spark集群环境下,实现人口平均年龄计算
spark集群环境下,计算人口平均年龄。收集常见错误
·
文章目录
任务目标
在虚拟机上部署spark集群,给定renkou.txt文件,输出平均年龄
renkou.txt:
集群运作spark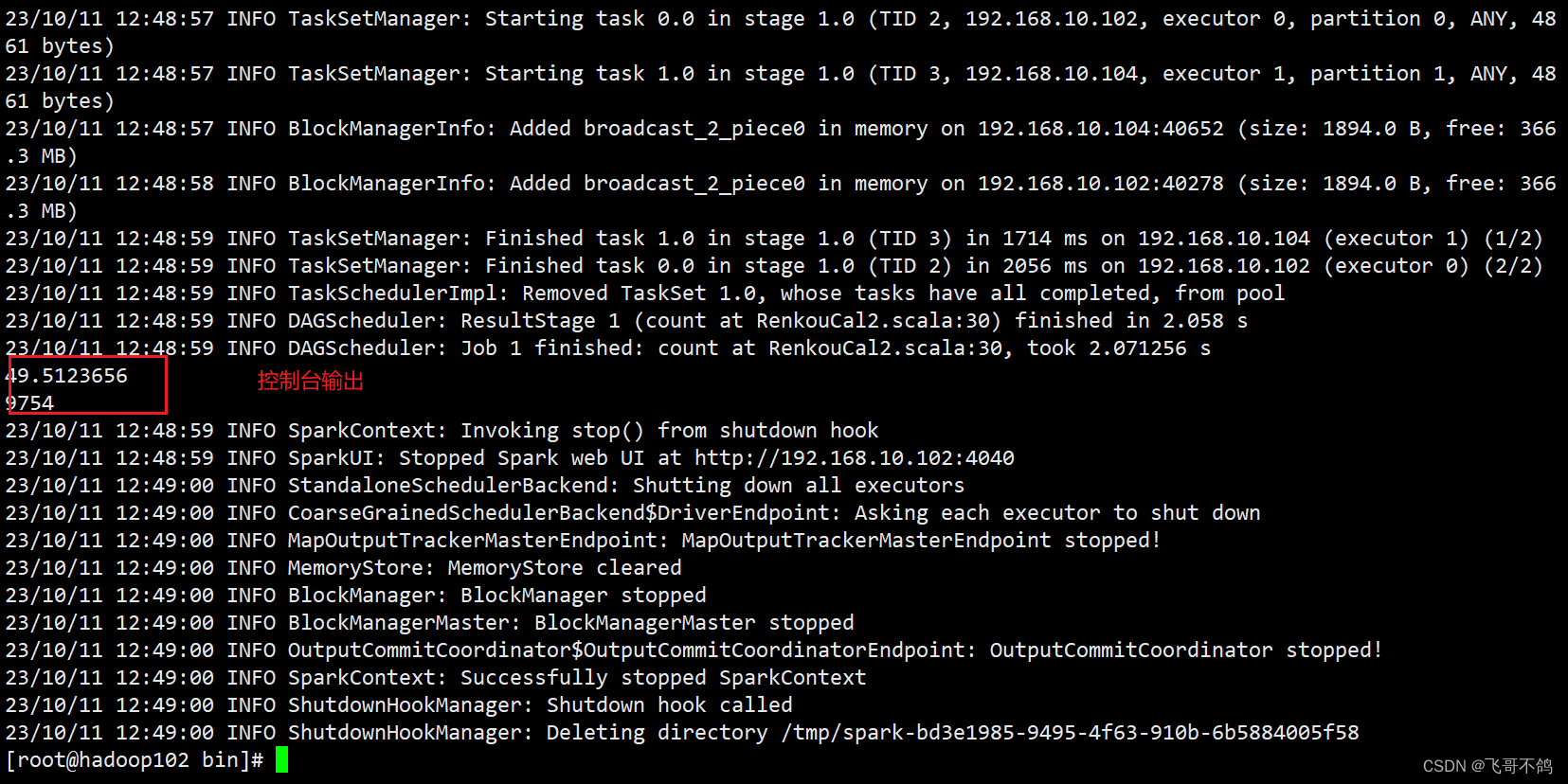
spark web界面显示结果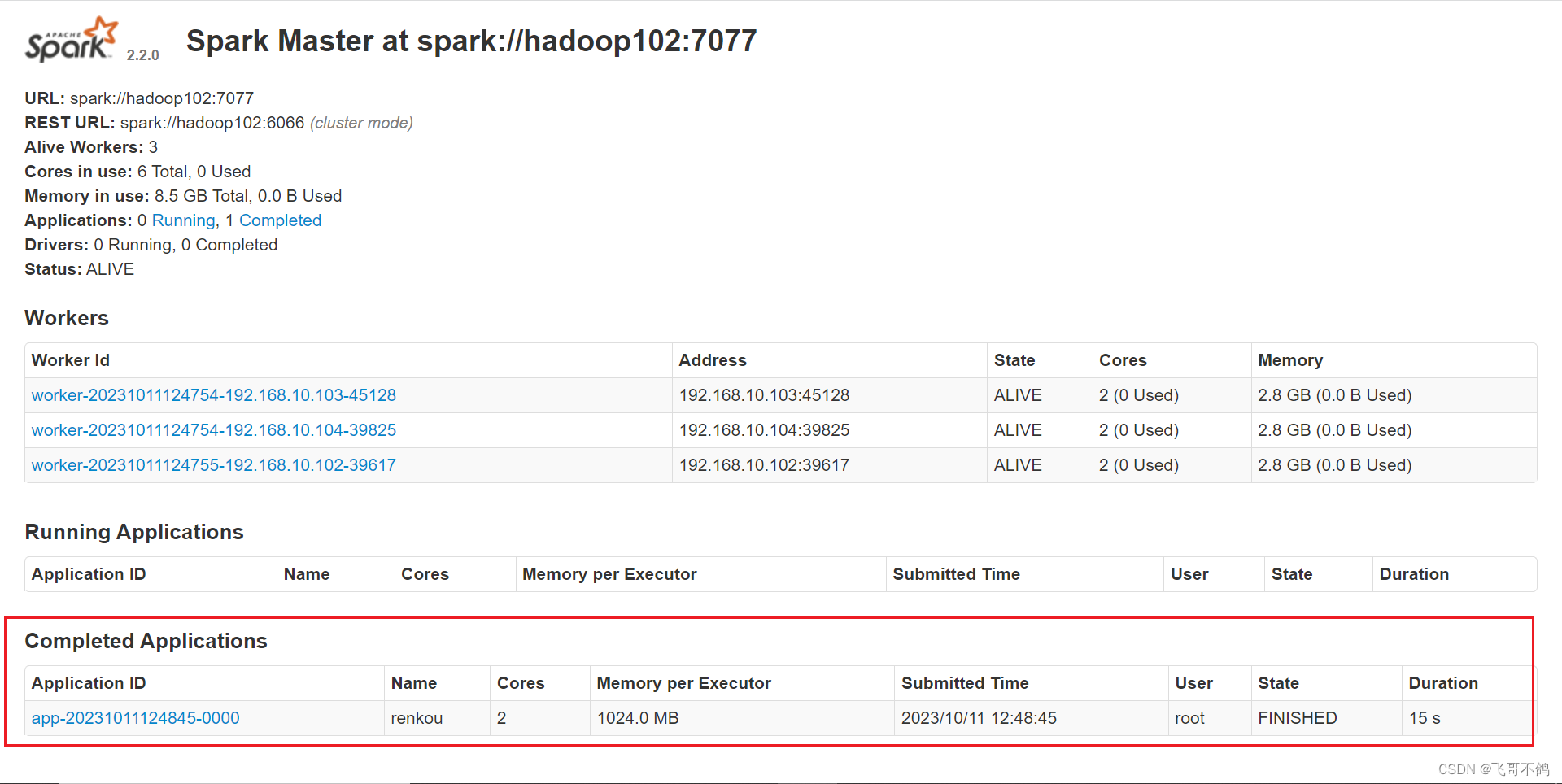
0. 版本信息
| 信息 | 版本 |
|---|---|
| Scala | 2.11.8 |
| Java | 1.8 |
| spark | 2.2.0 |
hadoop安装
尚硅谷Hadoop
spark
spark集群搭建
tip: 按照上述spark博客集群搭建时,node1是虚拟机的域名,记得换成自己虚拟机的域名。如果没有,填写真实ip地址即可
maven坐标
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
1. 计算生成renkou.txt
因为数据量很庞大, 1000万行,因此采用Java多线程的方式生成数据
package com.xhf.java;
import com.xhf.java.entity.Person;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Random;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* 生成renkou.txt
*/
public class RenkouGen {
static Random random = new Random();
static Object lock = new Object();
public static void main(String[] args) throws Exception {
// 创建文件
File file = new File("E:\\B站视频创作\\Java计算人口平均_spark\\src\\main\\resources\\renkou.txt");
// 判断file是否存在
if (file.exists()) {
file.delete();
}else {
file.createNewFile();
}
// 创建流管到
BufferedWriter bw = new BufferedWriter(new FileWriter(file, false));
// 创建线程池 1000万, 100万(每个线程)
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
// 生成数据
executorService.execute(() -> {
// 100万
for (int j = 0; j < 1000000; j++) {
Person person = new Person(j, random.nextInt(20) + 40);
// 数据写入文件
try {
// synchronized (lock) {
// 加锁
bw.write(person.toString());
// bw.newLine();
// }
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
// 关闭线程池
executorService.shutdown();
executorService.awaitTermination(10000L, TimeUnit.SECONDS);
bw.close();
}
}
tip:
- 生成完的文件需要上传到hadoop文件系统中,这样便于spark程序部署时获取文件信息
- 如果不上传至hadoop中,在集群环境下运行时,可以通过main的args参数指定路径,又或者将文件存放在resouce目录下,打jar包后,代码通过resource资源目录进行定位
2. 文件上传至spark
如果遇到问题,请往下看 3.上传文件时,可能出现的常见错误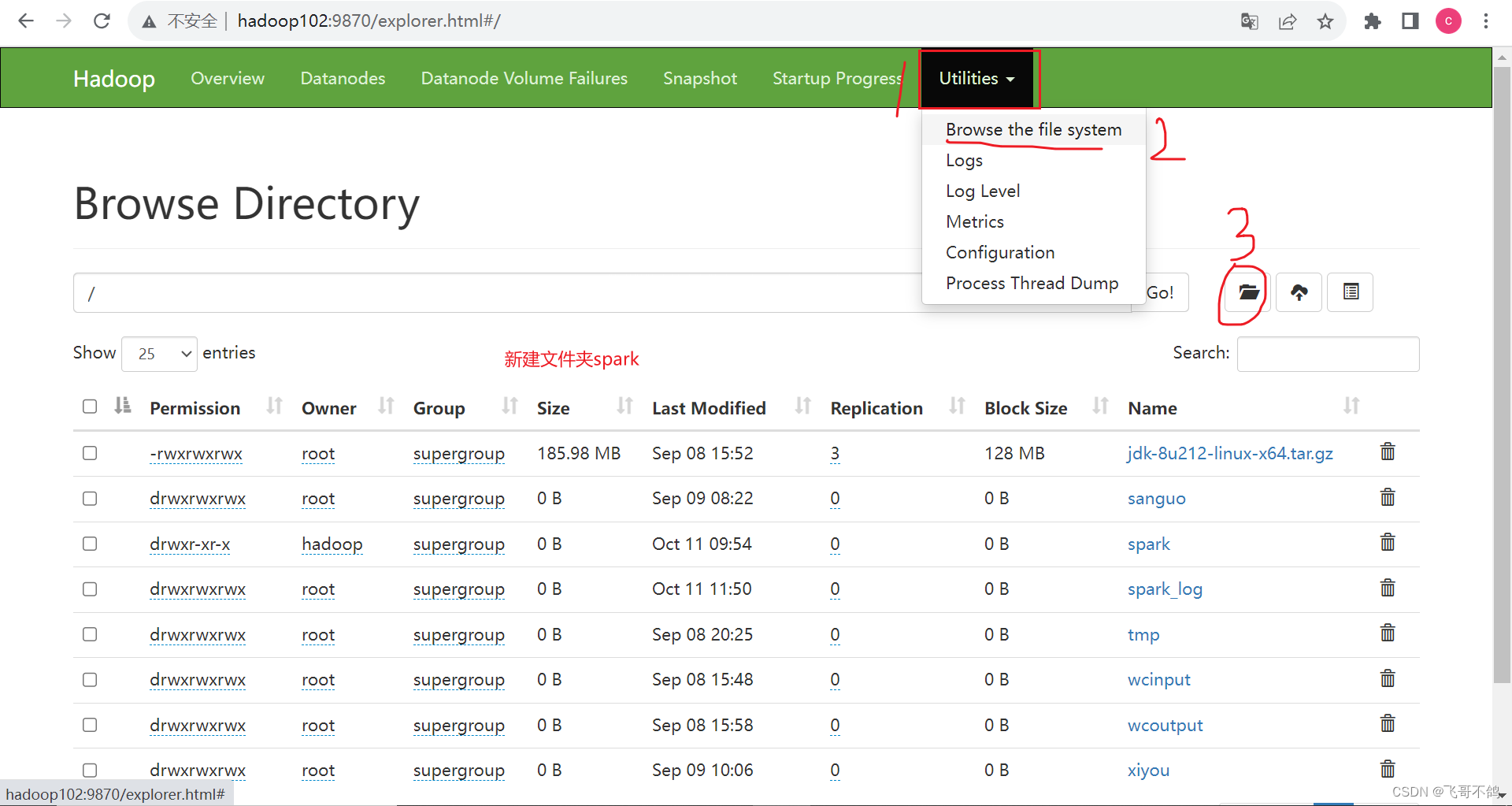
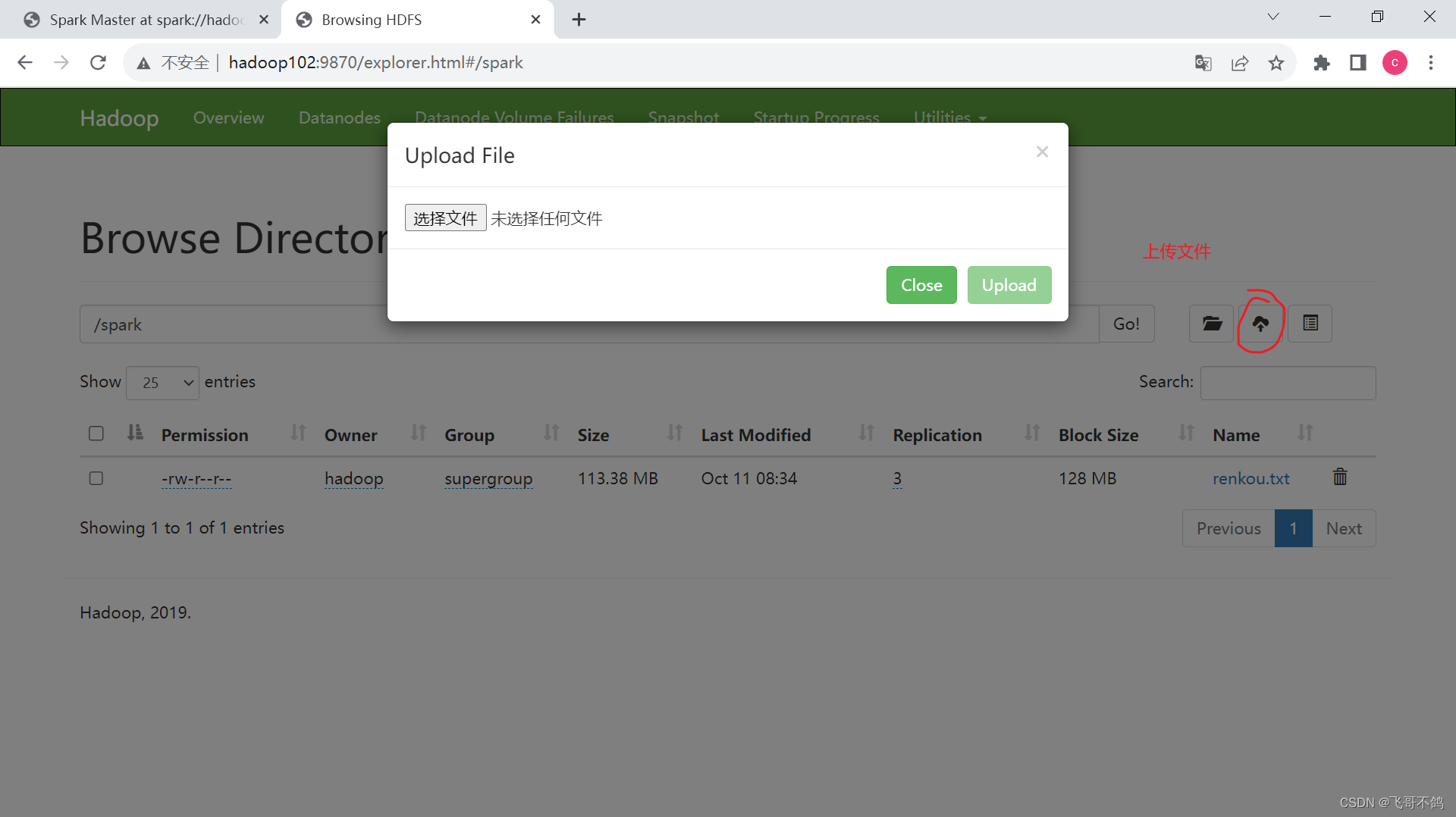
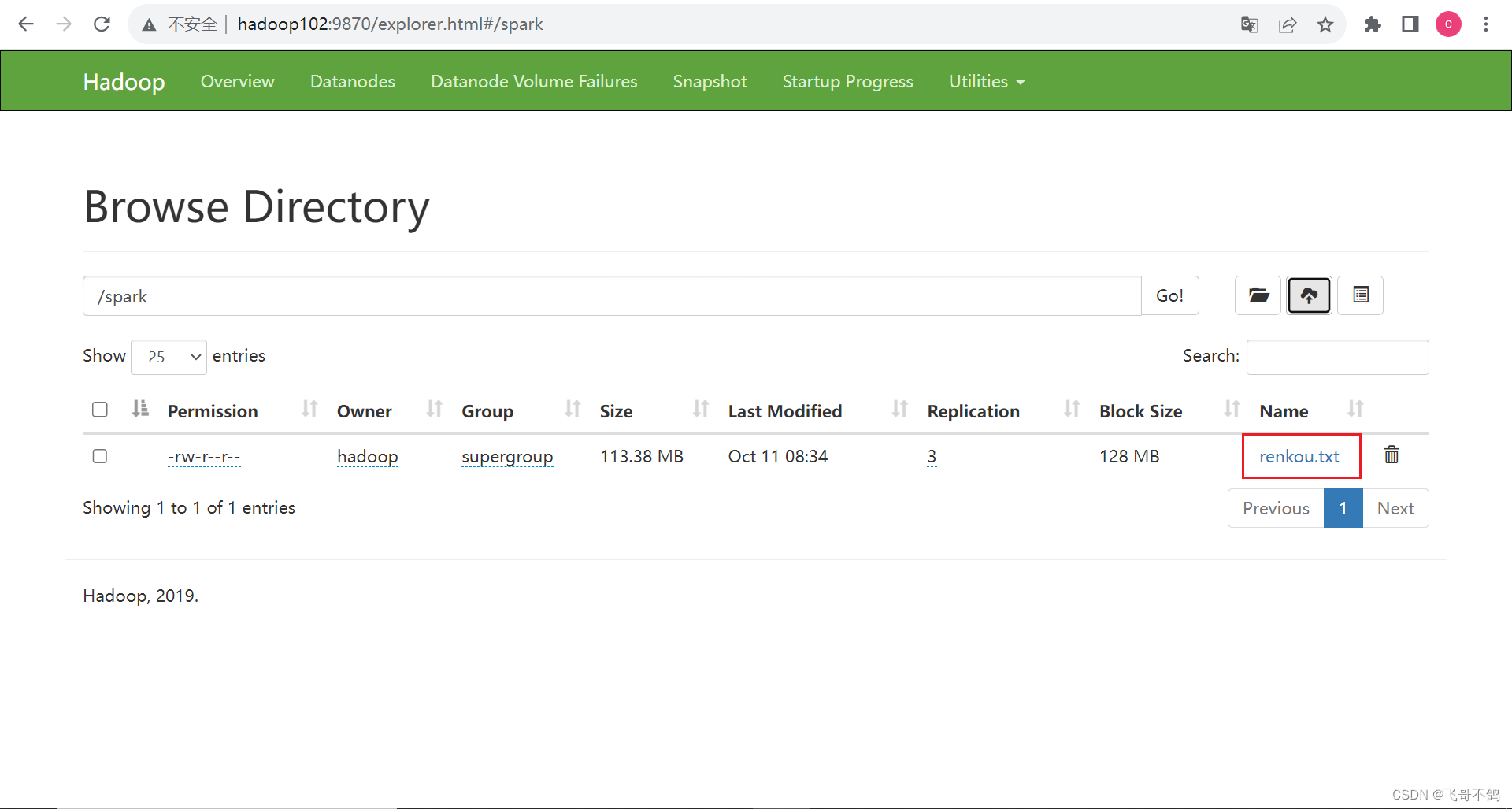
文件访问url: ‘hdfs://hadoop102:8020/spark/renkou.txt’
3. 上传文件时,可能出现的常见错误
在上传的过程中,可能会遇到各种报错,我这里整理好参考资料
- 解决hadoop Permission denied: user=dr.who, access=WRITE, inode=“/“:kfk:supergroup:drwxr-xr-x问题
- Name node is in safe mode
4. 编写spark文件
package com.xhf.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RenkouCal2_Cluster {
def main(args: Array[String]): Unit = {
// 设置配置, master记得输入你要提交的主节点地址,而不是local. 如果是local, 我的版本下能够运行, 但任务无法在UI界面上显示
val conf: SparkConf = new SparkConf().setAppName("renkou").setMaster("spark://hadoop102:7077")
// 连接spark
val sparkContext = new SparkContext(conf)
val filePath: String = "hdfs://hadoop102:8020/spark/renkou.txt";
// 读取文件 List<String>
val lines: RDD[String] = sparkContext.textFile(filePath)
val begin: Long = System.currentTimeMillis()
val value: RDD[Long] = lines.map(line => {
// String : "1 27"
line.split(" ")(1).toLong
});
// 计算 (把所有年龄累加 -> 除以个数 -> 平均年龄)
val sum: Long = value.reduce((x, y) => x + y)
println(sum / (1.0 * lines.count()))
println(System.currentTimeMillis() - begin)
// 终止spark
sparkContext.stop()
}
}
如果本地能够运行,通过maven打成jar包,上传运行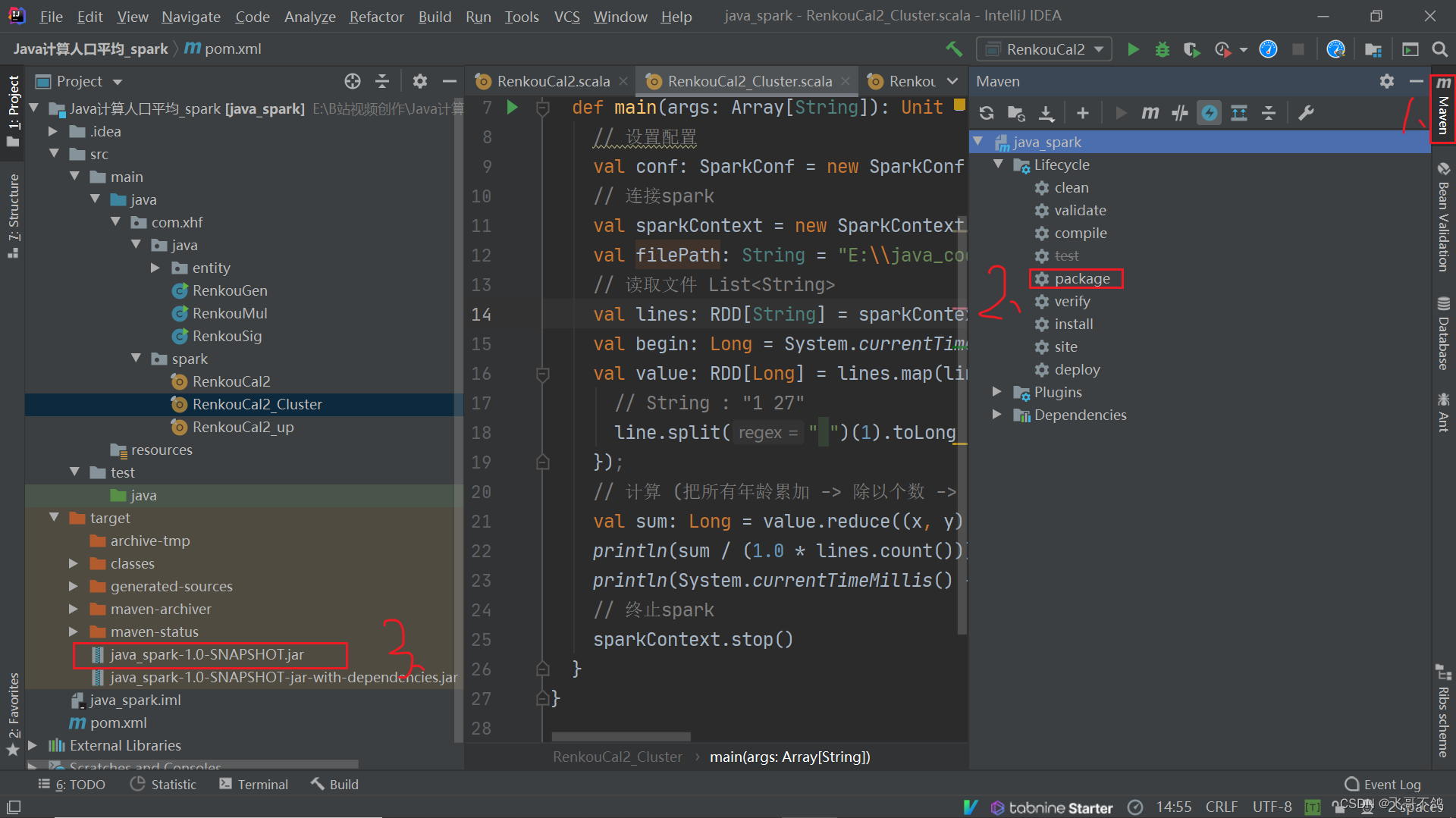
5. 上传集群
笔者采用xshell + xftp的方式进行jar包上传,上传至如下位置
6. 集群环境下提交任务
找到spark安装位置,进入bin目录
执行如下指令
./spark-submit \
--class com.xhf.spark.RenkouCal2 \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark_demo/java_spark-1.0-SNAPSHOT.jar
- –class 指定运行jar包具体的启动类,笔者运行的时RenkouCal2这个类
- –master 指定master节点的地址
- /export/servers/spark_demo/java_spark-1.0-SNAPSHOT.jar 指定jar包路径,这个由自己决定
其它参数见名知意,不在过多赘述
spark,启动!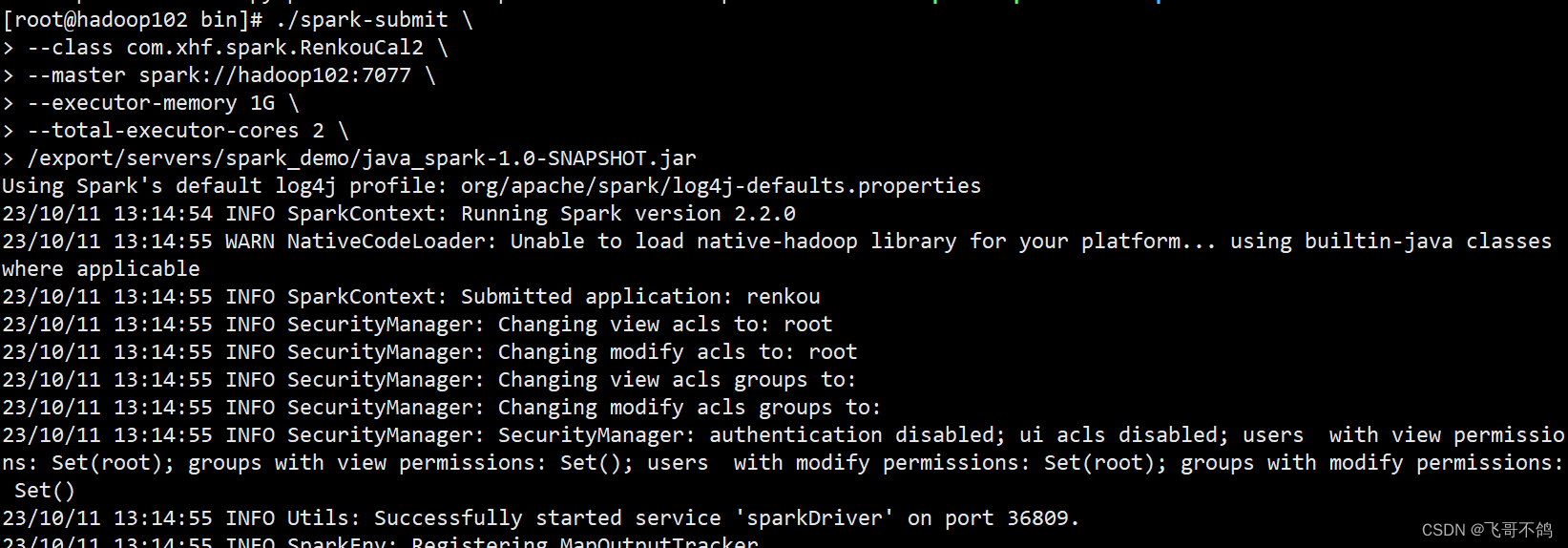

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)