Dify学习-19-EXCEL数据如何建立知识库+知识库的学习ING
Args:"""定义类,继承自类文档字符串说明这个类用于加载Excel文件这个类提供了从Excel文件(.xls和.xlsx)中提取数据并转换为文档列表的功能。处理两种Excel格式保留超链接信息跳过空行将每行数据转换为键值对格式的文档在元数据中保留源文件信息对于.xlsx文件使用openpyxl处理,可以获取更多单元格信息(如超链接);对于.xls文件则使用pandas的xlrd引擎处理。
文章目录
现在我的需求是EXCEL的内容进行导入
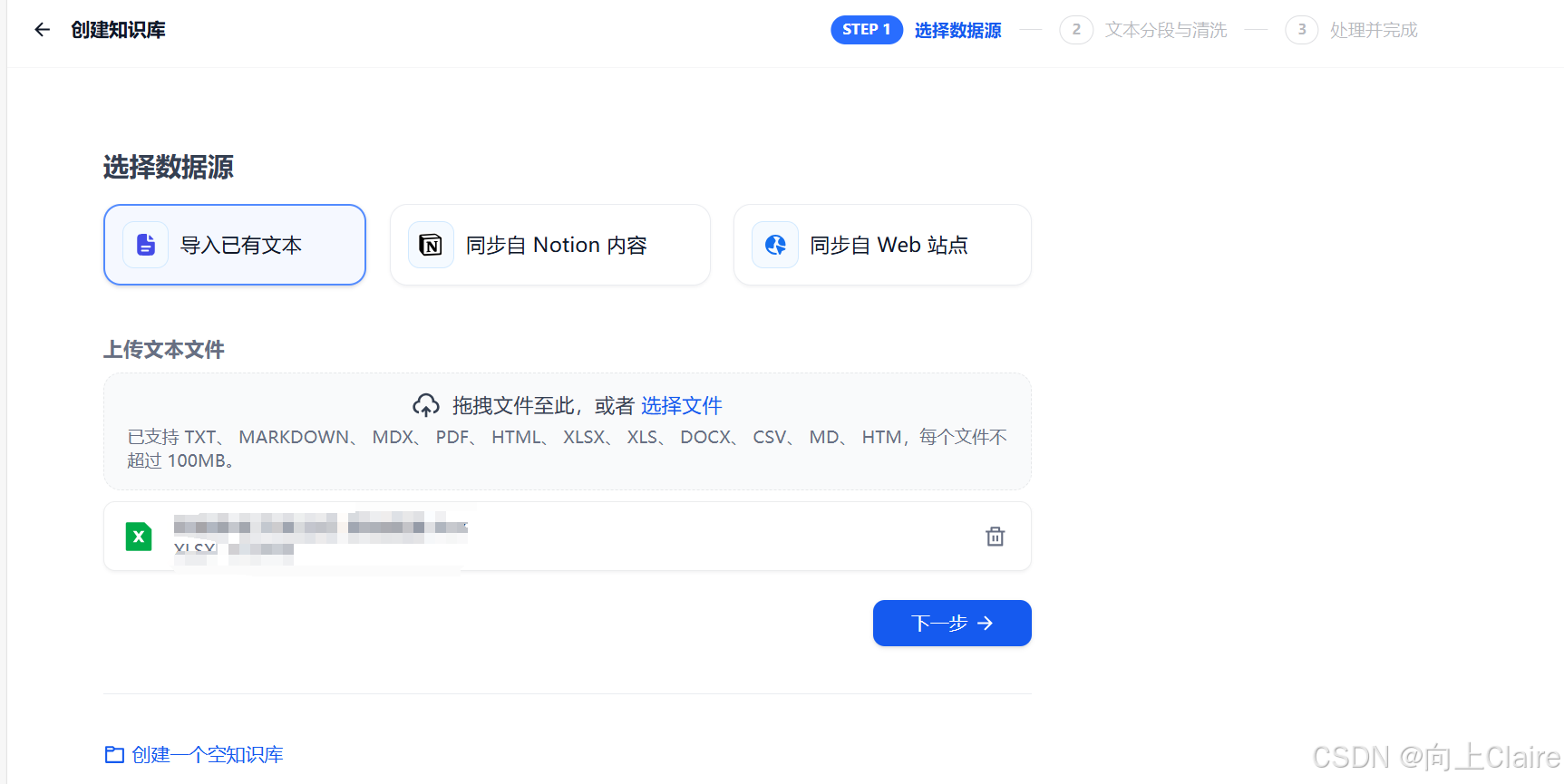
第一步:选择数据源
就是上传我需要导入的数据,比如我现在上传EXCEL
第二步:文本分段和清洗
分段是什么?
分段:文本长了,要分开存放才能存储
如何分段

Dify 提供了 “通用分段” 和 “父子分段” 两种分段模式,分别适应不同类型的文档结构和应用场景,满足不同的知识库检索和召回的效率与准确性要求。
Dify读取EXCEL,我如何让他按照每一行进行一个切块?
我选择的是父子分段模式
我需要是一行作为一段,把长度扩大了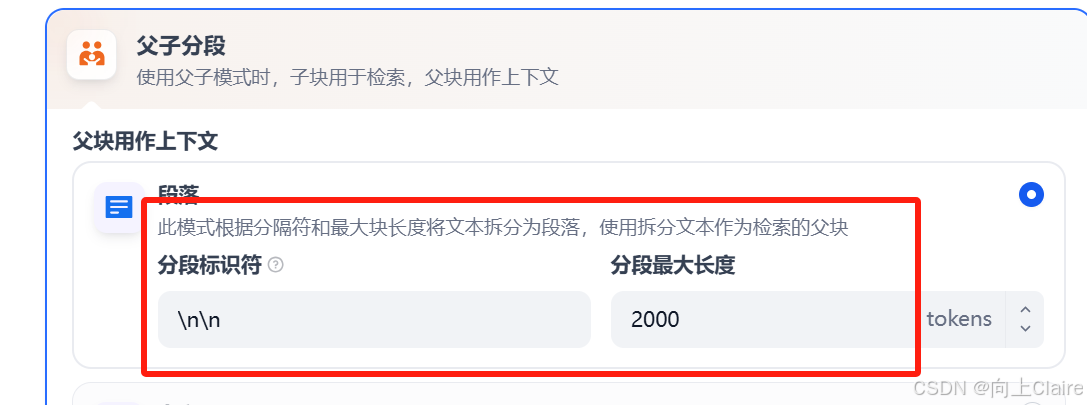
Dify的背后分块的逻辑是什么样子
我需要每个小的单元格是子块,但是他这个只是按长度分吗
我目前先做一个出来
再去进行代码块的分解进行修改
通用形式
父子块形式
子块会存在切割分割的问题

Dify知识库中遇到EXCEL的内部代码逻辑

感觉豆包解析的有点在瞎搞了
这是原始的代码
"""Abstract interface for document loader implementations."""
import os
from typing import Optional, cast
import pandas as pd
from openpyxl import load_workbook # type: ignore
from core.rag.extractor.extractor_base import BaseExtractor
from core.rag.models.document import Document
class ExcelExtractor(BaseExtractor):
"""Load Excel files.
Args:
file_path: Path to the file to load.
"""
def __init__(self, file_path: str, encoding: Optional[str] = None, autodetect_encoding: bool = False):
"""Initialize with file path."""
self._file_path = file_path
self._encoding = encoding
self._autodetect_encoding = autodetect_encoding
def extract(self) -> list[Document]:
"""Load from Excel file in xls or xlsx format using Pandas and openpyxl."""
documents = []
file_extension = os.path.splitext(self._file_path)[-1].lower()
if file_extension == ".xlsx":
wb = load_workbook(self._file_path, data_only=True)
for sheet_name in wb.sheetnames:
sheet = wb[sheet_name]
data = sheet.values
try:
cols = next(data)
except StopIteration:
continue
df = pd.DataFrame(data, columns=cols)
df.dropna(how="all", inplace=True)
for index, row in df.iterrows():
page_content = []
for col_index, (k, v) in enumerate(row.items()):
if pd.notna(v):
cell = sheet.cell(
row=cast(int, index) + 2, column=col_index + 1
) # +2 to account for header and 1-based index
if cell.hyperlink:
value = f"[{v}]({cell.hyperlink.target})"
page_content.append(f'"{k}":"{value}"')
else:
page_content.append(f'"{k}":"{v}"')
documents.append(
Document(page_content=";".join(page_content), metadata={"source": self._file_path})
)
elif file_extension == ".xls":
excel_file = pd.ExcelFile(self._file_path, engine="xlrd")
for excel_sheet_name in excel_file.sheet_names:
df = excel_file.parse(sheet_name=excel_sheet_name)
df.dropna(how="all", inplace=True)
for _, row in df.iterrows():
page_content = []
for k, v in row.items():
if pd.notna(v):
page_content.append(f'"{k}":"{v}"')
documents.append(
Document(page_content=";".join(page_content), metadata={"source": self._file_path})
)
else:
raise ValueError(f"Unsupported file extension: {file_extension}")
return documents
我这个EXCEL有很多工作簿,怎么感觉他都读取了出来
索引
正如搜索引擎通过高效的索引算法匹配与用户问题最相关的网页内容,索引方式是否合理将直接影响 LLM 对知识库内容的检索效率以及回答的准确性。
Dify的三种检索方式分别是:向量检索(基于语义相似度)、关键词检索(基于文本匹配)和混合检索(结合向量和关键词的优势),分别适用于不同的搜索场景和需求。
代码解析:ExcelExtractor 类
这是一个用于从Excel文件中提取数据的文档加载器实现。下面我将逐行解析代码:
1. 模块文档和导入
"""Abstract interface for document loader implementations."""
- 模块的文档字符串,说明这是一个文档加载器实现的抽象接口
import os
from typing import Optional, cast
import pandas as pd
from openpyxl import load_workbook # type: ignore
from core.rag.extractor.extractor_base import BaseExtractor
from core.rag.models.document import Document
- 导入必要的模块和类:
os:操作系统相关功能typing:类型提示相关pandas:数据处理库openpyxl:处理Excel文件- 从项目内部导入基类
BaseExtractor和Document模型
2. ExcelExtractor 类定义
class ExcelExtractor(BaseExtractor):
"""Load Excel files.
Args:
file_path: Path to the file to load.
"""
- 定义
ExcelExtractor类,继承自BaseExtractor - 类文档字符串说明这个类用于加载Excel文件
3. 初始化方法
def __init__(self, file_path: str, encoding: Optional[str] = None, autodetect_encoding: bool = False):
"""Initialize with file path."""
self._file_path = file_path
self._encoding = encoding
self._autodetect_encoding = autodetect_encoding
- 初始化方法,接收三个参数:
file_path:Excel文件路径encoding:可选的文件编码autodetect_encoding:是否自动检测编码
- 将参数保存为实例变量
4. extract 方法
def extract(self) -> list[Document]:
"""Load from Excel file in xls or xlsx format using Pandas and openpyxl."""
documents = []
file_extension = os.path.splitext(self._file_path)[-1].lower()
- 主要提取方法,返回
Document对象列表 - 初始化
documents列表用于存储结果 - 获取文件扩展名并转换为小写
处理.xlsx文件
if file_extension == ".xlsx":
wb = load_workbook(self._file_path, data_only=True)
for sheet_name in wb.sheetnames:
sheet = wb[sheet_name]
data = sheet.values
try:
cols = next(data)
except StopIteration:
continue
df = pd.DataFrame(data, columns=cols)
- 如果是.xlsx文件:
- 使用
openpyxl加载工作簿 - 遍历每个工作表
- 获取工作表数据
- 尝试获取第一行作为列名
- 如果没有数据则跳过该工作表
- 创建Pandas DataFrame
- 使用
df.dropna(how="all", inplace=True)
for index, row in df.iterrows():
page_content = []
for col_index, (k, v) in enumerate(row.items()):
if pd.notna(v):
cell = sheet.cell(
row=cast(int, index) + 2, column=col_index + 1
) # +2 to account for header and 1-based index
if cell.hyperlink:
value = f"[{v}]({cell.hyperlink.target})"
page_content.append(f'"{k}":"{value}"')
else:
page_content.append(f'"{k}":"{v}"')
documents.append(
Document(page_content=";".join(page_content), metadata={"source": self._file_path})
)
- 处理数据:
- 删除全为空的行
- 遍历DataFrame的每一行
- 构建页面内容:
- 检查单元格是否有超链接,如果有则创建Markdown格式链接
- 否则直接添加键值对
- 将处理后的内容创建为
Document对象并添加到结果列表
处理.xls文件
elif file_extension == ".xls":
excel_file = pd.ExcelFile(self._file_path, engine="xlrd")
for excel_sheet_name in excel_file.sheet_names:
df = excel_file.parse(sheet_name=excel_sheet_name)
df.dropna(how="all", inplace=True)
for _, row in df.iterrows():
page_content = []
for k, v in row.items():
if pd.notna(v):
page_content.append(f'"{k}":"{v}"')
documents.append(
Document(page_content=";".join(page_content), metadata={"source": self._file_path})
)
- 如果是.xls文件:
- 使用
xlrd引擎加载Excel文件 - 遍历每个工作表
- 解析工作表数据为DataFrame
- 删除全为空的行
- 遍历每一行构建页面内容并创建
Document对象
- 使用
不支持的文件格式
else:
raise ValueError(f"Unsupported file extension: {file_extension}")
return documents
- 如果文件扩展名不是.xls或.xlsx,抛出异常
- 最后返回提取的文档列表
总结
这个类提供了从Excel文件(.xls和.xlsx)中提取数据并转换为文档列表的功能。它能够:
- 处理两种Excel格式
- 保留超链接信息
- 跳过空行
- 将每行数据转换为键值对格式的文档
- 在元数据中保留源文件信息
对于.xlsx文件使用openpyxl处理,可以获取更多单元格信息(如超链接);对于.xls文件则使用pandas的xlrd引擎处理。
如何使用知识库
在聊天助手里,直接选择知识库就可以
之后就是CHATFLOW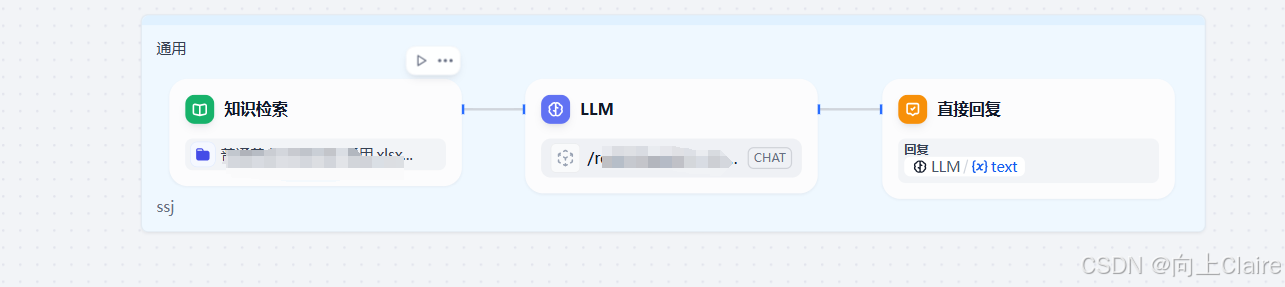
参考内容:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)