Spring AI 入门之 嵌入模型和Redis向量数据库
与传统关系型数据库的精确匹配查询不同,向量数据库的查询操作执行的是相似性搜索。当给定一个向量作为查询时,向量数据库会返回与该查询向量"相似"的向量集合。通过计算两个文本对应向量之间的数值距离(例如余弦相似度),应用程序可以量化评估生成这两个嵌入向量的原始对象之间的相似程度。嵌入模型将文本转成向量之后,要保存到向量数据库中才方便使用,下面将使用Redis作为向量数据库做一个简单的demo。至此,在S
嵌入模型
嵌入(Embeddings) 是对文本、图像或视频的数值化表示,能够捕捉输入内容之间的关联关系。其工作原理是将文本、图像和视频转化为由浮点数构成的数组,即向量(vectors) 。这些向量旨在捕捉原始内容的语义信息,而嵌入数组的长度被称为向量的维度。通过计算两个文本对应向量之间的数值距离(例如余弦相似度),应用程序可以量化评估生成这两个嵌入向量的原始对象之间的相似程度。
为了与AI和机器学习中的各类嵌入模型实现无缝对接,Spring AI 提供了EmbeddingModel接口。它的核心功能是将文本转换为数值向量。
话不多说,上代码。
引入依赖
版本信息: Springboot 3.4.5 、spring ai 1.0.0-M7。 模型依赖依然使用openai的。
xml
体验AI代码助手
代码解读
复制代码
<properties> <java.version>17</java.version> <spring-ai.version>1.0.0-M7</spring-ai.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-openai</artifactId> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>${spring-ai.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
配置文件
具体的模型使用的是bge-m3,它是一个多功能、多语言、多粒度的文本嵌入模型。它支持三种常见的检索功能:密集检索、多向量检索和稀疏检索。该模型可以处理超过100种语言,并且能够处理从短句到长达8192个词元的长文档等不同粒度的输入。
yaml
体验AI代码助手
代码解读
复制代码
# 内嵌模型 spring.ai.openai.embedding.base-url=https://api.siliconflow.cn spring.ai.openai.embedding.api-key=sk-你的秘钥 spring.ai.openai.embedding.options.model=BAAI/bge-m3 # 向量编码格式, base64 或者float类型 spring.ai.openai.embedding.options.encodingFormat=float
测试
写一个Controller 做个简单测试。
java
体验AI代码助手
代码解读
复制代码
@RestController @RequestMapping("/embedding") public class EmbeddingModelController { @Autowired private EmbeddingModel embeddingModel; @GetMapping("/ai/embedForResponse") public Map embedForResponse(@RequestParam(value = "message") String message) { EmbeddingResponse embeddingResponse = embeddingModel.embedForResponse(List.of(message)); return Map.of("embedding", embeddingResponse); } }
调用接口:
由于返回的json太长了,删除了一部分,从结果中可以看到输入的参数总共124个token,output 节点中是把参数向量化的结果,是由浮点数构成的数组。
json
体验AI代码助手
代码解读
复制代码
{ "embedding": { "metadata": { "model": "BAAI/bge-m3", "usage": { "promptTokens": 124, "completionTokens": 0, "totalTokens": 124, "nativeUsage": { "completion_tokens": 0, "prompt_tokens": 124, "total_tokens": 124 } }, "empty": true }, "result": { "index": 0, "metadata": { "modalityType": "TEXT", "documentId": "", "mimeType": { "type": "text", "subtype": "plain", "parameters": {}, "charset": null, "wildcardType": false, "wildcardSubtype": false, "subtypeSuffix": null, "concrete": true }, "documentData": null }, "output": [-0.03067115, -0.03704661, -0.029847892,0.051118582] }, "results": [{ "index": 0, "metadata": { "modalityType": "TEXT", "documentId": "", "mimeType": { "type": "text", "subtype": "plain", "parameters": {}, "charset": null, "wildcardType": false, "wildcardSubtype": false, "subtypeSuffix": null, "concrete": true }, "documentData": null }, "output": [-0.03067115, -0.03704661, -0.029847892] }] } }
嵌入模型将文本转成向量之后,要保存到向量数据库中才方便使用,下面将使用Redis作为向量数据库做一个简单的demo。
向量数据库
向量数据库是一种专门类型的数据库,在人工智能应用中发挥着至关重要的作用。
与传统关系型数据库的精确匹配查询不同,向量数据库的查询操作执行的是相似性搜索。当给定一个向量作为查询时,向量数据库会返回与该查询向量"相似"的向量集合。
向量数据库的核心作用在于将要向量化的数据与AI模型进行整合。其使用流程的第一步是将数据加载至向量数据库中。当需要向AI模型提交用户查询时,系统会首先检索出一组相似的文档。这些文档将作为用户问题的上下文背景,与原始查询一起发送给AI模型进行处理。这种技术被称为检索增强生成(Retrieval Augmented Generation,简称RAG)。
准备阶段
使用Redis作为向量数据库需要Redis版本支持Redis search 模块,使用docker 安装的话可以使用镜像 redis/redis-stack:latest。
如果是非docker环境就麻烦很多,能把 RediSearch项目编译成对应系统的文件也行。
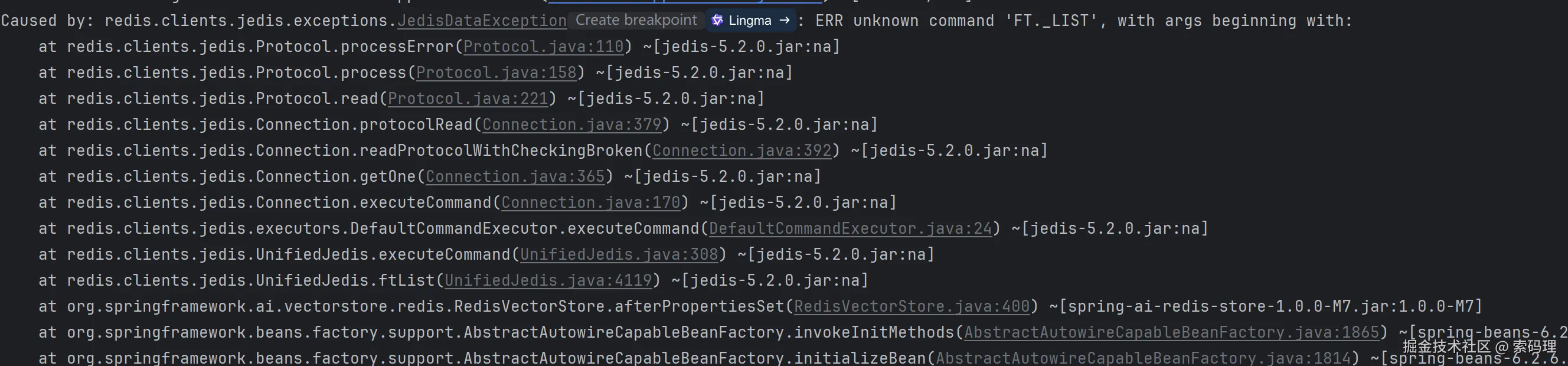
如果启动时报如下错误,就说明没有Redis search 模块。

引入依赖
在上面的基础上把Redis向量数据库依赖引入。
xml
体验AI代码助手
代码解读
复制代码
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-redis</artifactId> </dependency>
配置文件
一个简单的Redis 配置如下:
java
体验AI代码助手
代码解读
复制代码
# 向量数据库配置 # redis spring.data.redis.host=localhost spring.data.redis.port=6379 spring.data.redis.database=0 # 是否初始化向量数据库的 schema,默认为false spring.ai.vectorstore.redis.initialize-schema=true # redis key 前缀 spring.ai.vectorstore.redis.prefix=embedding: # 索引名称 spring.ai.vectorstore.redis.index-name=spring-ai-index
测试
java
体验AI代码助手
代码解读
复制代码
@Autowired private VectorStore vectorStore; @GetMapping("/ai/add") public void add(@RequestParam String message) { Document document = new Document(message); vectorStore.add(List.of(document)); // 删除 // String documentId = document.getId(); // vectorStore.delete(List.of(documentId)); } @GetMapping("/ai/search") public List<Document> search(@RequestParam String message) { // 查询前五个相似的结果 List<Document> documents = vectorStore.similaritySearch(SearchRequest.builder().query(message).topK(5).build()); return documents; }
添加
往向量数据库中添加两段文本。


保存到Redis中就形如下图中json类似。
json
体验AI代码助手
代码解读
复制代码
{ "embedding": [ -0.028931327, -0.034231577 ...... ], "content": "嵌入(Embeddings)是对文本、图像或视频的数值化表示,能够捕捉输入内容之间的关联关系。其工作原理是将文本、图像和视频转化为由浮点数构成的数组(即向量)。这些向量旨在捕捉原始内容的语义信息,而嵌入数组的长度被称为向量的维度。通过计算两个文本对应向量之间的数值距离(例如余弦相似度),应用程序可以量化评估生成这两个嵌入向量的原始对象之间的相似程度。" }
查询
访问 http://localhost:8080/embedding/ai/search?message=向量 查询向量字段。结果会把向量数据库中包含向量的信息返回。

至此,在Spring AI框架中使用嵌入模型和向量数据库简单的demo就完成了,探索更多用法和配置请参考官网。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)