crates/tabby/src目录:
services目录下定义其相关功能,routes目录下定义处理相关功能路由操作。
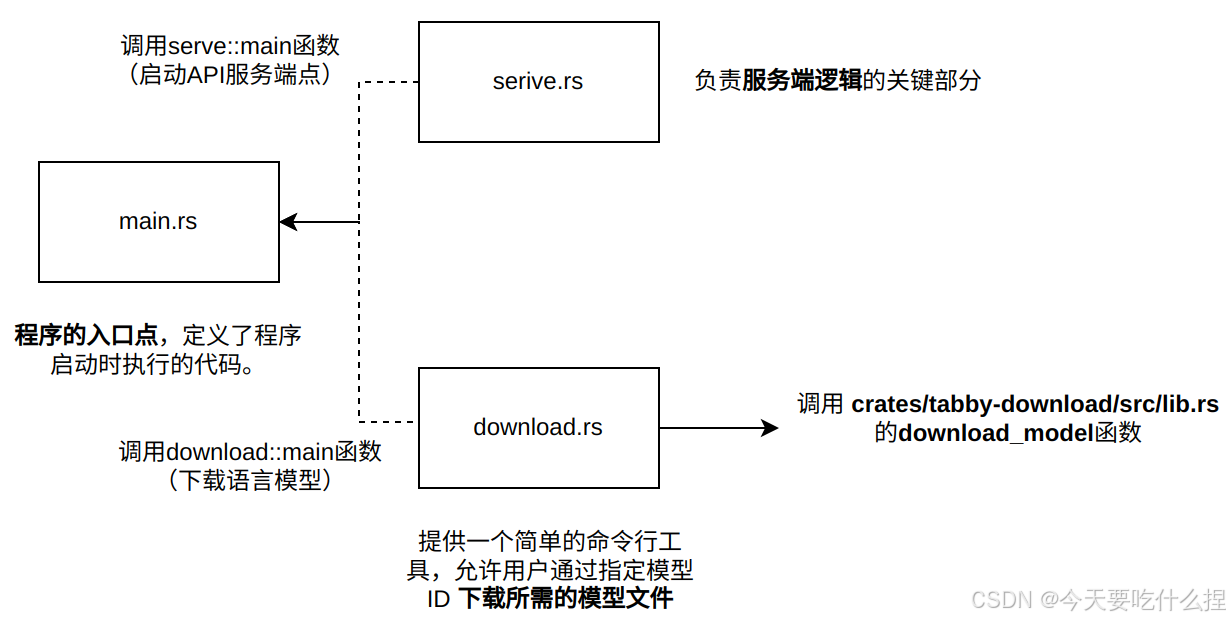
1、mian.rs
-
负责处理命令行参数、配置加载、日志记录和启动应用程序的主要功能。
-
核心:
在main函数中解析命令行参数,执行相应逻辑,启动服务或下载模型。
match cli.command {
Commands::Serve(ref args) => serve::main(&config, args).await,
Commands::Download(ref args) => download::main(args).await,
}CodeGeneration模块
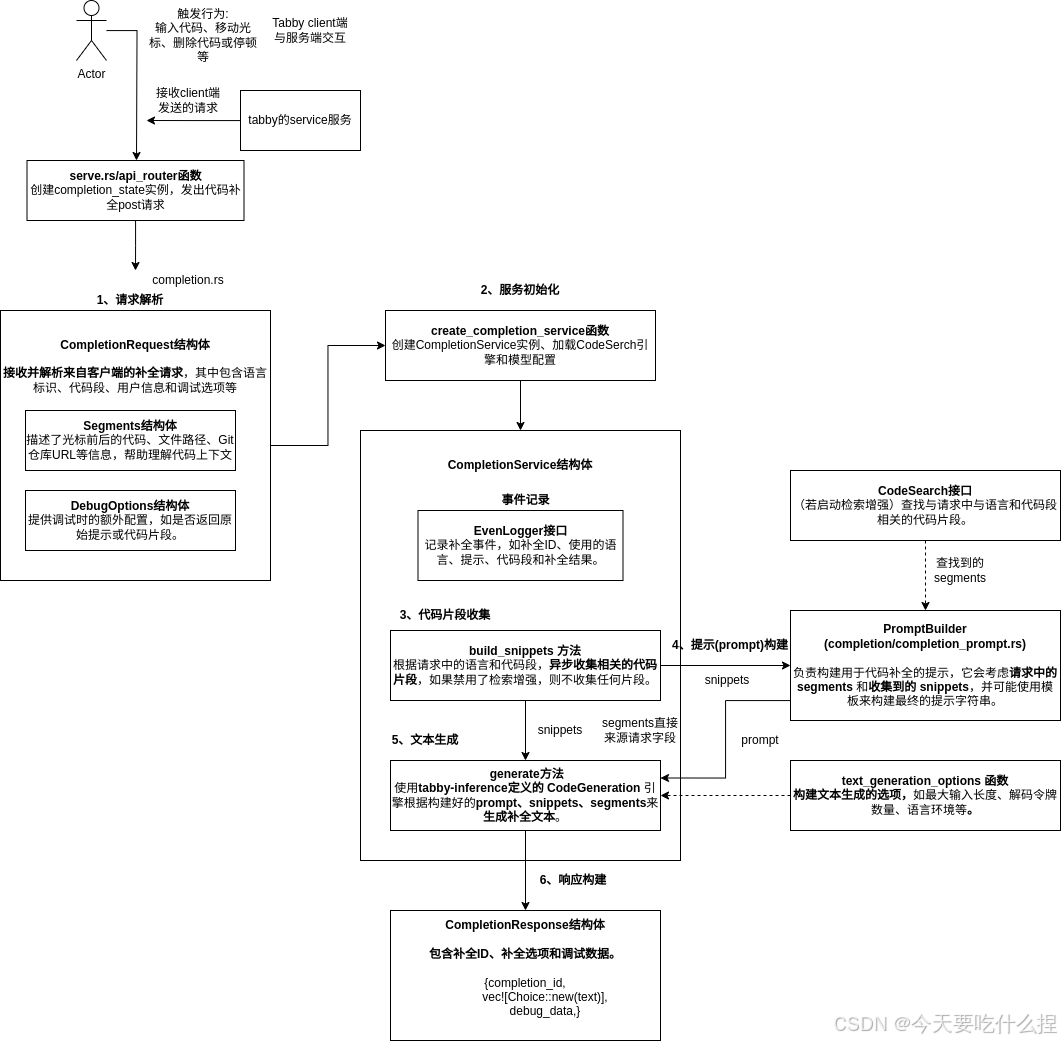
2、serve.rs
-
负责服务端逻辑的关键部分,它定义了 API 的结构、处理程序的路由以及服务器的启动和配置。
-
serve提供了一系列端点来处理不同类型的请求,例如记录事件、健康检查、代码补全、聊天补全和答案生成。
-
代码中还集成 Swagger UI 以提供 API 文档的 Web 界面。
触发流程:

2.1、定义本地crate模块
包括路由定义 (routes)、应用程序运行 (run_app)、服务定义 (services) 等。服务定义包括代码搜索、补全服务、事件日志、健康检查等。
use crate::{
routes::{self, run_app},
services::{
self, answer,
code::create_code_search,
completion::{self, create_completion_service},//代码补全
embedding,
event::create_event_logger,
health,
model::{self, download_model_if_needed},
tantivy::IndexReaderProvider,
},
to_local_config, Device,
};2.2、main 函数
是启动Tabby服务器的入口点,接收配置和命令行参数,加载模型,然后启动服务器。
//合并配置,加载模型,日志记录
let config = merge_args(config, args);
load_model(&config).await;
debug!("Starting server, this might take a few minutes...");
......
//创建嵌入服务,用于生成或处理嵌入向量。
let embedding = embedding::create(&config.model.embedding).await;
//创建事件日志记录器和配置访问对象
let mut logger: Arc<dyn EventLogger> = Arc::new(create_event_logger());
let mut config_access: Arc<dyn ConfigAccess> = Arc::new(StaticConfigAccess);
//创建 API 路由
let mut api = api_router(args, &config, logger.clone(), code, embedding, index_reader_provider, webserver).await;
//设置 Swagger UI 路由,提供 API 文档的 Web 界面。
let mut ui = Router::new()
.merge(SwaggerUi::new("/swagger-ui").url("/api-docs/openapi.json", ApiDoc::openapi()))
.fallback(|| async { axum::response::Redirect::temporary("/swagger-ui") });
//启动心跳检测
start_heartbeat(args, &config, webserver);
//运行应用程序,启动 axum web 服务器,监听传入的 HTTP 请求,并根据设置的路由分发这些请求到相应的处理函数。
run_app(api, Some(ui), args.host, args.port).await2.3、api_router函数
创建 API 路由,将请求分发到不同的处理函数。通过completion_state来触发代码补全功能,生成CompletionRequest请求(services/completion.rs)。
......
//创建代码补全服务
let completion_state = if let Some(completion) = &model.completion {
Some(Arc::new(
create_completion_service(code.clone(), logger.clone(), completion).await,
))
} else {
None
};
......
//设置代码补全路由:如果代码补全服务已创建,则设置一个路由来处理 /v1/completions 路径的 POST 请求。
//使用 completion_state 服务来处理请求
if let Some(completion_state) = completion_state {
routers.push({
Router::new()
.route(
"/v1/completions",//api_router 函数通过设置 /v1/completions 路由来允许客户端请求代码补全服务。
routing::post(routes::completions).with_state(completion_state),
)
//并应用了一个超时层以避免请求处理过久。
.layer(TimeoutLayer::new(Duration::from_secs(
config.server.completion_timeout,
)))
});
} else {//如果没有代码补全模型,则返回 NOT_IMPLEMENTED 状态码。
routers.push({
Router::new().route(
"/v1/completions",
routing::post(StatusCode::NOT_IMPLEMENTED),
)
})
}
......
// 合并路由:创建一个根 Router,并将所有单独的路由合并到这个根路由器中。这样,axum 就可以使用这个根路由器来分发进入的请求。
let mut root = Router::new();
for router in routers {
root = root.merge(router);
}
// 返回路由器:函数返回配置好的根路由器,它将被用作 axum 服务器的核心来处理 HTTP 请求。
root测试模块:通过模拟和单元测试确保服务的逻辑性和可靠性
3、services 目录
这个目录包含业服务逻辑模块的实现,这些服务是应用程序的核心功能,处理具体的业务逻辑。
|
模块 |
作用 |
|---|---|
|
completion.rs |
包含与代码补全服务相关的代码,提供自动完成代码片段的功能 |
|
completion |
目录下包含提示prompt构建的逻辑 |
|
code.rs |
定义用于代码搜索功能 |
|
doc |
包含文档搜索服务的代码,用于在文档中搜索特定的内容或模式。 |
|
model |
包含与模型配置和管理相关的代码,涉及到加载和初始化不同的模型配置 |
|
answer.rs |
包含与生成答案或响应(例如,对用户查询的响应)相关的逻辑 |
|
embedding.rs |
包含与嵌入向量相关的代码,嵌入向量常用于机器学习任务,如语义搜索或代码推荐。 |
|
event.rs |
包含与事件日志记录相关的代码,用于记录应用程序内发生的事件。 |
|
health.rs |
包含健康检查服务的代码,用于监控服务状态和性能指标。 |
|
mod.rs |
包含 services 目录的公共模块定义或配置 |
|
tantivy.rs |
Tantivy 是一个全文搜索库,这个文件可能包含使用 Tantivy 构建搜索索引和执行搜索查询的代码。 |
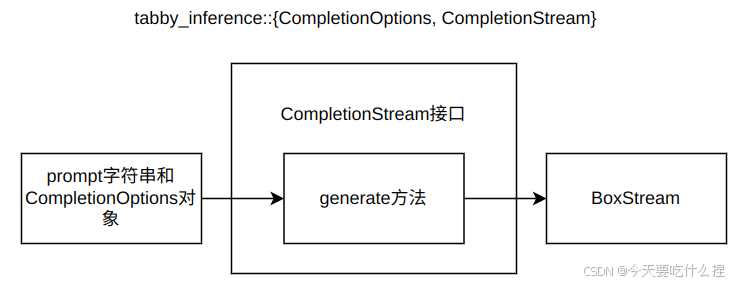
3.1、completion.rs和completion_prompt.rs
二者定义了 Tabby 项目中代码补全服务的核心组件和逻辑。
-
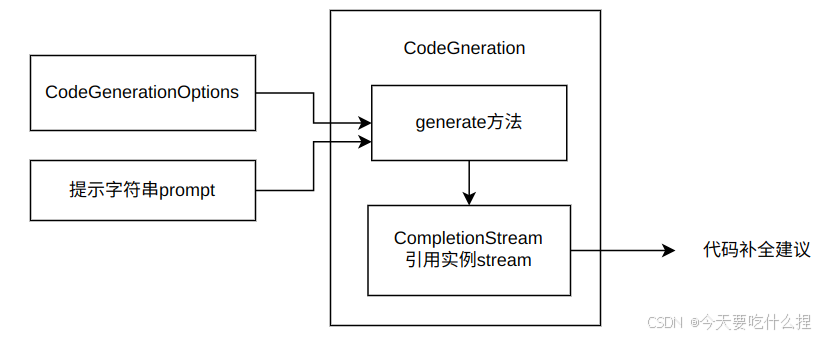
PromptBuilder 结构体(completion_prompt.rs):构建用于代码补全的提示字符串,这个提示字符串随后会被传递给代码生成引擎以产生补全建议。
-
作为CompletionService 结构体的成员变量引入completion.rs
pub struct CompletionService {
engine: Arc<CodeGeneration>, // 代码生成引擎
logger: Arc<dyn EventLogger>, // 日志记录器
prompt_builder: completion_prompt::PromptBuilder, // 提示构建器
}completion.rs 与其他各模块的引用关系
//引入completion文件夹中的completion_prompt.rs
mod completion_prompt;
use std::sync::Arc;
//引入了多个依赖,包括序列化/反序列化库 serde,错误处理库 thiserror,以及用于生成 API 文档的 utoipa。
use serde::{Deserialize, Serialize};
use tabby_common::{
api::{
self,
code::CodeSearch,
event::{Event, EventLogger},
},
config::ModelConfig,
languages::get_language,
};
use tabby_inference::{CodeGeneration, CodeGenerationOptions, CodeGenerationOptionsBuilder};
use thiserror::Error;
use utoipa::ToSchema;
use super::model;明确几个名词概念:
-
prompt(提示):是模型代码补全算法的输入,引导模型输出。
-
segments(段落):代码上下文段落信息,帮助解析器更好解析理解代码结构。
-
snippets(代码片段):预定义的代码块,可以被插入或用作训练补全模型的数据。
-
choice(选择):其中的text是代码补全的建议代码文本。
3.2、code.rs
实现了一个用于代码搜索的功能。它使用了Tantivy搜索引擎库来索引和搜索代码库。代码搜索功能支持根据查询语句和语言进行代码片段搜索,并结合了两种不同的搜索算法:基于embedding的搜索和基于BM25的搜索。搜索结果会根据排名和分数进行合并和过滤,最终返回最相关的代码片段。

4、routes 目录
包含定义不同 API 路由的代码。在 Web 应用或服务中,路由定义了如何处理不同类型的请求。
4.1、completions.rs
处理HTTP POST请求,请求体类型为CompletionRequest,响应体的类型是CompletionResponse。
#[instrument(skip(state, request))]
pub async fn completions(
State(state): State<Arc<CompletionService>>,
TypedHeader(MaybeUser(user)): TypedHeader<MaybeUser>,
Json(mut request): Json<CompletionRequest>,
) -> Result<Json<CompletionResponse>, StatusCode> {
if let Some(user) = user {
request.user.replace(user);
}
match state.generate(&request).await {
Ok(resp) => Ok(Json(resp)),
Err(err) => {
warn!("{}", err);
Err(StatusCode::BAD_REQUEST)
}
}
}五、crates/tabby-common/src
1、config.rs
定义和配置相关的数据结构和函数。配置文件Config、模型配置ModelConfig和相关结构体,load函数。
2、api目录
包含与api相关的代码
2.1、api/code.rs
实现代码搜索功能,上文的代码搜索就是使用这个实现。
六、crates/tabby-inference/src
1、decoding.rs
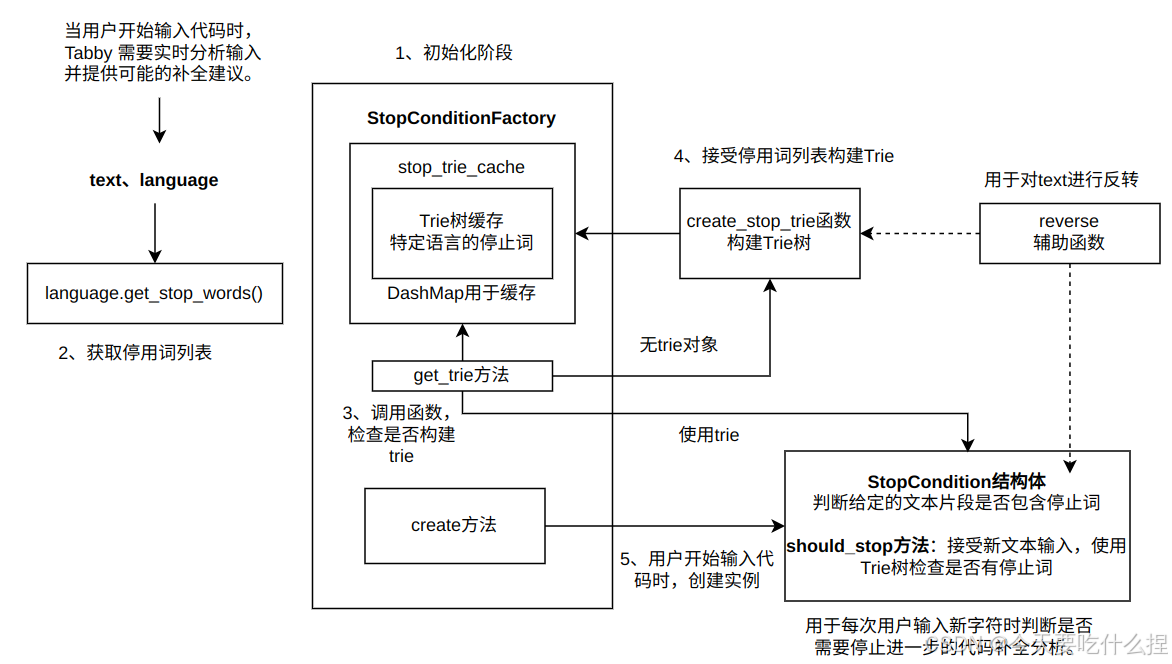
在tabby/src/main.rs中引用。在代码补全过程中提供了一种快速判断何时停止分析的方法,从而提高了补全效率。
2、completion.rs
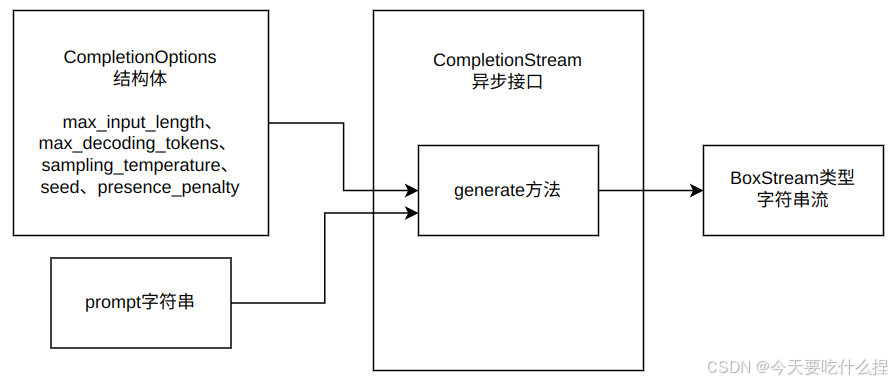
3、code.rs
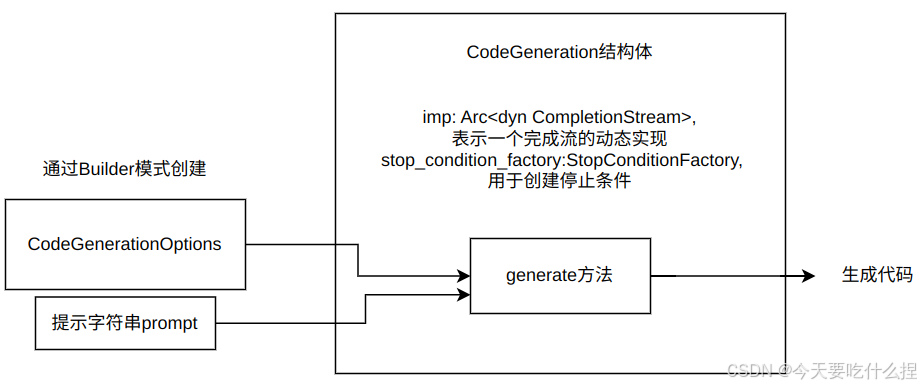
Q:
tabby-common/src/api/code.rs和tabby/src/services/code.rs的区别是什么?A:
tabby-common/src/api/code.rs
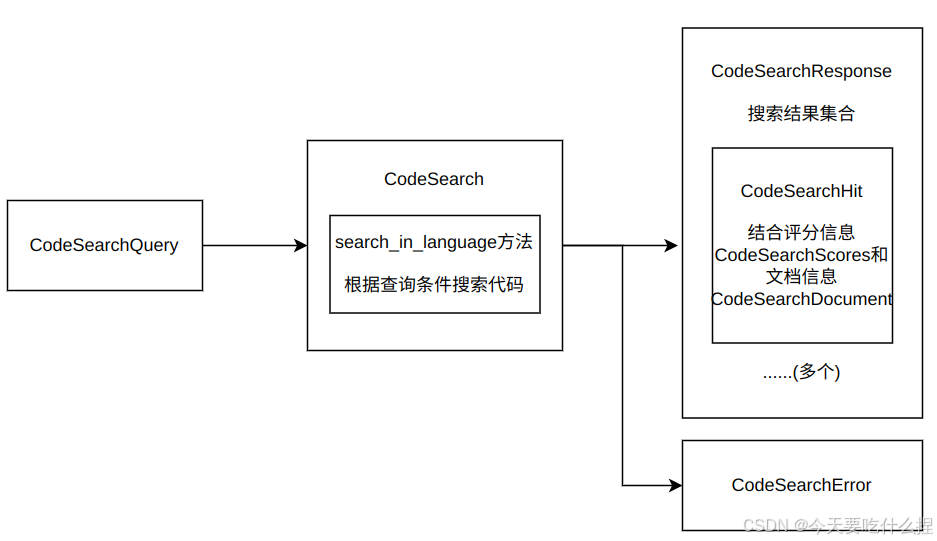
定义了一个CodeSearch trait,它是异步代码搜索接口的抽象,规定了进行代码搜索的方法签名。
任何实现此trait的对象都将提供search_in_language方法,该方法接受一个CodeSearchQuery和一个结果限制参数,返回一个CodeSearchResponse或者CodeSearchError。
tabby/src/services/code.rs
包含了CodeSearch trait的具体实现。
CodeSearchImpl 结构体: 包含了实际的搜索逻辑,包括使用Tantivy全文搜索引擎、embedding模型、以及缓存机制。
CodeSearchService结构体:将CodeSearchImpl与IndexReaderProvider结合起来,提供了一个可以被外部调用的CodeSearch服务实例。
总结:tabby-common提供了抽象接口和类型定义,而tabby/src/services则提供了具体的业务逻辑实现。两者紧密协作,共同构建了完整的代码搜索和补全等功能。
五、如何阅读项目源码
1、先跑起来
- 有的项目比较复杂,依赖的组件多,搭建起一个调试环境并不容易,所以不是所有项目都能顺利的跑起来。
- 跑起来后,尽量的精简自己的环境,减少调试过程中的干扰信息。
2、明确自己的目的
是需要了解其中一个模块的实现,还是需要了解这个框架的大体结构,还是需要具体熟悉其中的一个算法的实现,等等。
e.g:Nginx:了解核心的基础流程以及数据结构,了解如何实现一个模块,有了这些对这个项目大体的了解,剩下的就是遇到具体的问题查看具体的代码实现了。
3、区分主线和支线剧情
抓大放小。对于支线剧情的代码,比如一个不需要了解其实现的类,我们只需要了解其对外接口,了解这些接口的入口、出口参数以及作用,把实现部分当成一个“黑盒”即可。
4、纵向和横向
- 纵向:顺着代码的顺序阅读,在需要具体了解一个流程、算法的时候,经常需要纵向阅读。
- 横向:区分不同的模块进行阅读,在需要首先弄清楚整体框架时,经常需要横向阅读。
两个方向的阅读,应该交替进行。
建议:过程中还是以整体为首,在不理解整体的前提之前,不要太过深入某个细节。把某个函数、数据结构当成一个黑盒,知道它们的输入、输出就好,只要不影响整体的理解就暂且放下接着往前看。
5、情景分析和利用好测试用例
- 构造一些情景,然后通过加断点、调试语句等分析在这些场景下的行为。
- 测试用例往往是针对某个单一的场景,独自构造出一些数据来对程序的流程进行验证。
6、厘清核心数据结构之间的关系
- “程序设计=算法+数据结构”,对于算法,如果属于暂时不需要深究的细节部分,可以了解其入口、出口参数以及作用即可。
- 刚接手某个项目,需要简单的了解一下项目,可以先阅读代码了解都有哪些核心数据结构。理解了之后,如果不清楚某些情景下的流程,可以使用情景分析法。总而言之,交替进行直到解答疑问为止。
7、多问自己几个问题
- 为什么选择这个数据结构来描述这个问题?类似的场景下,其他项目是怎么设计的?都有哪些数据结构做这样的事情?
- 如果由我来设计这样的项目,我会怎么做?
- 结合上下文阅读代码中,可以自己做一些假设,然后在代码中寻找验证(福尔摩斯本斯 :D)。例如,如果一个应用有缓存策略,一个好问题就是:如果键无效了会怎样?缓存中的值如何更新? 带着这些问题阅读代码
8、多画图,写注释
多画图,一图胜千言,使用图形展示代码流程、数据结构之间的关系。
9、写代码阅读笔记
- 想象在向一个不太熟悉这个项目的人讲解原理,或者想象一下是几个月甚至几年后的自己回头来看这个文章。在这种情况下,会尽量的把语言组织好,循循善诱的解释。
- 尽量避免大段的贴代码。如果真要解释某段代码,可以使用伪代码或者缩减代码的方式。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 44
44 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)