整合AI大模型/中文搜索/人脸识别,NAS部署开源自托管照片和视频管理系统『immich』
immich作为一款开源的自托管照片和视频管理系统,可以帮助用户安全地存储和管理相关文件。同时它还有对应的手机端,功能丰富,体验流畅,并且还能无感同步设备端的照片,还是很强大的,有兴趣的小伙伴可以自己安装体验,我这里就不在演示了。🔺本教程演示的机型是海康存储(HIKVISION)私有云R1,它是一款四盘位高性能的家庭网络存储解决方案,最大支持96TB存储容量。它采用Intel四核处理器 N100
海康存储私有云虽说硬件强大,但是软件生态目前太过于偏向个人与家庭入门需求,所有有很多功能做的也并不是很全面和细化。
比如说相册,它目前支持的功能就很少,不说别的,友商一开始就支持的人脸识别,智能搜索它都没有,好在它支持Docher功能,所以我们可以通过部署相关的Docher项目来完善它系统上的不足。
今天就教大家部署一款免费开源的自托管照片和视频管理系统『immich』,支持整合非常多的大模型来实现中文搜索和人脸识别等各种功能,并且它还支持Web端和手机端同步备份,非常强大。
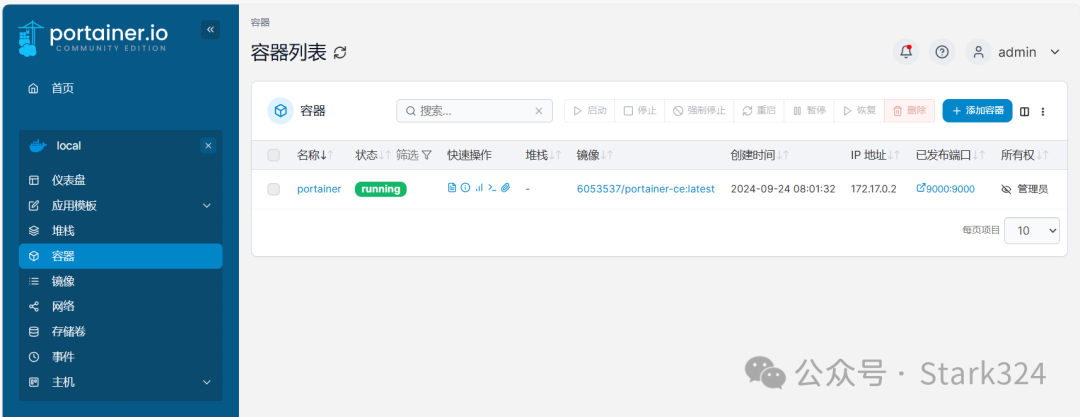
🔺因为immich需要多个不同的Docker容器联动运行,这种情况基本只有使用docker-compose部署才能成功。而我在前不久才教大家怎么在海康存储私有云上部署Portainer,Portainer对于docker-compose堆栈支持的就非常好,所以开始之前请根据我之前的教程安装Portainer。
immich部署准备
1,海康存储端准备
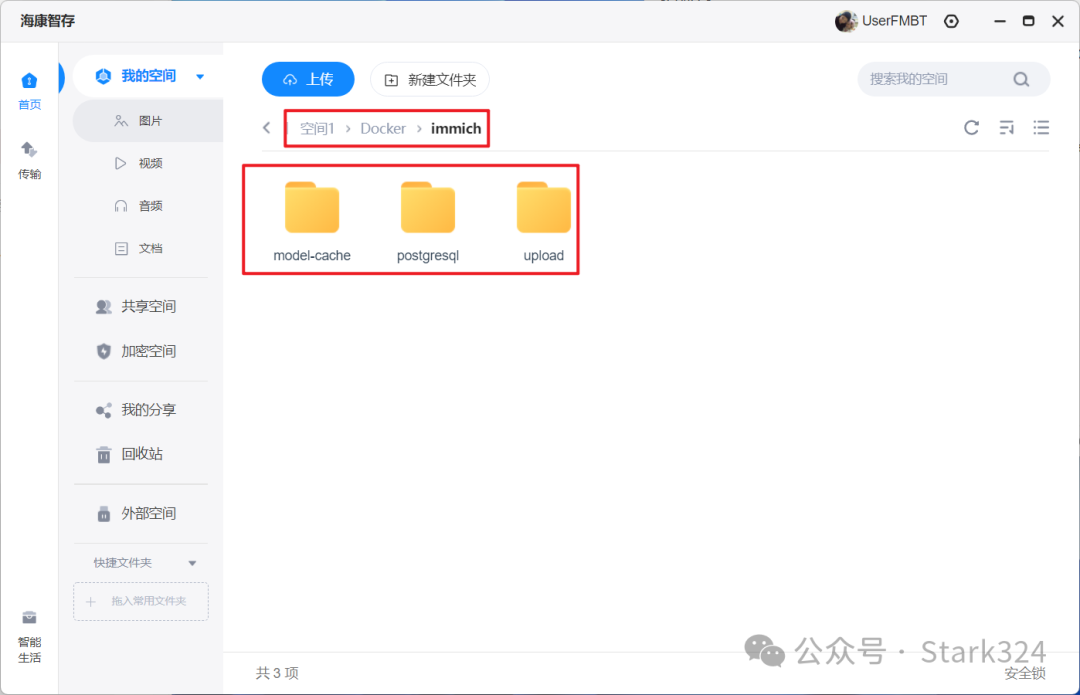
🔺我们先在文件管理器(我的空间)中的Docker目录下新建一个immich的文件夹,然后在该文件夹下在建“model-cache”、“postgresql”、“upload”三个子文件夹用于相关配置文件的持久化存储(也便于以后Docker容器迁移)。
-
model-cache:模型存放路径
-
postgresql:数据库存放路径
-
upload:immich的上传路径
2,下载自己需要的大模型
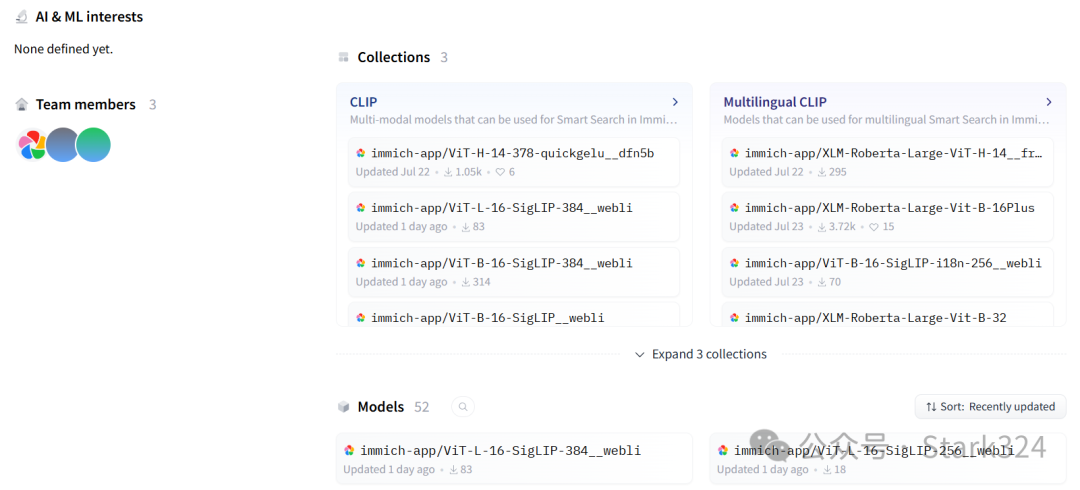
🔺immich支持多种模型,不过需要自己提前下载。
immich模型列表:https://huggingface.co/immich-app
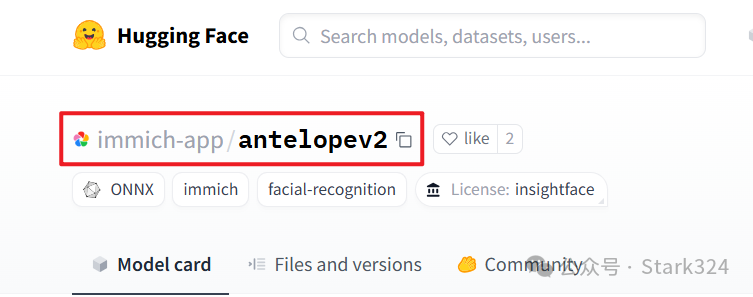
🔺我个人推荐小伙伴们优先下载这两个模型:一个是人脸识别的【immich-app/antelopev2】,另一个是对中文支持非常不错的【immich-app/XLM-Roberta-Large-Vit-B-16Plus】。
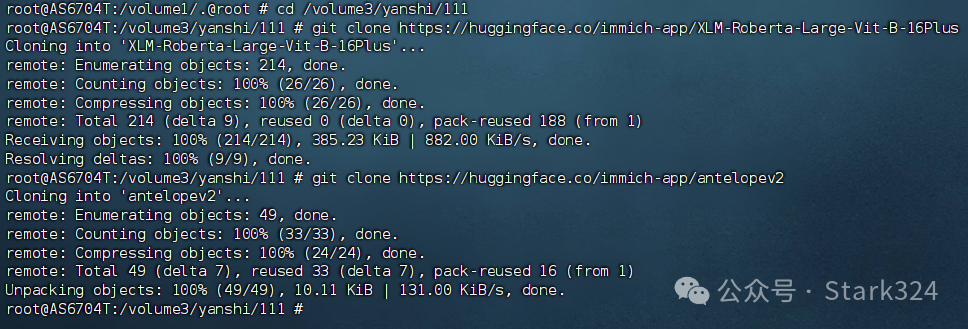
🔺至于下载方案我个人采取的是用我另外一台NAS git拉取,如果说你那边有群辉威联通这种传统NAS,或者Linux服务器也可以采取我这一样的方式。还可以度娘自己需要的模型名称,可能会有热心网友通过网盘的形式分享,拿过来知己金额用即可。
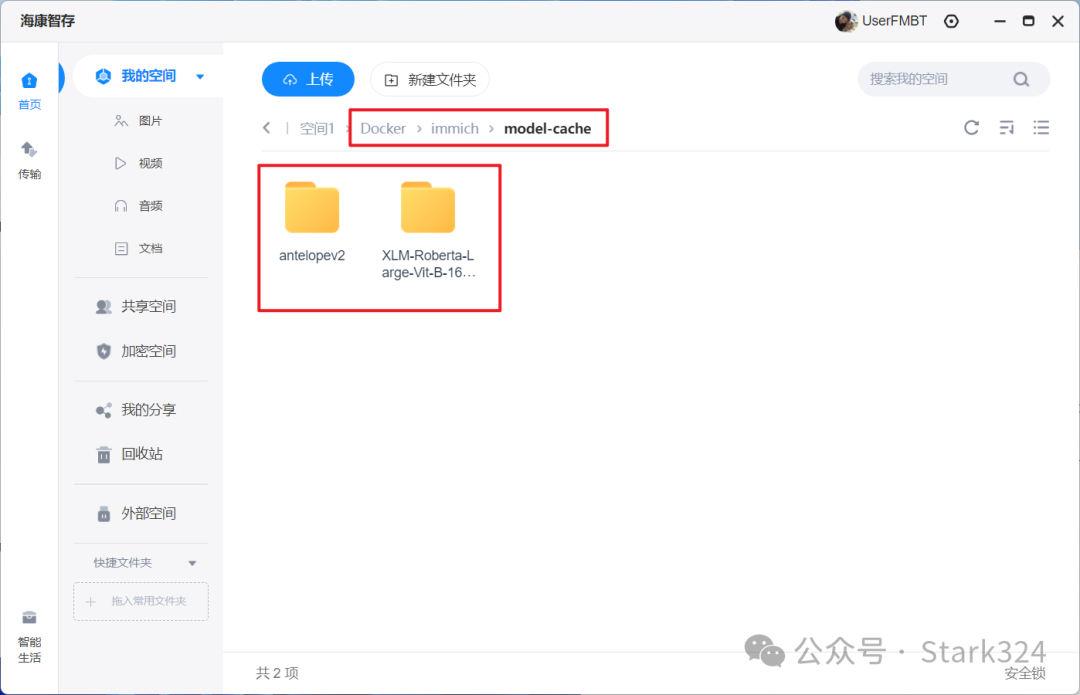
🔺然后将模型的主文件夹上传添加到immich目录中存放模型的“model-cache”文件夹即可。
3,创建环境变量文件
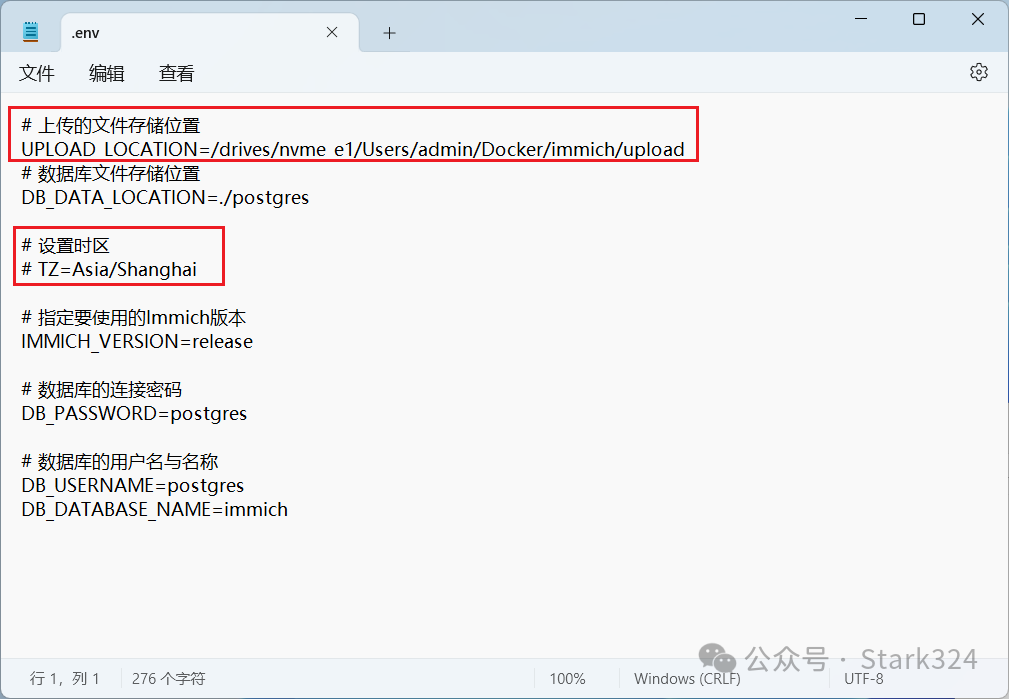
🔺环境变量文件也是 .env文件,创建非常简单,直接在桌面新建一个.txt的文本文档,然后将以下内容复制粘贴进去即可,然后直接重命名为【.env】(就一后缀,没有名称),放在电脑本地桌面待用。
\# immich的上传路径
UPLOAD\_LOCATION=/drives/nvme\_e1/Users/admin/Docker/immich/upload
\# 数据库文件存储路径
DB\_DATA\_LOCATION=./postgres
\# 设置时区
\# TZ=Asia/Shanghai
\# 指定要使用的Immich版本
IMMICH\_VERSION=release
\# 数据库的连接密码
DB\_PASSWORD=postgres
\# 数据库的用户名与名称
DB\_USERNAME=postgres
DB\_DATABASE\_NAME=immich
需要说明的是,immich上传路径其实就是前面我们新建的“upload”子文件夹,如果你不知道它的具体路径请回到我上一篇的portainer教程中,文中已经说的很清楚了。
至于数据库名称、用户名和密码大家根据自己的需求吧,喜欢抄作业的就按我给出的不动即可。
4,创建适合自己的docker-compose.yml文件
docker-compose.yml文件我们直接使用immich官方给出的略作修改即可。以下是我个人修改之后,适合我自己使用的docker-compose.yml文件:
name: immich
services:
immich-server:
container\_name: immich\_server
image: ghcr.io/immich-app/immich-server:${IMMICH\_VERSION:\-release}
\# extends:
\# file: hwaccel.transcoding.yml
\# service: cpu # set to one of \[nvenc, quicksync, rkmpp, vaapi, vaapi-wsl\] for accelerated transcoding
volumes:
\# Do not edit the next line. If you want to change the media storage location on your system, edit the value of UPLOAD\_LOCATION in the .env file
- ${UPLOAD\_LOCATION}:/usr/src/app/upload
- /etc/localtime:/etc/localtime:ro
- /drives/nvme\_e1/Users/admin/photo:/photo \# 映射NAS本地相册路径
env\_file:
- stack.env
ports:
- 2283:3001 \# 本地端口设置为未被占用
depends\_on:
- redis
- database
restart: always
healthcheck:
disable: false
immich-machine-learning:
container\_name: immich\_machine\_learning
\# For hardware acceleration, add one of -\[armnn, cuda, openvino\] to the image tag.
\# Example tag: ${IMMICH\_VERSION:-release}-cuda
image: ghcr.io/immich-app/immich-machine-learning:${IMMICH\_VERSION:\-release}
\# extends: # uncomment this section for hardware acceleration - see https://immich.app/docs/features/ml-hardware-acceleration
\# file: hwaccel.ml.yml
\# service: cpu # set to one of \[armnn, cuda, openvino, openvino-wsl\] for accelerated inference - use the \`-wsl\` version for WSL2 where applicable
volumes:
- /drives/nvme\_e1/Users/admin/Docker/immich/model-cache:/cache \# 映射模型存放路径
env\_file:
- stack.env
restart: always
healthcheck:
disable: false
redis:
container\_name: immich\_redis
image: docker.io/redis:6.2-alpine@sha256:2d1463258f2764328496376f5d965f20c6a67f66ea2b06dc42af351f75248792
healthcheck:
test: redis-cli ping || exit 1
restart: always
database:
container\_name: immich\_postgres
image: docker.io/tensorchord/pgvecto-rs:pg14-v0.2.0@sha256:90724186f0a3517cf6914295b5ab410db9ce23190a2d9d0b9dd6463e3fa298f0
environment:
POSTGRES\_PASSWORD: ${DB\_PASSWORD}
POSTGRES\_USER: ${DB\_USERNAME}
POSTGRES\_DB: ${DB\_DATABASE\_NAME}
POSTGRES\_INITDB\_ARGS: '--data-checksums'
volumes:
\# Do not edit the next line. If you want to change the database storage location on your system, edit the value of DB\_DATA\_LOCATION in the .env file
- /drives/nvme\_e1/Users/admin/Docker/immich/postgresql:/var/lib/postgresql/data \# 映射数据库存放路径
healthcheck:
test: pg\_isready --dbname='${DB\_DATABASE\_NAME}' --username='${DB\_USERNAME}' || exit 1; Chksum="$$(psql --dbname='${DB\_DATABASE\_NAME}' --username='${DB\_USERNAME}' --tuples-only --no-align --command='SELECT COALESCE(SUM(checksum\_failures), 0) FROM pg\_stat\_database')"; echo "checksum failure count is $$Chksum"; \[ "$$Chksum" = '0' \] || exit 1
interval: 5m
start\_interval: 30s
start\_period: 5m
command: \["postgres", "-c", "shared\_preload\_libraries=vectors.so", "-c", 'search\_path="$$user", public, vectors', "-c", "logging\_collector=on", "-c", "max\_wal\_size=2GB", "-c", "shared\_buffers=512MB", "-c", "wal\_compression=on"\]
restart: always
volumes:
model-cache:
需要修改的地方并不多,我已经用“# 中文”给大家注释好了,其它的都保持默认即可,不要动它。
immich正式部署
🔺前面的准备工作搞定之后,部署起来就比较容易了,直接打开portainer的“堆栈”开始创建即可。名称随意,不过建议使用“immich”便于今后识别区分,然后将我们修改之后的docker-compose.yml文件内容复制粘贴到方框之中。
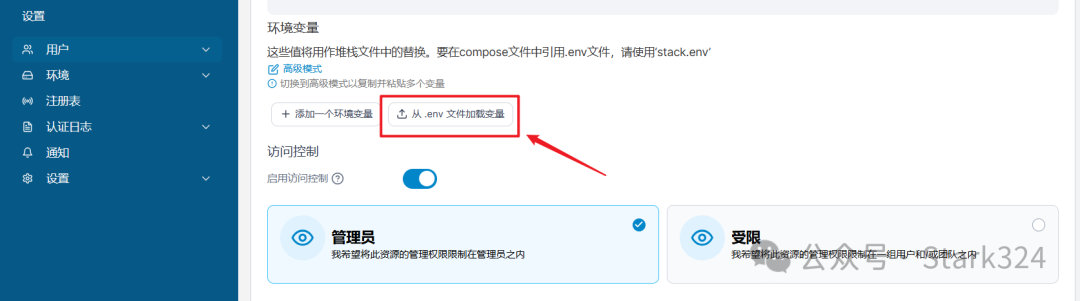
🔺接着在下面的“环境变量”选项中,点击“从.env文件加载变量”,选择我们准备工作存放在电脑本地的环境变量.env文件。
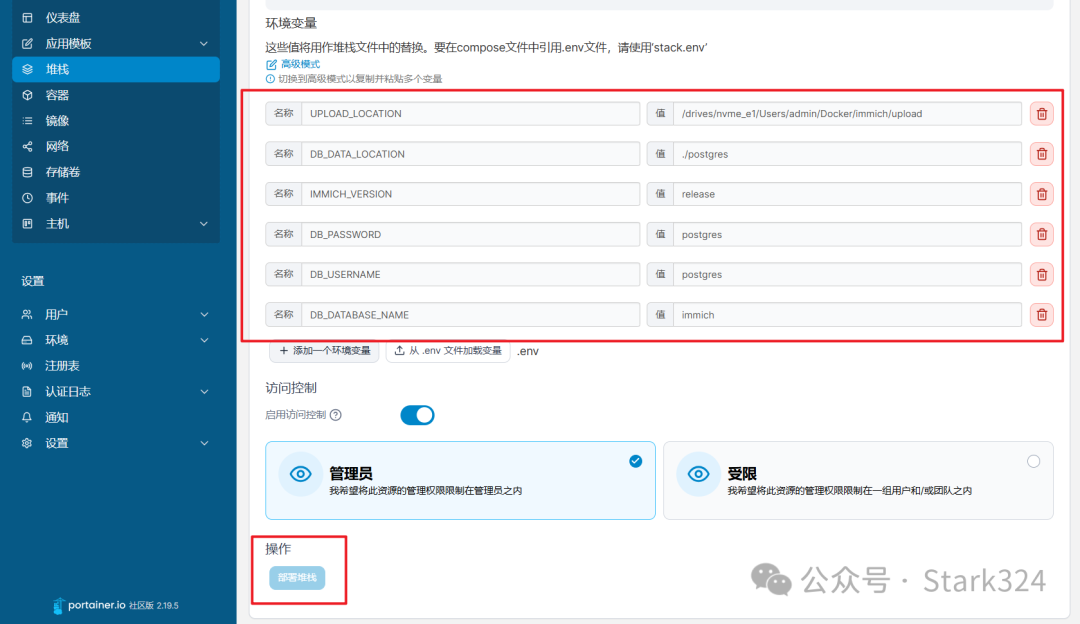
🔺可以看到.env文件中的环境变量一次全部添加到列表中,最后点击“部署堆栈”按钮即可开始部署immich项目。
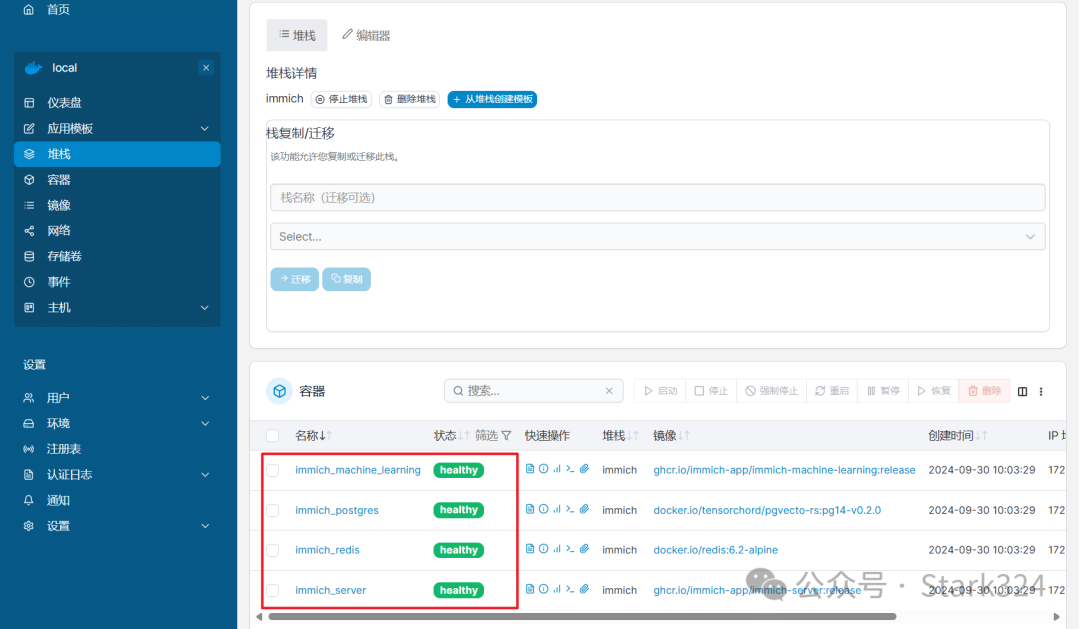
🔺因为immich项目多达4个容器联动,部署的时间可能略长。部署成功之后可以看到4个容器全部都在正常运行。
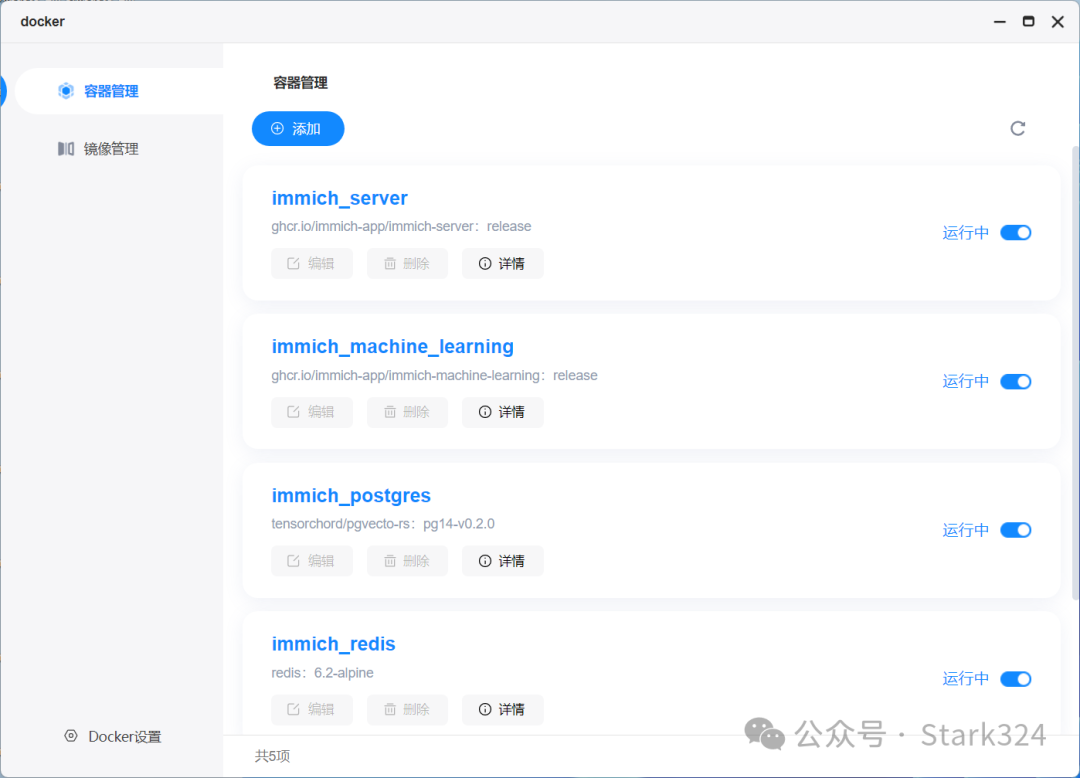
🔺打开海康存储这边的Docker管理器,也可以看到4个容器都是正常运行中。
immich体验
初始化设置:
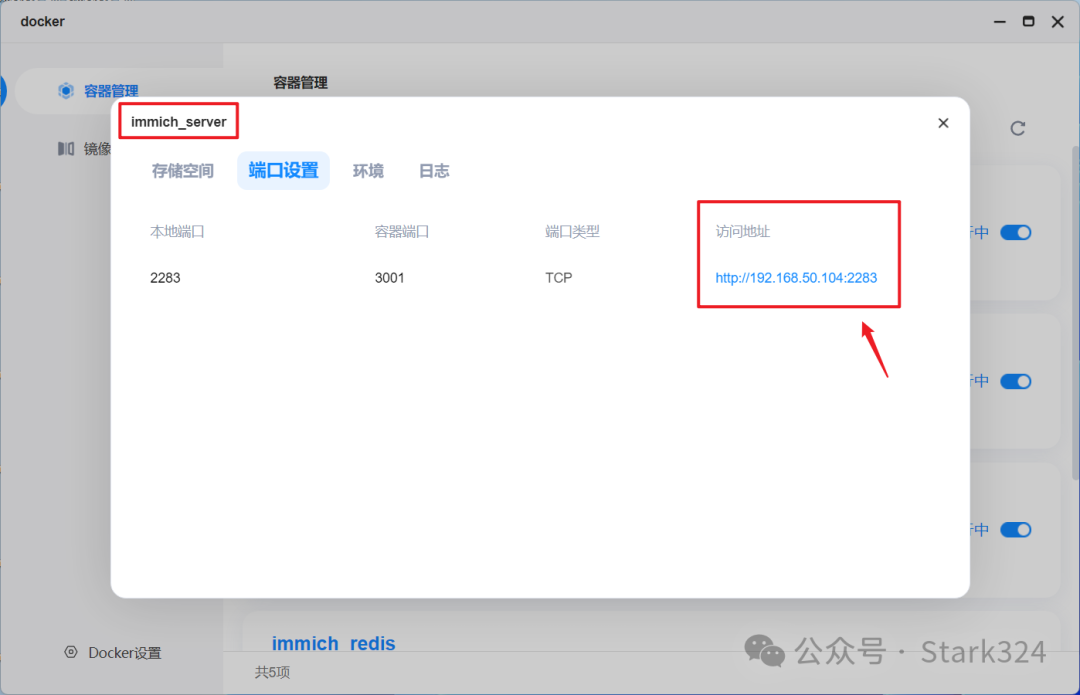
🔺打开方式很简单,直接浏览器【本地IP:端口号】,或者在容器管理中点击immich_server容器,从端口设置中点击“访问地址”即可。

🔺点击Get Started。
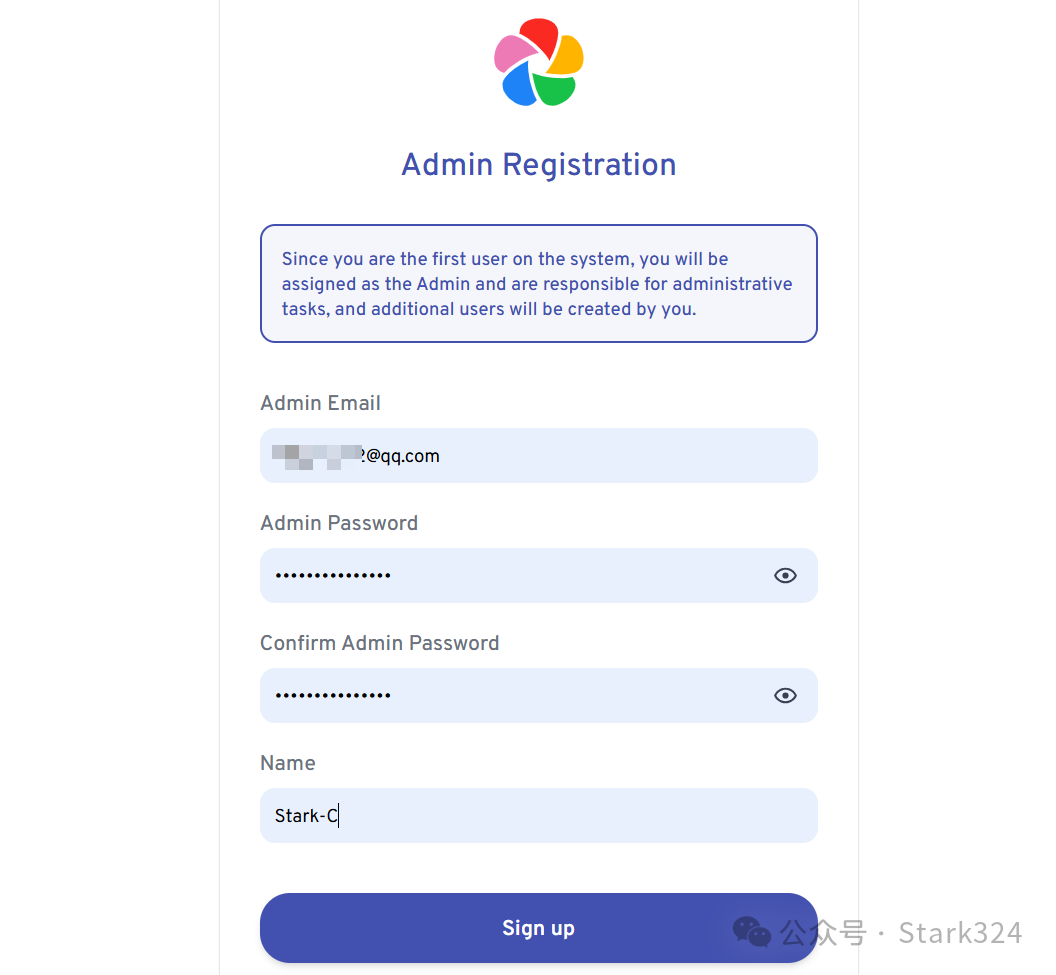
🔺这里是注册一个管理员账户,邮箱随意输入即可(不一定是自己的,但登录项目需要用到),然后设置管理员密码和名称即可。
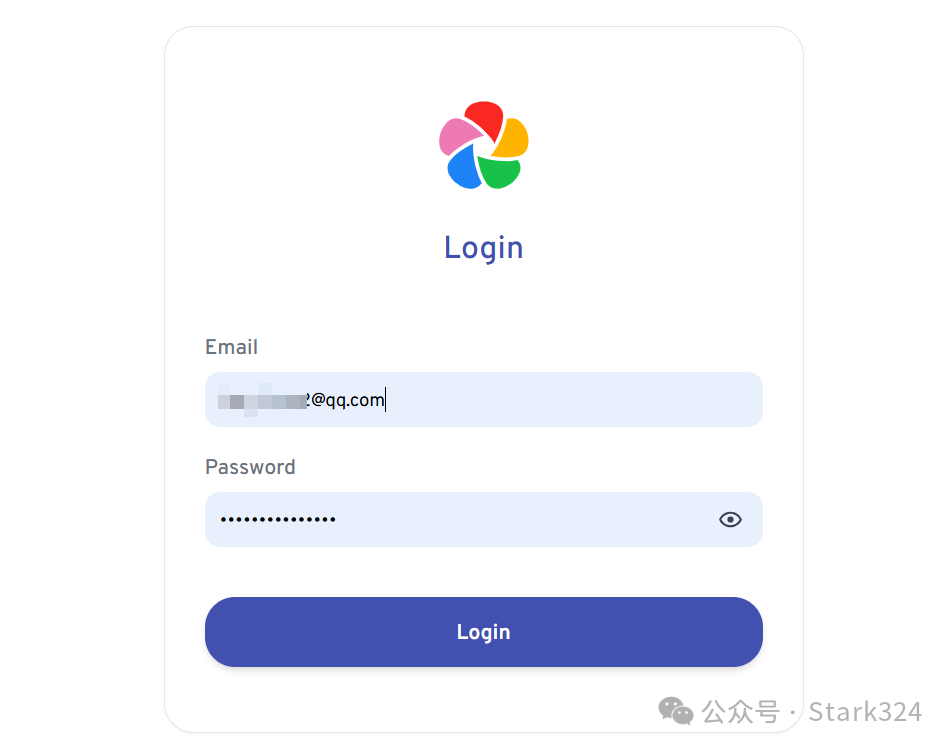
🔺注册完后直接使用邮箱和密码登录即可。
🔺开始进入初始化向导,点击Theme。
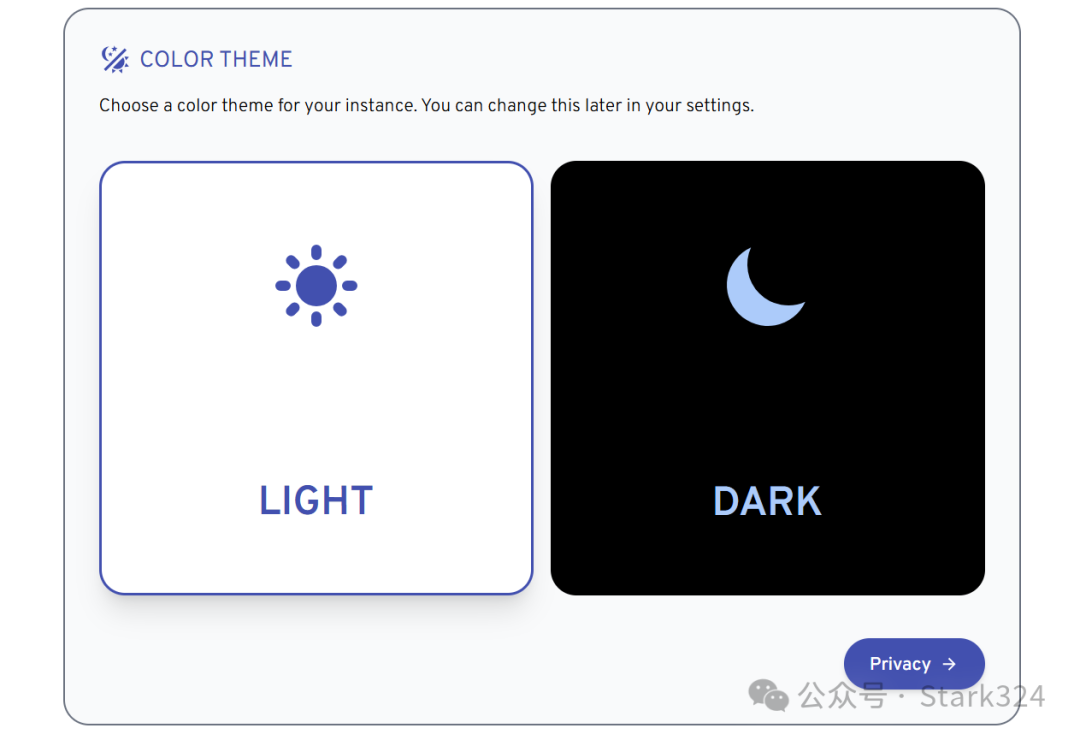
🔺根据自己的需求选择白天/夜晚模式。
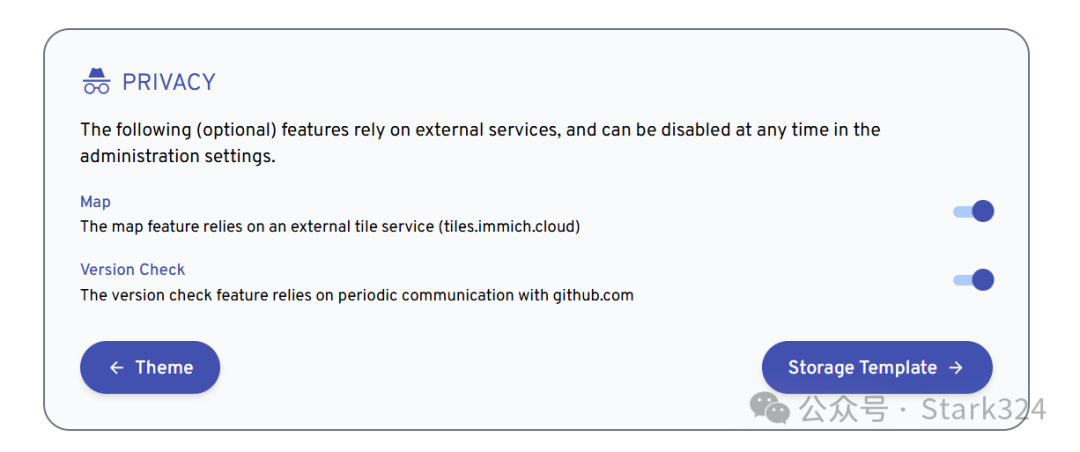
🔺这里是隐私方面的设置,默认即可。
🔺最后一步是存储模板的设置,默认是关闭的,可以打开根据自己的需求来设置,不过一般默认即可,最后点“Done”完成初始化的设置。
设置中文显示:
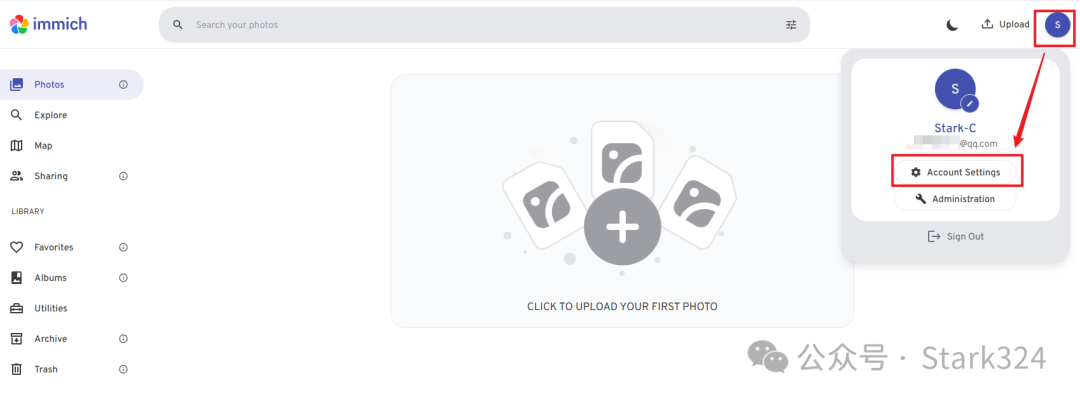
🔺immich默认是英文界面,不过它是有中文选项的。点击右上角的个人图像,选择“ccount Settings”。
🔺点击“App Settings–Language”
🔺在选项中选择Chinese(Simplified)即可。
添加本地照片:

🔺还是点击右上角的个人图像,选择“管理”。
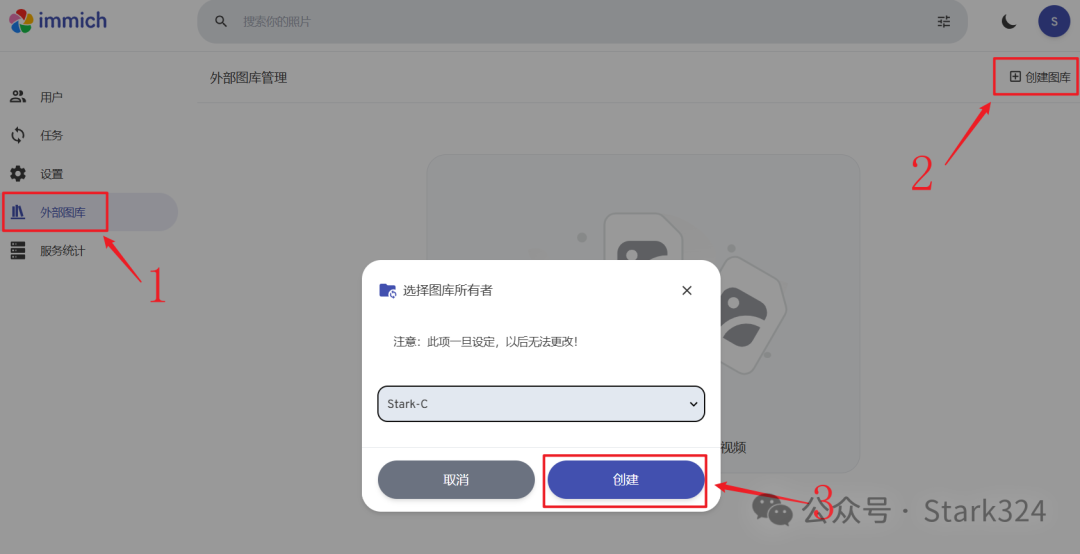
🔺点击“外部图库–创建图库–创建“。

🔺点击选项后面的三个点,选择“编辑导入路径”。
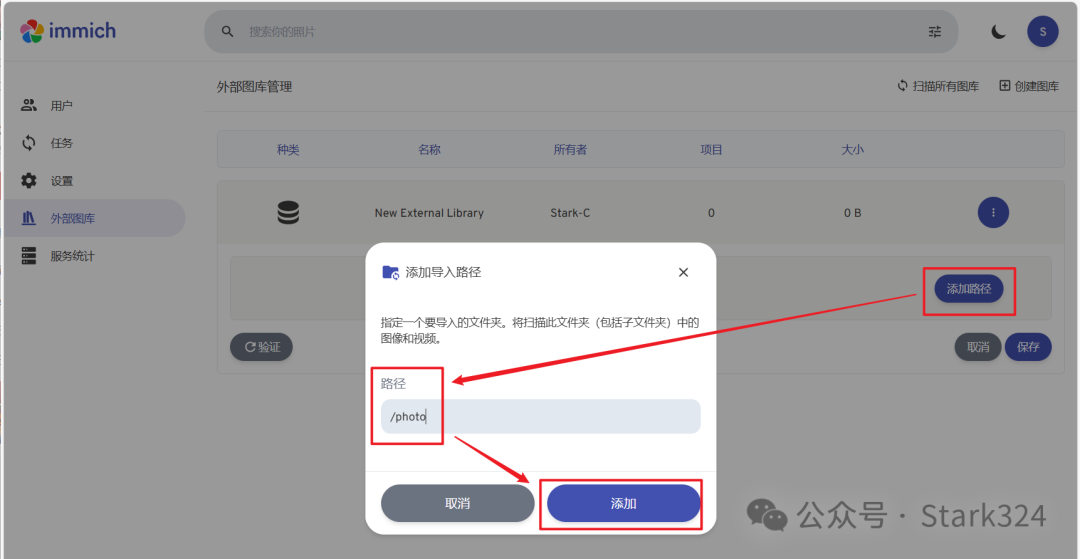
🔺点击“添加路径”,路径为“/photo”,也就是前面我们部署命令中的映射相册的容器路径,最后点“添加”。
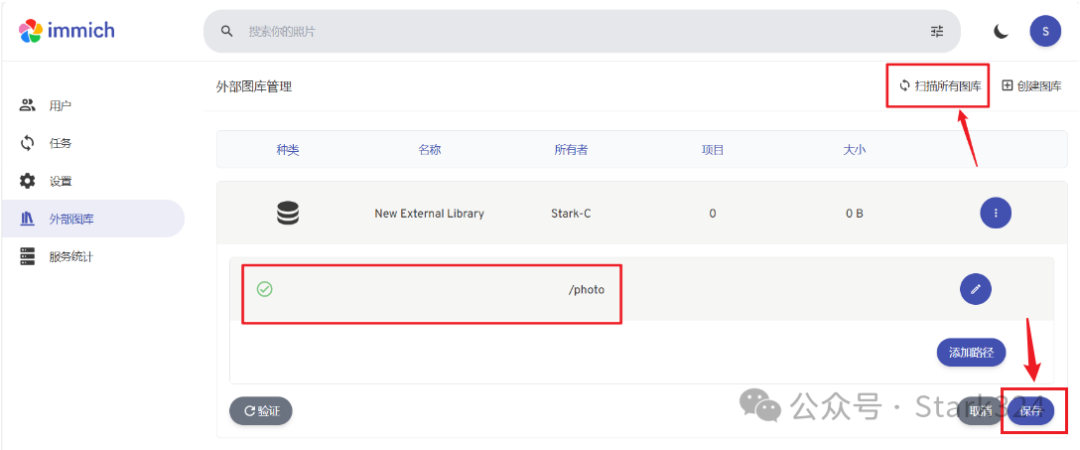
🔺确定路径添加成功之后,先点“保存”,在点页面上方的“扫描所欲图库”。
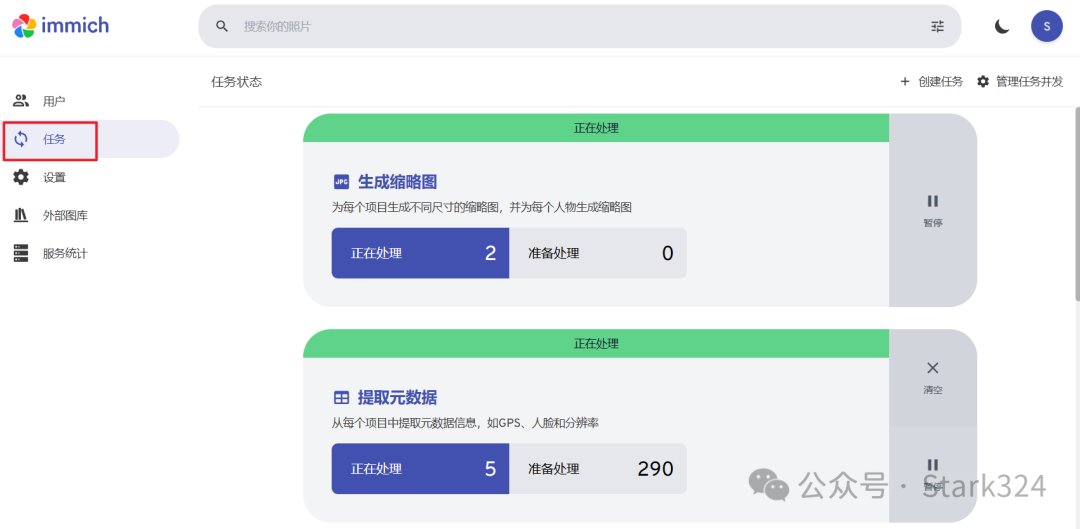
🔺在“任务”中,就能看见当前的任务状态。实测海康存储 R1的性能还是非常不错的,不管是苏略图还是提取元数据速度都很快。
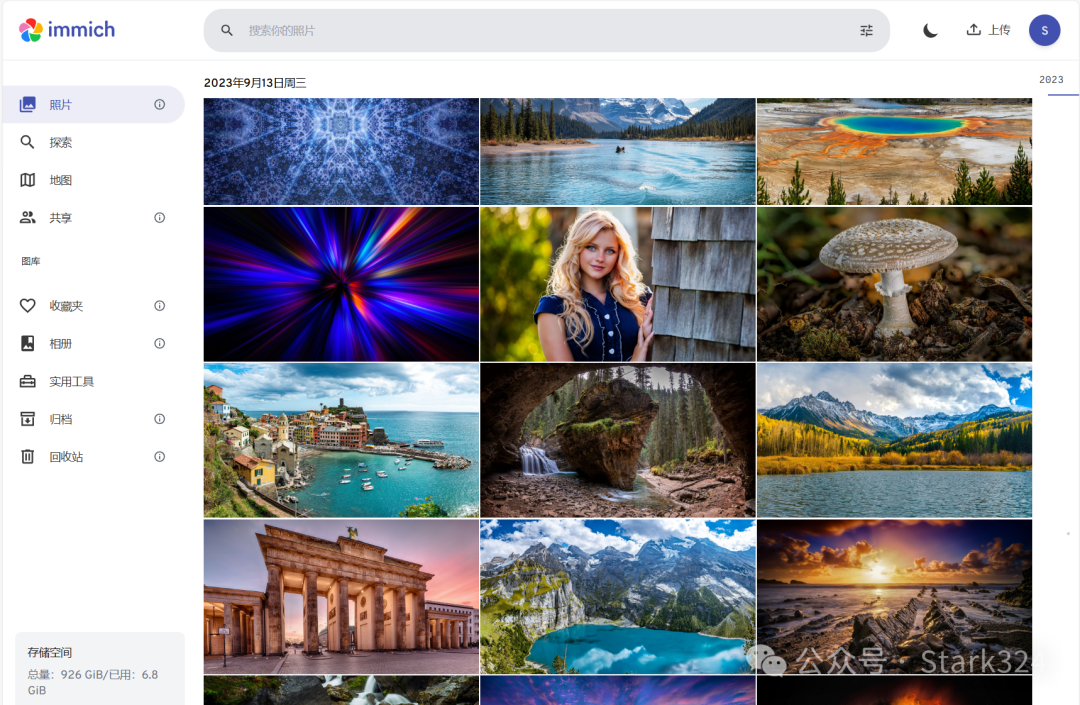
🔺回到immich项目主页,可以看到照片已经全部以缩略图样式展示出来了。
整合的大模式展示:
🔺我们在部署的时候加入的模型可以在“管理–设置”中的“机器学习设置”中看到可以看到我们加入的智能搜索与人脸识别模型已经加载进来了。
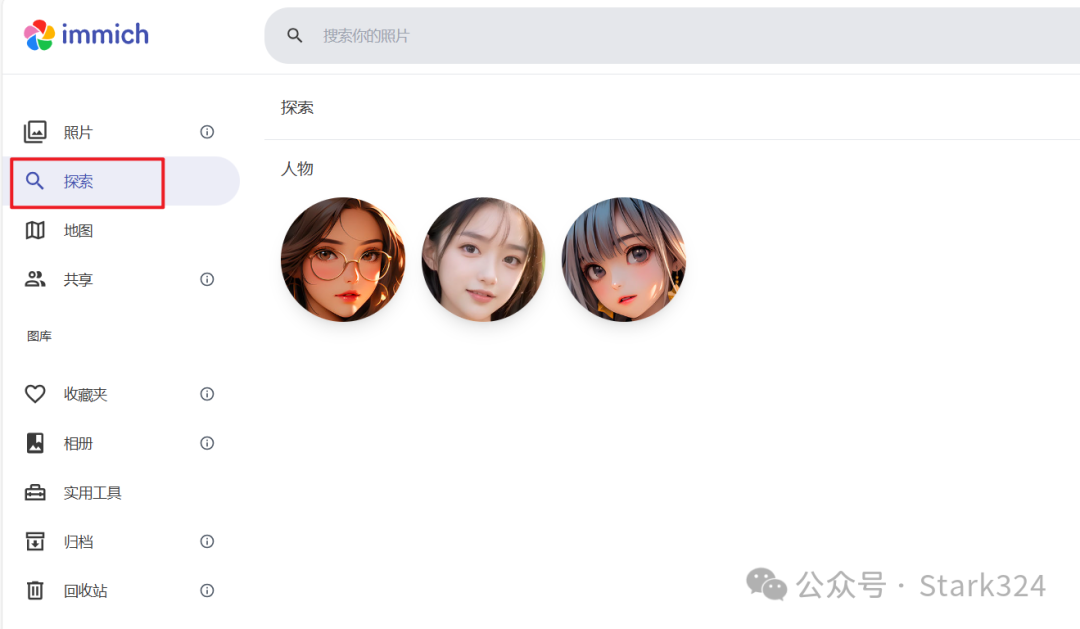

🔺人脸识别可以在首页位置“探索”中看到,随便点开一个识别的图像,可以看到识别的准确率确实挺高的,竟然世界打开了我收集的二次元合集内容。
🔺然后试试它的智能搜索,比如我搜索“美女”,我啥也不说,就问各位绅士们对它的搜索结果可否满意~?
最后
immich作为一款开源的自托管照片和视频管理系统,可以帮助用户安全地存储和管理相关文件。同时它还有对应的手机端,功能丰富,体验流畅,并且还能无感同步设备端的照片,还是很强大的,有兴趣的小伙伴可以自己安装体验,我这里就不在演示了。
🔺本教程演示的机型是海康存储(HIKVISION)私有云R1,它是一款四盘位高性能的家庭网络存储解决方案,最大支持96TB存储容量。它采用Intel四核处理器 N100,标配一个 DDR5内存插槽与双M.2 SSD设计,强大的性能足够个人及家庭用户的数据备份和文件共享需求。
I/O接口上也是非常丰富,包括3个USB 3.2 Gen2 10Gbps接口、1个 USB3.2 Gen2 Type-C接口及1个HDMI接口(4K 60fps),两个2.5G网口,适应多种扩展需求。
比较有意思的是,它的前面板刚还配备了1块2.86寸、60Hz触控屏,支持多种功能与主题设置,可实时显示温度、CPU占用、风扇、硬盘等状态信息,侧边还配备了透明侧板以及可调控炫彩RGB氛围灯,拥有极高的可玩性。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 18
18 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)