【机器人 / 强化学习】HIL-SERL 工程篇:人类在环的工程架构与物理设计
x00 概要
HIL-SERL 能在真实机械臂上跑通 RL,靠的不是某个算法突破,而是整套工程系统设计:异步 Actor-Learner 解耦、SpaceMouse 实时干预、混合动作空间、阻抗控制底层安全——每一层都是纸上算法到真实机器人之间的必要桥梁。
0x01 系统架构总览
HIL-SERL 是一个无中心编排的系统——没有 master、没有 supervisor、没有 orchestrator。所有组件都是手动启动的独立进程,通过硬编码端口互连。
1.1 逻辑架构
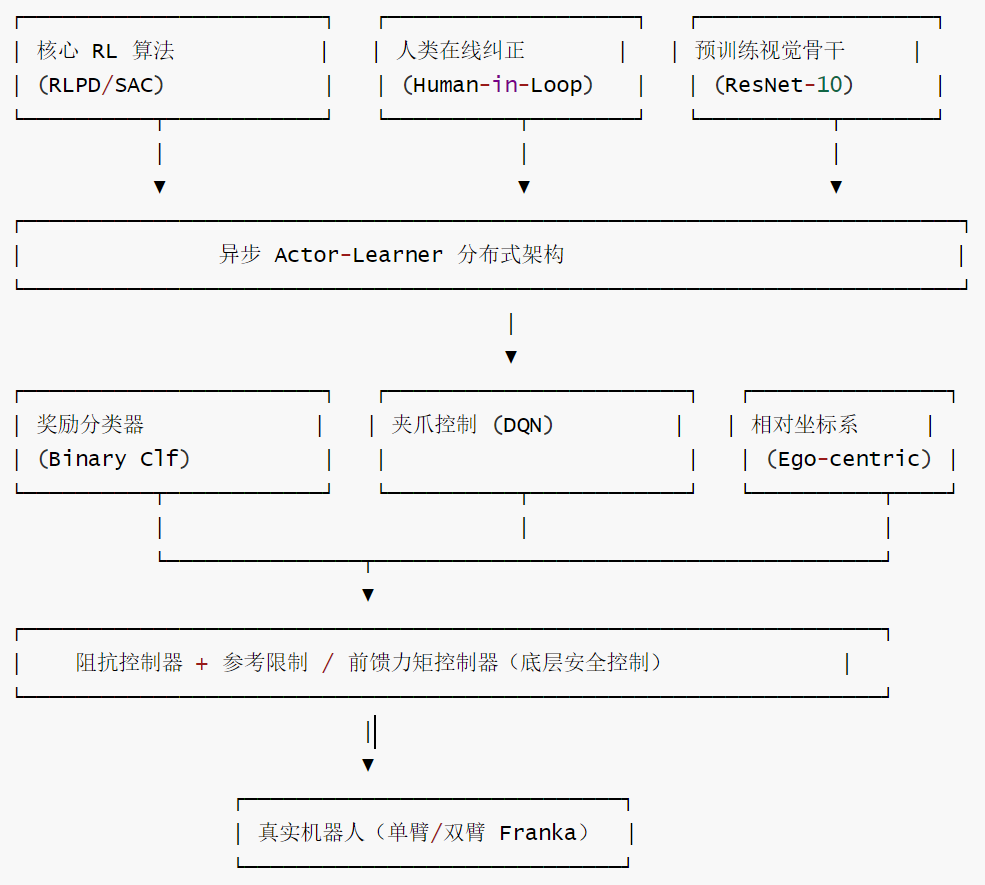
HIL-SERL 最核心的机制是人类纠偏,"干预即负反馈"——将"挨骂"转化为进化的动力。在传统 RL 中失败的惩罚往往是滞后的(直到任务结束才判定失败),而 HIL-SERL 实现了瞬时负反馈:当人类通过 SpaceMouse 介入的一瞬间,系统不仅拿走控制权,还会给被接管前的动作打上负分,相当于在 Q 函数曲面上直接"挖坑"——机器人产生避险本能,不需要等到任务彻底失败就能提前规避错误。
1.2 物理拓扑
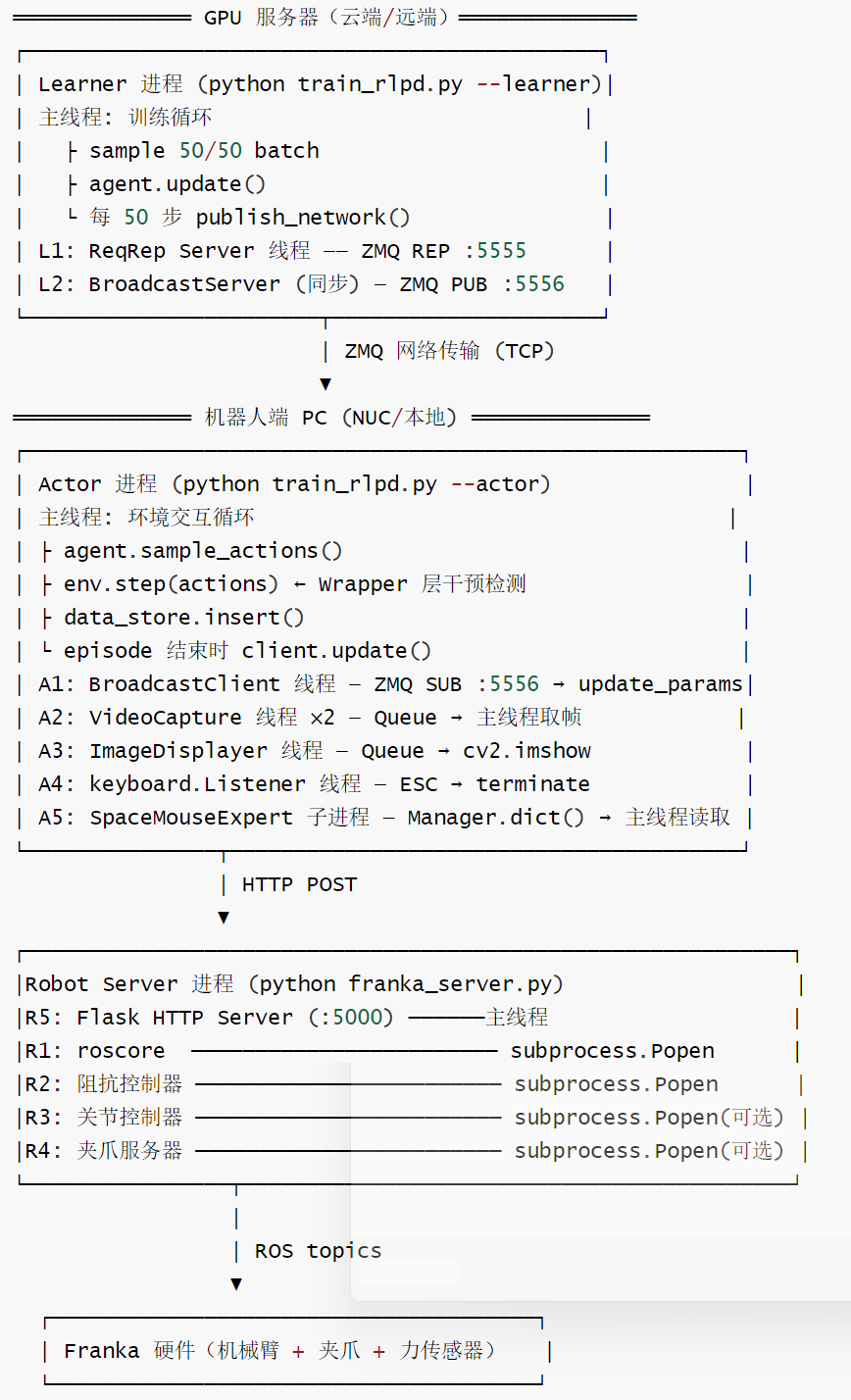
1.3 部署拓扑与启动顺序
HIL-SERL 是一个手工编排的系统:人类操作者就是"中控",负责在 3 个终端里分别启动 Robot Server、Learner、Actor,通过 --ip 参数和硬编码端口让它们互连。
启动顺序:必须先启动机器人服务器 → 再启动 Learner → 最后启动 Actor(Actor 有 wait_for_server=True,会等待 Learner 就绪)。

Actor 是手动启动的独立进程,结束即结束,不会自动重启。任何组件挂掉都需要人工重启,不支持多 Actor,没有故障恢复——这是典型的研究原型设计,够用就好,不做生产级运维。
1.4 独立运行的组件清单
共 3 大进程,内部 13+ 个独立执行单元。所有"持续运行"的组件都是生产者,它们预取或缓存数据;Actor 主线程是消费者,按需读取最新值。这种解耦保证了主循环的步进节奏不受硬件 I/O 延迟影响。
| # | 组件 | 进程 | 类型 | 循环方式 | 通信方式 |
|---|---|---|---|---|---|
| L1 | Learner 主线程 | Learner | 主线程 | for step in range(max_steps) | 直接调用 |
| L2 | ReqRep Server 线程 | Learner | daemon 线程 | while not is_kill 无限循环 | ZMQ REP :5555 |
| L3 | BroadcastServer | Learner | 同步调用 | 无循环,被动触发 | ZMQ PUB :5556 |
| A1 | Actor 主线程 | Actor | 主线程 | for step in range(max_steps) | 直接调用 |
| A2 | BroadcastClient 线程 | Actor | 线程 | while not is_kill 无限循环 | ZMQ SUB :5556 |
| A3 | VideoCapture 线程 ×2 | Actor | 线程 | while enable 无限循环 | Queue → 主线程 |
| A4 | ImageDisplayer 线程 | Actor | daemon 线程 | while True 无限循环 | Queue → cv2.imshow |
| A5 | keyboard.Listener 线程 | Actor | pynput 线程 | 无限循环(事件驱动) | — |
| A6 | SpaceMouseExpert 子进程 | Actor | 子进程 | while True 无限循环 | Manager.dict() 共享内存 |
| R1 | roscore | Robot Server | subprocess | 无限循环(ROS master) | ROS |
| R2 | 阻抗控制器 | Robot Server | subprocess | 无限循环(ROS node) | ROS topic |
| R3 | 关节控制器 | Robot Server | subprocess | 无限循环(ROS node) | ROS topic |
| R4 | 夹爪服务器 | Robot Server | subprocess | 无限循环(ROS node) | ROS topic |
| R5 | Flask HTTP Server | Robot Server | 主线程 | 无限循环(WSGI) | HTTP :5000 |
自主运行组件(无限循环,不受主线程控制):SpaceMouseExpert(硬件驱动必须持续轮询,否则丢失输入事件)、VideoCapture(相机帧率 30fps,必须持续读取避免帧堆积)、BroadcastClient(随时可能收到 Learner 参数,必须持续监听)、ReqRep Server(随时可能收到 Actor 数据,必须持续监听)、Robot Server 各进程(机器人控制器必须持续运行,保证安全)。
按需运行组件(由主线程驱动):Actor 主循环、Learner 主循环(均逐步同步执行)、BroadcastServer(仅在 publish_network 被调用时发送)、client.update(仅在 episode 结束时触发数据传输)。
1.5 单步交互时序
Actor 主循环是系统的执行核心。每一步的序列如下:
for step in pbar: # 默认 1,000,000 步,实际上等同于持续运行直到人为终止
① agent.sample_actions(obs)
│ ← BroadcastClient 可能在任意时刻异步更新 agent 参数
│ ← VideoCapture 已在后台持续写入最新帧到 Queue
▼ ← SpaceMouseExpert 已在后台持续写入最新状态到共享内存
② env.step(actions)
│ SpacemouseIntervention.step():
│ ├ expert.get_action() ← 读 A6 的共享内存(非阻塞,取最新值)
│ ├ 干预判定 → 决定 new_action
│ └ self.env.step(new_action)
│ │
│ FrankaEnv.step():
│ ├ _get_obs()
│ │ └ 相机: 从 Queue 取最新帧(A3 早已预取好)
│ │ 状态: HTTP POST /getstate → R5 Flask → ROS → 硬件
│ ├ _send_gripper_command() → HTTP POST → R5 → R4 → 硬件
│ ├ _send_pos_command() → HTTP POST → R5 → R2 → 硬件
│ └ _update_currpos() → HTTP POST → R5 → ROS → 硬件
│ 返回 (obs, rew, done, info)
▼ info["intervene_action"] = ...(如有干预)
③ 干预处理: actions = info.pop("intervene_action")(如有)
④ transition 构建 + data_store.insert()
⑤ if done: client.update() → ZMQ REQ-REP → Learner ReqRep Server → replay_buffer
⑥ obs = next_obs, 回到 ①
每一步内部是同步阻塞的:sample_actions() → env.step() → insert() → 下一步。异步体现在线程层级——网络参数接收、视频采集、SpaceMouse 读取都在独立线程/进程中持续运行,主线程只管取最新值。
0x02 物理硬件设计
2.1 混合动作空间:连续手臂 + 离散夹爪
机器人动作包含两类性质完全不同的部分。机械臂运动是连续 6D 末端位姿或 twist,需要平滑控制;夹爪动作是开/关/保持,天然是离散决策。
如果用一个连续 SAC policy 同时输出两者,夹爪可能输出类似"闭合 0.537"的中间值,导致犹豫、抖动或无效机械动作。因此 HIL-SERL 做了分治:
- 连续手臂动作由 SAC policy 输出;
- 离散夹爪动作由 GraspCritic(DQN 风格)选择;
- 最后拼接成完整动作。
通俗说:用 SAC 给机器人一条柔顺的手臂,用 DQN 给机器人一只果断的手。
这种设计也更贴近人类遥操作习惯:SpaceMouse 控制连续运动,按钮控制夹爪开关。
双 MDP 并行求解:
MDP₁ (连续): S → A₁ (6D/12D twist) ← SAC Actor-Critic (RLPD)
MDP₂ (离散): S → A₂ (open/close/stay) ← DQN Critic (argmax)
单臂: |A₂| = 3 (open, close, stay)
双臂: |A₂| = 3² = 9 (每臂独立动作组合)
推理: a = [π_θ(s), argmax_a' Q_grasp(s, a')]
2.2 阻抗控制与精细力觉
HIL-SERL 不再使用僵硬的位置控制,而是采用笛卡尔阻抗控制(Cartesian Impedance Control)。
虚拟弹簧模型:机器人表现得像一个柔顺的弹簧,而不是冰冷的铁块。这使得机器人在探索时能够感知到物理约束(如孔位的边缘)。在开阔地带它能快速移动;在精密接触时,它能顺着物理约束滑动。
这种力觉层面的鲁棒性,让 HIL-SERL 能够完成诸如插内存条、翻煎蛋等对力度极其敏感的任务。它不是在"撞击"世界,而是在"抚摸"世界。
两种控制模式按任务类型切换:

我们可以这样理解:RL policy 负责高层策略,低层控制器负责把不完美动作变成可承受的物理交互。如果低层控制器过硬,探索阶段会损坏硬件;如果过软,机器人又无法完成精密装配。控制器不是附属细节,而是 HIL-SERL 成功的物理前提。
2.3 预训练视觉骨干
真实图像复杂、数据量有限,从零训练视觉编码器很容易过拟合或不稳定。HIL-SERL 使用预训练的 ResNet-10,在工程实现中冻结 ResNet-10 权重,只训练空间池化层和 MLP head——用预训练视觉特征降低真机数据需求。
多相机配置上,先选择任务最合适的相机:腕部相机有利于空间泛化,因为它提供 ego-centric view;如果腕部相机视野不够,就增加侧面相机。所有相机图像会裁剪到关注区域并 resize 到 128×128。
0x03 Human-in-the-Loop 机制
HIL-SERL 之所以能在众多真机 RL 方案中脱颖而出,不仅是因为效率,更因为它深刻理解了物理世界的交互本质——"人"作为最高级传感器的核心价值。
Human-in-the-Loop 在线纠正机制如下图所示。

3.1 人类何时介入
当策略把机器人带入 unrecoverable 或 undesirable state,或者卡在 local optimum 中——如果没有人类帮助需要很久才能走出来,此时人类会介入。这和 HG-DAgger 类似:人类不是全程控制,而是在策略表现不好时接管。
但 HIL-SERL 与纯 HG-DAgger 的关键区别是:HIL-SERL 使用这些纠正数据进行 reinforcement learning,而不是只做 supervised learning。不是简单地把人类动作当成 BC 标签,而是把人类纠偏纳入 off-policy RL 数据流,让策略从任务 reward 和纠正数据中共同学习。
环境恢复:盲目恢复 + 任务特定人工提示
系统不检查错误状态,而是预防性地每次发命令前都尝试恢复:
# franka_env.py:417-422 - "盲目恢复"
def _send_pos_command(self, pos):
self._recover() # ← 每次发命令前都清除错误,不管有没有错
requests.post(self.url + "pose", json=data)
def _recover(self):
requests.post(self.url + "clearerr") # → ROS ErrorRecoveryActionGoal
人工介入提示点
人工介入提示点举例如下:
| 场景 | 提示内容 |
|---|---|
| 鸡蛋丢失 | "We lost the egg!!! Put egg back and press Enter..." |
| 双臂交接重置 | "Press Enter to continue..." |
| RAM 重新抓取 | "Place RAM in holder and press enter to grasp..." |
| 相机冻结 | "camera frozen. Check connect, then press enter..." |
| 人工判断成功 | "Success? (1/0)" |
关键结论: 碰撞 / 错误不终止 episode。**done 只由超时、成功或 ESC 触发。碰撞后如果 _recover() 成功,机器人继续运行,中间的 “致死数据” 照常存入 Buffer,不会被标记或过滤。
3.2 干预数据如何进入训练
HIL-SERL 是异步 Actor-Learner 架构,数据是一个异步闭环。Actor 端持续执行环境交互,Learner 端持续从 buffer 中采样训练。人类干预发生后,数据会被写入本地 data store,并在一定时机上传到 Learner。Learner 训练和参数发布也有自己的节奏。
可以用时间线理解:
Actor端: ─[干预]─[干预]─[放手]─[policy]─[policy]─...─[episode结束]─client.update()→ 发送数据
↑
Learner端: ─────────────────────────────────────────────────────[持续训练循环]────────────
←────────────── 每 steps_per_update 步发布一次参数 ───────────────────────────→
因此,从干预发生到新参数生效,中间存在如下步骤或者环节:
- 当前 episode 剩余步骤;
- 数据传输:client.update() 在 episode 结束时才触发,不是干预后立刻上传
- Learner 采样到该数据:Learner 有自己独立的训练循环,持续从 buffer 采样训练,不关心数据来源是干预还是策略
- 完成若干训练更新;
- 下一次参数发布:每 steps_per_update=50 步发布一次,与干预事件无关
- Actor 接收并替换参数。
这不是“干预后即时改模型”,而是一个低耦合、异步的在线训练闭环。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)