YOLOv12环境配置,训练自己的数据集,更改评价指标。
到数据集文件夹中,比如val,子文件夹新增一个annotations文件,将生成的instances_val2017.json 复制到这个annotations里面。最后用命令行运行python val.py --weights best.pt --batch-size 1 --data test.yaml --save-json。首先,在YOLOv12项目下面新增`TXTToCOCO`文件夹,在
1.创建虚拟环境,python版本是3.11,因为在配置文件中可以看出该项目希望使用的是3.11版本
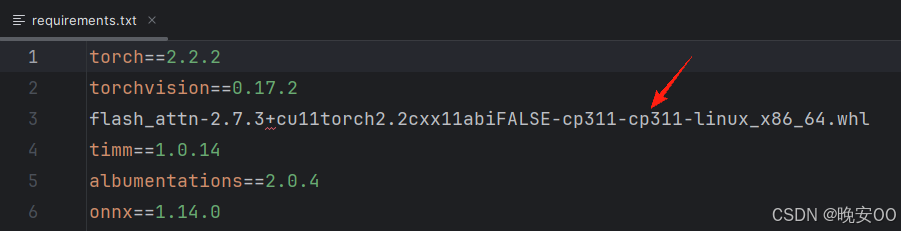
用该命令行创建环境及安装python
conda create -n yolov12 python=3.11
2.按照requirements.txt配置文件说明,到pytorch官网找到对应版本,即:
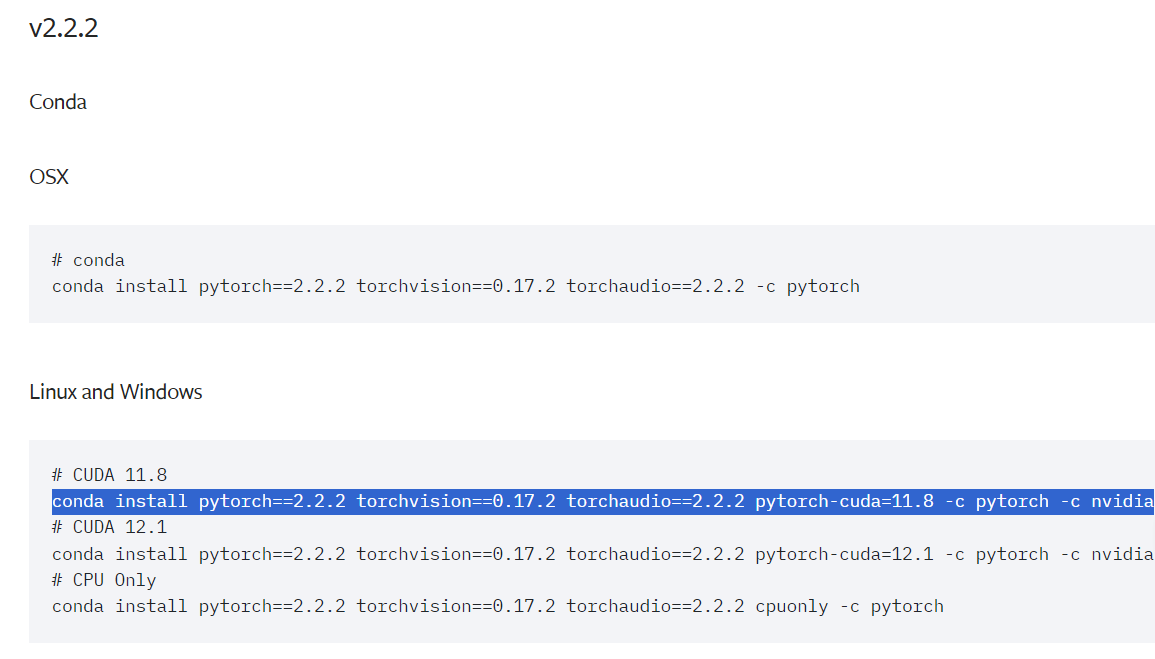
在配置文件第三行可以看到需要手动安装flash_attnhttps://github.com/Dao-AILab/flash-attention/releases/tag/v2.7.3从官网中选择要求的版本安装。但是官网只有适用Linux 系统的包,windows用户参考一下其他教程。
flash attention是一个用于加速模型训练推理的可选项,目前支持 Turing、Ampere、Ada Lovelace 或 Hopper 架构的 GPU(例如,T4、Quadro RTX 系列、RTX20 系列、RTX30 系列、RTX40 系列、RTX A5000/6000、A30/40、A100、H100 等)。
显卡不适用的话建议不要安装,训练推理不会出问题。但是其他特殊需求可能要用的上。
然后cd到该whl文件下载的目录,输入以下命令行安装
pip install flash_attn-2.7.3+cu11torch2.2cxx11abiTRUE-cp311-cp311-linux_x86_64.whl
最后注释掉第三行,执行
pip install -r requirements.txt和
pip install -e .到这里安装好了所有依赖。
3.创建数据集配置文件.yaml
train: /mnt/e/datasets/COCOmini/train # 训练集路径
val: /mnt/e/datasets/COCOmini/val # 验证集路径
nc: 3 #数据集分类数目
# class names
names: ['car','truck','bus'] #类别按照标签文件中类别顺序写入4.创建训练配置文件.py,README.md中给出了代码。
# -*- coding: utf-8 -*-
from ultralytics import YOLO
model = YOLO('yolov12.yaml')#模型路径
# Train the model
results = model.train(
data='coco.yaml',#数据集路径
epochs=600,
batch=4,
imgsz=640,
scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6
device='',
)#参数自行调整
# Evaluate model performance on the validation set
metrics = model.val()
# Perform object detection on an image
results = model("image")#输出图片路径
results[0].show()到此可以训练自己的数据集了。

5.更改评价指标。因为我是做小目标检测的,所以需要mAP值在像素32×32以内的评分。
首先,在YOLOv12项目下面新增`TXTToCOCO`文件夹,在此文件夹下新增jtxt2coco_map.py和class.txt
文件格式为-- TXTToCOCO
--- txt2coco_map.py
--- class.txt
class.txt文件里面内容为每个类别的名字,一定按照标签中类别的顺序填写。
参考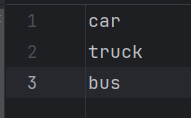 每一类占一行
每一类占一行
txt2coco_map.py代码为
import os
import json
import cv2
import random
import time
from PIL import Image
# 部分同学都用的autodl, 用antodl举例
# 使用绝对路径
#数据集 txt格式-labels标签文件夹
txt_labels_path='/mnt/e/datasets/cocomini/val/labels'
#数据集图片images文件夹
datasets_img_path='/mnt/e/datasets/cocomini/val/images'
# 这里 voc 为数据集文件名字,可以改成自己的路径
# xx.json生成之后存放的地址
save_path='/mnt/e/basic model/contrast experiment/yolov12-main/yolov12-main/TXTToCOCO'
#自己数据集的类别, 一行一个类 例如: class.txt文件
# car
# phone
# ...
classes_txt='/mnt/e/basic model/contrast experiment/yolov12-main/yolov12-main/TXTToCOCO/class.txt'
with open(classes_txt,'r') as fr:
lines1=fr.readlines()
categories=[]
for j,label in enumerate(lines1):
label=label.strip()
categories.append({'id':j,'name':label,'supercategory':'None'})
print(categories)
write_json_context=dict()
write_json_context['info']= {'description': 'For object detection', 'url': '', 'version': '', 'year': 2021, 'contributor': '', 'date_created': '2021'}
write_json_context['licenses']=[{'id':1,'name':None,'url':None}]
write_json_context['categories']=categories
write_json_context['images']=[]
write_json_context['annotations']=[]
imageFileList=os.listdir(datasets_img_path)
for i,imageFile in enumerate(imageFileList):
imagePath = os.path.join(datasets_img_path,imageFile)
image = Image.open(imagePath)
W, H = image.size
img_context={}
img_context['file_name']=imageFile
img_context['height']=H
img_context['width']=W
img_context['id']= imageFile[:-4]
img_context['license']=1
img_context['color_url']=''
img_context['flickr_url']=''
write_json_context['images'].append(img_context)
txtFile=imageFile[:-4]+'.txt'
with open(os.path.join(txt_labels_path,txtFile),'r') as fr:
lines=fr.readlines()
for j,line in enumerate(lines):
bbox_dict = {}
class_id,x,y,w,h=line.strip().split(' ')
class_id,x, y, w, h = int(class_id), float(x), float(y), float(w), float(h)
xmin=(x-w/2)*W
ymin=(y-h/2)*H
xmax=(x+w/2)*W
ymax=(y+h/2)*H
w=w*W
h=h*H
bbox_dict['id']=i*10000+j
bbox_dict['image_id']=imageFile[:-4]
bbox_dict['category_id']=class_id
bbox_dict['iscrowd']=0
height,width=abs(ymax-ymin),abs(xmax-xmin)
bbox_dict['area']=height*width
bbox_dict['bbox']=[xmin,ymin,w,h]
bbox_dict['segmentation']=[[xmin,ymin,xmax,ymin,xmax,ymax,xmin,ymax]]
write_json_context['annotations'].append(bbox_dict)
name = os.path.join(save_path,"instances_val2017"+ '.json')
with open(name,'w') as fw:
json.dump(write_json_context,fw,indent=2)
print("ok🚀")
运行 txt2coco_map.py会生成 一个 instances_val2017.json 文件。
到数据集文件夹中,比如val,子文件夹新增一个annotations文件,将生成的instances_val2017.json 复制到这个annotations里面。
最后用命令行运行python val.py --weights best.pt --batch-size 1 --data test.yaml --save-json

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)