UC伯克利最新!Real2Render2Real:超灵活可扩展机器人数据~
能否在不依赖动力学仿真或人类遥操作的情况下,通过计算方法规模化生成机器人视觉-动作数据?当R2R2R数据量达到1000条时,性能与人类数据相当(p>0.05,等效性检验):人类遥操作数据(50-150条)vs R2R2R生成数据(50-1000条):最大规模的数据集(约10万条)仍比LLM/VLM训练数据小100,000倍。:生成1000条数据仅需13-38分钟(人类收集150条需60-104分钟
点击下方卡片,关注“具身智能之心”公众号
作者丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
出发点与核心问题
机器人学习领域长期面临数据稀缺的挑战。当前主流的数据收集方式——人类遥操作(teleoperation)存在以下局限性:
-
成本高昂:依赖人工操作,单次演示耗时约1-2分钟
-
可扩展性差:最大规模的数据集(约10万条)仍比LLM/VLM训练数据小100,000倍
-
硬件依赖:需特定机器人实体,难以跨平台复用
传统解决方案如物理仿真存在固有缺陷:
-
动力学模型不精确(如能量不守恒)
-
复杂接触建模需人工调参
-
高保真资产创建耗时
核心科学问题:能否在不依赖动力学仿真或人类遥操作的情况下,通过计算方法规模化生成机器人视觉-动作数据?

方法创新:R2R2R技术框架
1)整体流程
R2R2R通过三阶段流程实现数据生成:
-
Real-to-Sim转换:
-
输入:智能手机拍摄的多视角物体扫描+单段人类演示视频
-
输出:带纹理的3D网格资产+6-DoF物体运动轨迹
-
数据增强:
-
-
物体初始位姿随机化
-
运动轨迹插值生成新变体
-
-
并行渲染:
-
-
使用IsaacLab引擎生成光真实感的机器人执行视频
-
输出RGB图像-动作对(兼容VLA模型)
2)关键技术突破
(1) 3D高斯泼溅重建(3DGS)
-
采用GARField算法实现物体/部件级语义分割
-
支持刚体和铰接物体(如抽屉、水龙头)
-
通过SuGaR方法转换为兼容渲染引擎的网格
(2) 轨迹多样性生成
-
空间归一化:将原始轨迹转换到规范空间
-
球面线性插值(Slerp):保持运动语义
-
采样启发式:避免目标位姿附近的无效初始化
(3) 无动力学假设的逆运动学
-
使用PyRoki求解器生成关节空间轨迹
-
关键假设:接触期间物体刚性跟随轨迹
-
避免模拟摩擦/变形等复杂物理现象
实验验证
1)实验设置
-
硬件平台:ABB YuMi双臂机器人(训练时未见过的形态)
-
对比基准:人类遥操作数据(50-150条)vs R2R2R生成数据(50-1000条)
-
评估任务:
-
-
单物体抓取(拾取玩具虎)
-
多物体交互(将杯子放在咖啡机上)
-
铰接物体操作(关闭水龙头/打开抽屉)
-
双手协调(双手抬起包裹)
-
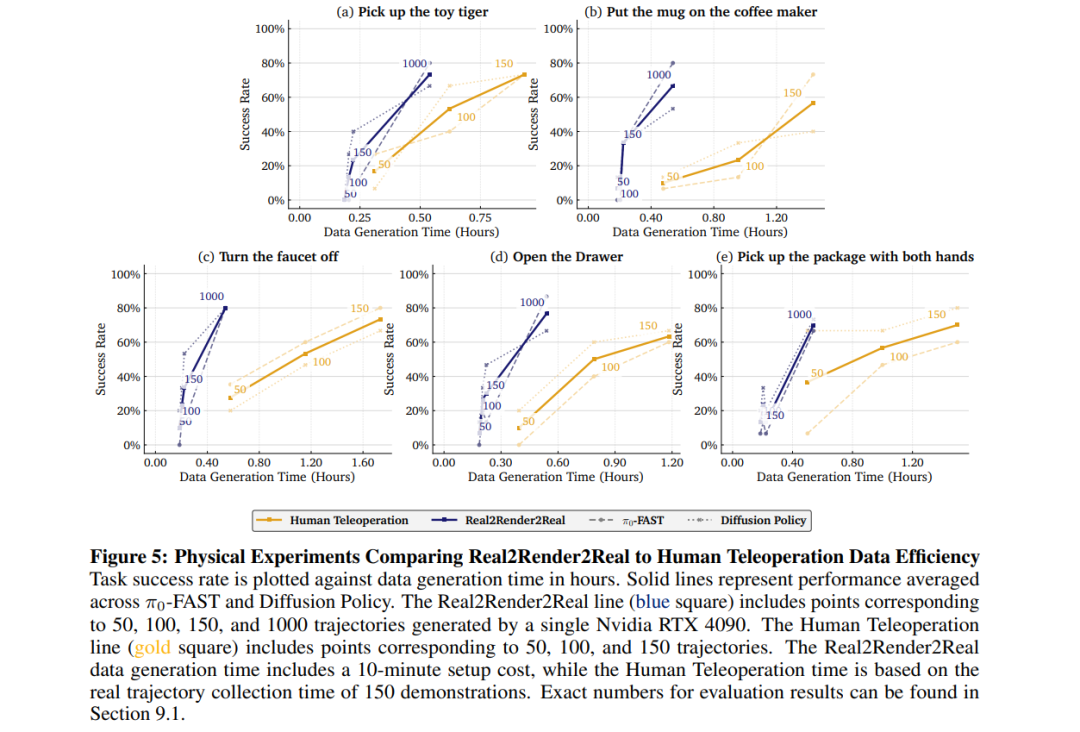
2)核心发现
(1) 数据效率对比
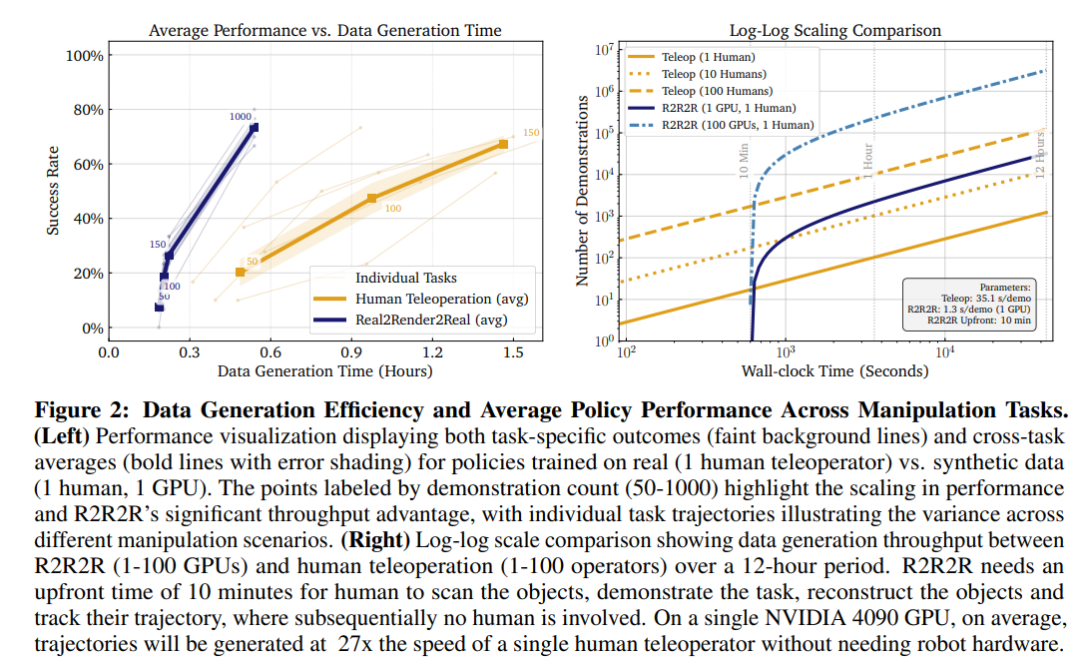
-
单GPU速度:51条/分钟(人类遥操作仅1.7条/分钟)
-
时间成本:生成1000条数据仅需13-38分钟(人类收集150条需60-104分钟)
(2) 策略性能分析
-
低数据量时(<150条),真实数据更具样本效率
-
当R2R2R数据量达到1000条时,性能与人类数据相当(p>0.05,等效性检验)
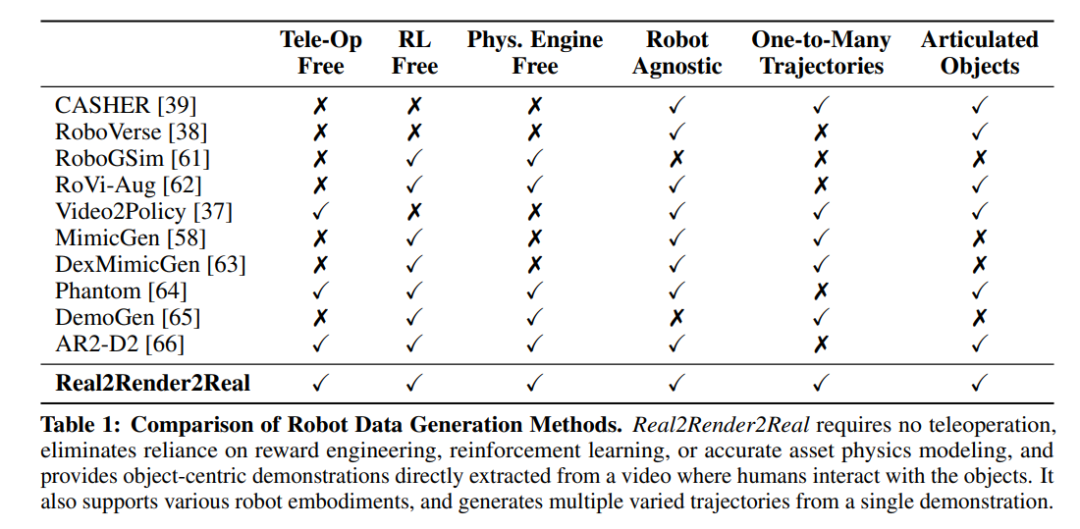
技术优势与局限性
1)创新价值
-
免仿真:完全规避物理引擎的建模误差
-
硬件无关:仅需智能手机采集的2D视频
-
轨迹多样性:单次演示可生成数百变体
-
跨形态兼容:支持不同机器人URDF模型
2)当前局限
限制维度
具体表现
改进方向
物理交互建模
无法模拟滑动/形变
集成增量势接触模型(IPC)
环境感知
缺乏碰撞检测
结合快速运动规划
操作类型
仅支持抓取式操作
扩展非抓取动作(推动/倾倒)
抓取泛化性
仅兼容平行夹爪
支持多指灵巧手
跟踪鲁棒性
易受反光/遮挡干扰
置信度感知滤波
参考
[1] Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware
文章首发于国内首个具身智能之心全栈技术平台,具身智能之心知识星球,欢迎扫码加入和近300家公司和高校交流!

-

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)