11-聊天机器人项目准备
学习NLP,了解聊天机器人,聊天机器人项目准备
·
目录
0.BOT的认识

我的上篇文章链接: (6条消息) 10-走进聊天机器人_我行我素,向往自由的博客-CSDN博客
1.需求分析和流程介绍

1.1 需求分析

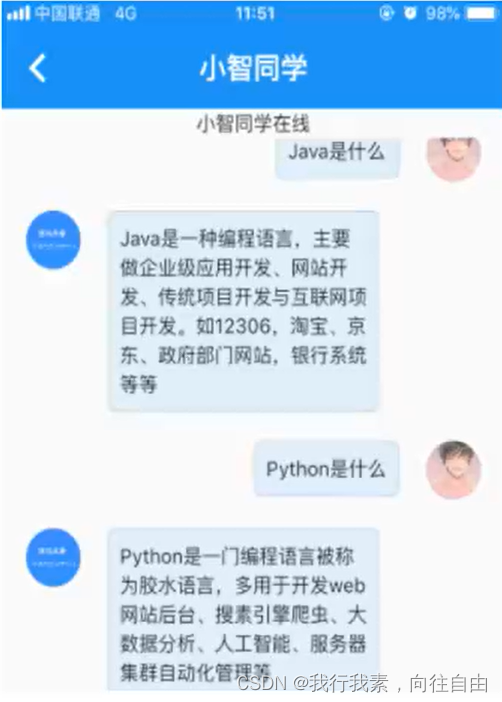
1.2 效果演示
1.3 实现流程
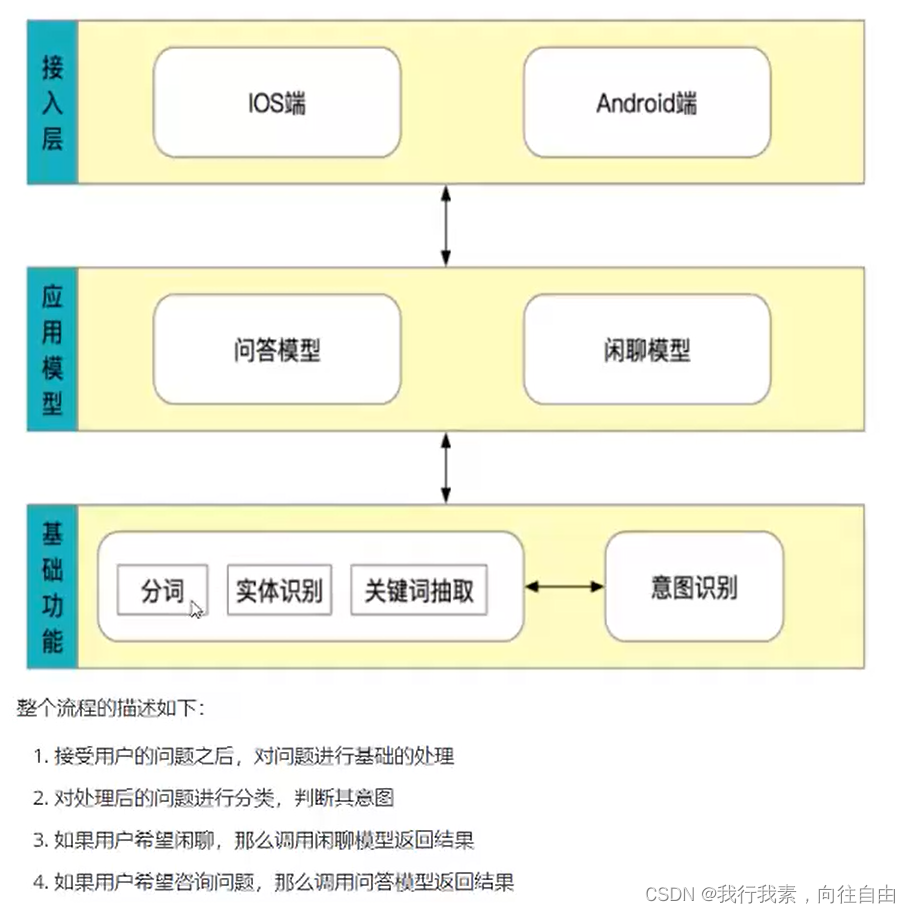
1.3.1 整体架构
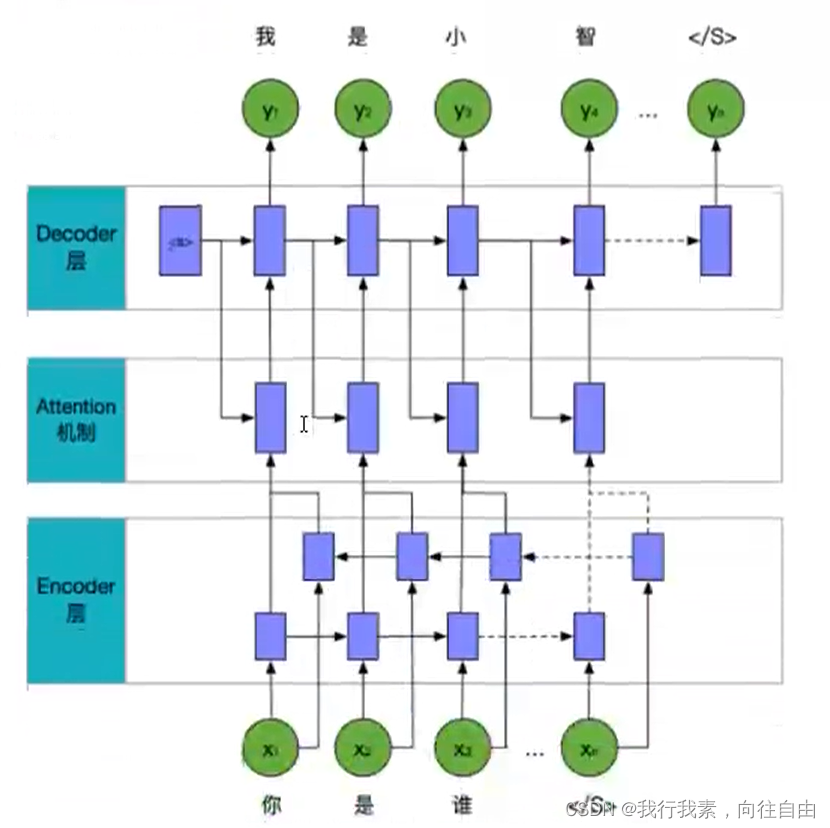
1.3.2 闲聊模型

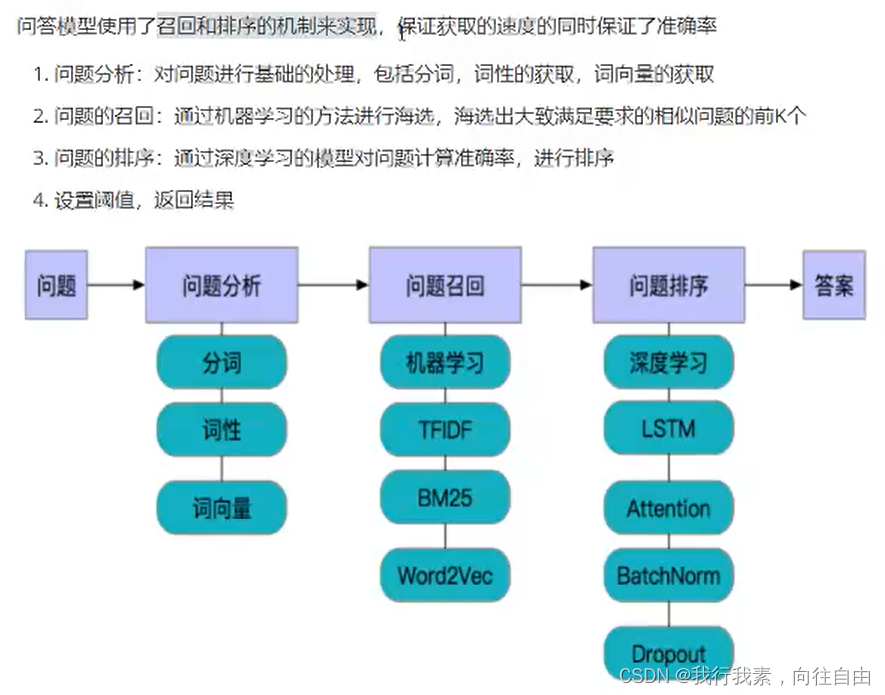
1.3.3 问答模型
2.环境准备

2.1 Anaconda环境准备

2.2 fasttext安装
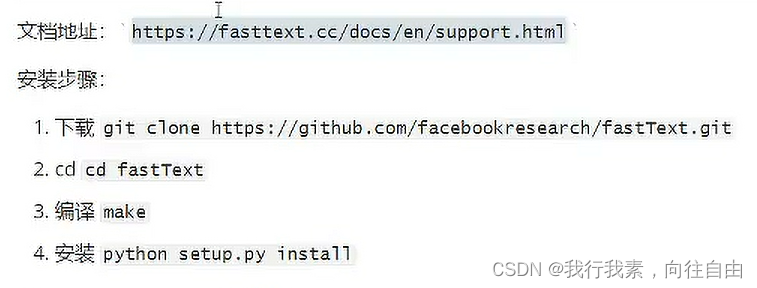
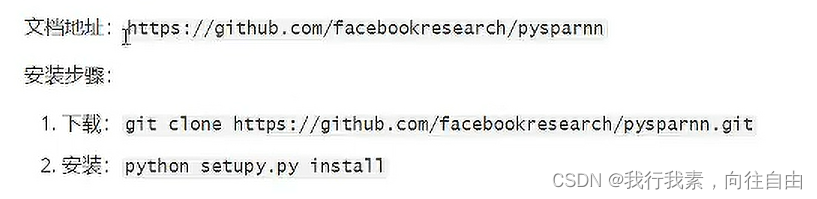
2.3 pysparnn安装
3.语料准备

3.1 分词词典

3.1.1 词典来源

3.1.2 词典处理

3.1.3 对多个词典文件内容进行合并
下载使用不同平台的多个词典之后,把所有的txt文件合并到一起供之后使用。
3.2 准备停用词
3.2.1 什么是停用词
对句子进行分词之后,句子中不重要的词。
3.2.2 停用词的准备
![]()
3.2.3 手动筛选和合并

3.3 问答对的准备
3.3.1 现有问答对的样式


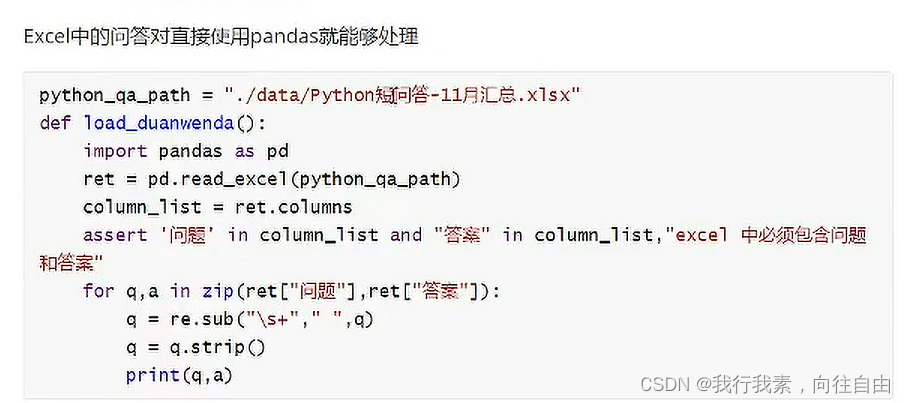
3.3.2 excel中问答对的处理
3.4 相似问答对的采集
3.4.1 采集相似问答对的目的
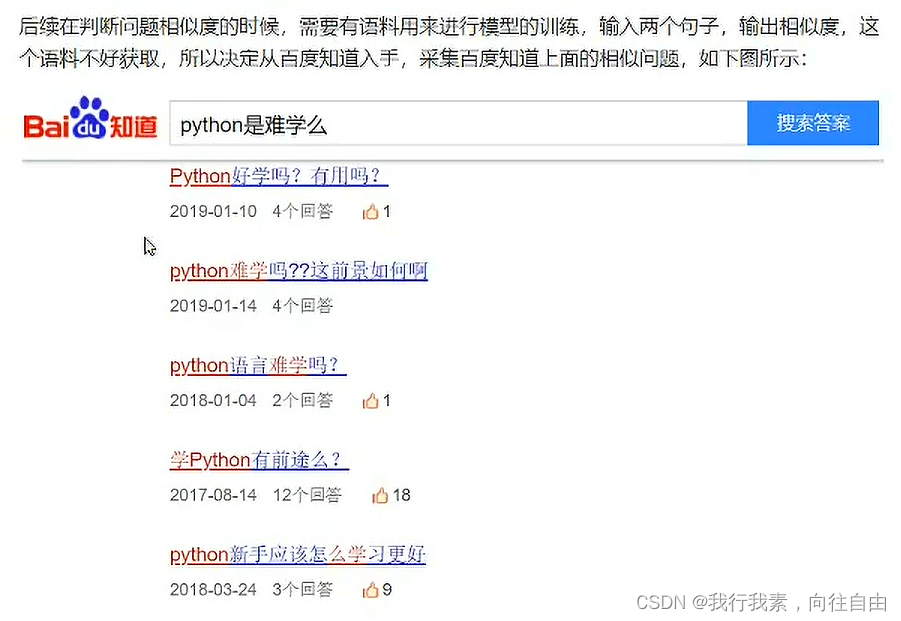
上面采集的数据套存在部分噪声,部分问题搜索到的结果语义上并不是太相似。
3.4.2 手动构造数据
根据前面的问答对的内容,把问题大致分为了若干类型,对不同类型的问题设计模板,然后构造问题,问题模块如下:
4.文本分词

4.1 准备词典和停用词
4.1.1 准备词典

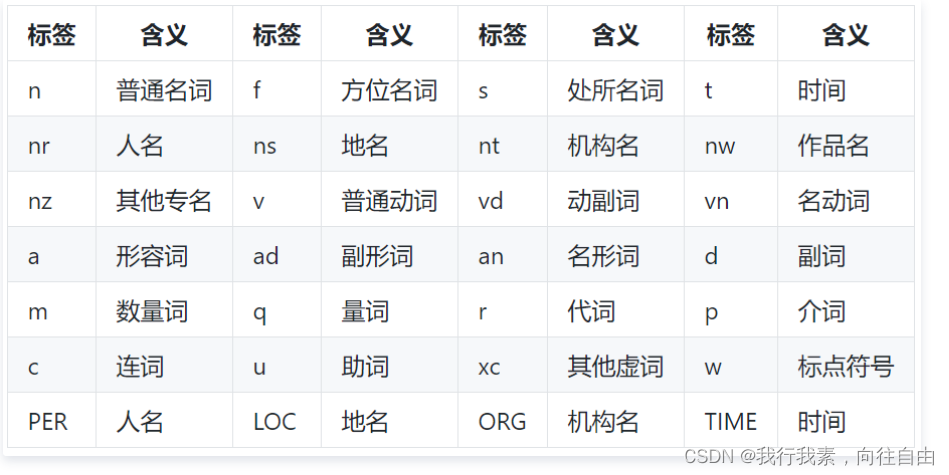
4.1.2 准备停用词

4.2 准备按照单个字切分句子的方法

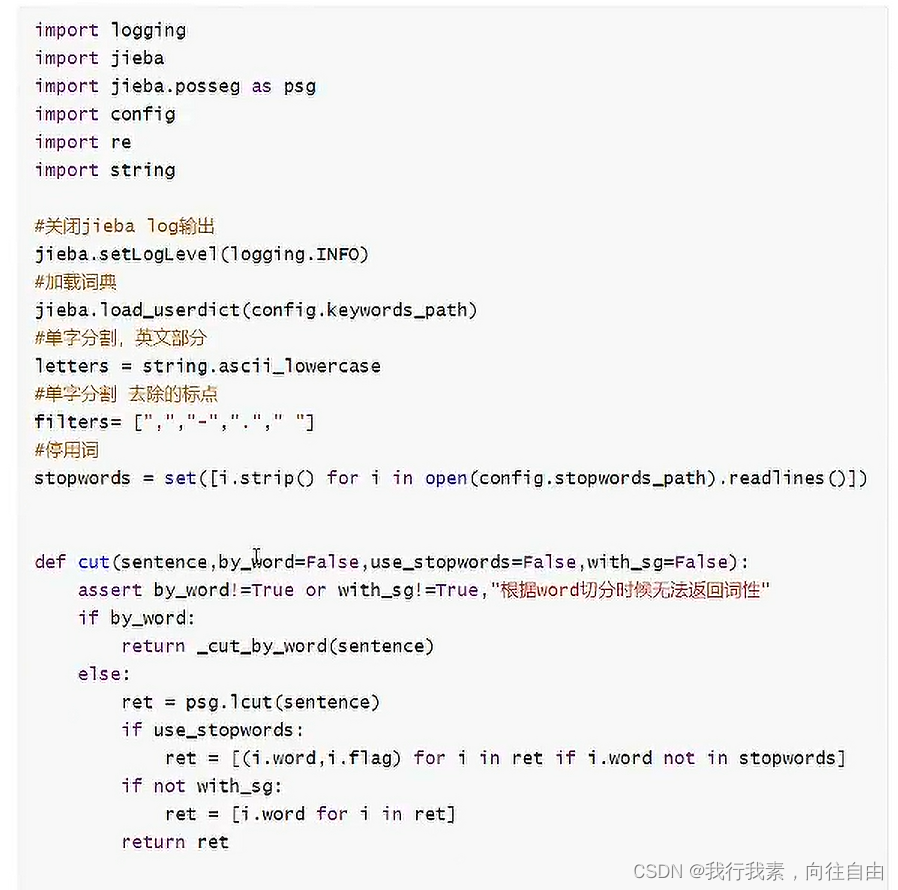
4.3 完成分词方法的封装
lib下创建cut_sentence.py文件,完成分词方法的构建:


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)