【分布式计算框架】 MapReduce编程初级实践
【分布式计算框架】 MapReduce编程初级实践
🕺作者: 主页
我的专栏 C语言从0到1 探秘C++ 数据结构从0到1 探秘Linux 😘欢迎 ❤️关注 👍点赞 🙌收藏 ✍️留言
文章目录
MapReduce编程初级实践
一、实验目的
- 编程WordCount
- 编程实现文件合并和去重操作
- 编程实现对输入文件的排序
二、实验环境
- centos 6.5
- VMware Workstation
三、实验内容
mapreduce高可用环境配置
伪分布式(单节点)修改配置:
(1) mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

(2) yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

复制目录D:\software\eclipce\workspace\Test20191909\src
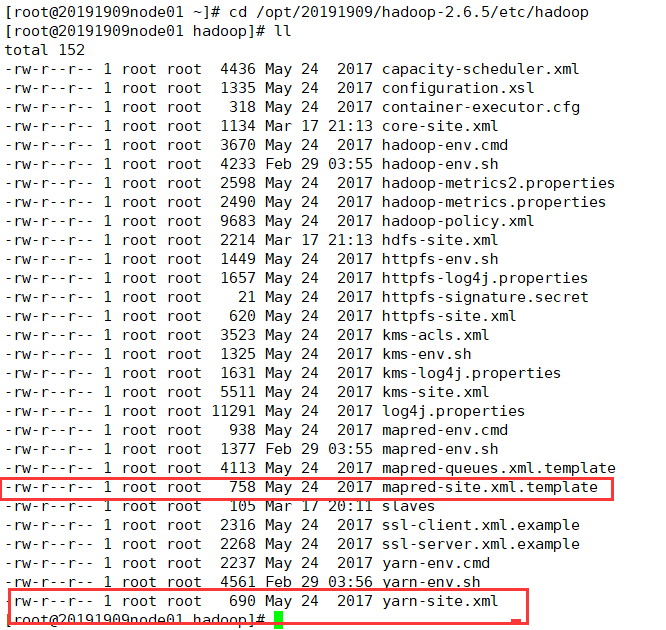
cd /opt/20191909/hadoop-2.6.5/etc/hadoop 进入配置文件的目录
ll 查看文件
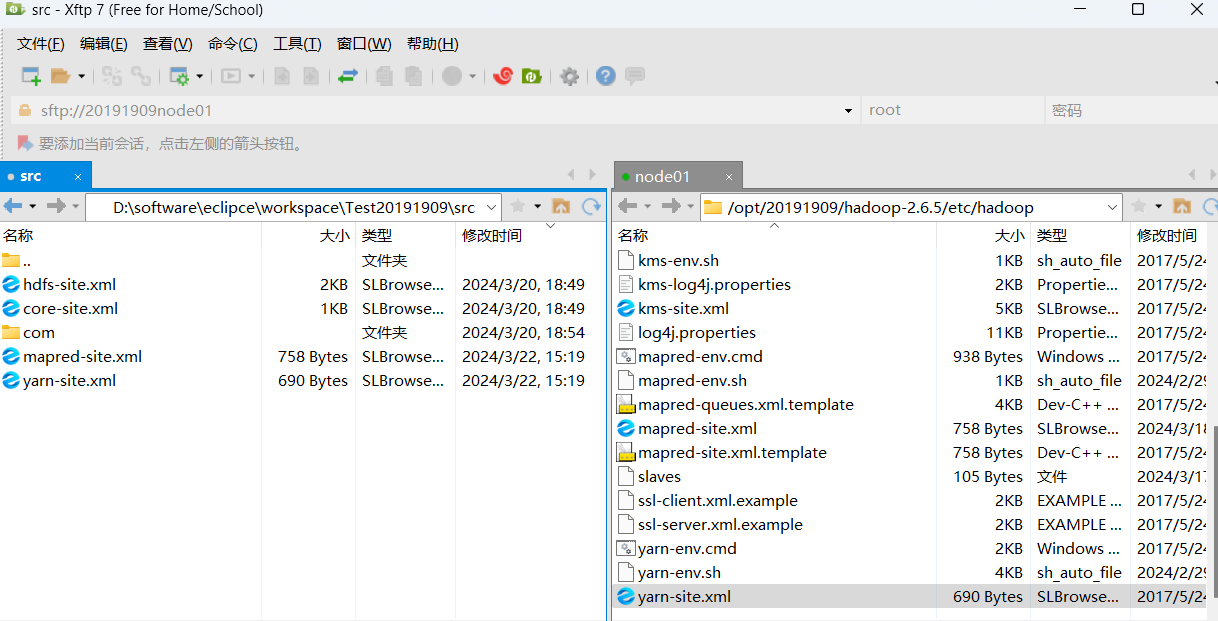
将yarn-site.xml和mapred-site.xml文件复制到D:\software\eclipce\workspace\Test20191909\src 下
新建一个类
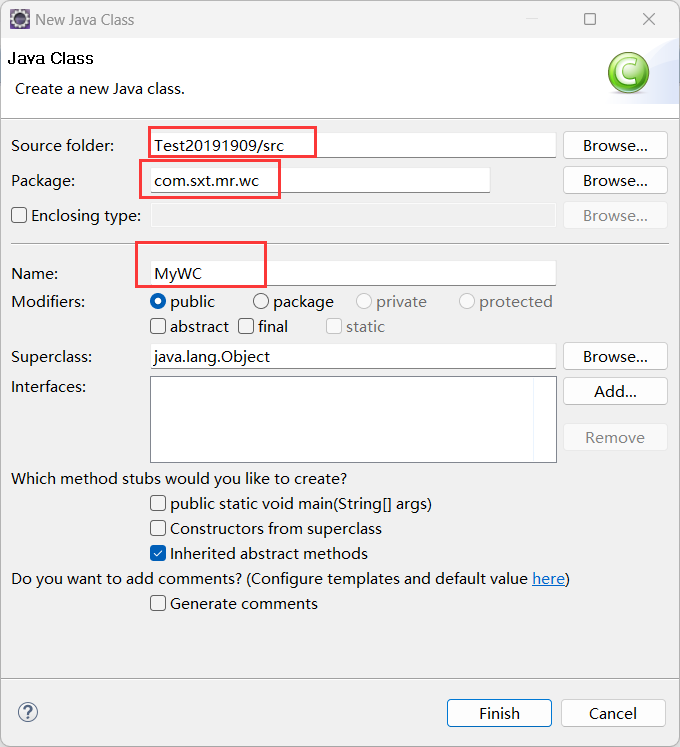
启动resourcemanager服务

编程WordCount
(1)创建一个新文件
for i in `seq 100000`;do echo "hello jxxy$i" >> test.txt;done
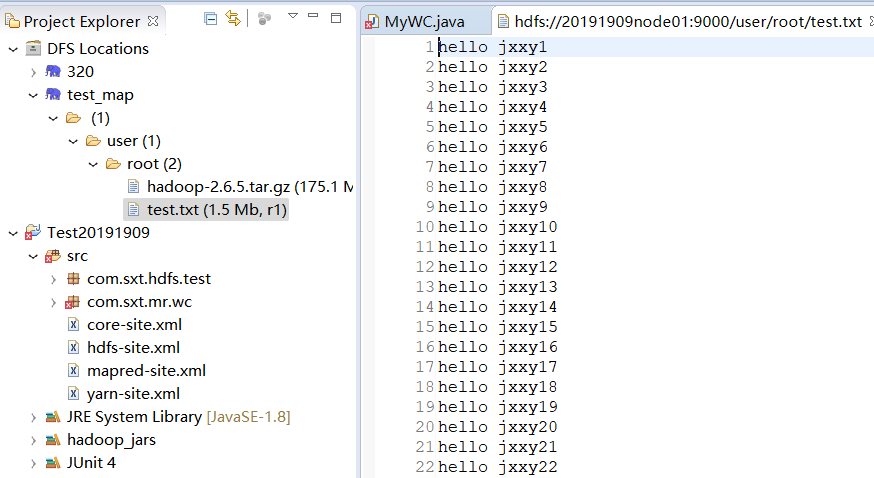
(2)编程MyWC主类,MyMapper类,MyReducer类,制作jar包
- MyWC主类
package com.sxt.mr.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyWC {
public static void main(String[] args){
Configuration conf=new Configuration();
try{
//创建一个新作业
Job job=Job.getInstance(conf);
job.setJarByClass(MyWC.class); //jar包
job.setJobName("myjob");
//job.setInputPath(new Path());
//job.setOutputPath(new Path());
Path inPath=new Path("/user/root/test.txt");
FileInputFormat.addInputPath(job,inPath);
//org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
Path outPath=new Path("/output/wordcount");
//如果输出路径存在,则先删除
if(outPath.getFileSystem(conf).exists(outPath))
outPath.getFileSystem(conf).delete(outPath,true);
FileOutputFormat.setOutputPath(job,outPath);
//org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//创建MyMapper,MyReducer两个类
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
//提交作业
job.waitForCompletion(true);
}
catch(Exception e){
}
}
}
- MyMapper类
package com.sxt.mr.wc;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<Object,Text,Text,IntWritable> {
private final static IntWritable one=new IntWritable(1);
private Text word=new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
StringTokenizer str=new StringTokenizer(value.toString());
while(str.hasMoreTokens()){
word.set(str.nextToken());
context.write(word,one);
}
}
}
- MyReducer类
package com.sxt.mr.wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
//迭代计算
private IntWritable result=new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{
int sum=0;
for(IntWritable val:values){
sum+=val.get();
}
result.set(sum);
context.write(key,result);
}
}
- 打成jar包
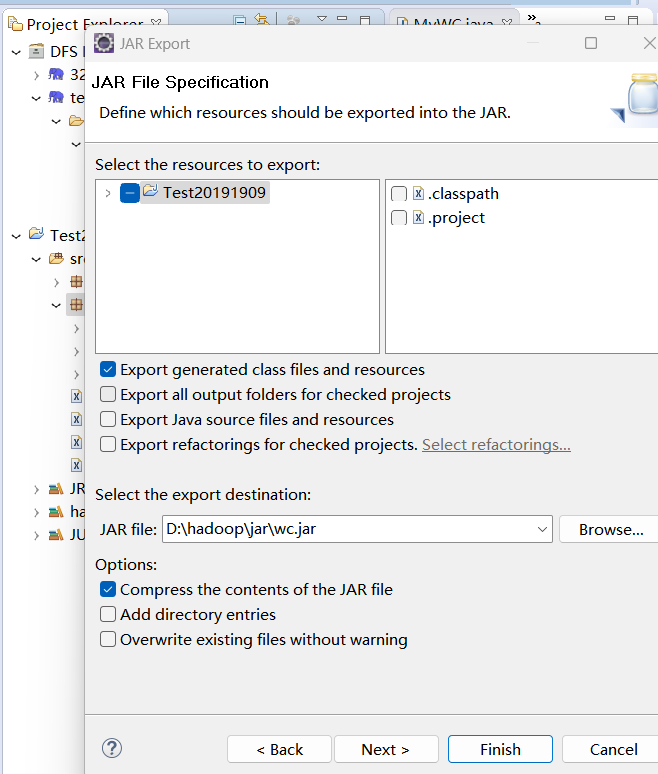
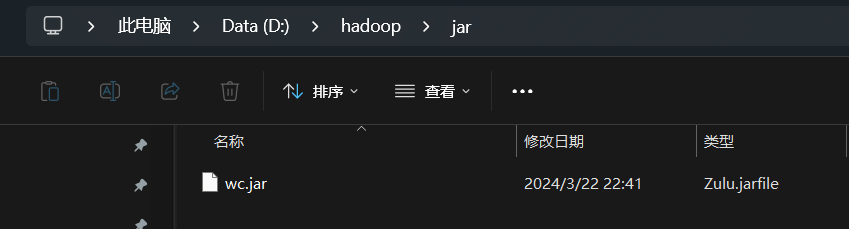
将jar包上传
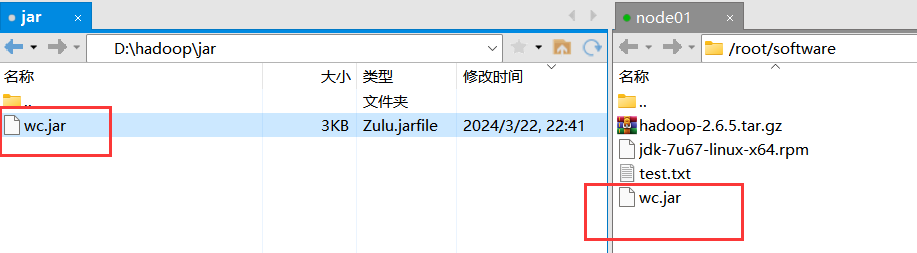
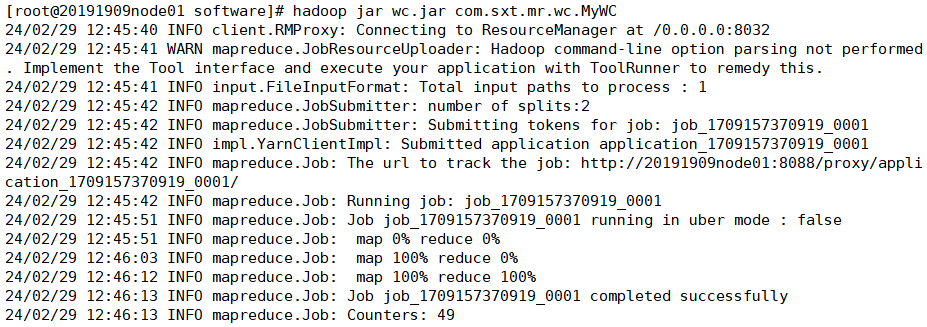
在集群上执行命令
hadoop jar wc.jar com.sxt.mr.wc.MyWC
(3)运行程序,统计test.txt文件hello和jxxy出现的次数
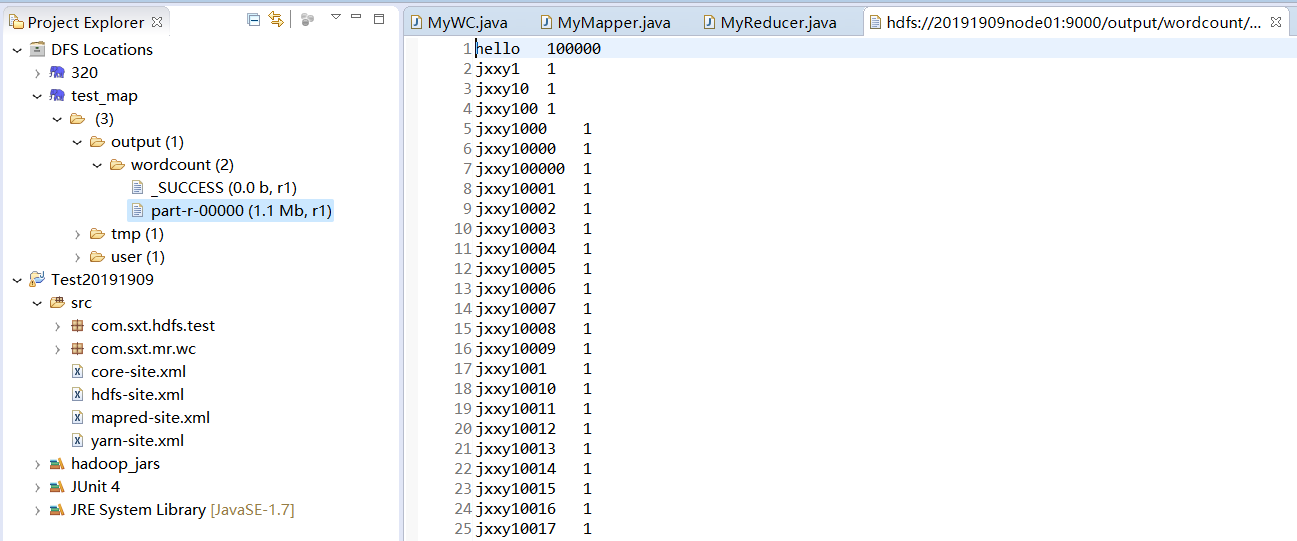
查看浏览器8088端口
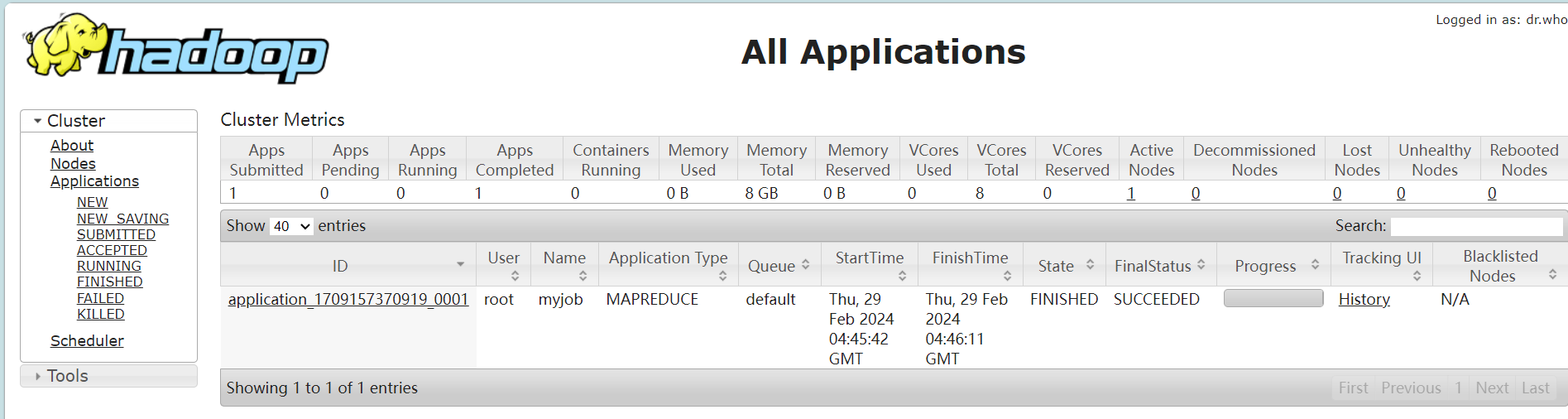
编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,编写程序对两个文件进行合并,并剔除其中重复的内容,
得到一个新的输出文件C。
样例如下:
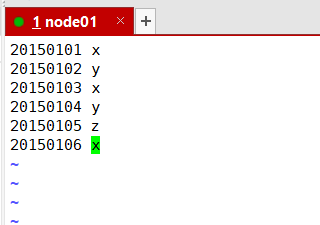
文件A
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
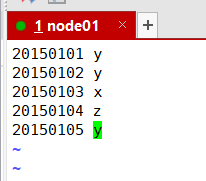
文件B
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
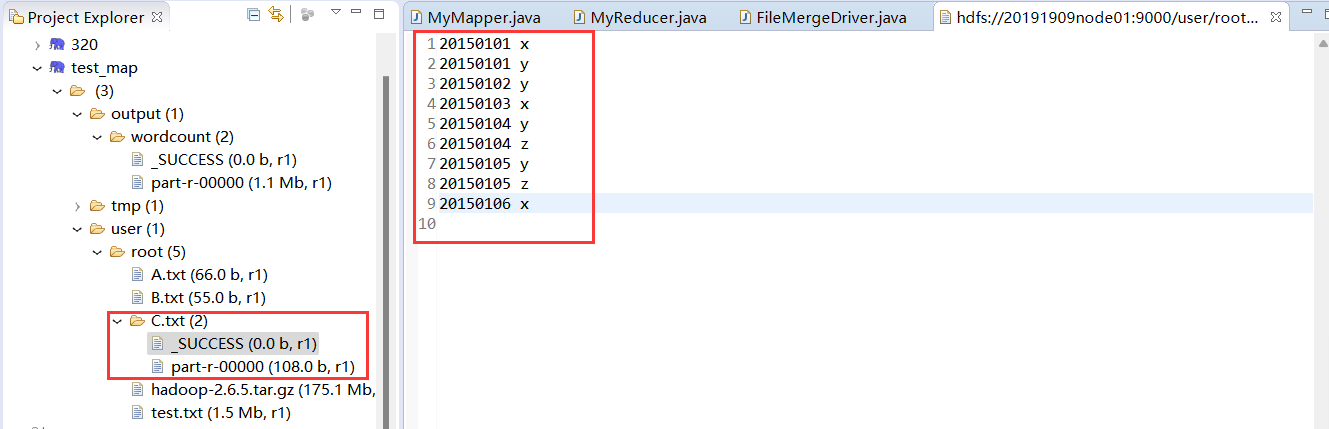
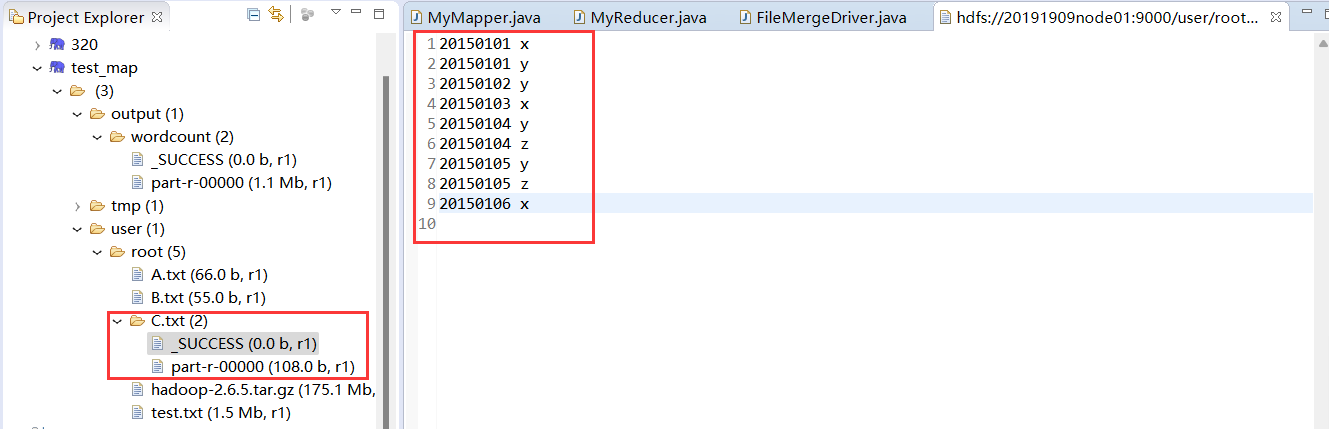
合并如下
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
代码如下
FileMergeDriver类
package com.sxt.file.test1;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FileMergeDriver extends Configured implements Tool {
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "FileMerge");
job.setJarByClass(FileMergeDriver.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new FileMergeDriver(), args);
System.exit(exitCode);
}
}
MyReducer类
package com.sxt.file.test1;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, Text, Text, Text> {
private final static Text nonDuplicate = new Text();
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
nonDuplicate.set(""); // 设置空值
context.write(key, nonDuplicate); // 将key写入输出,实现去重
}
}
MyMapper类
package com.sxt.file.test1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
private final static Text nonDuplicate = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
nonDuplicate.set(""); // 设置空值
context.write(value, nonDuplicate); // 将每行文本作为key输出
}
}
将jar包上传
准备测试数据
A.txt
B.txt
执行命令
hdfs dfs -put ./A.txt /user/root
hdfs dfs -put ./B.txt /user/root
hadoop jar test1.jar com.sxt.file.test1.FileMergeDriver /user/root/A.txt /user/root/B.txt /user/root/C.txt
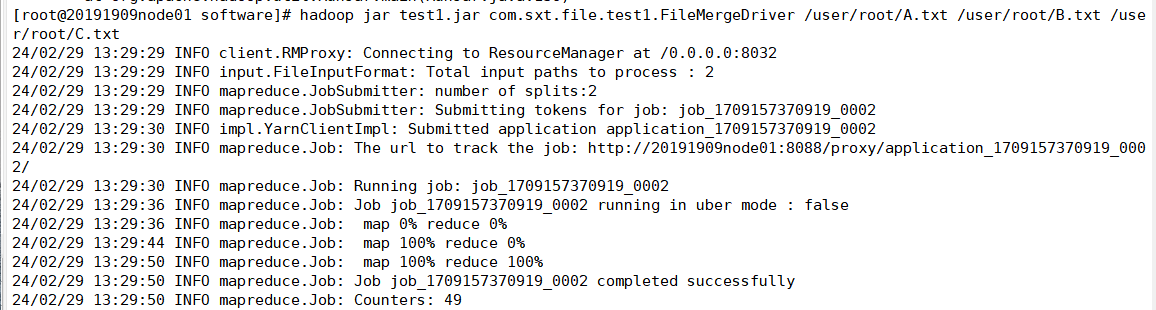
查看结果与样例一致实验成功
编程实现对输入文件的排序
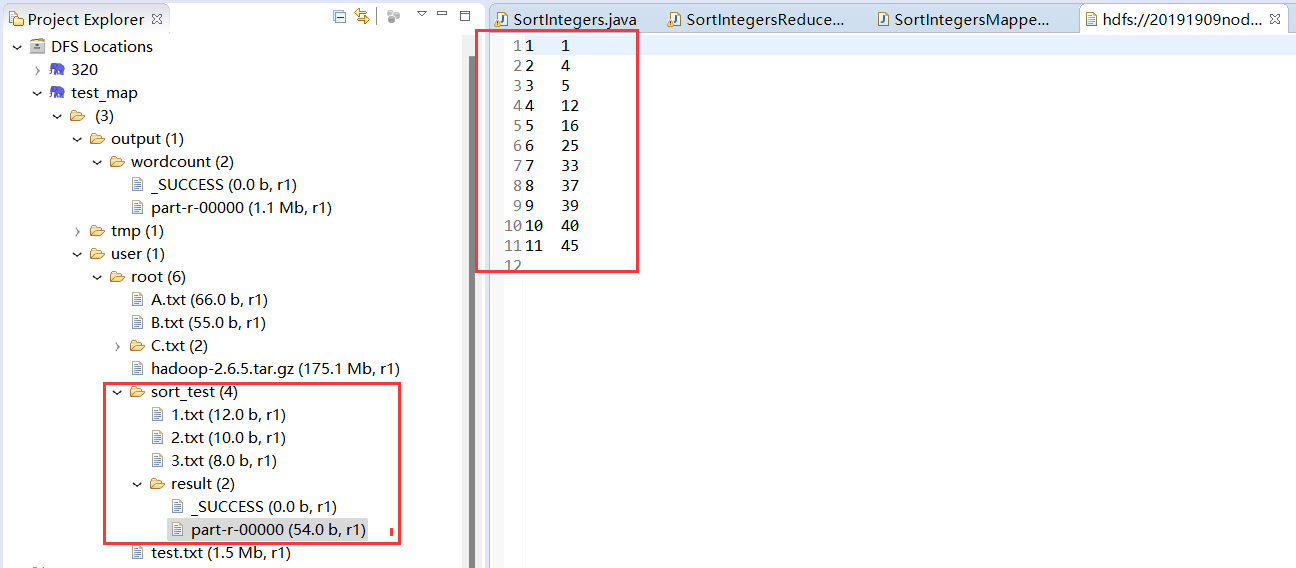
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的
文件中,输出的整数格式为每行两个整数,第一个整数位第二个整数的排序位次,第二个整数位原待排列的整数。
样例如下:
文件1
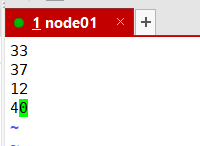
33
37
12
40
文件2
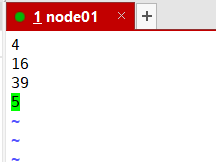
4
16
39
5
文件3
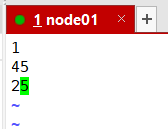
1
45
25
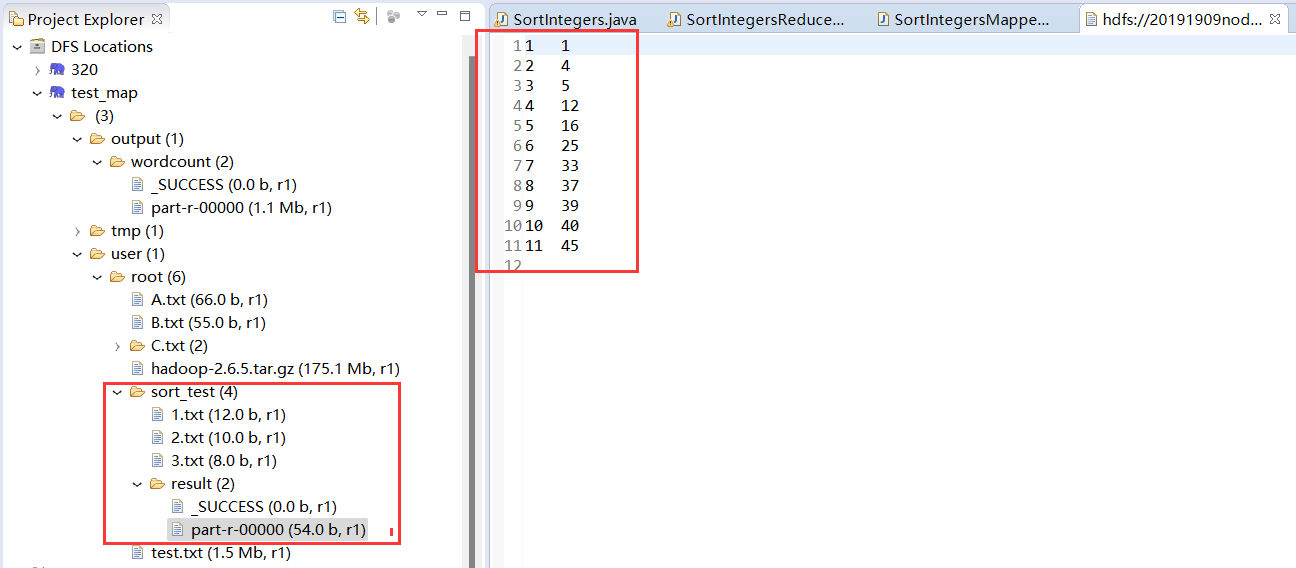
输出文件
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
代码如下
SortIntegers类
package com.sxt.file.test2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SortIntegers {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "sort integers job");
job.setJarByClass(SortIntegers.class);
job.setMapperClass(SortIntegersMapper.class);
job.setReducerClass(SortIntegersReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0])); // 输入文件路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 输出文件路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
SortIntegersReducer类
package com.sxt.file.test2;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class SortIntegersReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private IntWritable rank = new IntWritable(1);
private IntWritable number = new IntWritable();
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable val : values) {
number.set(key.get());
context.write(rank, number);
rank.set(rank.get() + 1);
}
}
}
SortIntegersMapper类
package com.sxt.file.test2;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SortIntegersMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable> {
private final static IntWritable lineNumber = new IntWritable(1);
private IntWritable number = new IntWritable();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
int num = Integer.parseInt(line.trim());
number.set(num);
context.write(number, lineNumber);
lineNumber.set(lineNumber.get() + 1);
}
}
打成jar包
上传jar包
创建测试文件
1.txt
2.txt
3.txt
将文件上传到HDFS
hadoop fs -mkdir /user/root/sort_test
hdfs dfs -put ./1.txt /user/root/sort_test
hdfs dfs -put ./2.txt /user/root/sort_test
hdfs dfs -put ./3.txt /user/root/sort_test
hadoop jar test2.jar com.sxt.file.test2.SortIntegers /user/root/sort_test /user/root/sort_test/result
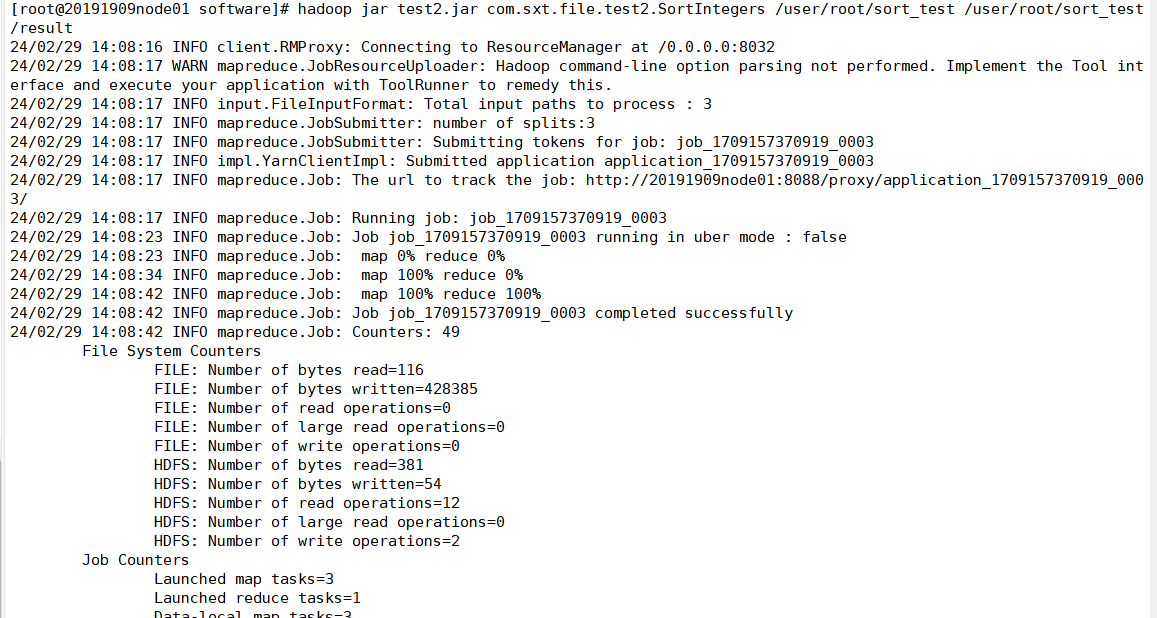
实验结果与样例一致,实验成功
四、出现的问题及解决方案
-
DFS Location拒绝连接

解决方案:
-
杀死所有java进程后开启集群
start-dfs.shstart-yarn.sh无效
-
新建一个Location,把端口号改为9000(这里是伪分布式的端口,之前没有修改,也是错误的原因)
解决
-
-
执行上传作业,版本不一致
解决方案
-
在 Eclipse 中选择要修改的项目,然后右键单击该项目,在弹出菜单中选择 “Properties”(属性)。
-
在弹出的对话框中,找到并展开 “Java Build Path”(Java 构建路径)选项。
-
在 “Java Build Path” 下,点击 “Libraries”(库),然后点击 “JRE System Library”。
-
点击 “Edit”(编辑)按钮,然后选择合适的 JRE(Java 运行时环境)版本。可以选择系统中已安装的 JRE 版本,也可以选择其他已配置的 JRE。
-
点击 “Finish”(完成)保存更改。
-
接下来,还需要修改项目的编译级别:
- 在项目属性对话框中,找到 “Java Compiler”(Java 编译器)选项。
- 确保选中 “Enable project specific settings”(启用项目特定设置)复选框。
- 在 “Compiler compliance level”(编译器兼容性级别)下拉菜单中选择你想要的 Java 版本。
- 点击 “Apply and Close”(应用并关闭)保存更改。
-
五、实验结果
运行程序,统计test.txt文件hello和jxxy出现的次数
运行程序,实现文件合并和去重操作
运行程序,实现对输入文件的排序
六、实验思考题
- 完全分布式配置哪些文件?
-
mapred-site.xml
-
yarn-site.xml
- 试述MapReduce的工作流程。
MapReduce是一种用于处理大规模数据集的并行计算编程模型。其工作流程包括以下几个步骤:
划分阶段(Input Split):
- 输入数据集被划分成若干个输入切片(input splits),每个输入切片会被一个Map任务处理。
映射阶段(Map Stage):
- 每个Map任务读取一个输入切片,并对其进行处理,生成中间键值对(key-value pairs)。
- 中间键值对由用户自定义的Map函数生成,这些键值对会被分区函数划分到不同的Reducer任务。
分区和排序阶段(Shuffle and Sort Stage):
- 中间键值对根据键进行排序,并按照分区函数的规则划分到不同的Reducer任务。
- 分区函数的作用是确保相同键的键值对会被发送到同一个Reducer任务。
归约阶段(Combine Stage,可选):
- 可选的归约(Combiner)函数可以在Map阶段后执行,用于局部聚合中间键值对,以减少数据传输量。
合并阶段(Reduce Stage):
- 每个Reduce任务接收来自Map任务输出的中间键值对,并按照键进行分组。
- Reduce任务对每个键的值列表执行用户定义的Reduce函数,生成最终的输出结果。
输出阶段(Output Stage):
最终的输出结果会被写入HDFS或其他存储系统,用于进一步的分析或处理。
输入数据集被划分成若干个输入切片(input splits),每个输入切片会被一个Map任务处理。
整个MapReduce过程涉及到数据的划分、映射、分区、排序、归约和合并等操作,通过并行化处理大规模数据集,实现高效的数据处理和分析。 MapReduce的工作流程简化了分布式计算任务的编写和执行,使得处理海量数据变得更加容易和高效。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)