Focus-Then-Contact——跟我之前给一工厂设计的插拔策略不谋而合:先ACT引导到目标区域附近,然后残差RL实施最终插入,且插入过程中视觉提供稠密奖励,必要时人工干预
前言
今(26年7.4日),无意中刷到一篇新闻,其中提到有一篇论文用在插拔场景中的策略,跟我5.21日在给一工厂设计的电池包充电插拔方案:ACT 宏观导引 + 真机残差 RL 微操,高度吻合,也是巧了(相当于各自独立摸索出来的策略)
我当时之所以如此设计,原因在于两点
- 一开始,即4.21日用的vla + 残差RL(为何用残差RL呢,因为相比纯真机RL探索,轻量级残差RL的训练更快)

- 后来,5.7日工厂说,节拍能否更快
故我于5.7日,又给工厂提供了非 VLA 的方案,即经典视觉 + 传统力控,RL则作为可选
可实话讲,因为非vla方案 需要严格限定各种条件,故我内心是担忧的 - 再后来,5.21日,跟工厂再次开会,工厂希望是否能保留一些些泛化性
就这样,我被工厂“逼”着想出了最终:ACT + 残差RL的插拔方案
那与我所设计策略类似的论文是哪篇论文呢,便是本文要介绍的:Focus-Then-Contact
第一部分 Focus-Then-Contact: Speeding Up Robotic Contact-Rich Task Learning withAffordance-Guided Real-World Residual Reinforcement Learning
1.1 引言与相关工作
1.1.1 引言
如原论文所说,RL已经逐步应用在机器人的各类任务中。而传统RL一般依赖于先在仿真中的训练,可许多接触密集型任务需要极高的进度,故对仿真引擎提出了极高要求
- 好在后来出现的人类在环的真实世界强化学习,使得将物理环境转化为实用的、可交互的 RL 训练平台成为可能(Luo et al., 2024,即SERL; 2025,即HIL-SERL)
比如HIL-SERL,详见本博客中的解读《HIL-SERL——结合“人类离线演示、在线策略数据、人工在线干预”的RL方法:直接真实环境中RL开训,可组装电脑主板和插拔USB》
这种范式摆脱了对传统仿真引擎的依赖,而在人类在环的真实世界 RL 训练中引入人类示范干预,甚至可以将接触密集型任务的成功率提升至 100%(Chen et al., 2025 即ConRFT; Strangh¨oner et al., 2025 即SHaRe-RL; Luo etal., 2025) - 然而,由于在真实世界中可进行的交互次数极为有限,人类在环的方法需要人类专家投入大量时间,通过示教来引导机械臂完成任务
因此,人类在环真实世界 RL 的核心挑战在于:在极其有限的物理交互下,如何才能高效地学习到鲁棒且精确的控制策略?
一种提升强化学习(RL)策略的有前景的方法是将其与模仿学习(IL)相结合
- Yuan et al., 2025b
Policy decorator: Model-agnostic online refinement for large policy model - Chu etal., 2025
Sft memorizes, rl generalizes: A comparative study of foundation model post-training
该文献对基础大模型的后训练阶段进行了对比研究,指出监督微调(SFT)倾向于使模型死记硬背而强化学习(RL)能增强其泛化能力
IL 提供了一个基础动作,用于对探索过程进行正则化,而在线 RL 则通过与环境交互来提升策略性能
- 然而,现代的 IL 模型(例如 Vision-Language-Action,VLA)具有复杂的架构,这使得直接应用 RL 方法变得具有挑战性
Li et al., 2025a
Simplevla-rl: Scaling vla training via reinforcement learning
Luet al., 2025a
Zang et al., 2025
Rlinf-vla: A unified and efficient framework for vla+ rl training
该文献构建了一个用于将VLA基础大模型与强化学习在线微调进行联合训练的统一且高效的训练框架(RLinf-VLA) - 一个自然而然的想法是,Residual RL 通过针对这些问题提供一种更简单但同样有效的解决方案
其核心概念是固定一个由 IL得到的“基础策略”,并训练一个轻量级的“残差策略”,以在实际运行时迭代地调整基础策略的输出Alakuijala et al., 2021
Residual reinforcement learning from demonstrations
该文献探索了如何结合已有的行为演示来通过残差强化学习(Residual RL)改善和纠正控制策略
Residual off-policy rl for finetuning behavior cloning policies
该文献开发了ResFiT框架,通过离策残差强化学习对经典的行为克隆模仿学习策略进行后续微调
然而,这一方法在有人参与的人机交互真实环境强化学习(RL)设置中尚未充分展示其潜力。除此之外,许多当前的方法依赖稀疏奖励,这会导致探索效率较低
- Xu et al., 2024
Rldg: Robotic generalist policy distillation via reinforcement learning,详见本博客中的解读《知识蒸馏RLDG:先基于精密任务训练RL策略(HIL-SERL),得到的RL数据去微调OpenVLA,最终效果超越人类演示数据》 - Dong et al., 2025
Expo: Stable reinforcement learning with expressive policies,该文献提出了一种与高表达能力流策略相结合的稳定、高效的残差强化学习算法架构(EXPO) - Ankile etal., 2025a
对此
- 作者认为,需要设计一种稠密奖励
Li etal., 2026b
BoostAPR: Boosting automated program repair via execution-grounded reinforcement learning with dual reward models,该文献利用基于代码执行落地的强化学习和双奖励模型来显著提升和增强自动程序修复(APR)的能力
以引导智能体逐步聚焦到有助于任务完成的感兴趣区域(ROI)
一个有前景的方向是引入可供性(affordance,即环境中物体的可行动属性),它可以引导智能体的注意力指向ROI
Bahl et al., 2023
Affordances from human videos as a versatile representation for robotics,该文献将从人类日常行为视频中提取出的可操作性(Affordance)视为一种通用的、跨任务的机器人空间动作表征
Lee et al., 2025
Affordance-guided reinforcement learning via visual prompting,该文献探讨了利用大模型配合视觉提示生成可操作性信号,以计算稠密过程奖励从而引导强化学习训练的方法(KAGI) - 然而,目前用于预测或提取可供性的模型
Achiamet al., 2023,即GPT4
Carion et al., 2025,即Sam 3: Segment anything with concepts
通常规模较大,这可能会在真实世界的 RL 场景中阻碍推理速度
最终,来自1 School of Data Science, The Chinese University of Hong Kong, Shenzhen、2 DexForce Co., Ltd的研究者文提出了一种名为 Focus-Then-Contact(FTC)的方法,这是一种轻量且低成本的人在回路真实世界强化学习框架,专为接触密集、细粒度操作任务而设计

FTC 从三个关键维度推进了当前技术水平:
- 基于残差强化学习的基础动作
利用残差强化学习来细化模仿学习(IL)得到的基础策略,从而生成基础动作。该基础动作为探索提供了起点,使系统能够聚焦目标区域,降低在真实世界环境中学习的复杂度 - 基于关键帧的可供性引导
为最大限度减少基于接触的无意义试错,FTC 提供源自关键帧可供性的连续学习信号
作者从示教数据中提取目标关键帧,并采用时间上一致的视觉编码器来度量当前嵌入与目标嵌入之间的距离 - 在杂乱场景中通过人类在环实现接触
为促进精确交互,FTC 采用双腕部相机配置,并在杂乱环境中对夹爪和目标物体都加入旋转泛化能力。人类专家可以通过一个定时干预窗口进行介入
1.1.2 相关工作
首先,对于人类参与环节的现实世界强化学习系统
- 近期的工作已经成功地将人类干预整合到策略训练过程中
Kelly 等,2019,即Hg-dagger: Interactive imitation learning with human experts
Retzlaff 等,2024,即Human-in-the-loop reinforcement learning: A survey and position on requirements, challenges, and opportunities,该文献全面而系统地综述了人在环路强化学习(HITL-RL)领域的核心需求、所面临的关键挑战以及未来发展机遇
并利用强化学习方法来优化策略性能,从而实现对机器人进行精确且灵巧的操作,例如 SERL 和 HIL-SERL - 利用得益于人类引导的优势,近期工作大幅提升了机器人在灵巧操作任务中的性能
He et al.,2025,即Uncertainty comes for free: Human-in-the-loop policies with diffusion models
Hu et al., 2025,即Rac: Robot learning for long-horizon tasks by scaling recovery and correction,详见本博客中的解读《RaC——挂衬衫且打包外卖盒:如果机器人将失败,则人类让其先回退后纠正,以减缓IL中的误差累积(让数据的增长对任务促进的效率更高)》 - 基于人类参与在环(human-in-the-loop)的强化学习系统,近期工作也在微调 VLA 模型方面取得了进展
Xu et al., 2024
Lu et al., 2025b,即Human-in-the-loop online rejection sampling for robotic manipulation,该文献展示了一套人在环路的在线拒绝采样策略,用以优化机器人多阶段操作的轨迹合理性
Kawaharazuka et al., 2025
ConRFT 结合行为克隆和 Q-learning,以实现高样本效率
Chen etal., 2025,详见本博客中的解读《ConRFT——Consistency Policy下RL微调VLA的方法:先通过示教数据离线微调(Cal-QL的Q损失基础上引入BC损失),后在线RL微调(引入RLPD的新老数据对称采样及人工干预)》
而 HAPO 则通过人类干预来对齐动作的参考,有助于让 VLA 模型避免产生不满意的运动
Xia et al., 2025,即Human-assisted robotic policy refinement via action preference optimization,该文献提出通过人类在线干预来对齐和优化机器人的动作参考偏好(HAPO),以防VLA大模型产生不合理的错误运动
然而,这些工作都需要长期的人类干预以及大量计算资源才能完成
其次,对于残差强化学习(Residual RL)系统
- 与其微调整个策略网络,残差强化学习系统更侧重通过一个轻量级网络来学习校正,从而在提供安全性保证的同时提高样本效率
- 近期工作在利用残差强化学习解决机器人操作任务方面取得了显著进展
DP-RRL和 EXPO 将残差强化学习应用于流式策略(flowpolicies),在引入残差的同时保留了流式策略的表达能力
Dong 等,2025
Li 等,2025b
然几乎所有的最新工作在强化学习训练中都采用稀疏奖励设定,即只有在任务接近完成或成功完成时才给予奖励,这会导致大量无效的探索以及缓慢的训练收敛
最后,对于机器人操作的可供性(Affordance)
- 可供性作为一种空间表征方式,在机器人操作领域被广泛使用
Manuelli et al., 2019
Ardón et al., 2020
Gao &Tedrake, 2021
Curtis et al., 2022; Xu et al.,2026
通过预测不同形式的可供性表征,已有工作在面向真实场景机器人操作的视觉-语言模型(VLM)中取得了成功
Bahl et al., 2023
Yuan etal., 2025a
Liu et al., 2024 - 作为物体交互的一种有效指导信号,近期工作也将强化学习(RL)系统与可供性信号进行集成
Brohan et al., 2023
Fang et al., 2023
KAGI 利用 VLM 从机器人观测中生成可供性,然后计算稠密奖励以指导 RL 训练(Lee et al., 2025)
然而,VLM 推理的高计算开销无法满足真实场景中的 RL 训练需求
因此,作者决定采用了一种更轻量的方式,为真实环境下的 RL 训练提供由可供性引导的奖励
1.1.3 问题形式化
对于目标条件部分可观测马尔可夫决策过程
作者将真实世界中的强化学习机器人高接触操作任务形式化为一个无限时域的目标条件部分可观测马尔可夫决策过程(GCPOMDP)(Sutton & Barto, 2018),由元组定义
其中:
- 在观测空间
内,每个观测
由两部分组成:本体感知(
) 和视觉输入(
)
记录机器人、工作空间环境以及周围背景的完整信息
作者将状态总结为,且每个
表示动作空间,动作
表示末端执行器相对于上一帧的6D 位姿增量,并使用一维离散值0/1 来控制夹爪的开/关
表示奖励函数,通常由可供性引导的奖励和稀疏任务奖励组成
表示转移动作函数,将状态-动作对映射到未来状态的分布
表示初始状态分布
表示折扣因子
表示机器人手臂在完成任务后到达的目标(不同的末端执行器6D 位姿)
表示一个函数,将状态空间中的视觉观测映射到目标空间中的目标
在该GCPOMDP下,目标是学习一个控制策略,以最大化折扣累计回报
- 状态-动作价值函数可以估计为:
其中表示任务范围
- 作者的方法基于一个离线策略强化学习算法Soft Actor-Critic (SAC) (Haarnoja et al., 2018),我们希望求解:
其中是一个正则化系数,用于控制熵项的重要性
与HIL-SERL 中采用的人在回路方法一致,人类专家可以在RL 训练过程中随时进行干预
动作模式根据干预切换为
。此类干预被单独存储到RL 回放缓冲区
和专家示范缓冲区
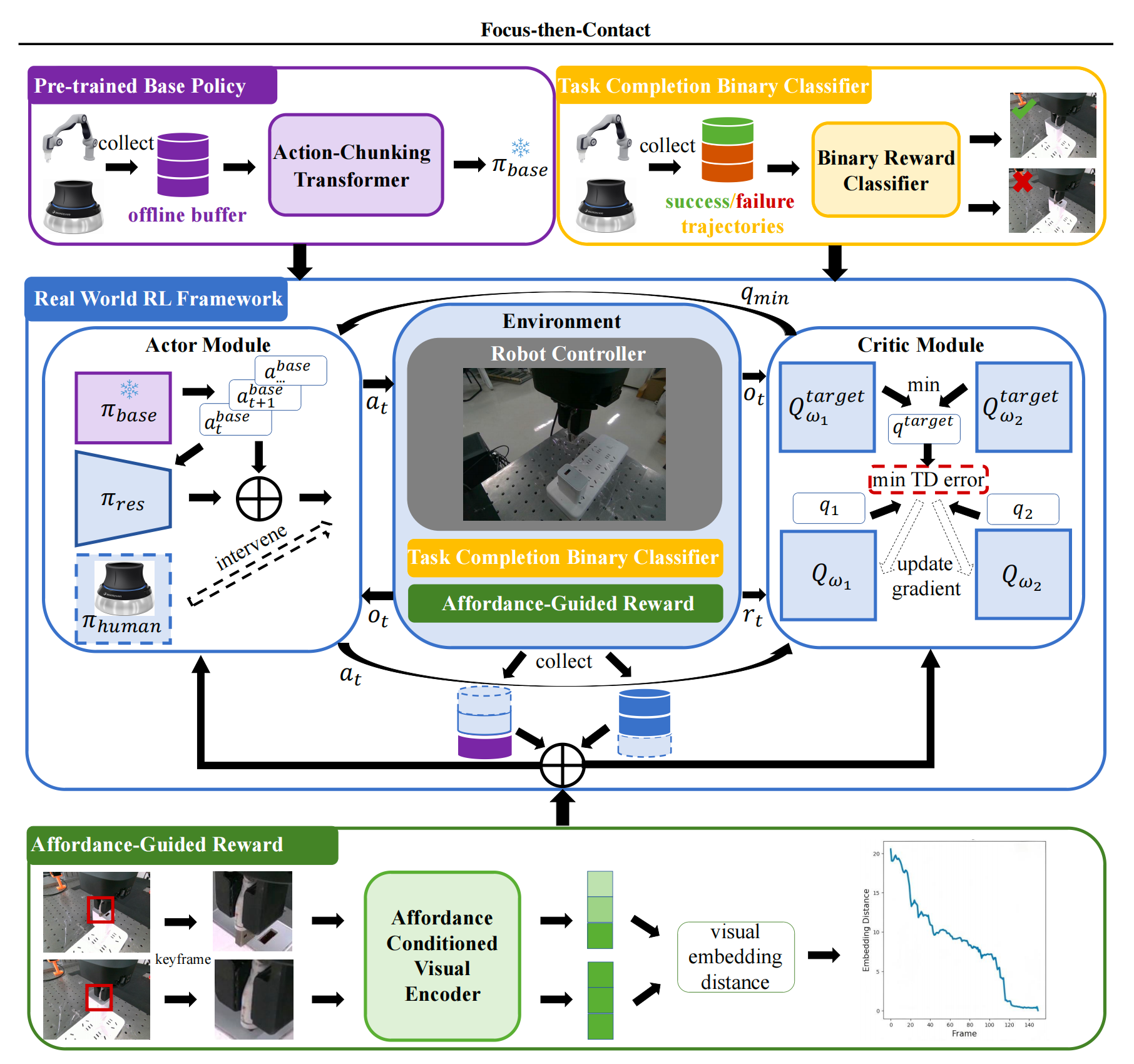
1.2 First ”Focus” Then ”Contact”的完整方法论
作者提出的方法 Focus-Then-Contact(FTC)由离线IL 预训练阶段和在线RL微调阶段构成。整体框架包含三个主要组件:
- 残差强化学习设计
- 基于可供性(affordance)的奖励机制
- 以及人类参与的人机闭环真实世界强化学习系统
具体如图 1所示
1.2.1 现实世界中的残差强化学习
BC 过程产生一个基础策略,它在任务成功率上提供了一定的保障,但仍有提升空间
为此,冻结π base ,并引入一个残差策略来纠正
所犯的错误,从而提升整体性能。用于学习残差策略的残差网络非常轻量,仅由两层MLP 和层归一化组成
这样的设计确保了两个关键方面:
与
松散耦合,从而能够无缝集成不同的基础策略
在残差学习框架中,作者将动作 分解为两个部分:基础动作
和残差动作
。
也需要存储在
和
中
- 由于动作包含三个表示欧拉角旋转的维度,旋转通常不能直接相加。然而,这对神经网络的收敛性没有显著影响。因此,时刻
的总动作为
残差策略 - 为了在残差框架中表示状态-动作价值
,需要修改贝尔曼方程,以近似基础动作与残差策略动作之和的Q 值
因此,应当用如下方式计算Q 值
于是,问题变为:
在与环境交互的过程中,基础策略每次都会输出末端执行器姿态的相对取值。为了降低RL训练的难度,作者不让残差策略输出所有 k 个数值。相反,它只输出第一个数值,而基础策略则利用该数值来生成最终动作
1.2.2 基于关键帧的可供性引导奖励
如原论文所述,尽管残差强化学习(residual RL)可以提高采样效率,但稀疏奖励仍然只能提供有限的反馈,这使得现实世界中的强化学习在训练过程中难以获得有效的指导,从而导致训练时间更长
- 毕竟强化学习需要大量成功的轨迹来学习正确的策略
此外,现实世界中的强化学习交互频率远低于仿真环境,因此需要大量正确示例,才能让智能体逐步学习并完成任务
这凸显了在环人类教学(human-in-the-loop teaching)的必要性,以加速任务学习 - 相比之下,稠密奖励能够提供连续反馈,更好地引导智能体走向成功
FTC 旨在通过在稀疏的任务完成奖励之上增加稠密的过程奖励,来提供这类反馈
具体来说,作者认为稠密奖励是基于可供性信息计算的
传统方法通常依赖关键点来表示可供性(Lee 等,2025;Ardón 等,2020)
在最初阶段,作者也采用了这一思路,具体做法是使用VLM(Achiam 等,2023)/目标检测 + 分割模型,例如 SAM 3(Carion 等,2025),并结合视觉或语言提示来识别关键点
尽管 VLM/SAM 3 具有很强的泛化能力,然而,直接将这种方法应用于真实环境仍然存在一些尚未解决的问题:
- 开源 VLM 的泛化能力不足(Li 等人,2026a),而收集大量数据进行微调的成本又过于高昂。相较之下,闭源 VLM 在推理速度方面无法满足要求,因为真实世界的强化学习需要实时给出奖励
- 如图 2 所示,SAM 3 中的目标检测会受到周围环境的影响,在背景杂乱的场景中容易出错

- 作者的实验任务设置涉及旋转泛化。在夹爪旋转过程中,会出现视觉遮挡,从而影响相机视野并导致感知上的潜在误差
然后作者考虑,基于关键帧的可供性是否可以作为一种替代方式来引导RL 朝向目标?对于诸如USB 插拔之类的任务,在操作过程中孔洞通常是被遮挡的,但只需要关注任务完成时的目标状态
- 在真实世界RL 训练之前,
会预先填充演示轨迹,作者可以从中直接提取与任务完成相关的关键ROI
- 基于此,作者设计了一个稠密奖励函数:将当前图像和目标关键帧都裁剪到相同的预定义ROI,然后通过共享的视觉编码器进行编码
奖励被计算为两个嵌入之间的距离函数
接下来的问题便是选择什么样的视觉编码器了
- 作者宣称,在他们的实验中,他们发现直接使用传统的视觉编码器(例如 ResNet 或 ViT)来计算距离并获得奖励信号,会导致性能不稳定
- 为了获得更平滑且在几何上更加一致的嵌入表示,作者参考了 (Ma et al.,2023),其学习了一种自监督的最优距离函数。这可以被表述为 InfoNCE (Oord et al., 2018) 的形式:
其中可以被视为目标关键帧的分布
为“正样本”的分布
而为“负样本”的分布
是一个超参数
可以将其理解为一种新颖的隐式时间对比目标,该目标生成在时间上平滑的嵌入,从而使得距离函数可以通过嵌入空间中的距离被隐式地定义 - 随后,作者为当前任务构造奖励函数:
其中
————
且作者还训练了一个稀疏的二值奖励分类器,并将其与结合:
作者宣称,他们经过实验验证后发现,与仅依赖稀疏奖励相比,这种引导能够促进更高效且更具泛化能力的在线学习
1.2.3 FTC 人类参与闭环的真实世界RL设计
如上所述,作者的方法使用了离策略数据、混合奖励函数,并在训练策略时交替使用SAC
在下文中,作者将详细说明在不同任务和夹爪之间实现稳定FTC框架所需的关键设计选择。且算法1给出了FTC框架的伪代码。关于其他具体细节,请参见附录B
首先,对于人类在环模块设计
作者使用一台工业协作机械臂,在坐标系方面采用工业应用中常见的工件坐标系。在实验中,作者观察到在机械臂控制上,人类示教与强化学习(RL)之间偶尔会发生冲突
为了解决这一问题,作者在人工示教期间引入一个短暂的干预窗口,记为 W
- 如果在该时间窗口内没有发生人类示教,一旦窗口到期,控制权将移交给 RL
- 如果窗口处于激活状态但没有人类示教发生,机械臂将保持静止
- 如果人类示教持续超出该窗口,则该窗口的时长将被重置
其次,对于奖励的可扩展性
作者分别讨论稠密奖励和稀疏奖励
- 对于稀疏奖励,作者为每个任务单独训练一个二元奖励分类器
比如需要为每个任务收集4 条成功轨迹和 8 条失败轨迹,每条轨迹包含 50到 100 张图像。训练和推理都在一张 4090 GPU上进行,共 2,000 个 epoch,但总耗时不超过五分钟
因此,即使为每个任务单独训练一个稀疏奖励模型,速度也非常快 - 对于稠密奖励,作者在所有任务中使用一个共享的视觉编码器
为确保该视觉编码器能够对大多数任务进行良好的泛化,作者首先在大量人类操作视频上对其进行预训练。尽管这些超出机器人控制领域的视频并非机器人控制的“域内”数据,但可以被视为人类动作策略的“域内”数据
图3在相同视觉编码器设置下给出了多种任务的稠密奖励曲线,表明基于关键帧的奖励能够在相关任务和物体之间迁移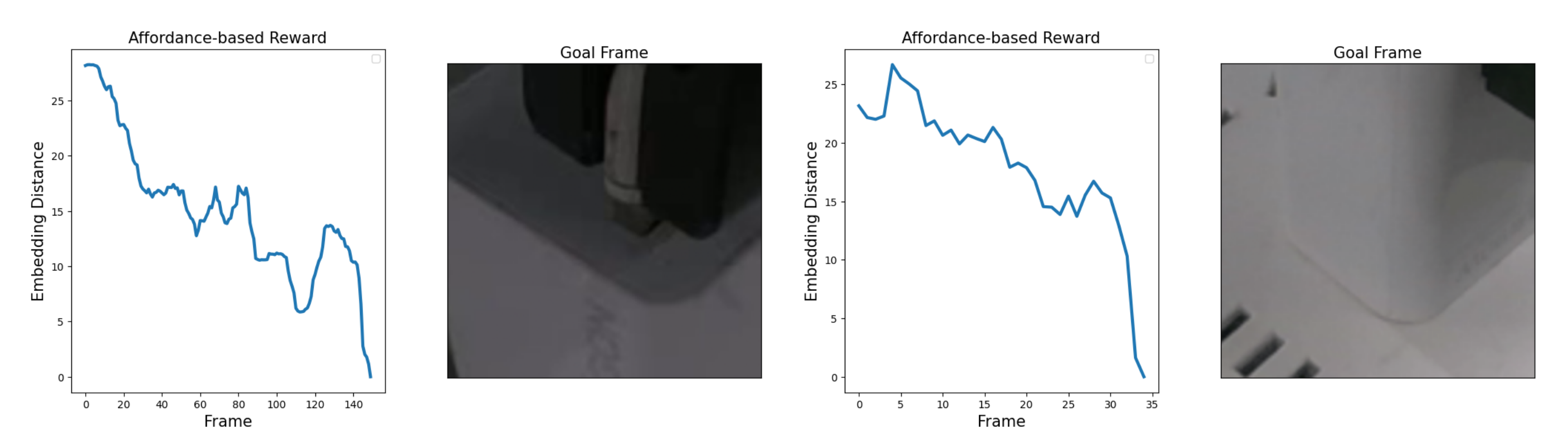
这一结果清晰地展示了在不同高接触密集型任务过程中奖励的波动情况
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 1
1 0
0- 0



 已为社区贡献100条内容
已为社区贡献100条内容

所有评论(0)