爬虫练手-国家统计局数据获取和分析
爬虫练习-如果利用浏览器查看接口,并用python来获取数据和数据清洗。
·
进入统计局数据查询页面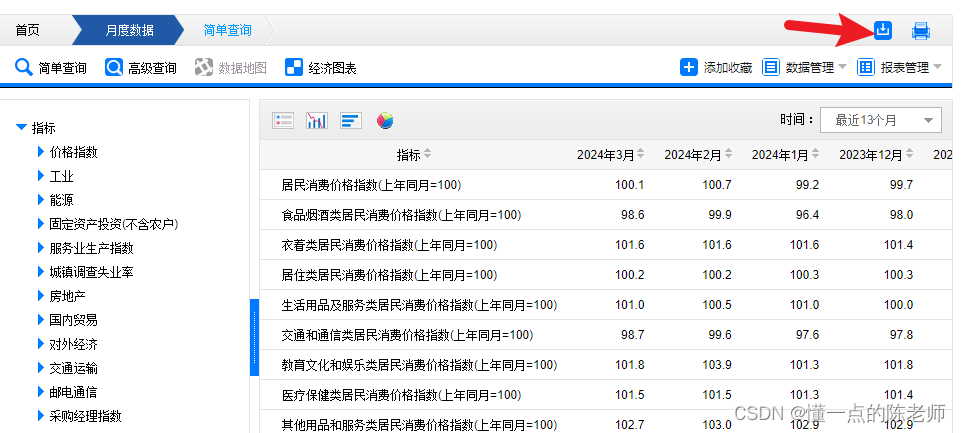
一般数据查询,然后可以直接下载为电子表格,非常方便。不过若需要左侧栏比较多数据,那么可以查看连接,通过接口请求获取。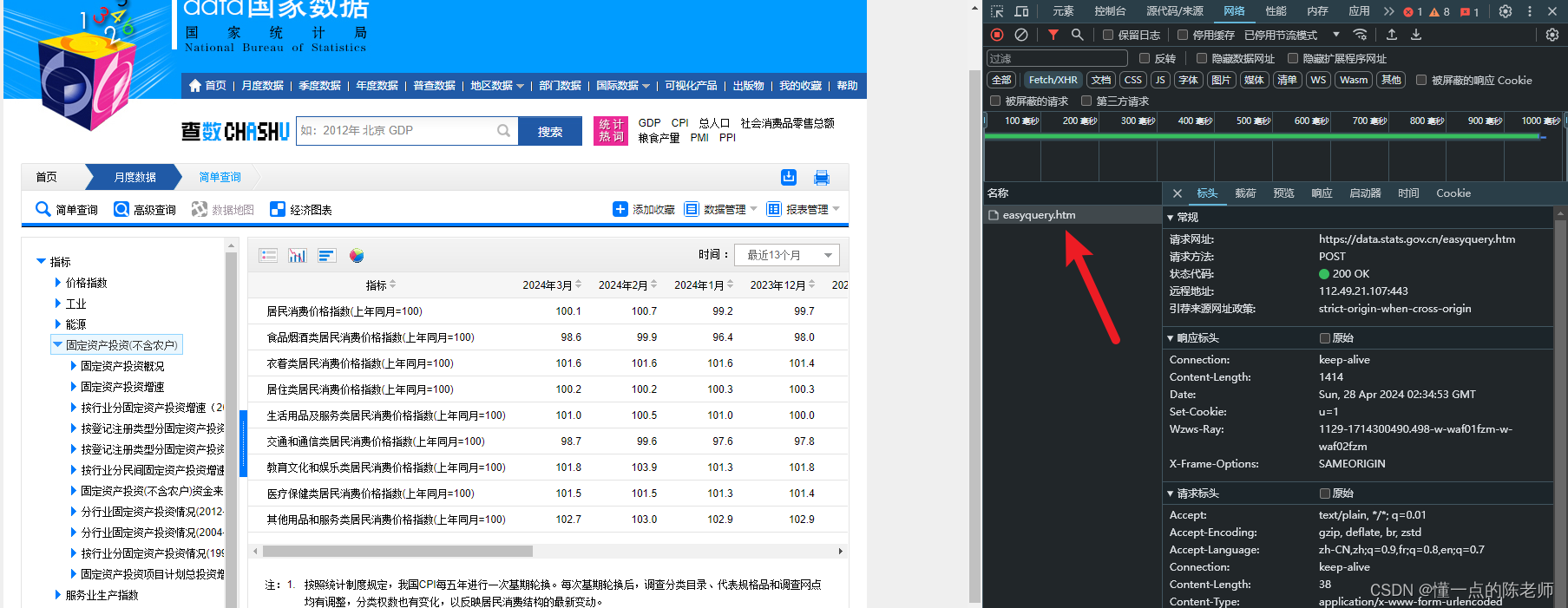
观察接口,然后用Python模拟数据请求,代码如下:
# 解析URL,提取参数及其值
url = "https://data.stats.gov.cn/easyquery.htm"
params = {
'm': 'QueryData',
'dbcode': 'fsnd',
'rowcode': 'zb',
'colcode': 'reg',
'wds': '[{"wdcode":"sj","valuecode":"2021"}]',
'dfwds': '[{"wdcode":"zb","valuecode":"A0502"}]',
'k1': str(int(time.time() * 1000)),
'h': '1'
}
# 发送GET请求
response = requests.get(url, params=params, verify=False)
# 输出响应内容
print(response.text)
data = response.json()

这些数据看起来和页面的有些区别,因为这里很多中文都用标识来代替了,若要还原表格,可以查看返回数据中的data["returndata"]["wdnodes"], 然后把code和对应cname 做一个字典匹配。
def handle_data_to_dict(wdnode):
"""
处理数据字典
:param wdnode:
:return:
"""
zb_dict = {}
reg_dict = {}
for item in wdnode:
if item["wdcode"] == "zb":
for node in item["nodes"]:
# print(node["cname"], node["code"], node["unit"])
zb_dict[node["code"]] = f'{node["cname"]}({node["unit"]})'
if item["wdcode"] == "reg":
for node in item["nodes"]:
# print(node["cname"], node["code"])
reg_dict[node["code"]] = node["cname"]
return zb_dict, reg_dict
想获取完整代码可以关注我的公众号,发送国家统计局,获取连接。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)