【计算机视觉|卷积注意力机制】9种即插即用涨点模块分享!涵盖SENet极其变式!附部分代码!
SENet通过通道注意力机制(Squeeze-and-Excitation模块)来自适应地调整各通道特征响应,增强了网络的表示能力。
SENet极其变式,9种即插即用涨点模块分享!
1. SENet - 挤压激励网络
论文名称:Squeeze-and-Excitation Networks
简介:SENet通过通道注意力机制(Squeeze-and-Excitation模块)来自适应地调整各通道特征响应,增强了网络的表示能力。
核心原理:SENet通过建模通道之间的依赖关系,并根据这些关系自适应地对每个通道的特征进行重新校准,从而提高了网络的表现力。具体如下:sqneeze:全局平均池化,压缩输入张量,Excitation:两层全连接+sigmoid限制【0,1】,将权重作为结果与U相乘,得到各个通道的权重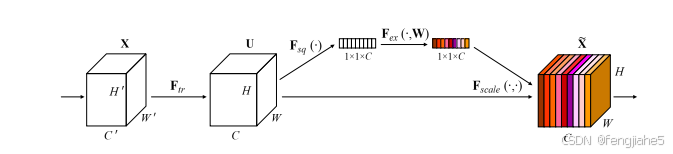
2. BAM - 瓶颈注意力模块
论文名称:BAM: Bottleneck Attention Module
简介:这项工作中,作者把重心放在了Attention对于一般深度神经网络的影响上,然后提出了一个简单但是有效的Attention模型—BAM,它可以结合到任何前向传播卷积神经网络中,BAM模型通过两个分离的路径 channel和spatial, 得到一个Attention Map。在神经网络中,BAM常常用在模型的各个模块的交界处,因此被称为“瓶颈注意模块”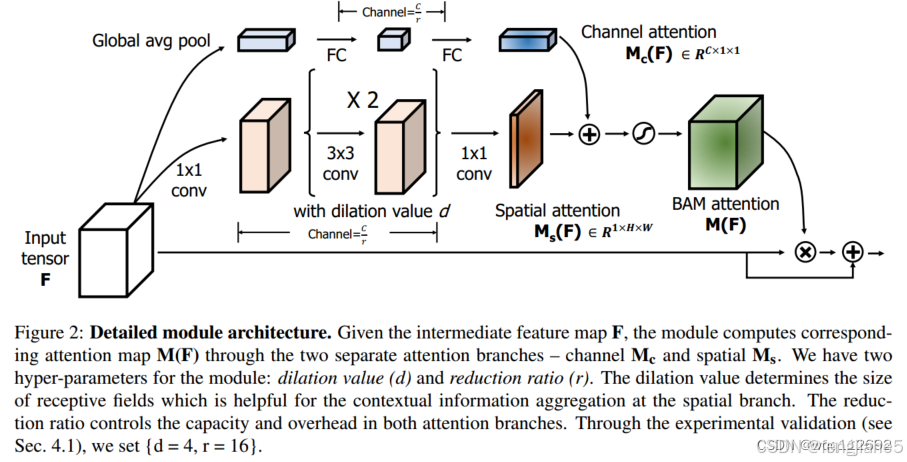
核心原理:通过将通道注意力与空间注意力结合,BAM在瓶颈结构内显著增强了特征图的表达,提升了模型的性能。
代码:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class Flatten(nn.Module):
def forward(self,x):
return x.view(x.shape[0],-1)
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
gate_channels=[channel]
gate_channels+=[channel//reduction]*num_layers
gate_channels+=[channel]
self.ca=nn.Sequential()
self.ca.add_module('flatten',Flatten())
for i in range(len(gate_channels)-2):
self.ca.add_module('fc%d'%i,nn.Linear(gate_channels[i],gate_channels[i+1]))
self.ca.add_module('bn%d'%i,nn.BatchNorm1d(gate_channels[i+1]))
self.ca.add_module('relu%d'%i,nn.ReLU())
self.ca.add_module('last_fc',nn.Linear(gate_channels[-2],gate_channels[-1]))
def forward(self, x) :
res=self.avgpool(x)
res=self.ca(res)
res=res.unsqueeze(-1).unsqueeze(-1).expand_as(x)
return res
class SpatialAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3,dia_val=2):
super().__init__()
self.sa=nn.Sequential()
self.sa.add_module('conv_reduce1',nn.Conv2d(kernel_size=1,in_channels=channel,out_channels=channel//reduction))
self.sa.add_module('bn_reduce1',nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_reduce1',nn.ReLU())
for i in range(num_layers):
self.sa.add_module('conv_%d'%i,nn.Conv2d(kernel_size=3,in_channels=channel//reduction,out_channels=channel//reduction,padding=1,dilation=dia_val))
self.sa.add_module('bn_%d'%i,nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_%d'%i,nn.ReLU())
self.sa.add_module('last_conv',nn.Conv2d(channel//reduction,1,kernel_size=1))
def forward(self, x) :
res=self.sa(x)
res=res.expand_as(x)
return res
class BAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,dia_val=2):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(channel=channel,reduction=reduction,dia_val=dia_val)
self.sigmoid=nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
sa_out=self.sa(x)
ca_out=self.ca(x)
weight=self.sigmoid(sa_out+ca_out)
out=(1+weight)*x
return out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
og.csdnimg.cn/direct/dc08ef816bf24308a29a0134f42d3bea.png)
3. CBAM - 卷积块注意力模块
论文名称:CBAM: Convolutional Block Attention Module
简介:CBAM( Convolutional Block Attention Module )是一种轻量级注意力模块的提出于2018年,它可以在空间维度和通道维度上进行Attention操作。论文在Resnet和MobileNet上加入CBAM模块进行对比,并针对两个注意力模块应用的先后进行实验,同时进行CAM可视化,可以看到Attention更关注目标物体。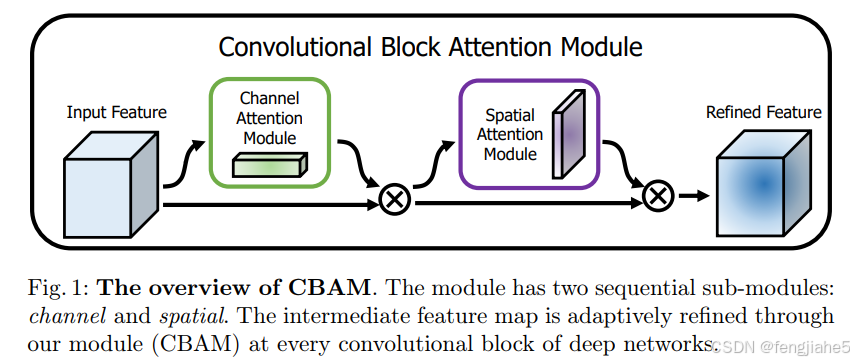
核心原理:通过按顺序应用通道注意力和空间注意力,CBAM强化了特征图中关键信息的表达,尤其在捕捉空间和通道层面的依赖关系时表现出色。
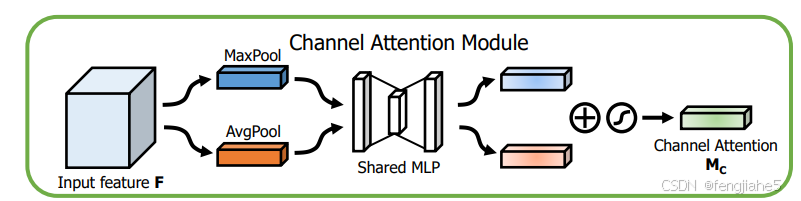
图解:将输入的feature map经过两个并行的MaxPool层和AvgPool层,将特征图从CHW变为C11的大小,然后经过Share MLP模块,在该模块中,它先将通道数压缩为原来的1/r(Reduction,减少率)倍,再扩张到原通道数,经过ReLU激活函数得到两个激活后的结果。将这两个输出结果进行逐元素相加,再通过一个sigmoid激活函数得到Channel Attention的输出结果,再将这个输出结果乘原图,变回CHW的大小。
本声明。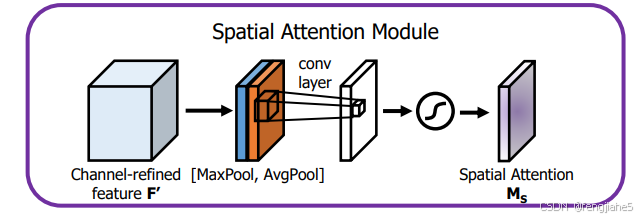
图解:将Channel Attention的输出结果通过最大池化和平均池化得到两个1HW的特征图,然后经过Concat操作对两个特征图进行拼接,通过77卷积变为1通道的特征图(实验证明77效果比33好),再经过一个sigmoid得到Spatial Attention的特征图,最后将输出结果乘原图变回CH*W大小。
代码:import torch
import torch.nn as nn
class CBAMLayer(nn.Module):
def init(self, channel, reduction=16, spatial_kernel=7):
super(CBAMLayer, self).init()
# channel attention 压缩H,W为1
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# shared MLP
self.mlp = nn.Sequential(
# Conv2d比Linear方便操作
# nn.Linear(channel, channel // reduction, bias=False)
nn.Conv2d(channel, channel // reduction, 1, bias=False),
# inplace=True直接替换,节省内存
nn.ReLU(inplace=True),
# nn.Linear(channel // reduction, channel,bias=False)
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
# spatial attention
self.conv = nn.Conv2d(2, 1, kernel_size=spatial_kernel,
padding=spatial_kernel // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.conv(torch.cat([max_out, avg_out], dim=1)))
x = spatial_out * x
return x
x = torch.randn(1,1024,32,32)
net = CBAMLayer(1024)
y = net.forward(x)
print(y.shape)
4. ECANet - 高效通道注意力网络
论文名称:ECANet: Efficient Channel Attention for Visual Recognition
简介:ECANet通过使用1D卷积替代全局平均池化,改进了通道注意力机制,减少了计算开销。 ECA事实上是SENET的改进版,它去除了原来SENET中的全连接层,换成了11的卷积核进行处理,使得模型参数变小,变得更加轻量级,因为ECA的作者认为卷积具有良好的跨通道信息捕捉能力,因此捕捉所有通道的信息是没必要的,因此取消了全连接层,换成了11的卷积。
核心原理:ECANet优化了传统的通道注意力机制,通过更高效的1D卷积操作,捕捉到通道间的依赖关系,且计算量更小。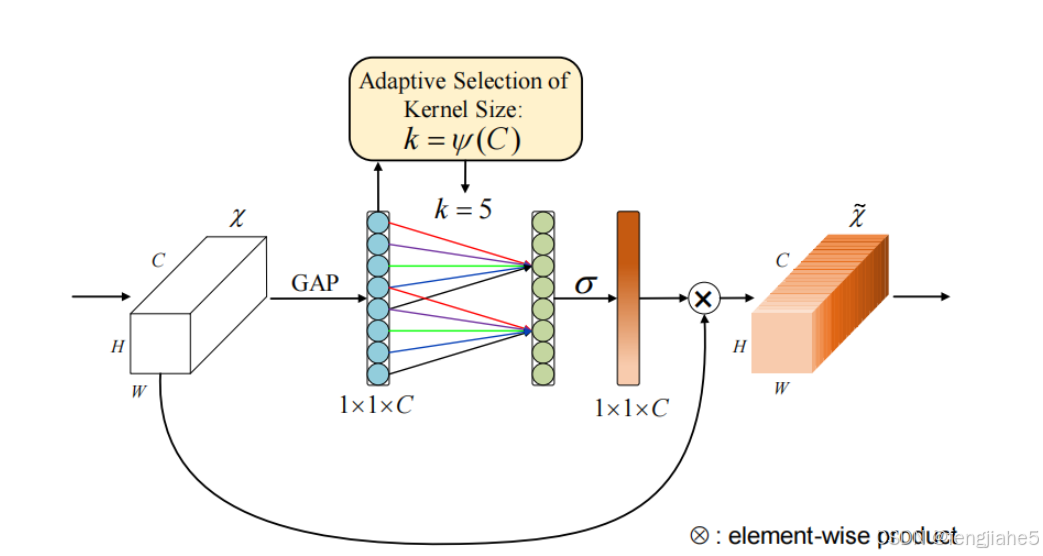
5. GCNet - 全球上下文网络
论文名称:GCNet: Global Context Networks
简介:GCNet通过自注意力机制引入全局上下文建模,增强了网络对全局依赖关系的捕捉。
核心原理:GCNet专注于通过全局上下文建模,替代了传统的局部特征提取,极大地提升了全局特征捕获能力。
6. FCA-Net -多谱信道注意方法
论文名称:FcaNet: Frequency Channel Attention Networks
简介: FcaNet是一种新的通道注意力网络,通过离散余弦变换(DCT)来解决通道表示的压缩问题。它证明了全局平均池(GAP)是DCT的特例,从而提出在频域中扩展通道注意力。FcaNet包括多光谱通道注意力模块,通过选择不同频率分量来捕获更多信息。
核心原理:证明了传统GAP(全局平均化池)是DCT(离散余弦变换)的特例。提出了三种频率分量选择标准以及建议的多光谱信道注意力框架,以实现FcaNet。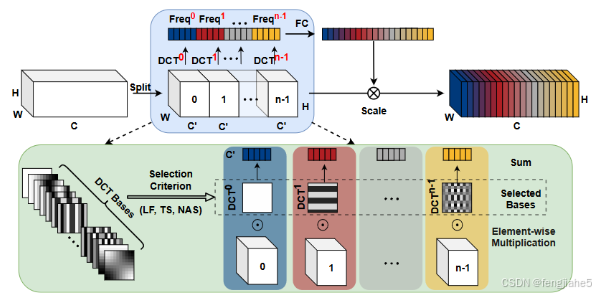
7. DANet - 双重注意力网络
论文名称:Dual Attention Network for Scene Segmentation
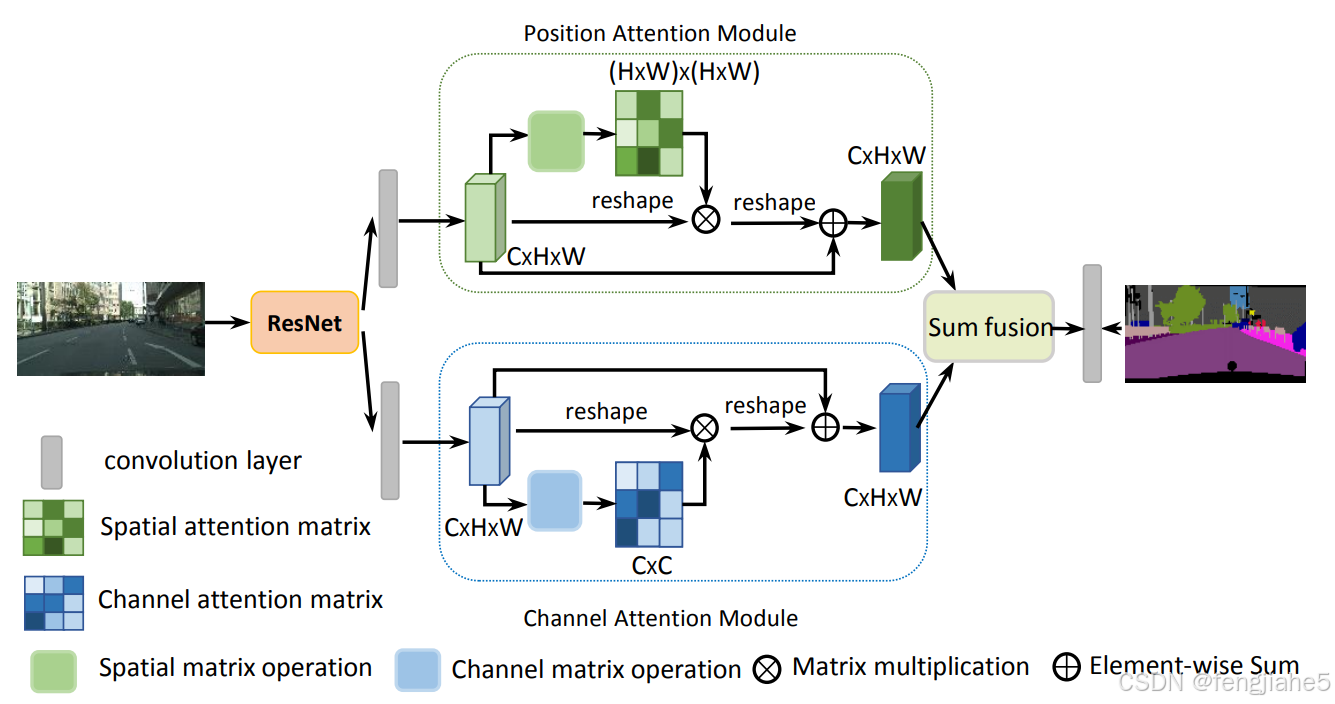
简介:DANet采用了两个独立的注意力模块:一个用于位置注意力(空间),一个用于通道注意力。两者相加后续输入
核心原理:在本文中,我们通过基于自注意机制捕捉丰富的上下文依赖来解决场景分割任务。与以往通过多尺度特征融合来捕捉上下文的方法不同,我们提出了一种双重注意力网络(DANet),以自适应地将局部特征与全局依赖性相结合。具体而言,我们在扩张的FCN之上附加了两种类型的注意力模块,分别对空间和通道维度中的语义依赖关系进行建模。位置注意力模块通过对所有位置的特征进行加权求和,选择性地聚合每个位置的特征。无论距离如何,相似的特征都会相互关联。同时,通道注意力模块通过整合所有通道图像中的相关特征,选择性地强调相互依赖的通道图像。我们将两个注意力模块的输出相加,进一步改善特征表示,从而为更精确的分割结果做出贡献。我们在三个具有挑战性的场景分割数据集上取得了最新的分割性能,即Cityscapes,PASCAL Context和COCO Stuff数据集。特别是,在不使用粗数据的情况下,我们在Cityscapes测试集上实现了81.5%的Mean IoU分数。
8. FACMA - 特征感知上下文建模注意力
论文名称:FACMA: Feature-Aware Context Modeling Attention
简介:FACMA结合了局部和全局上下文建模,旨在通过动态关注关键区域来增强上下文信息。
核心原理:频域跨模态注意力模块 (FACMA):作者提出了一种频率感知的跨模态注意力模块,以增强和选择 RGB 和深度图的互补特征。该模块设计了一个空间频率通道注意力(SFCA)子模块,能够在空间和频率域中提取互补信息。这一模块从频域角度出发,不同于传统的仅基于空间和通道的注意力机制,能够更好地保留不同模态之间的特征互补性。
加权跨模态融合模块 (WCMF):为了提高融合效果,作者提出了一个加权跨模态融合模块,通过学习内容相关的权重图来自适应地融合不同模态的特征,弱化低质量深度图的影响。此外,该模块还通过非线性特征增强(NFE)单元提高了融合过程中网络的非线性表示能力。
性能对比与效果验证:论文在八个基准数据集上进行了实验,并与17种最新的 RGB-D 显著性检测方法进行对比,在四种评价指标(如 S-measure、F-measure、MAE 和 E-measure)上均取得了最佳或接近最佳的结果,这展示了所提出模型的有效性和鲁棒性。
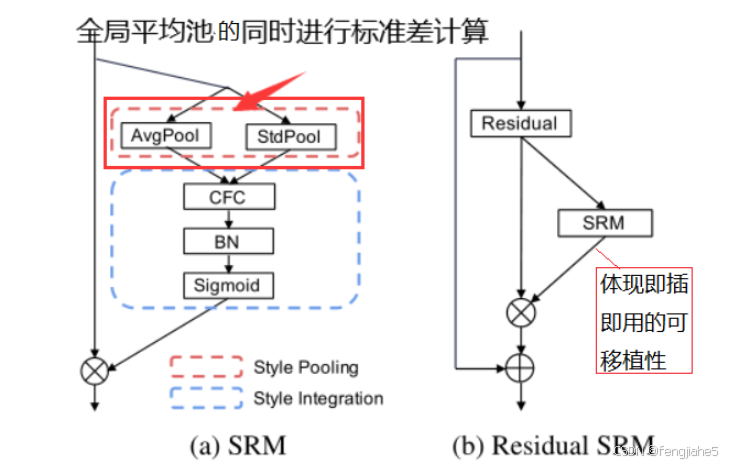
9.SRM - Style-based Recalibration Module
论文名称:Style-based Recalibration Module
简介:SRM通过基于样式的信息重新校准特征图,从而提高卷积神经网络的表示能力。 相比于SEnet引入了标准差池化
核心原理:SRM包含样式池化和样式整合两个步骤,利用样式特征重新校准特征图,强调或抑制通道的样式相关性,提高模型的特征表示能力。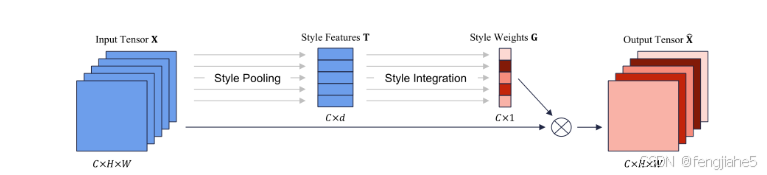

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)