开源大数据流水线系统PiflowX本地开发调试
编译完成后,找到streampark-console-service模块target目录下压缩包apache-streampark-2.2.0-SNAPSHOT-incubating-bin.tar.gz,解压到指定目录。在资源管理中,上传piflowx/piflow-server/target下piflow-server.jar。Program main填写。启动完成,会在项目下生成一个serv
1.代码获取
关注公众号PiflowX,发送“源码”获取github地址。
2.环境准备
说明:本文档基于windows11操作系统,flink和hdfs基于虚拟机centos启动。
2.1 本地flink环境
Flink >= 1.12, 只需要从Flink官网下载解压即可。演示中我下载的是[flink-1.18.0](Apache Archive Distribution Directory)
解压到指定目录,如d:\\env\\flink
下载wintutils。具体步骤可参考文章Windows环境下安装Hadoop3.1.0全过程(超详细手把手一条龙教学)_windows安装hadoop-CSDN博客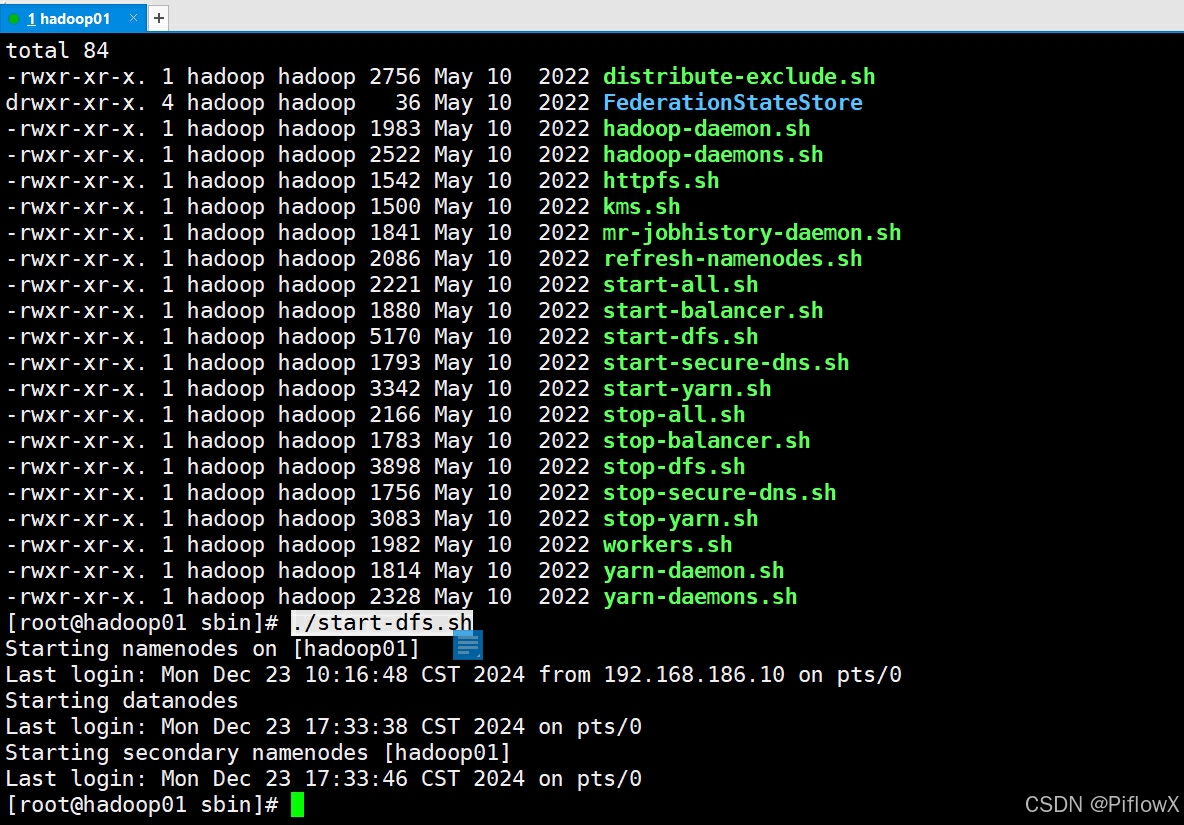

3.后端本地开发
3.1前提条件
-
java 1.8+
-
maven
-
hdfs
-
flink
3.2项目编译
切换到dev-flow分支。
mvn clean package -DskipTests
3.3解压压缩包
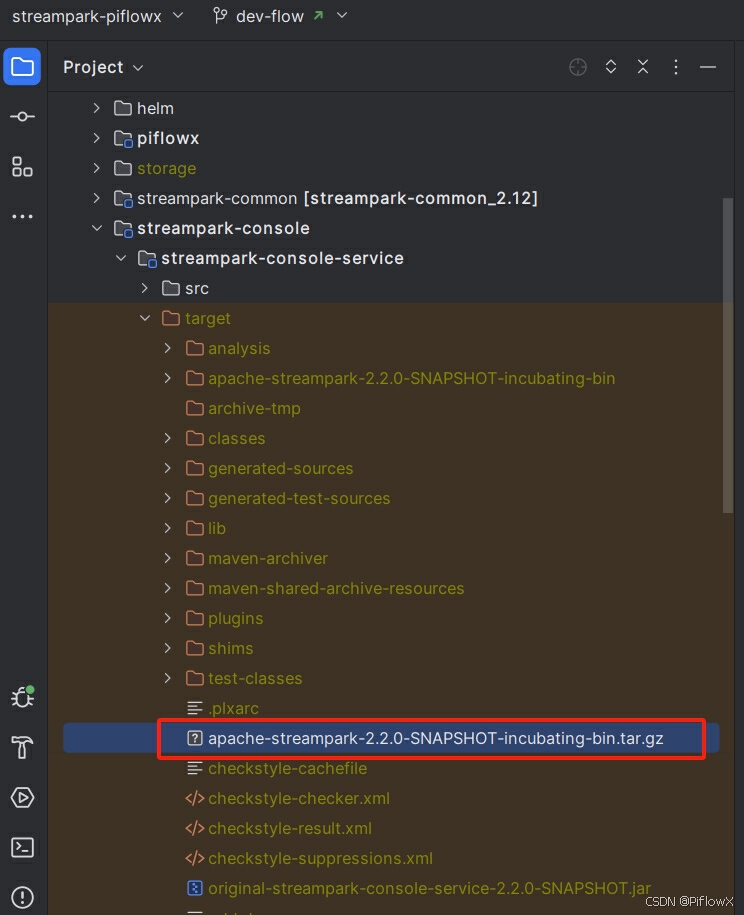
编译完成后,找到streampark-console-service模块target目录下压缩包apache-streampark-2.2.0-SNAPSHOT-incubating-bin.tar.gz,解压到指定目录。
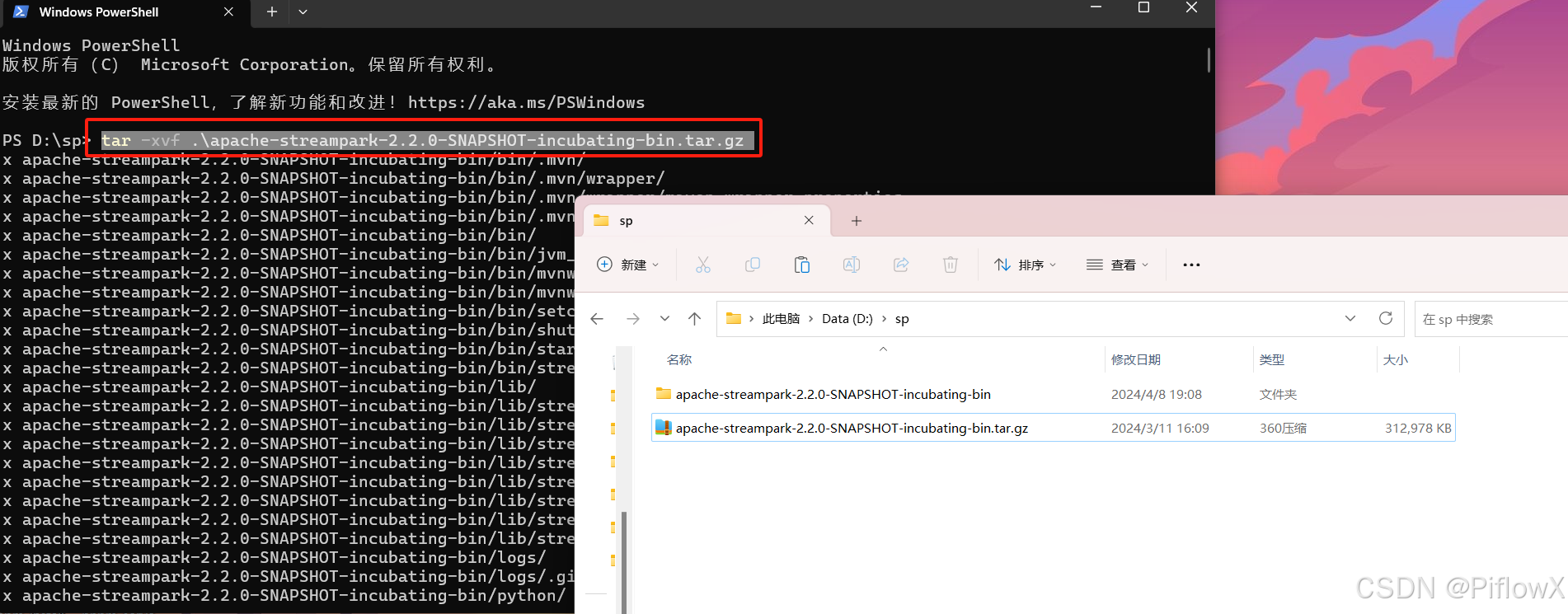
cd ./streampark-console-service/target
tar -zxvf apache-streampark-2.2.0-SNAPSHOT-incubating-bin.tar.gz
3.4启动后台服务
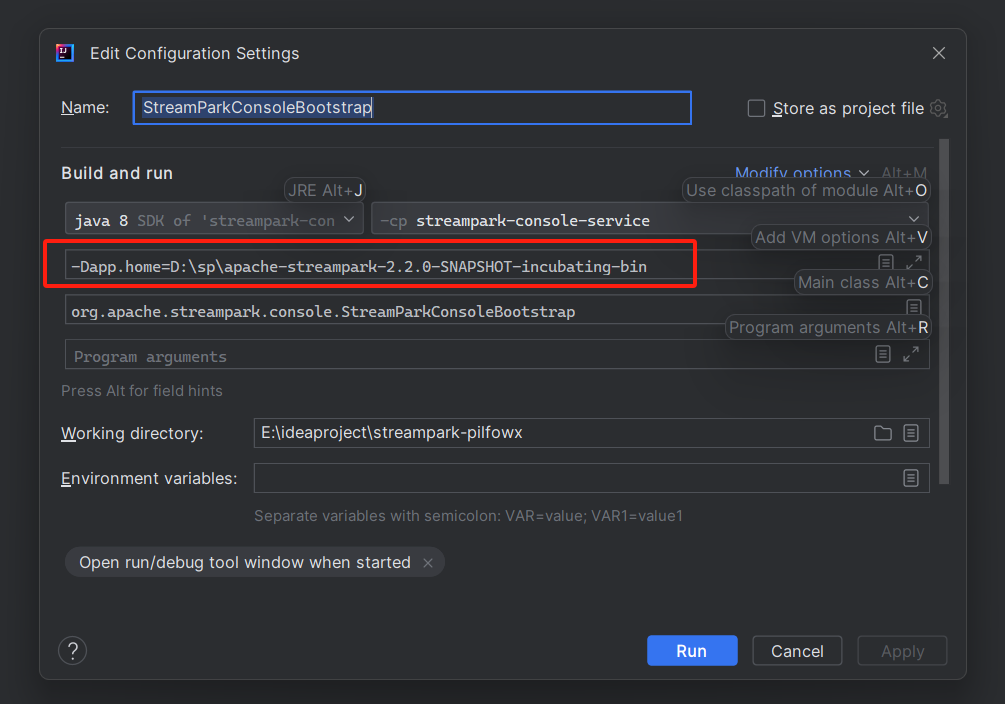
找到 streampark-console/streampark-console-service/src/main/java/org/apache/streampark/console/StreamParkConsoleBootstrap.java
修改启动配置
勾选Add VM options,填写参数-Dapp.home=$path,$path是我们刚刚复制的路径
4.PiflowX后端启动
启动服务
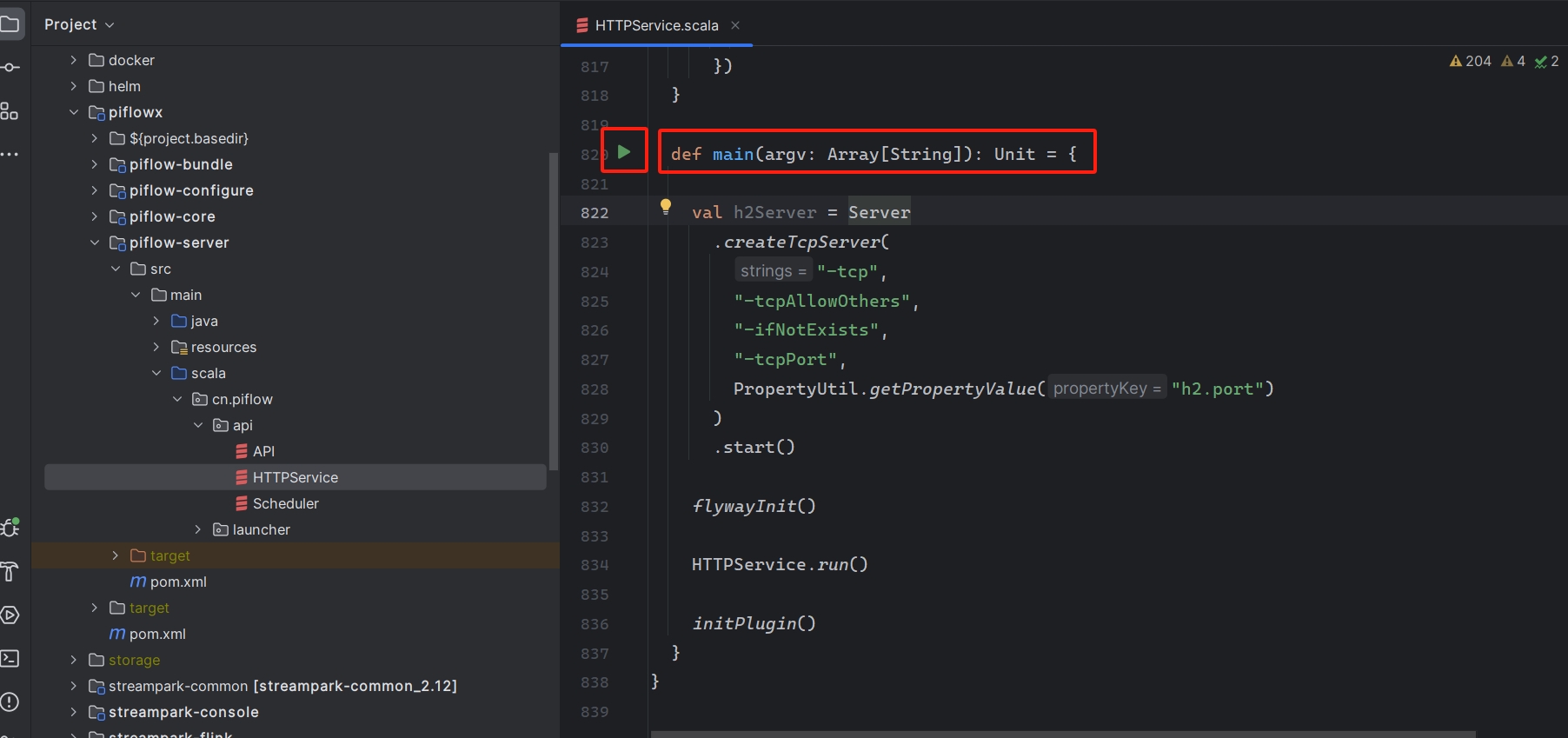
找到 piflowx/piflow-server/src/main/scala/cn/piflow/api/HTTPServer.scala,
运行main方法。
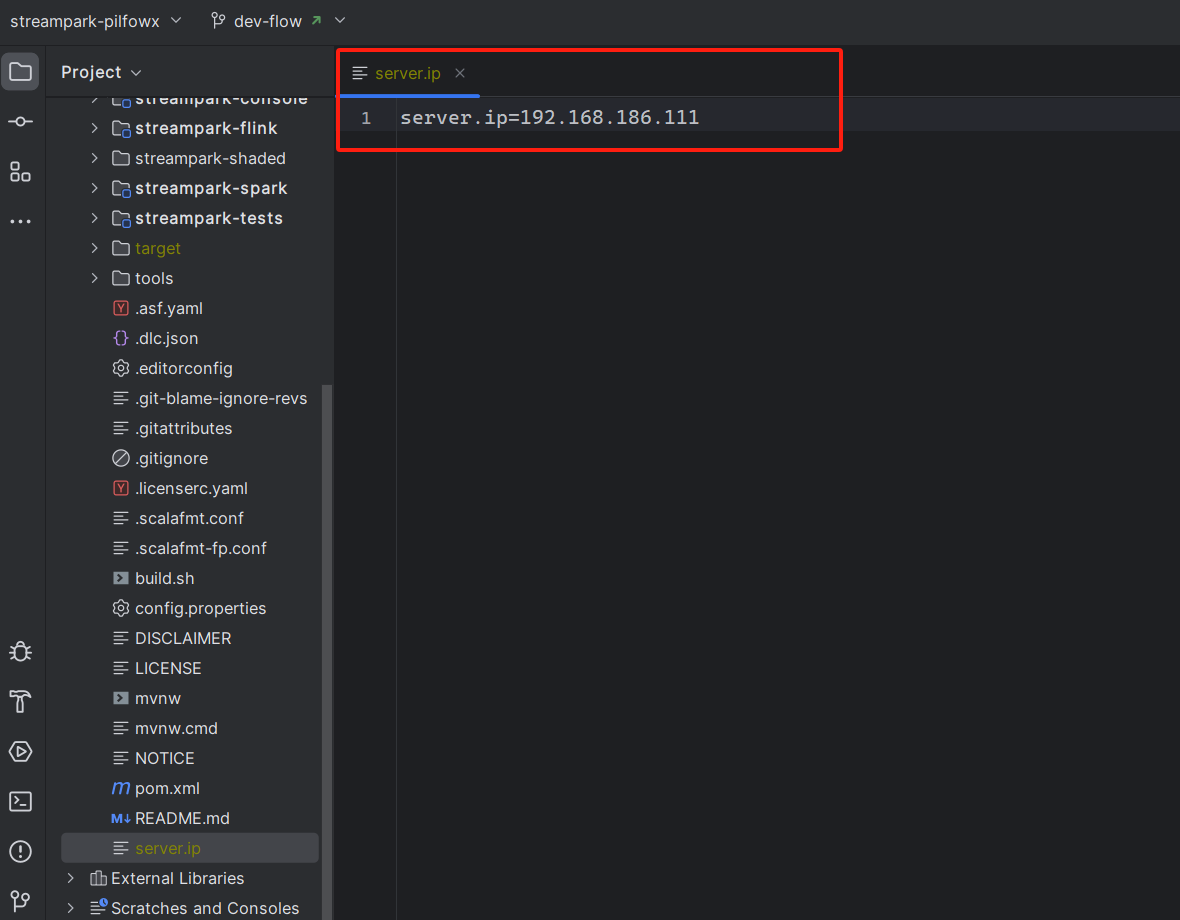
启动完成,会在项目下生成一个server.ip文件,文件内容为当前机器ip。
修改streampark-console-service服务baseConfig.properties配置文件,piflowx.server.ip为上述server.ip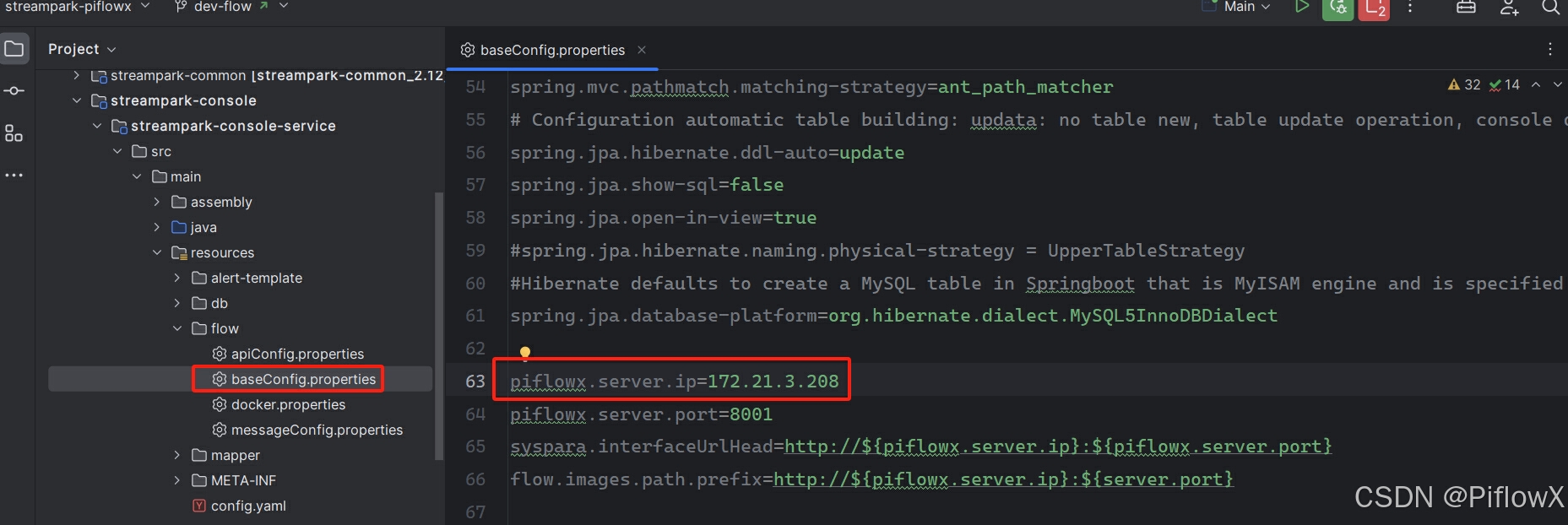
重启streampark-console-service服务。
5.前端本地开发
前提条件
Note
如果你遇到依赖下载缓慢需要配置 npm 镜像源,方法为在用户文件夹下找到 .npmrc 将以下内容写入:
strict-peer-dependencies=false save-workspace-protocol = rolling registry = 'http://registry.npmmirror.com'
构建并运行
- 安装依赖:
cd ../streampark-console/streampark-console-webapp
pnpm install
如果运行失败,执行以下命令:
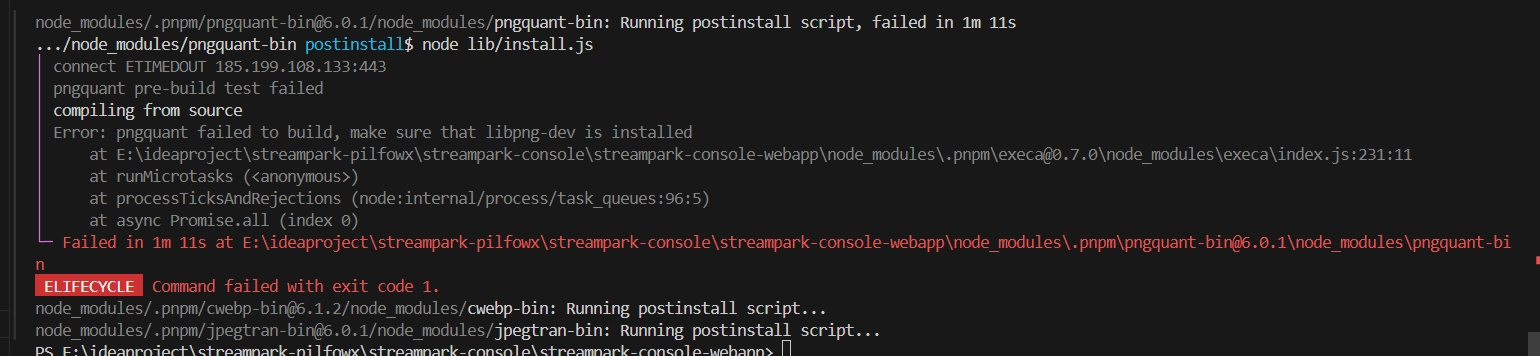
pnpm install --ignore-scripts
- 运行:
pnpm serve

- 打包
pnpm build
浏览器支持
本地开发推荐使用Chrome 80+ 浏览器,支持现代浏览器, 不支持 IE。
6.flink流水线任务示例
浏览器输入http://localhost:10001/登陆系统。点击登陆进入首页。
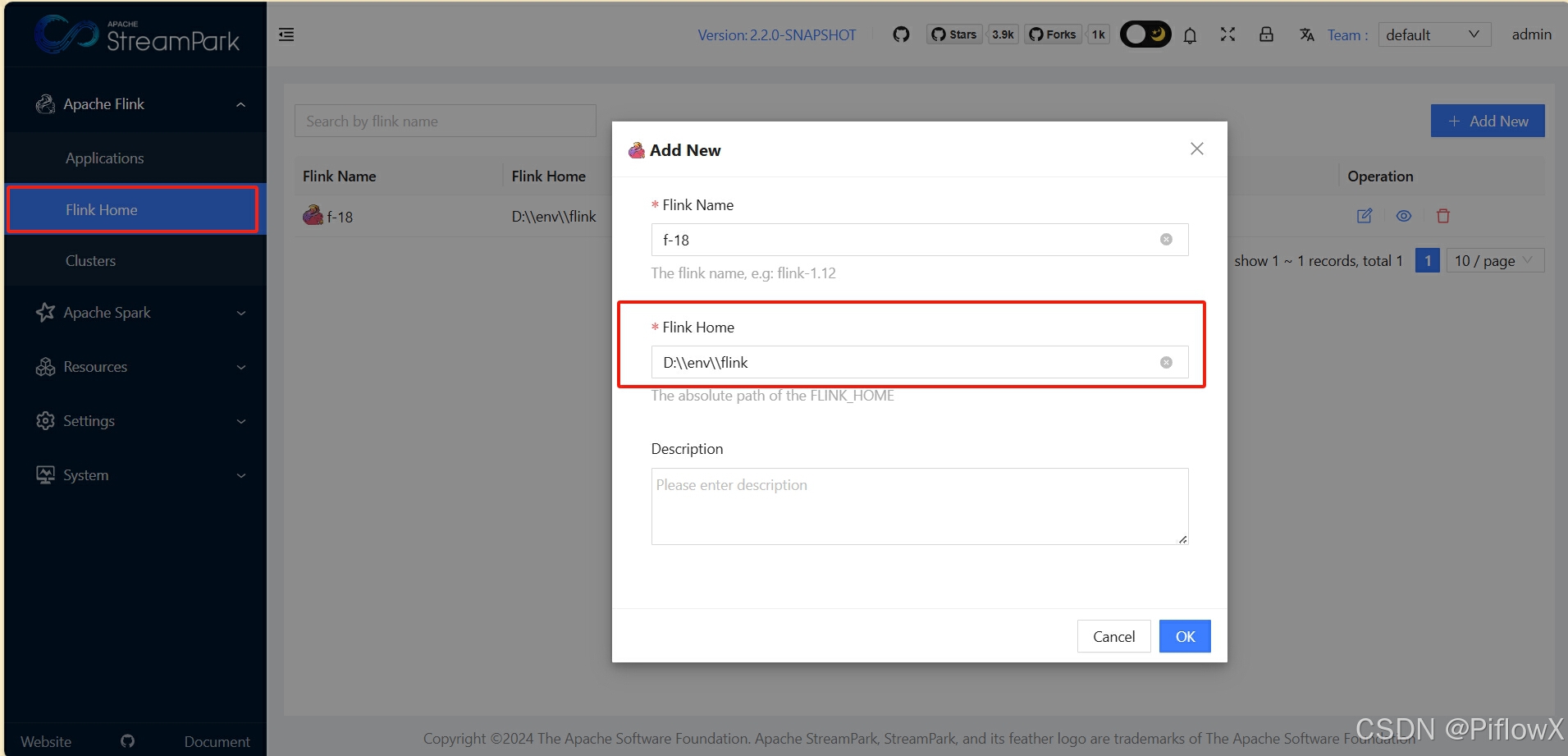
配置flink home
flink home为2.1节flink解压目录(如d:\\env\\flink)
配置flink cluster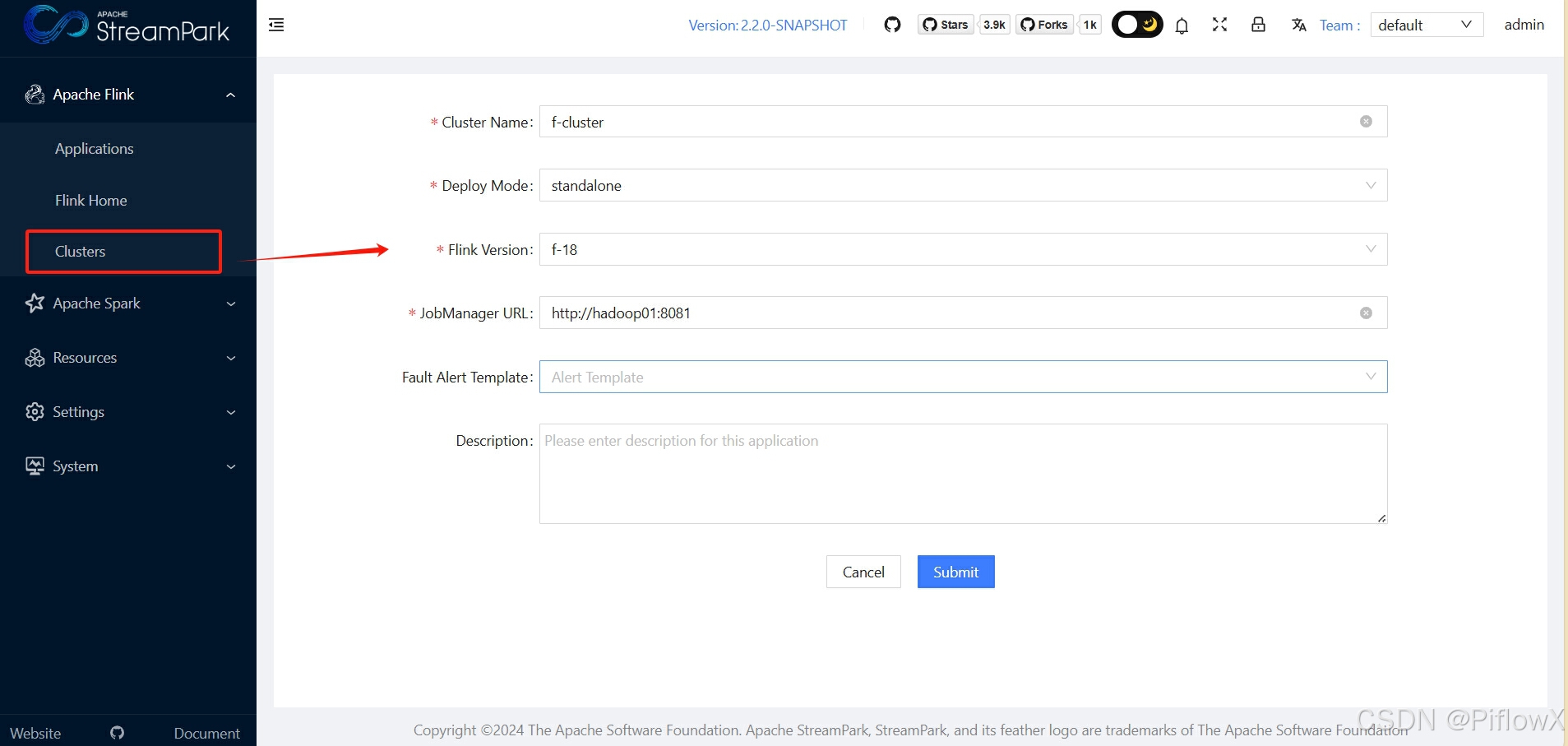
上传flink流水线依赖包
在资源管理中,上传piflowx/piflow-server/target下piflow-server.jar。Program main填写cn.piflow.launcher.flink.StartFlinkFlowMain。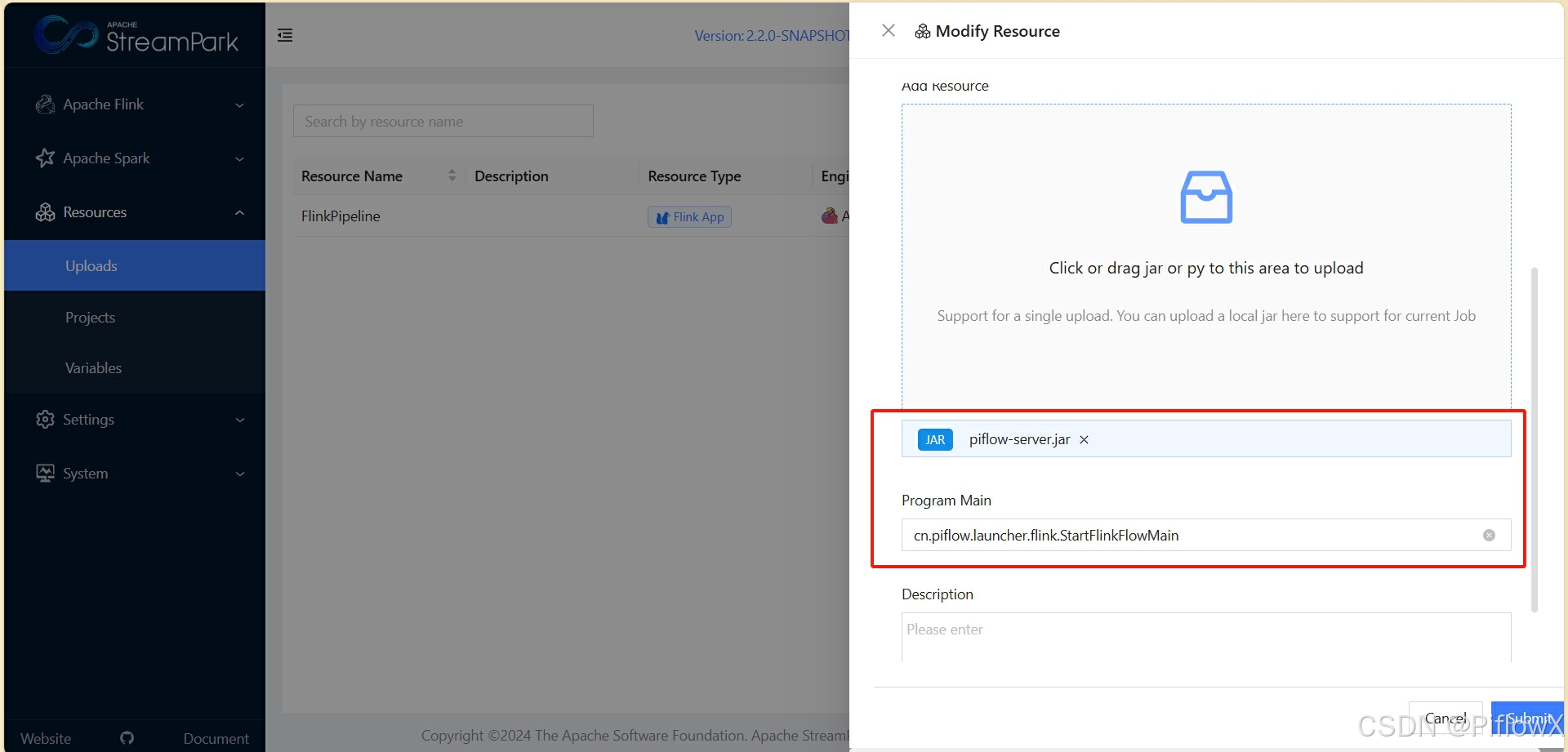
创建作业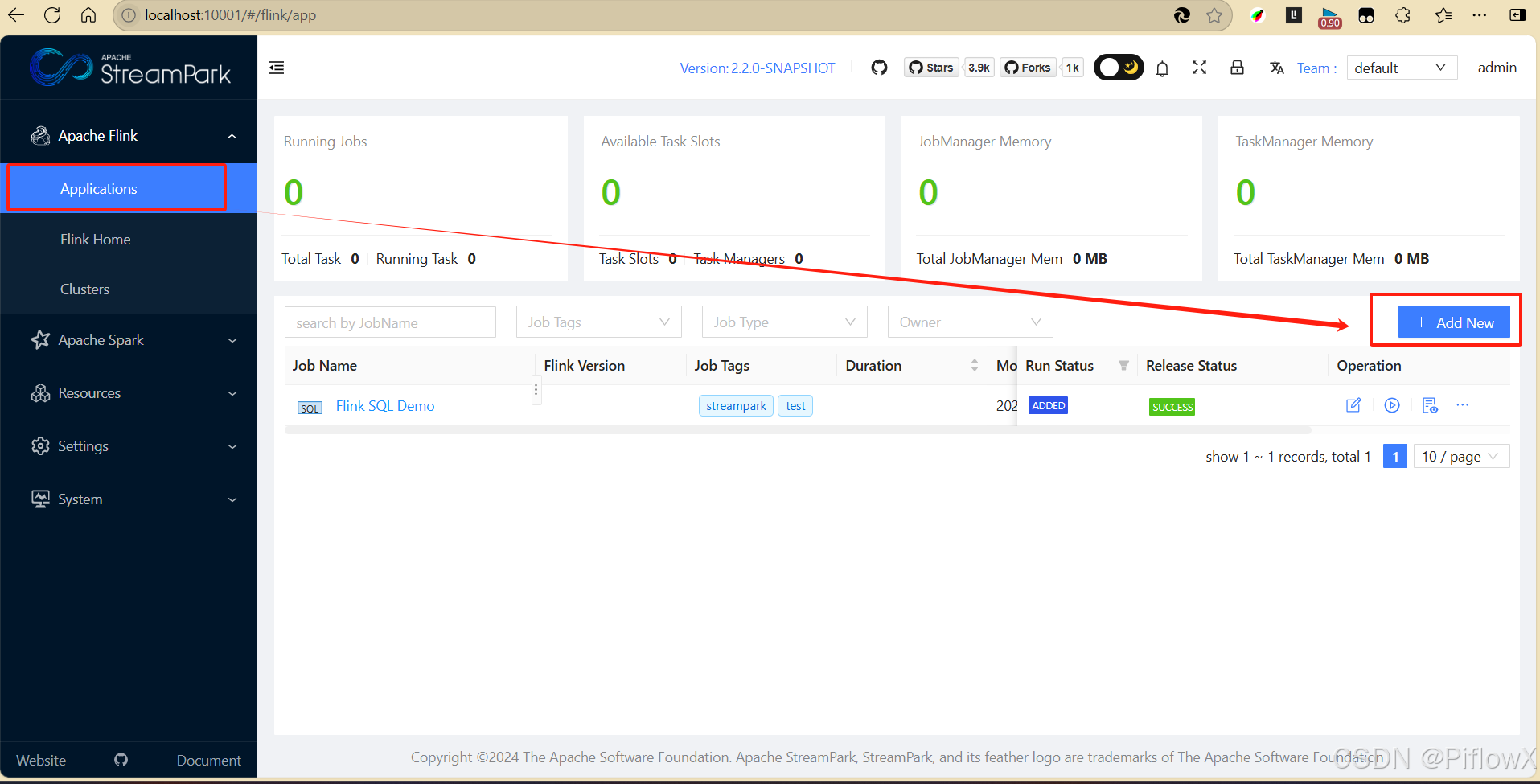
选择Flink Pipeline作业类型创建流水线任务
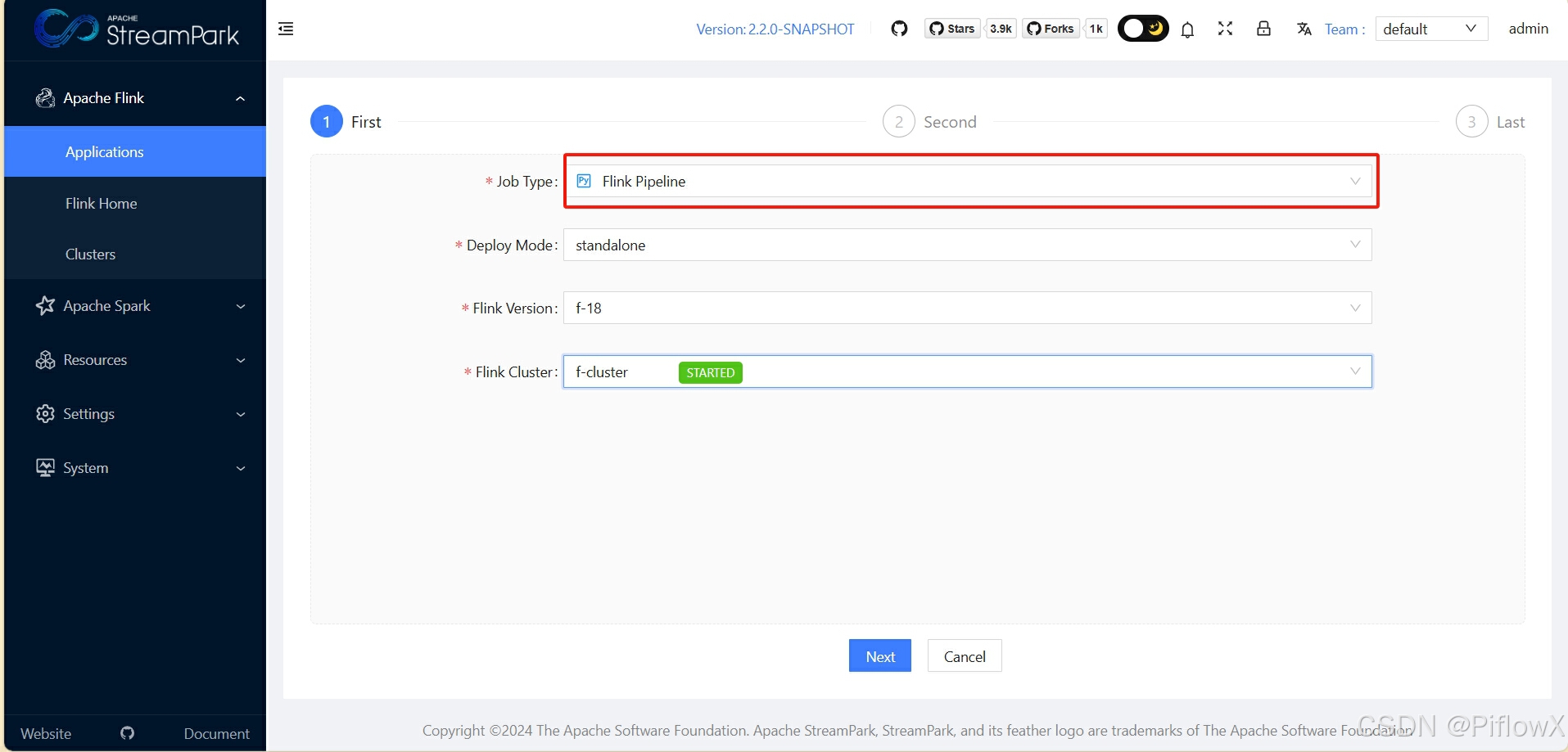
资源选择前面上传的Flink流水线作业依赖包
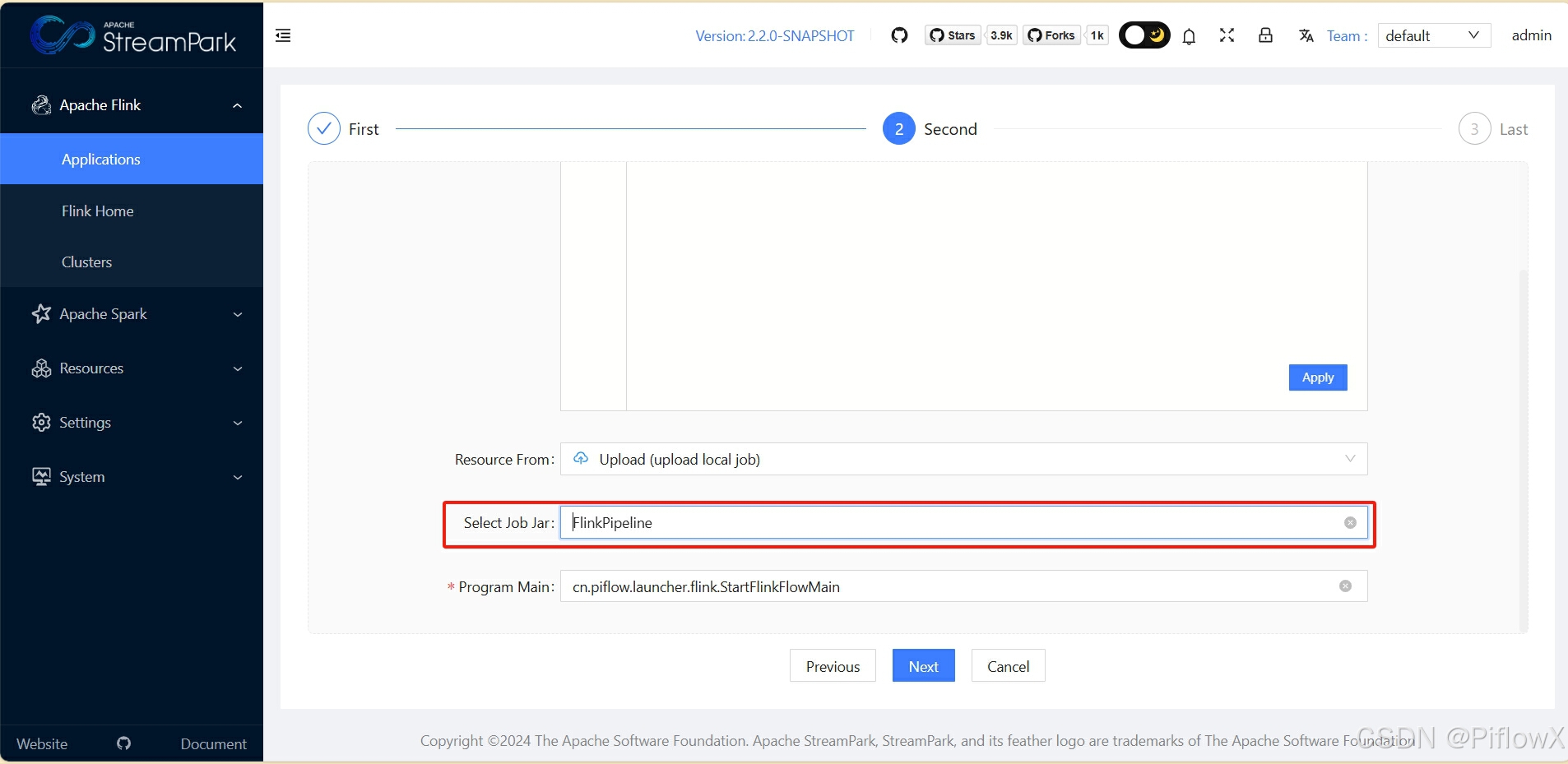
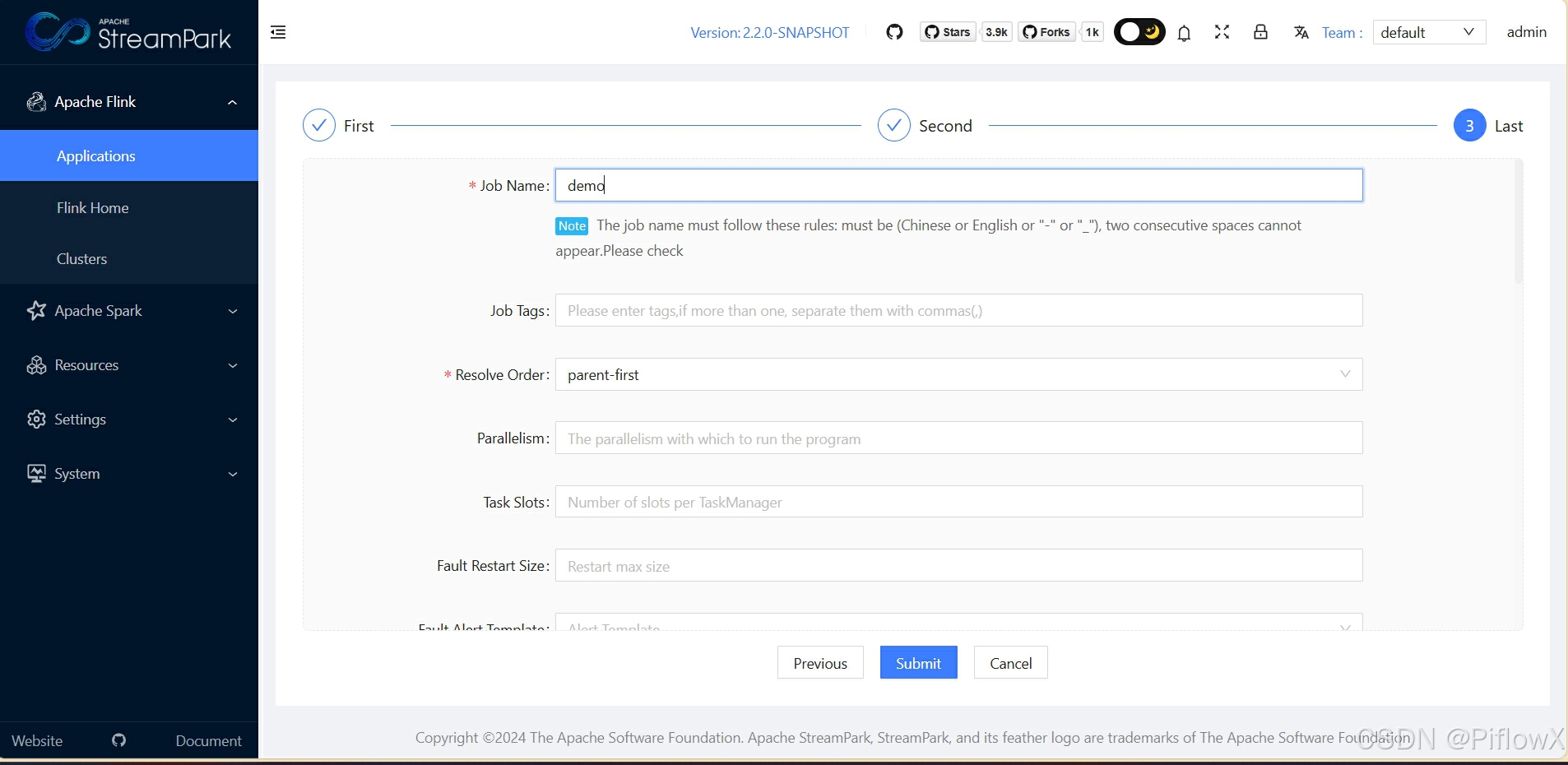
填写作业名称,点击提交
在作业列表,可以看到刚刚创建的流水线任务,点击图中图标,进入设计界面。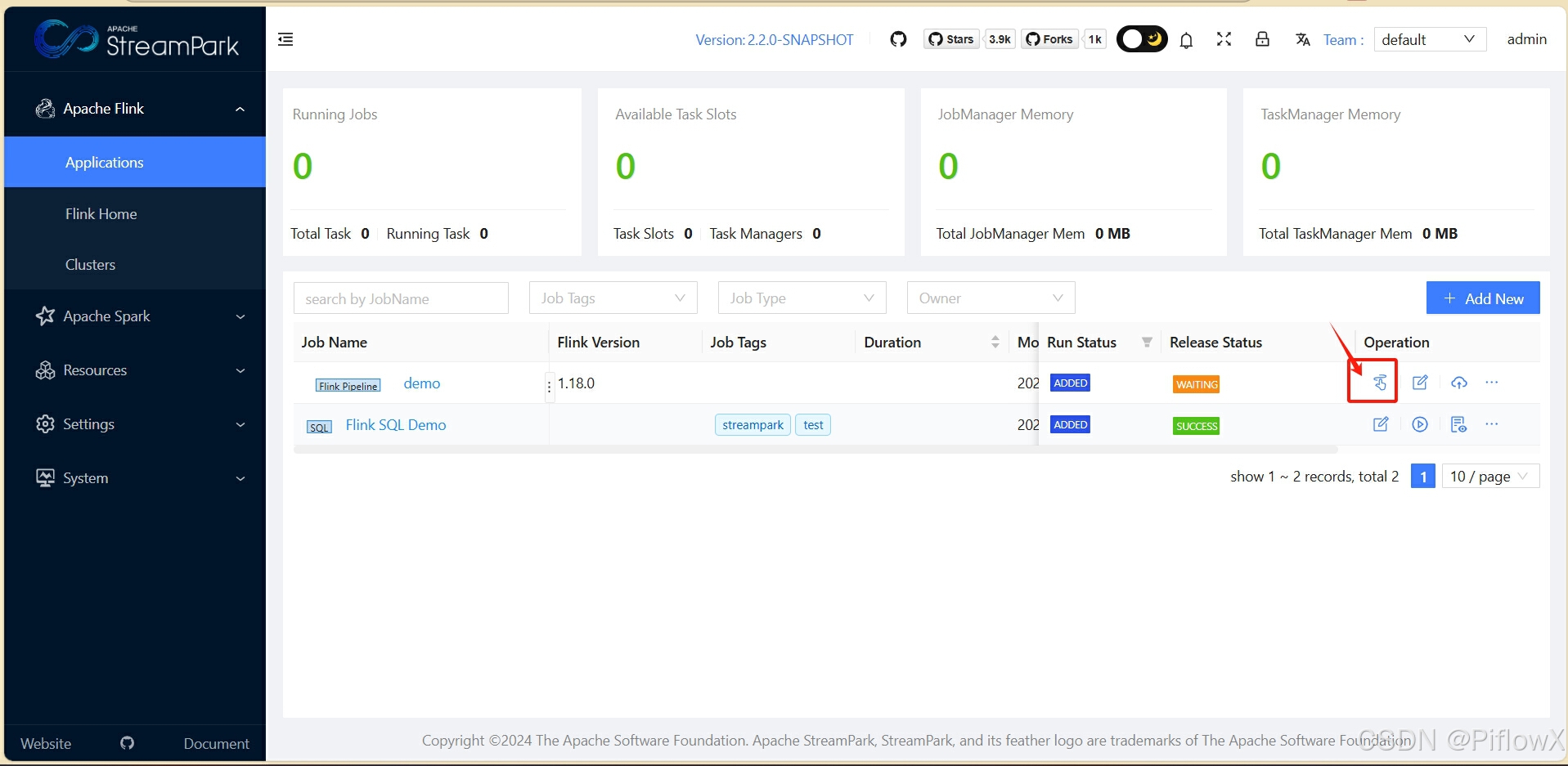
首次使用系统,是没有flink流水线算子组件的,需要点击reload stops选项加载或刷新组件。
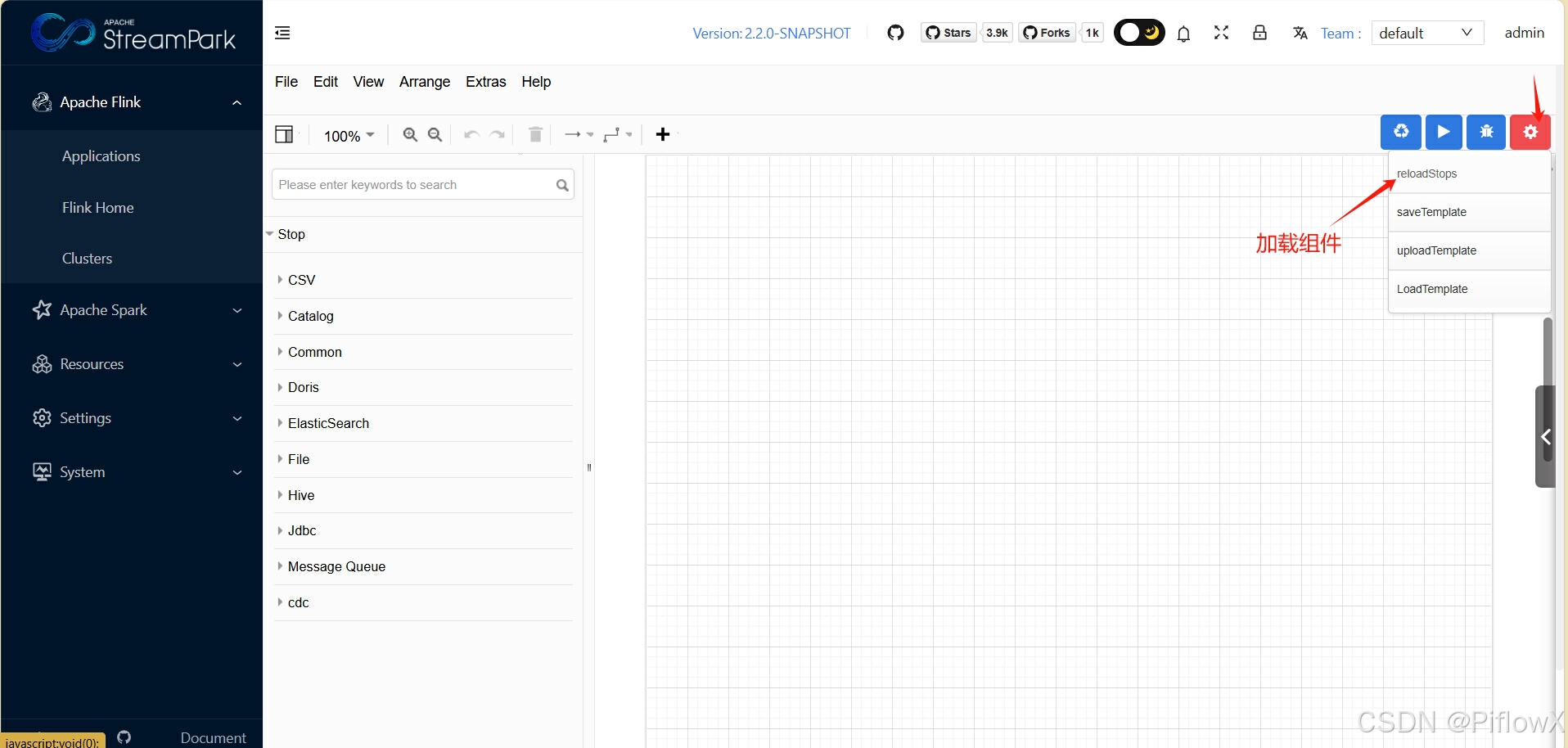
拖动一个DataGen组件和ShowData组件,模拟生成100条数据,并查看数据。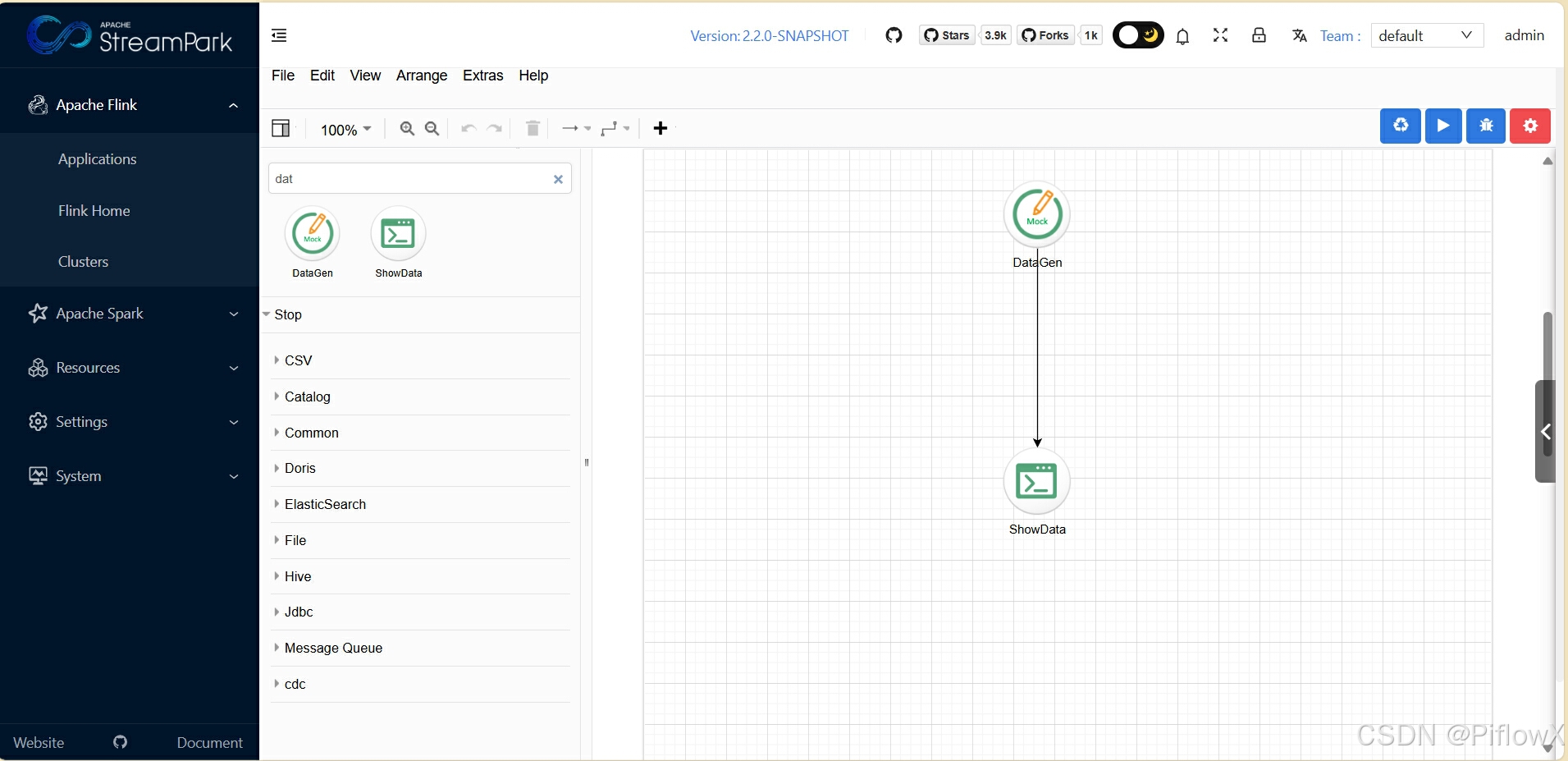
回到作业首页,发布任务,并启动。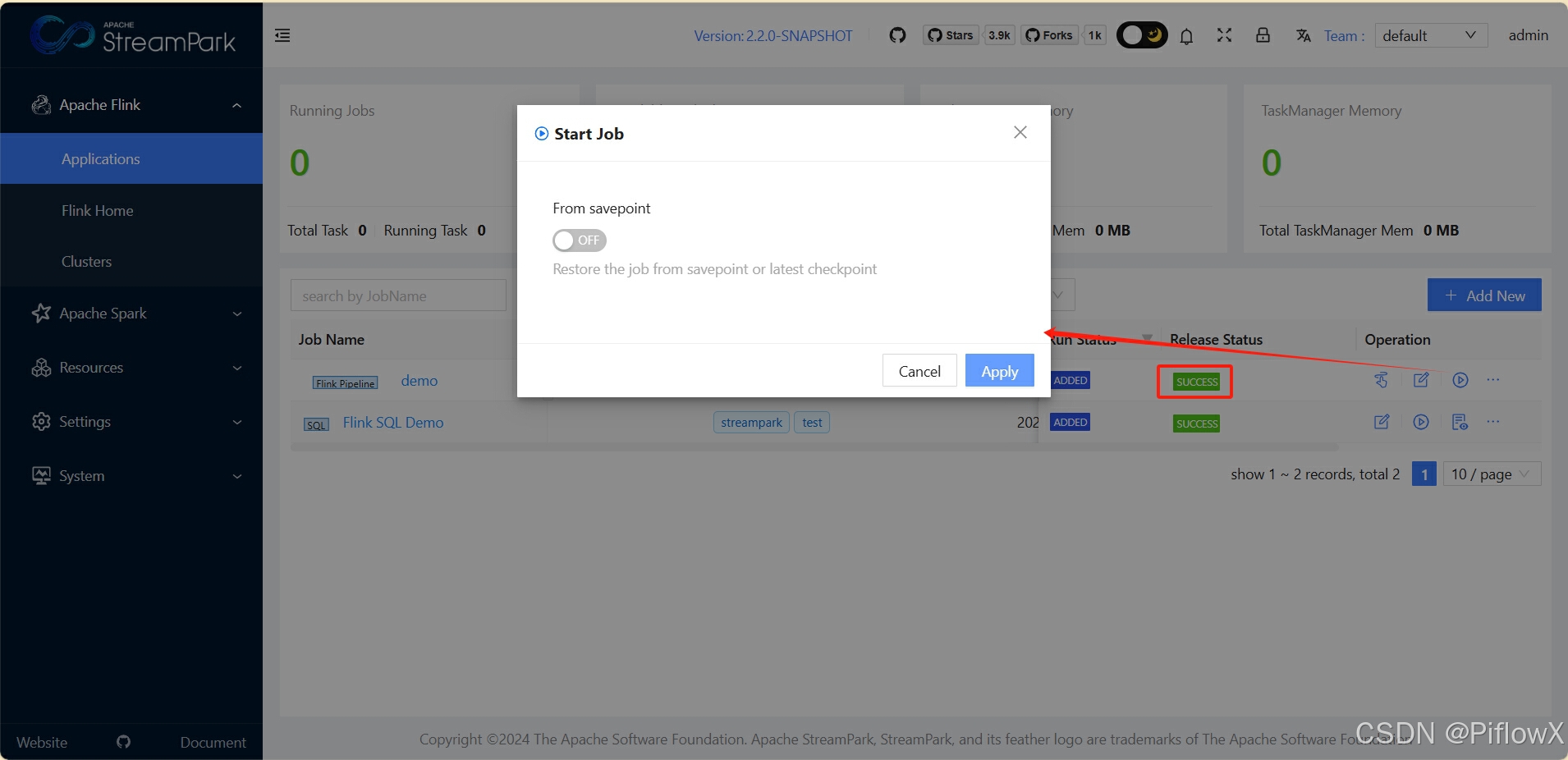
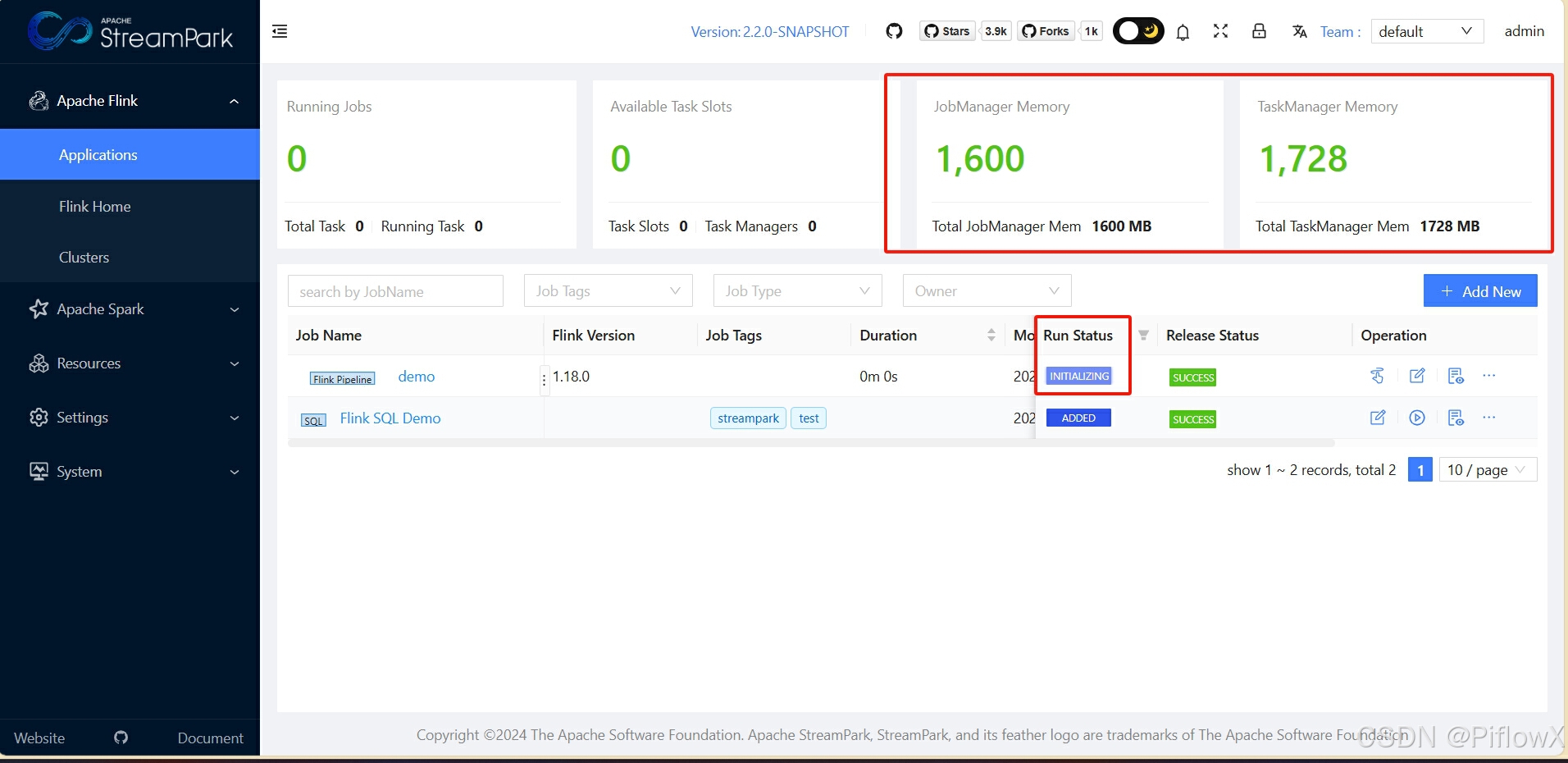
等待一会,可以看到作业运维界面作业状态已变化。
在flink web可以看到作业的运行状态。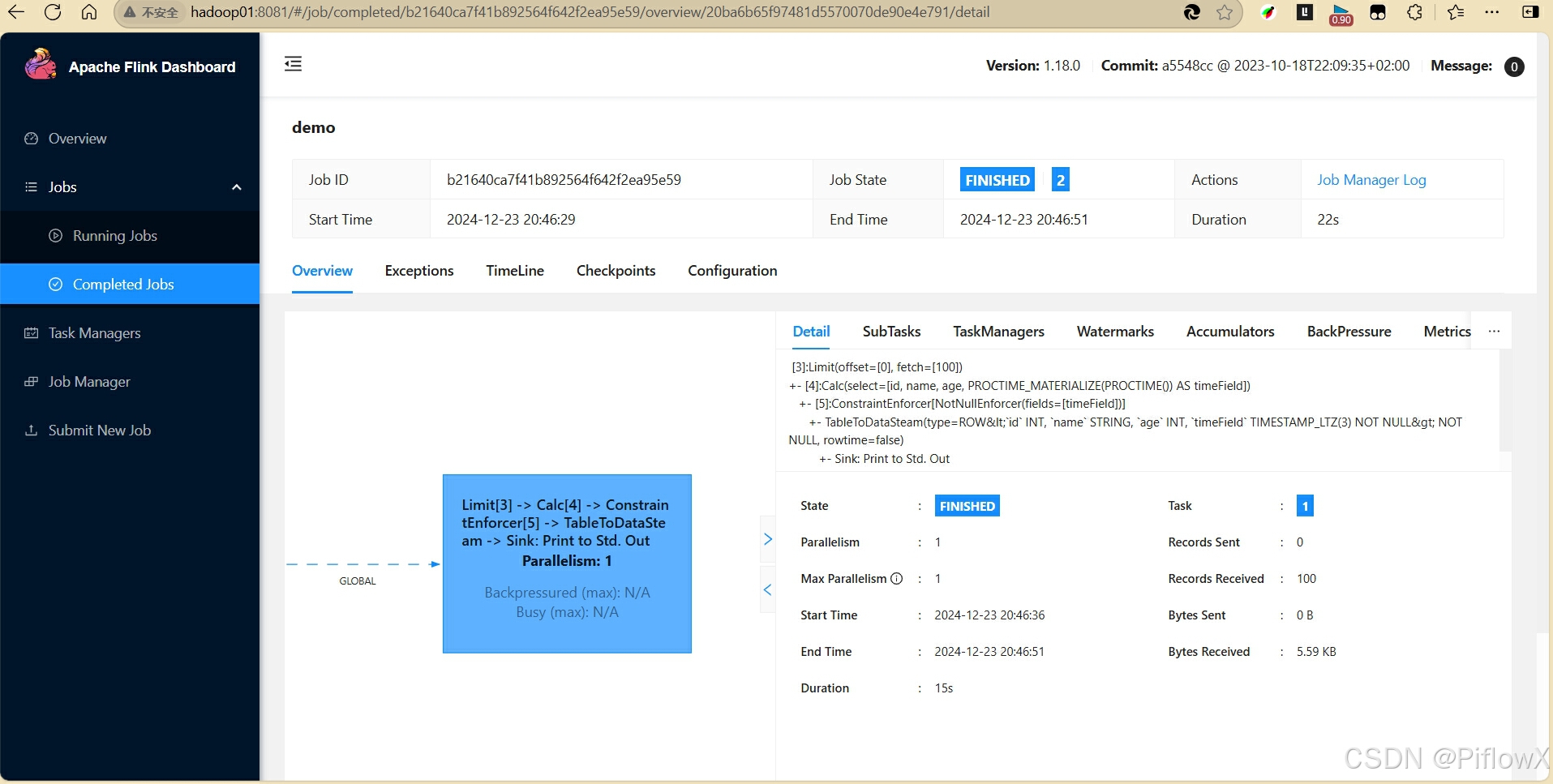
日志输入可看到流水线生成的模拟数据。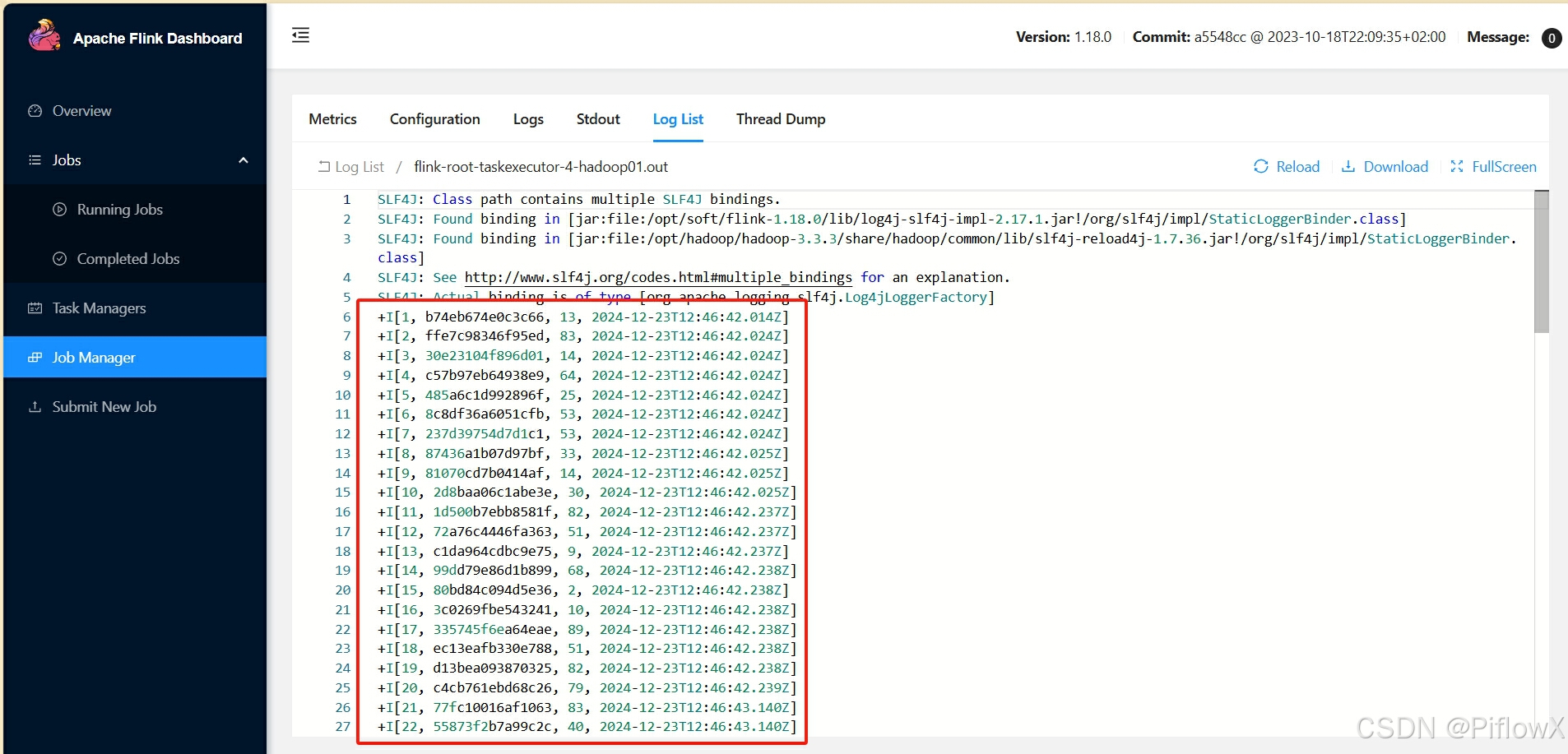

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)