Whisper.cpp + GPU 加速全攻略:Mac M 芯片高效转录音频教程
Whisper.cpp 简介Whisper是 OpenAI 开源的语音识别模型,支持多语言转写,在降噪和语音识别方面表现出色。是该项目的C/C++ 版本,可以在本地设备上高效运行,无需 Python 依赖,非常适合轻量级部署。Mac M 芯片的 GPU 加速Apple M1/M2/M3 芯片内置高性能 GPU和,但默认情况下 Whisper.cpp不会自动利用 GPU。我们可以使用CoreML 工
内容预告
本文将手把手教你如何利用 GPU 加速,在 Mac M 芯片上使用 Whisper 进行音频转文字,大幅提升转录效率。
本教程涵盖:
- Whisper.cpp 简介:为什么它适用于本地语音转写?
- Mac M 芯片的 GPU 加速:如何使用 CoreML 提升处理速度?
- 完整搭建流程:环境准备、项目编译、模型下载、音频格式转换等。
- 实战优化技巧:批量转换、手动下载模型、避免常见问题等。
为爱发电,如果对你有帮助,请不吝 点赞 和 关注,谢谢 😁
1. 背景介绍
Whisper.cpp 简介
Whisper 是 OpenAI 开源的语音识别模型,支持多语言转写,在降噪和语音识别方面表现出色。whisper.cpp 是该项目的 C/C++ 版本,可以在本地设备上高效运行,无需 Python 依赖,非常适合 轻量级部署。
Mac M 芯片的 GPU 加速
Apple M1/M2/M3 芯片内置 高性能 GPU 和 Neural Engine,但默认情况下 Whisper.cpp 不会自动利用 GPU。
我们可以使用 CoreML 工具链 将 Whisper 模型转换为 CoreML 格式,从而大幅加快语音转写速度。
2. 环境准备
2.1 安装 Xcode 及命令行工具
首先,确保你已安装 Xcode 并配置好 Command Line Tools:
xcode-select --install
如果已安装,可以通过以下命令检查:
xcode-select -p
2.2 安装 Homebrew(推荐)
Homebrew 是 macOS 上的包管理工具,可用于安装必要的依赖:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install cmake ffmpeg
3. 下载 Whisper.cpp 并获取模型
3.1 克隆项目代码
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
3.2 下载模型文件
Whisper 提供多个不同规模的模型:
| Model | 磁盘占用 | 内存占用(约) |
|---|---|---|
| tiny | 75 MB | 273 MB |
| base | 142 MB | 388 MB |
| small | 466 MB | 852 MB |
| medium | 1.5 GB | 2.1 GB |
| large | 2.9 GB | 3.9 GB |
下载方式:
sh ./models/download-ggml-model.sh large-v3-turbo
如果遇到 下载速度慢,可以手动下载:
curl -L -o models/ggml-large-v3-turbo.bin https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-large-v3-turbo.bin
4. 配置 GPU 加速(Mac M 芯片)
4.1 安装 Python 及 Conda
推荐使用 Miniforge 作为 Conda 发行版:
brew install miniforge
conda create -n whisper_env python=3.10 -y
conda activate whisper_env
4.2 安装依赖
pip install torch==2.5.0 --extra-index-url https://download.pytorch.org/whl/cpu
pip install openai-whisper coremltools
pip install --no-deps ane-transformers
验证是否成功安装:
python -c "import torch; print(torch.__version__)"
python -c "import whisper; print(whisper.__version__)"
5. 模型转换为 CoreML 格式
运行以下命令,将 Whisper 模型转换为 CoreML 格式 以实现 GPU 加速:
./models/generate-coreml-model.sh large-v3-turbo
如果报错 coremlc: error: Model does not exist,请手动下载:
curl -L -o models/coreml-encoder-large-v3-turbo.mlpackage https://huggingface.co/ggerganov/whisper.cpp/resolve/main/coreml-encoder-large-v3-turbo.mlpackage
放在 whisper.cpp/models/ 文件夹下面
6. 编译 Whisper.cpp
6.1 使用 Makefile 构建
make clean
WHISPER_COREML=1 make -j
6.2 使用 CMake 构建
mkdir build && cd build
cmake -DWHISPER_COREML=1 ..
make -j
构建成功后,你会看到如下输出: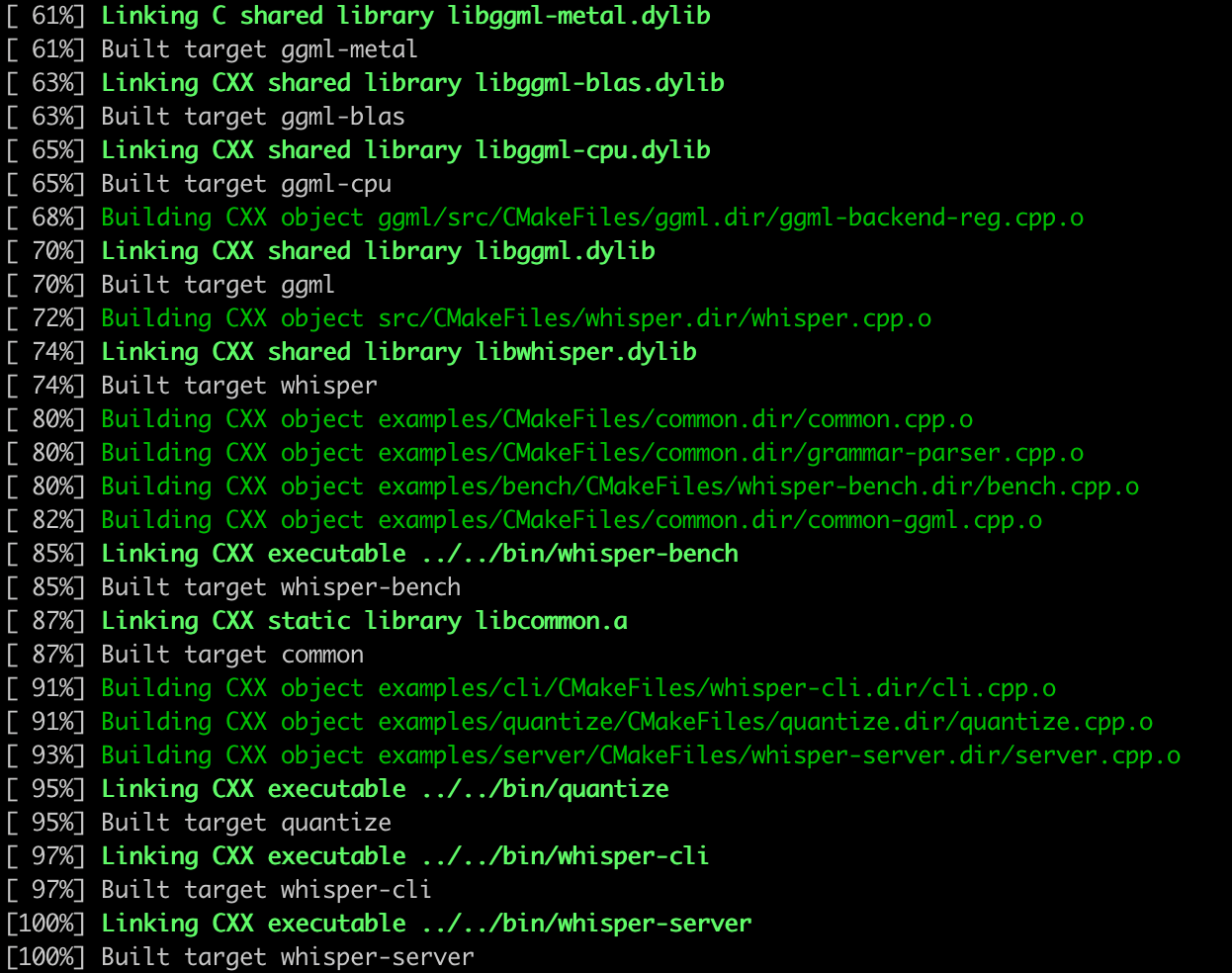
7. 运行 Whisper 转录程序
以 Whisper Large V3 turbo 为例,确保输入的音频文件是 WAV 格式:
./build/bin/whisper-cli -m models/ggml-large-v3-turbo.bin -f samples/jfk.wav
运行时,你会看到 GPU 资源正在被使用: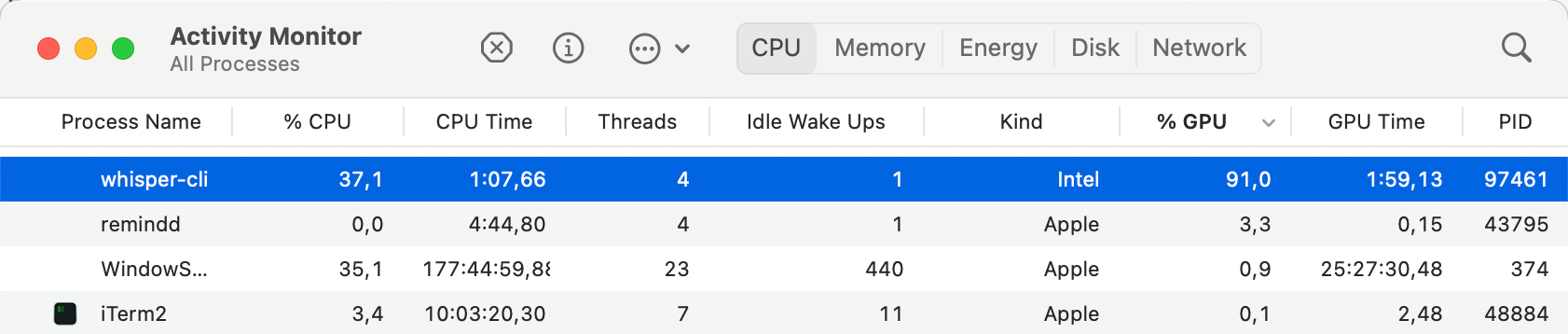
8. 语音格式转换(可选)
如果你的音频文件是 .mp3,可以使用 FFmpeg 转换:
ffmpeg -i steve.mp3 -ar 16000 -ac 1 -c:a pcm_s16le steve.wav
批量转换
for file in *.mp3; do ffmpeg -i "$file" -ar 16000 -ac 1 -c:a pcm_s16le "${file%.mp3}.wav"; done
如果你想让 Whisper 在 Mac 上发挥最大性能,这篇教程能帮到你!🔥
不定期更新专业知识和有趣的东西,欢迎反馈、点赞、加星
您的鼓励和支持是我坚持创作的最大动力!ღ( ´・ᴗ・` )

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)